Continuation from the previous 128 parts, the whole series can be found at https://www.nikoport.com/columnstore/.
In this blog post I would like to point the compatibilities with the immediately upcoming release of Sql Server 2019 and the Columnstore Indexes.
In the last decade, Microsoft has made a kind of a rule – making the Columnstore Indexes not immediately compatible with all the features and sometimes making just one kind of the Columnstore Indexes compatible while others would have to wait until the next release (Think Online Rebuild), cry and ask for more (Resumable Online Index Rebuild) or even probably waiting forever (think Replication for the Clustered Columnstore Index).
Looking at the newest features (because as you will see in the next blog posts, there are smaller things in this release of Sql Server 2019 (or let’s say they will be considered by the most users as such) or … let’s say that some features ARE hidden behind the trace flags and maybe won’t ever see the light of the day). I mean do not forget about the funny kid on the block – The In-Memory Columnstore Indexes … Just a reminder: I would LOVE to see them being supported on the Schema-Only In-Memory tables!
And so I decided to make a list and a test of the features that are new to the upcoming Sql Server 2019 and that make sense testing with the Columnstore Indexes on the first sight:
– Approximate Distinct Count
– Scalar UDF Inlining
– Table variable deferred compilation
– Accelerated Database Recovery
– Memory-Optimized TempDB Metadata
– Persistent Memory
– Optimize for Sequential Key option
– SQL Graph with a number of different features, especially focusing on the Sql Server 2019 additions
– Verbose truncation warnings
Warning: I am not considering the Big Data Clusters in this moment in this blog post, so feel free to comment on this post complaining. :)
Setup
I will use the forever young version of the good old free and currently removed from the official download site of Microsoft – ContosoRetailDW database. If you want a copy of it, just google around.
To set it up a bit further we shall need to create a Clustered Columnstore Index on the FactOnlineSales table and a Nonclustered Columnstore Index on the FactSales table:
USE [master]
alter database ContosoRetailDW
set SINGLE_USER WITH ROLLBACK IMMEDIATE;
RESTORE DATABASE [ContosoRetailDW]
FROM DISK = N'C:\Install\ContosoRetailDW.bak' WITH FILE = 1,
MOVE N'ContosoRetailDW2.0' TO N'F:\Data\ContosoRetailDW.mdf',
MOVE N'ContosoRetailDW2.0_log' TO N'F:\Data\ContosoRetailDW.ldf',
NOUNLOAD, STATS = 1;
alter database ContosoRetailDW
set MULTI_USER;
GO
use ContosoRetailDW;
ALTER TABLE dbo.[FactOnlineSales] DROP CONSTRAINT [PK_FactOnlineSales_SalesKey];
CREATE CLUSTERED COLUMNSTORE INDEX PK_FactOnlineSales on dbo.FactOnlineSales;
CREATE NONCLUSTERED COLUMNSTORE INDEX NCIX_FactSales ON dbo.FactSales
([SalesKey], [DateKey], [channelKey], [StoreKey], [ProductKey], [PromotionKey], [CurrencyKey], [UnitCost], [UnitPrice], [SalesQuantity], [ReturnQuantity], [ReturnAmount], [DiscountQuantity], [DiscountAmount], [TotalCost], [SalesAmount], [ETLLoadID], [LoadDate], [UpdateDate], [NewTotalCost])
In the end we need to ensure that we are working with Compatibility Level 150, corresponding to the Sql Server 2019, because that’s where the most features are hidden and Query Optimiser won’t be helpful running an elder version of the product and trying the newest features which won’t even work in some of the cases:
ALTER DATABASE [ContosoRetailDW] SET COMPATIBILITY_LEVEL = 150;
Approximate Distinct Count
I have already blogged about Approximate Distinct Count and the usage of the Columnstore Indexes makes EXTREME amount of sense in the big data scenarios.
