There is a long time topic that has been quite an important item for the data platforms dealing with a significant amount of data – the approximate calculations.
Anyone who is not familiar with this topic, can visit the Wikipedia page for COUNT DISTINCT PROBLEM.
To summarise the pain points – there are 2 major parts that are targeted to be improved from the COUNT( DISTINCT ) function when implementing Approximate Distinct Count:
– the overall execution time (on bigger tables it can grow into pretty much unreasonable dimensions, such as minutes.
– the overall memory consumption. In order to store the distinct values, while calculating – we shall need an unreasonable amount of memory, and applying hashing with compression while can lower the overall memory consumption will result in the further execution time delays.
One of the more known algorithms for solving this problem is HyperLogLog, and if you read through some of the diverse solutions on the different platforms – you might find a number of mentions of this algorithms or even implementations of some modification of it.
The thing with this or any other algorithm is the magnitude of the speed improvement and the deviation percentage from the real result. It is easy to say that if we lose 5 seconds out of 5 minutes for losing the 25% of the precision should be pretty much unacceptable for the most people, but if we can get a 2-3 times improvement, with amounts of the used memory going from GB into MB area, and loosing under 2% of the results at maximum, that would sound quite different, right ?
In some scenarios – imagine a generic dashboard showing the number of transactions in the large millions/billions where the exact number is irrelevant or can be then consulted in the detailed view, the speed of the dashboard update and the consumed resources can become pretty important. If we can bring the generic view to be close enough to understand the tendency while reaching out for the real-time, this looks to be very interesting.
A couple of months ago, Microsoft has announced the public preview of this feature in the Azure SQL Database, while during the Ignite they have announced that the freshly released CTP 2.0 of the SQL Server 2019 contains the APPROX_COUNT_DISTINCT function. (According to the documentation it is available in the Azure SQL Datawarehouse as well, but while writing this blog post I had no opportunity to confirm this)
Do not take this addition as a new & risky adventure – a huge number of modern platforms has this capacity – Amazon Redshift, Vertica, Oracle, BigQuery, Terradata, Databricks, MemSQL and even the likes of Adobe & many more.
Microsoft Research has been playing with this idea for a number of years, and if you look up the SIGMOD white papers, you will find some very interesting thoughts and criticisms for the Approximate Query Processing.
In the initial offering in Microsoft Data Platform we have received the APPROX_COUNT_DISTINCT function, that is simply used as a similar to COUNT function, as presented below:
SELECT APPROX_COUNT_DISTINCT(l_orderkey) FROM dbo.lineitem;
The current explanation/expectation on the APPROX_COUNT_DISTINCT functionality is that its value should vary under 2% of the total distinct count, while providing a good speedup while using significantly less memory, and right here in this blog I would like to take this to the test.
For the testing purposes I will be using a 10GB & 100GB TPCH sample database, that can be easily generated with the help of the free software, such as the HammerDB.
For the start, lets run a simple query, counting the distinct values within the column l_orderkey consisting of the BIGINT data type against the TPCH 10GB database:
SET STATISTICS TIME ON SELECT APPROX_COUNT_DISTINCT(l_orderkey) FROM dbo.lineitem; SELECT COUNT(DISTINCT l_orderkey) FROM dbo.lineitem;
Both execution plans are presented below:


Both plans are very much similar, with the only noticeable difference would be the elapsed time if we focus over the Hash Match iterator, which for the APPROX_DISTINCT_COUNT takes 0,897 seconds, while for the COUNT(DISTINCT) takes almost the double amount of time – 1.514 seconds.
The memory grant for the APPROX_DISTINCT_COUNT was 24.476 MB while the COUNT(DISTINCT) required 774.280 MB, which represents a gigantic difference, favouring naturally the new kid on the block – the APPROX_DISTINCT_COUNT.
Regarding the calculated results, the first query with the APPROX_DISTINCT_COUNT function delivered 15164704 values, while the actual number of distinct values for the column l_orderkey was 15 Million values, representing a 1.01% difference, well below the advertised 2%!