The approximate distinct count is definitely compatible with the regular Columnnstore Indexes, as you can see from the queries below:
SELECT YEAR(s.DateKey) as ShipYear, COUNT( s.DiscountAmount ), COUNT(DISTINCT s.DiscountAmount), APPROX_COUNT_DISTINCT (s.DiscountAmount) FROM [dbo].FactSales s GROUP BY YEAR(s.DateKey); SELECT YEAR(s.DateKey) as ShipYear, COUNT( s.DiscountAmount ), COUNT(DISTINCT s.DiscountAmount), APPROX_COUNT_DISTINCT (s.DiscountAmount) FROM [dbo].FactOnlineSales s GROUP BY YEAR(s.DateKey);
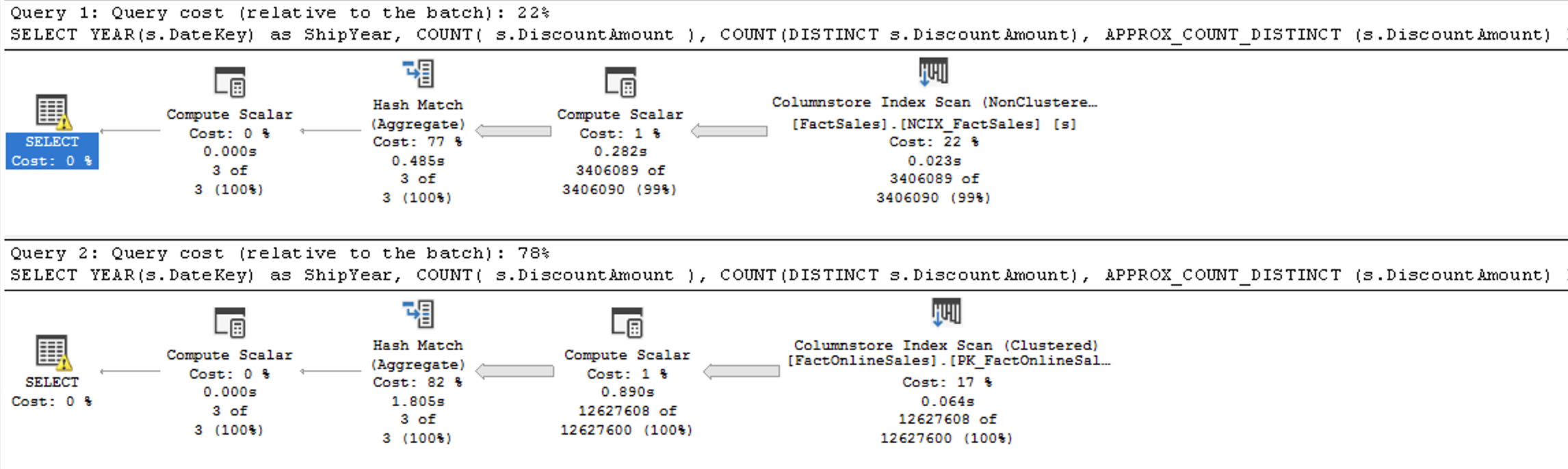 The corresponding execution plans are presented on the top and in both cases you can clearly see the usage of the Columnstore (Nonclustered & Clustered) Indexes.
The corresponding execution plans are presented on the top and in both cases you can clearly see the usage of the Columnstore (Nonclustered & Clustered) Indexes.
I expect nothing less from a new T-SQL feature, especially the one that really strives and shines with the Batch Execution Mode.
Scalar UDF Inlining
In a little bit cheeky post Froid vs Freud: Scalar T-SQL UDF Inlining I have also blogged about one of the most exciting features of the upcoming Sql Server – The Froid Framework, which allows Query Optimiser to inline the User Defined Functions.
Creating some random math functions that is easily inalienable
CREATE FUNCTION dbo.SumAndMultiply( @p1 DECIMAL(16,4), @p2 DECIMAL(16,4) )
RETURNS DECIMAL(38,6) AS
BEGIN
RETURN (@p1 + @p2) + (@p1 * @p2)
END
and then running a couple of MagicCounts on the both types of the Columnstore Indexes:
SELECT TOP 100 dbo.SumAndMultiply(s.ReturnAmount, s.ReturnQuantity) as MagicCount FROM dbo.FactSales s ORDER BY MagicCount DESC; SELECT TOP 100 dbo.SumAndMultiply(s.ReturnAmount, s.ReturnQuantity) as MagicCount FROM dbo.FactOnlineSales s ORDER BY MagicCount DESC;
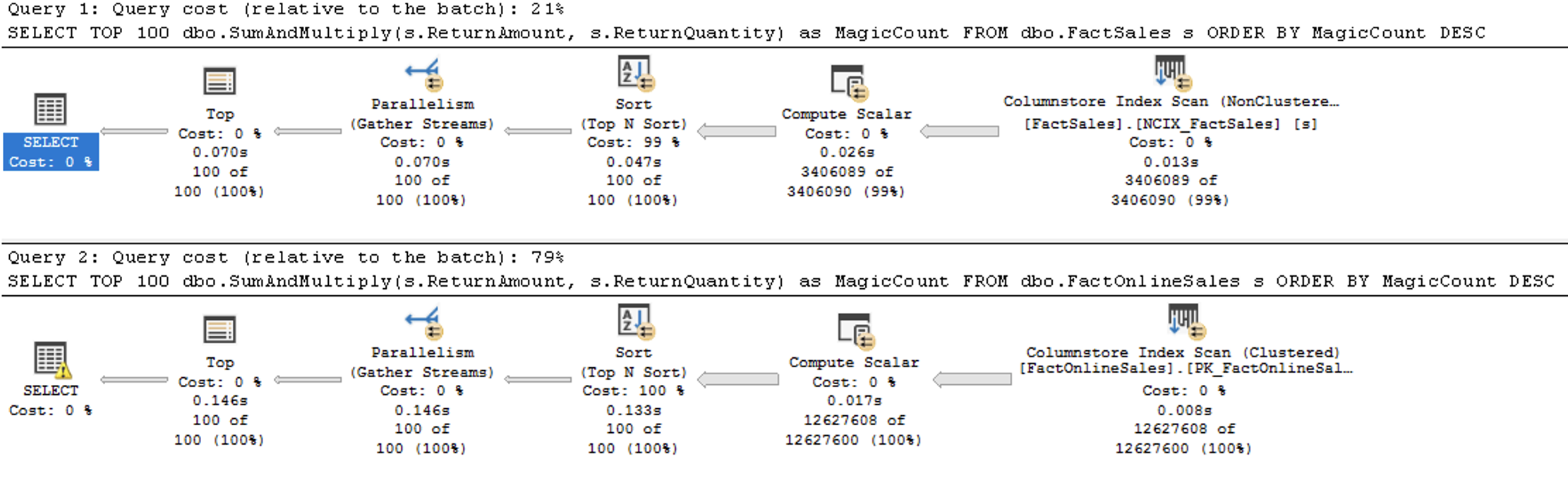 Works like magic, isn’t it ? A brilliant effort by Microsoft which I hugely appreciate.
Works like magic, isn’t it ? A brilliant effort by Microsoft which I hugely appreciate.
Table variable deferred compilation
Table variable deferred compilation is an awesome addition to the Intelligent Query Processing family
DECLARE @testVar TABLE (c1 INT NOT NULL PRIMARY KEY, INDEX CCI_TestVar CLUSTERED COLUMNSTORE );
but unfortunately (Good Question if it is unfortunately until 2019, but even a better question that in SQL Server with Table variable deferred compilation the Columnstore should be supported in Table Variables) there is no support for Columnstore Indexes in table variables.
The error message is very much explicit about this:
Msg 35310, Level 15, State 1, Line 3 The statement failed because columnstore indexes are not allowed on table types and table variables. Remove the column store index specification from the table type or table variable declaration.
Accelerated Database Recovery
Accelerated Database Recovery is one of the key item for Sql Server & Azure SQL Database/SQL Datawarehouse. Allowing to cancel instantly long-running queries is essential for Business Intelligence & Data Warehousing projects. Generally any significant ETL is a winner with ADR, in the case it has enough support for the caused IO.
Let’s enable Accelerated Database Recovery on the ContosoRetailDW and run a couple of queries, loading the data
ALTER DATABASE ContosoRetailDW
SET ACCELERATED_DATABASE_RECOVERY = ON;
CREATE NONCLUSTERED COLUMNSTORE INDEX [NCIX_FactITMachine] ON [dbo].[FactITMachine] ([ITMachinekey], [MachineKey], [Datekey], [CostAmount], [CostType], [ETLLoadID], [LoadDate], [UpdateDate])
SELECT SUM([CostAmount]) FROM dbo.FactITMachine;
Works like it should:

Memory-Optimized TempDB Metadata
Memory-Optimized TempDB Metadata is something I am going to write about. The feature Hekaton-ises a good number of Metadata inside the TempDB, allowing to speed up essential operation in TempDB, such as new object allocation.
Enabling this feature is done with ALTER SERVER CONFIGURATION command and a Restart of the Sql Server service.
ALTER SERVER CONFIGURATION SET MEMORY_OPTIMIZED TEMPDB_METADATA = ON;
Running the same test queries as in the previous item on Accelerated Database Recovery gives us positive result:
CREATE NONCLUSTERED COLUMNSTORE INDEX [NCIX_FactITMachine] ON [dbo].[FactITMachine] ([ITMachinekey], [MachineKey], [Datekey], [CostAmount], [CostType], [ETLLoadID], [LoadDate], [UpdateDate]) WITH (DROP_EXISTING = ON ); SELECT SUM([CostAmount]) FROM dbo.FactITMachine;
but the tricky stuff will appear once we experiment on working with TempDB, by creating a temp table with a Columnstore Index (and it does not matter which one, if it is a Clustered Columnstore or Nonclustered Columnstore):
CREATE TABLE #t (c1 int, INDEX CCI_T CLUSTERED COLUMNSTORE );
The error message is pretty much explicit, saying this this is not supported at all.
Msg 11442, Level 16, State 1, Line 2 Columnstore index creation is not support in tempdb when memory-optimized metadata mode is enabled. Msg 1750, Level 16, State 1, Line 2 Could not create constraint or index. See previous errors.
This is a serious bummer for me, since we do not have the Schema-Only In-Memory Table, Temporary tables are pretty much useful feature for so many scenarios.
One of the key impacts here is the fact is that the support for Columnstore Indexe compression estimation that is being introduced in Sql Server 2019 will be unsupported for the configurations with Memory-Optimized TempDB Metadata:
EXECUTE [sys].[sp_estimate_data_compression_savings] @schema_name = 'dbo', @object_name = 'FactSalesQuota', @index_id = 1, @partition_number = 1, @data_compression = 'COLUMNSTORE';
The error message once again is different and very much explicit:
Msg 11442, Level 16, State 1, Line 1 Columnstore index creation is not support in tempdb when memory-optimized metadata mode is enabled.
I will give you a hint as a solution – you can easily use my CISL library, which will allow you to parametrize the cstore_sp_estimate_columnstore_compression_savings Strored Procedure destination Database Name, Schema Name, Table Name and if the table should be deleted right after the end of the estimation process:
execute dbo.cstore_sp_estimate_columnstore_compression_savings @tableName = 'FactSalesQuota', @data_compression = 'COLUMNSTORE_ARCHIVE', @destinationDbName = 'ContosoRetailDW', @destinationTable = 'FactSalesQuota_estimated', @deleteAfterSampling = 1;

I totally understand that Columnstore Indexes are complex beasts, but I expect this to be fixed. I believe we shall be seeing more investments into the In-Memory technologies and one day some company important enough will force Microsoft to dedicate attention to the lack of support of this feature.
Interestingly – I have successfully tested creation of the temp table with Columnstore Indexes on Azure SQL Database (P1), meaning that there is no such problem there:
CREATE TABLE #t (c1 int, INDEX CCI_T CLUSTERED COLUMNSTORE ); CREATE TABLE #tnc (c1 int, INDEX CCI_Tnc NONCLUSTERED COLUMNSTORE (c1) );
The results of the compatibility clearly show that this feature – Memory Optimised Metadata model is a on-premises or IaaS (Azure VM) focused only at the moment. Unless Microsoft is playing some double game and have some tweaks that they can not transcend into regular Sql Server version – I will make a guess that Azure is not using Memory Optimised Metadata model yet. Given some of the other limitations that I know of, it is a very much probable scenario.
I do however hope that this option will get more attention in post-SQL Server 2019 releases.
I assume that Microsoft won’t risk breaking existing applications and the Memory-Optimized TempDB Metadata won’t hit Azure until the lack of support is fixed.
Persistent Memory
I expect the Persistent Memory to fully support Columnstore Indexes (maybe with the exception of the In-Memory Columnstore – hehe pun intended), but given that right now I do not have any access to a server with it – I can’t test it.
Dear Microsoft, if you are reading it – please send me a server with some Persistent Memory to test … Hehehe :)
Optimize for Sequential Key option
Another feature on my to-blog about list is the Optimize for Sequential Key option that will allow to improve the contention caused by last-page insertion operations.
We all know that Columnstore Indexes do not order … YET (see Columnstore Indexes – part 129 (“Compatibility with the New Features of Sql Server 2019”) … WELL, OFFICIALLY at least … but the insertion of the data into Delta-Stores (aka Trickle Inserts) are done with the traditional heaps and so I thought maybe we should test them.
Additionally, if this option is applied on the Rowstore Indexes – are they still compatible with the Columnstore Indexes ?
Well … Creating a table with the hint OPTIMIZE_FOR_SEQUENTIAL_KEY = ON gives immediately an error message :(
CREATE CLUSTERED COLUMNSTORE INDEX PK_FactOnlineSales on dbo.FactOnlineSales
WITH (DROP_EXISTING = ON, OPTIMIZE_FOR_SEQUENTIAL_KEY = ON );
CREATE NONCLUSTERED COLUMNSTORE INDEX [NCIX_FactITMachine] ON [dbo].[FactITMachine] ([ITMachinekey], [MachineKey], [Datekey], [CostAmount], [CostType], [ETLLoadID], [LoadDate], [UpdateDate])
WITH (DROP_EXISTING = ON, OPTIMIZE_FOR_SEQUENTIAL_KEY = ON );
The error messages are pretty much explicit:
Msg 35318, Level 15, State 1, Line 2 The statement failed because the OPTIMIZE_FOR_SEQUENTIAL_KEY option is not allowed when creating a columnstore index. Create the columnstore index without specifying the OPTIMIZE_FOR_SEQUENTIAL_KEY option. Msg 35318, Level 15, State 1, Line 3 The statement failed because the OPTIMIZE_FOR_SEQUENTIAL_KEY option is not allowed when creating a columnstore index. Create the columnstore index without specifying the OPTIMIZE_FOR_SEQUENTIAL_KEY option.
Creating additional Indexes with OPTIMIZE_FOR_SEQUENTIAL_KEY on the tables with Columnstore Indexes works fine though:
CREATE NONCLUSTERED INDEX NC_FactSales_SalesKey ON dbo.FactSales ( [SalesKey] ASC )WITH ( OPTIMIZE_FOR_SEQUENTIAL_KEY = ON); CREATE NONCLUSTERED INDEX NC_FactOnlineSales_SalesKey ON dbo.FactOnlineSales ( [DateKey] ASC )WITH ( OPTIMIZE_FOR_SEQUENTIAL_KEY = ON) GO
I love the feature and I see it being used for high-end installations. The direct non-compatibility with Columnstore Indexes is not a big thing, but one always wonders if one day the features will be well and equally supported.
SQL Graph with a number of different features
Here I will focus specifically on the Sql Server 2019 additions, such as Edge Constraints, Derived Tables, Heterogeneous Nodes, Merge DML and the Shortest Path.
SQL Graph can benefit hugely from the Columnstore Indexes and especially from the Batch Execution Mode and its support is monumental for the SQL Graph success in the future. New to Sql Server 2019 the Edge Constraints do this support both Columnstore Indexes as you can see from execution of the script below:
DROP TABLE IF EXISTS dbo.FriendsWith;
DROP TABLE IF EXISTS dbo.Person;
CREATE TABLE dbo.Person
(
Id INT NOT NULL identity(1,1) primary key,
FullName NVARCHAR(75) NOT NULL,
Age TINYINT NOT NULL,
INDEX NCCI_Person NONCLUSTERED COLUMNSTORE (Id, FullName, Age),
) AS NODE;
CREATE TABLE dbo.FriendsWith(
YearsOfFriendship TINYINT NULL,
INDEX CCI_FriendsWith CLUSTERED COLUMNSTORE,
CONSTRAINT EDG_FriendsWith CONNECTION (Person TO Person)
)
AS EDGE;
The slightly modified example from the SQL Graph, part III – Derived Tables & Views for Heterogeneous Nodes works with different types of Columnstore Indexes as well:
DROP TABLE IF EXISTS dbo.Follows;
DROP TABLE IF EXISTS dbo.Person;
DROP TABLE IF EXISTS dbo.Business;
DROP TABLE IF EXISTS dbo.Company;
CREATE TABLE dbo.Person(
PersonID BIGINT NOT NULL PRIMARY KEY NONCLUSTERED,
FULLNAME NVARCHAR(250) NOT NULL,
INDEX CCI_Person CLUSTERED COLUMNSTORE) AS NODE;
CREATE TABLE dbo.Business(
BusinessID BIGINT NOT NULL PRIMARY KEY CLUSTERED,
BusinessName NVARCHAR(250) NOT NULL UNIQUE,
INDEX CCI_Business NONCLUSTERED COLUMNSTORE (BusinessId, BusinessName) ) AS NODE;
CREATE TABLE dbo.Company(
CompanyID BIGINT NOT NULL PRIMARY KEY NONCLUSTERED,
CompanyName NVARCHAR(250) NOT NULL UNIQUE,
INDEX CCI_Company CLUSTERED COLUMNSTORE ) AS NODE;
CREATE TABLE dbo.Follows(
Since DATETIME2 NULL,
CONSTRAINT EDG_Person_Follows CONNECTION (Person TO Company, Business TO Company)
)
AS EDGE;
INSERT INTO dbo.Person
VALUES (1,'John Doe'), (2,'Andres Martins');
INSERT INTO dbo.Business
VALUES (1,'Foody Company'), (2,'Dressing Inc.');
INSERT INTO dbo.Company
VALUES (1,'Creative Value Company'), (2,'Real Stuff');
INSERT INTO dbo.Follows
SELECT p1.$node_id as from_obj_id,
(SELECT p2.$node_id as to_obj_id FROM dbo.Company p2 WHERE p2.CompanyID = 1),
GETDATE()
FROM dbo.Person p1
WHERE p1.PersonID = 1
INSERT INTO dbo.Follows
SELECT p1.$node_id as from_obj_id,
bus.to_obj_id,
GETDATE()
FROM dbo.Business p1
CROSS APPLY (SELECT p2.$node_id as to_obj_id FROM dbo.Company p2 WHERE p2.CompanyID = 2) as bus
GO
CREATE OR ALTER VIEW dbo.Followers AS
SELECT PersonId as Id, FullName
FROM dbo.Person
UNION ALL
SELECT BusinessId, BusinessName
FROM dbo.Business;
GO
SELECT Followers.ID, Followers.FullName
FROM Followers, Follows, Company
WHERE MATCH(Followers-(Follows)->Company)
AND CompanyName = 'Real Stuff';
Merge DML support as described in SQL Graph, part IV – Merge DML Support (aka MATCH support for the MERGE against the Edges) works without any problem with both Columnstore Indexes:
DROP TABLE IF EXISTS dbo.Follows;
DROP TABLE IF EXISTS dbo.Person;
DROP TABLE IF EXISTS dbo.Business;
DROP TABLE IF EXISTS dbo.Company;
CREATE TABLE dbo.Person(
PersonID BIGINT NOT NULL PRIMARY KEY NONCLUSTERED,
FULLNAME NVARCHAR(250) NOT NULL,
INDEX CCI_Person CLUSTERED COLUMNSTORE) AS NODE;
CREATE TABLE dbo.Business(
BusinessID BIGINT NOT NULL PRIMARY KEY CLUSTERED,
BusinessName NVARCHAR(250) NOT NULL UNIQUE,
INDEX CCI_Business NONCLUSTERED COLUMNSTORE (BusinessId, BusinessName) ) AS NODE;
CREATE TABLE dbo.Company(
CompanyID BIGINT NOT NULL PRIMARY KEY NONCLUSTERED,
CompanyName NVARCHAR(250) NOT NULL UNIQUE,
INDEX CCI_Company CLUSTERED COLUMNSTORE ) AS NODE;
CREATE TABLE dbo.Follows(
Since DATETIME2 NULL,
INDEX CCI_Follows CLUSTERED COLUMNSTORE,
CONSTRAINT EDG_Person_Follows CONNECTION (Person TO Company, Business TO Company)
)
AS EDGE;
INSERT INTO dbo.Person
VALUES (1,'John Doe'), (2,'Andres Martins');
INSERT INTO dbo.Company
VALUES (1,'Creative Value Company'), (2,'Real Stuff');
INSERT INTO dbo.Follows
SELECT p1.$node_id as from_obj_id,
(SELECT p2.$node_id as to_obj_id FROM dbo.Company p2 WHERE p2.CompanyName = 'Real Stuff'),
'2019-01-01'
FROM dbo.Person p1
INSERT INTO dbo.Follows
SELECT p1.$node_id as from_obj_id,
(SELECT p2.$node_id as to_obj_id FROM dbo.Company p2 WHERE p2.CompanyName NOT like 'Real%' ),
'2019-01-01'
FROM dbo.Person p1
SELECT Person.FullName, Follows.Since as FollowsSince, Company.CompanyName
FROM dbo.Follows, dbo.Person, dbo.Company
WHERE MATCH(Person-(Follows)->Company)
MERGE dbo.Follows
USING (SELECT PersonID, FullName
FROM Person)
AS Source
INNER JOIN dbo.Company
ON Company.CompanyName = 'Real Stuff'
ON MATCH(Source-(Follows)->Company)
WHEN MATCHED THEN
UPDATE SET Since = '2001-01-01';
SELECT Person.FullName, Follows.Since as FollowsSince, Company.CompanyName
FROM dbo.Follows, dbo.Person, dbo.Company
WHERE MATCH(Person-(Follows)->Company)
And as for the Shortest Path, described in SQL Graph, part V – Shortest Path it is here to stay for sure.
Warning: Notice that this example with Columnstore Indexes is very inefficient and serves only as a test of a given feature compatibility with the Columnstore Indexes.
DROP TABLE IF EXISTS dbo.Follows;
DROP TABLE IF EXISTS dbo.Person;
CREATE TABLE dbo.Person(
PersonID BIGINT IDENTITY(1,1) NOT NULL PRIMARY KEY NONCLUSTERED ,
FULLNAME NVARCHAR(250) NOT NULL,
INDEX CCI_Person CLUSTERED COLUMNSTORE) AS NODE;
CREATE TABLE dbo.Follows(
Since DATETIME2 NULL,
CONSTRAINT EDG_Person_Follows CONNECTION (Person TO Person),
INDEX CCI_Follows CLUSTERED COLUMNSTORE,
)
AS EDGE;
INSERT INTO dbo.Person
VALUES ('John Doe'),
('Andres Martins'),
('Tyron Mcdonnell'),
('Ellesha Wong'),
('Sumaya Lang'),
('Maxine Williams'),
('Manha Curran'),
('Maysa Hays'),
('Ciaron Roberts'),
('Carole Sanchez'),
('Simrah Freeman'),
('Rickie Devine');
-- John Doe follows almost everyone whos name starts with letters C &vM (but not himself, as obvious)
INSERT INTO dbo.Follows
SELECT p1.$node_id as from_obj_id,
pf.to_obj_id,
GetDate()
FROM dbo.Person p1
CROSS APPLY (SELECT p2.$node_id as to_obj_id FROM dbo.Person p2 WHERE p2.PersonId <> p1.PersonId and (p2.FULLNAME LIKE 'C%' OR p2.FULLNAME LIKE 'M%')) pf
WHERE p1.FULLNAME = 'John Doe';
-- Andres Martins follows Tyron Mcdonnell
INSERT INTO dbo.Follows
SELECT p1.$node_id as from_obj_id,
(SELECT p2.$node_id as to_obj_id FROM dbo.Person p2 WHERE p2.FULLNAME = 'Tyron Mcdonnell'),
GetDate()
FROM dbo.Person p1
WHERE p1.FULLNAME = 'Andres Martins';
-- Tyron follows Ellesha & Sumaya
INSERT INTO dbo.Follows
SELECT p1.$node_id as from_obj_id,
pf.to_obj_id,
GetDate()
FROM dbo.Person p1
CROSS APPLY (SELECT p2.$node_id as to_obj_id FROM dbo.Person p2 WHERE p2.FULLNAME IN ('Ellesha Wong','Sumaya Lang')) pf
WHERE p1.FULLNAME = 'Tyron Mcdonnell';
-- Sumaya follows the same people as John Doe
INSERT INTO dbo.Follows
SELECT p1.$node_id as from_obj_id,
pf.to_obj_id,
GetDate()
FROM dbo.Person p1
CROSS APPLY (SELECT p2.$node_id as to_obj_id FROM dbo.Person p2 WHERE p2.PersonId <> p1.PersonId and (p2.FULLNAME LIKE 'C%' OR p2.FULLNAME LIKE 'M%')) pf
WHERE p1.FULLNAME = 'Sumaya Lang';
-- Maxine follows Manha, Maysa, Simrah & Rickie
INSERT INTO dbo.Follows
SELECT p1.$node_id as from_obj_id,
pf.to_obj_id,
GetDate()
FROM dbo.Person p1
CROSS APPLY (SELECT p2.$node_id as to_obj_id FROM dbo.Person p2 WHERE p2.PersonId <> p1.PersonId and p2.FULLNAME IN ('Manha Curran','Maysa Hays','Simrah Freeman','Rickie Devine')) pf
WHERE p1.FULLNAME = 'Maxine Williams';
--Carole Sanchez follows Andres, Maxine and Simrah
INSERT INTO dbo.Follows
SELECT p1.$node_id as from_obj_id,
pf.to_obj_id,
GetDate()
FROM dbo.Person p1
CROSS APPLY (SELECT p2.$node_id as to_obj_id FROM dbo.Person p2 WHERE p2.PersonId <> p1.PersonId and p2.FULLNAME IN ('Maxine Williams','Andres Martins','Simrah Freeman')) pf
WHERE p1.FULLNAME = 'Carole Sanchez';
SELECT
p1.PersonId,
p1.FULLNAME as StartNode,
LAST_VALUE(p2.FULLNAME) WITHIN GROUP (GRAPH PATH) AS FinalNode,
STRING_AGG(p2.FULLNAME,'->') WITHIN GROUP (GRAPH PATH) AS [Edges Path],
COUNT(p2.PersonId) WITHIN GROUP (GRAPH PATH) AS Levels
FROM
dbo.Person p1,
dbo.Person FOR PATH p2,
dbo.Follows FOR PATH follows
WHERE
MATCH(SHORTEST_PATH(p1(-(follows)->p2)+))
AND p1.FULLNAME = 'John Doe';
Verbose truncation warnings
The long-awaited and quite frankly incredibly long overdue and which is running on the Sql Server 2016 with SP2 and CU 6 & SQL Server 2017 CU12 with the support of Trace Flag 460, and which is enabled by default in Sql Server 2019 is here to support Columnstore Indexes as well without any problem:
DROP TABLE IF EXISTS dbo.[VerboseErrorMessageTest]
GO
CREATE TABLE dbo.[VerboseErrorMessageTest](
[ID] [INT] NOT NULL,
[Code] [varchar](10) NULL,
INDEX CCI_VerboseErrorMessageTest CLUSTERED COLUMNSTORE
)
GO
INSERT INTO dbo.[VerboseErrorMessageTest]
VALUES ('1234567890','11111111111' );
GO
The error message is complete and indicates precisely the value which insertion has failed:
Msg 2628, Level 16, State 1, Line 10 String or binary data would be truncated in table 'ContosoRetailDW.dbo.VerboseErrorMessageTest', column 'Code'. Truncated value: '1111111111'. The statement has been terminated.
Final Thoughts
With the exception of the Memory-Optimized TempDB Metadata the Columnstore Indexes look to be compatible with the rather simple tests I have ran. I honestly expect this incompatibility to be solved rather sooner then later, even though not really in Sql Server 2019.
The Table Variables should get the Columnstore Index support one day, since the Table variable deferred compilation feature is starting to enabling their usage in larger then a couple of rows scenarios.
to be continued with Columnstore Indexes – part 130 (“Columnstore Indexes on Azure SQL DB”)
Hi Niko,
Thanks for the article.
I am planning to test the implication of columnstore index on our Sql server 2016 which has got some DBs of compatibility level 110. Can I use all column store features of Sql Server 2016 on Dbs having 110 compatibility level.
Hi Sidharth,
no, not all of the features of the Sql Server 2016 are available under 110 compatibility level.
You will need to raise it to 130 to get the best of it.
What is the reason you are not going to 120 and beyond ? The new Cardinality Estimation ? If this is the case, you can switch it off with the Database Scoped Configurations!
Best regards,
Niko Neugebauer
Hi Niko, for some reason this statement is giving me an error (SSMS v. 18.9.1):
ALTER SERVER CONFIGURATION SET MEMORY_OPTIMIZED TEMPDB_METADATA = ON;
Error;
“…Incorrect syntax near MEMORY_OPTIMIZED.”
I am on SQL Server version:
Microsoft SQL Server 2019 (RTM-CU9) (KB5000642) – 15.0.4102.2 (X64) Jan 25 2021 20:16:12 Copyright (C) 2019 Microsoft Corporation Developer Edition (64-bit) on Windows 10 Home 10.0 (Build 19041: )
I can’t figure out why, despite a lengthy google search. I have been able to change the setting with sp_configure and a service restart though, so all good – it is, however, vexing why it seems I am the only one having this issue. :-)
Also, in section “Verbose truncation warnings” when running the “VerboseErrorMessageTest” query I get this output, repeated 6 times – very weird… :-)
Msg 2628, Level 16, State 1, Line 199
String or binary data would be truncated in table ‘ContosoRetailDW.dbo.VerboseErrorMessageTest’, column ‘Code’. Truncated value: ‘1111111111’.
Msg 2628, Level 16, State 1, Line 199
String or binary data would be truncated in table ‘ContosoRetailDW.dbo.VerboseErrorMessageTest’, column ‘Code’. Truncated value: ‘1111111111’.
Msg 2628, Level 16, State 1, Line 199
String or binary data would be truncated in table ‘ContosoRetailDW.dbo.VerboseErrorMessageTest’, column ‘Code’. Truncated value: ‘1111111111’.
Msg 2628, Level 16, State 1, Line 199
String or binary data would be truncated in table ‘ContosoRetailDW.dbo.VerboseErrorMessageTest’, column ‘Code’. Truncated value: ‘1111111111’.
Msg 2628, Level 16, State 1, Line 199
String or binary data would be truncated in table ‘ContosoRetailDW.dbo.VerboseErrorMessageTest’, column ‘Code’. Truncated value: ‘1111111111’.
Msg 2628, Level 16, State 1, Line 199
String or binary data would be truncated in table ‘ContosoRetailDW.dbo.VerboseErrorMessageTest’, column ‘Code’. Truncated value: ‘1111111111’.
The statement has been terminated.
The statement has been terminated.
The statement has been terminated.
The statement has been terminated.
The statement has been terminated.
The statement has been terminated.
I thoroughly enjoy reading your posts and share your fascination with columnstore indexes!
Hi Marios,
this looks like a bug – did you submitted it to the support ?
Best regards,
Niko