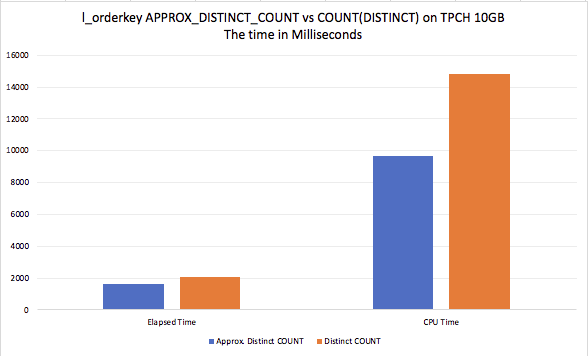 I consider the results to be pretty good, given that we have improved the memory grant for our query around 30 times, the CPU time around 50% while the total execution time was improved over 30%, all in exchange for loosing the precision of 1.01%! At the places where it is acceptable, this is a cool improvement on the table with just 15 million rows.
I consider the results to be pretty good, given that we have improved the memory grant for our query around 30 times, the CPU time around 50% while the total execution time was improved over 30%, all in exchange for loosing the precision of 1.01%! At the places where it is acceptable, this is a cool improvement on the table with just 15 million rows.
 A rather interesting result takes place if we scale our database to 100GB TPCH and run the very same queries – the total elapsed time jumps to 50% difference (from 30%), the CPU execution time difference is kept at 50%, but the memory grant gives the biggest difference ever – those 24.476 MB are still intact for the APPROX_DISTINCT_COUNT, while the COUNT(DISTINCT) asks for just a bit over 11GB ! Besides going through a completely different gateway on the bigger machines, running COUNT(DISTINCT) will bring your system to a full stop way before the same will take place with the APPROX_DISTINCT_COUNT.
A rather interesting result takes place if we scale our database to 100GB TPCH and run the very same queries – the total elapsed time jumps to 50% difference (from 30%), the CPU execution time difference is kept at 50%, but the memory grant gives the biggest difference ever – those 24.476 MB are still intact for the APPROX_DISTINCT_COUNT, while the COUNT(DISTINCT) asks for just a bit over 11GB ! Besides going through a completely different gateway on the bigger machines, running COUNT(DISTINCT) will bring your system to a full stop way before the same will take place with the APPROX_DISTINCT_COUNT.
Regarding the precision – in my tests I did not see the difference going over 1%.
I have tried a number of different data types and the most impressive for me was the handling of the strings (the l_comment column in the dbo.lineitem table), where the results stayed pretty much the same, giving a little edge to the APPROX_COUNT_DISTINCT function over the COUNT(DISTINCT):
SET STATISTICS TIME ON SELECT APPROX_COUNT_DISTINCT(l_comment) FROM dbo.lineitem; SELECT COUNT(DISTINCT l_comment) FROM dbo.lineitem;
Scaling the databases to the 100 GB version of TPCH, would allow to give more significant performance improvement to the APPROX_COUNT_DISTINCT, going from just the edges over to 109 seconds vs 148 seconds difference, while the memory grant is still around those same 24.476 vs 11.224.008 as for the other data types.
Warning
In the original announcement post Microsoft has given quite a number of fair warnings – in 98% of the cases, the precision of the results of the APPROX_COUNT_DISTINCT should be within 2% of the COUNT(DISTINCT) function, but there will be those 2% of the perky cases where things can go very much wrong and the difference can get as much as 20% lower. Yeap, that would be a quite different game, those 20% difference, and I will do here a strong guess, that if you measure your results manually and they are pretty much OK, unless you change a huge amount of data and hence the hash values, there should not be a significant worthing of the difference gap.
There are no guarantees that your queries will get faster, and I guess that in some cases, some of the more complex queries might get even slower.
There are no absolute guarantees that the amounts of requested memory will go down – if you are doing a rather simple COUNT(DISTINCT), then I would say YEAH, you should expect it (but you will have to test it as close to the real production as possible), but if your queries are extremely complex, things can go in a different direction eventually.
Example of Equal Memory Grants
Consider the following query that I have executed against the 100GB TPCH Database :
SELECT YEAR([l_shipdate]) as ShipYear, COUNT( l_orderkey), APPROX_COUNT_DISTINCT(l_orderkey) FROM [dbo].[lineitem] GROUP BY YEAR([l_shipdate]) SELECT YEAR([l_shipdate]) as ShipYear, COUNT( l_orderkey), COUNT(DISTINCT l_orderkey) FROM [dbo].[lineitem] GROUP BY YEAR([l_shipdate])
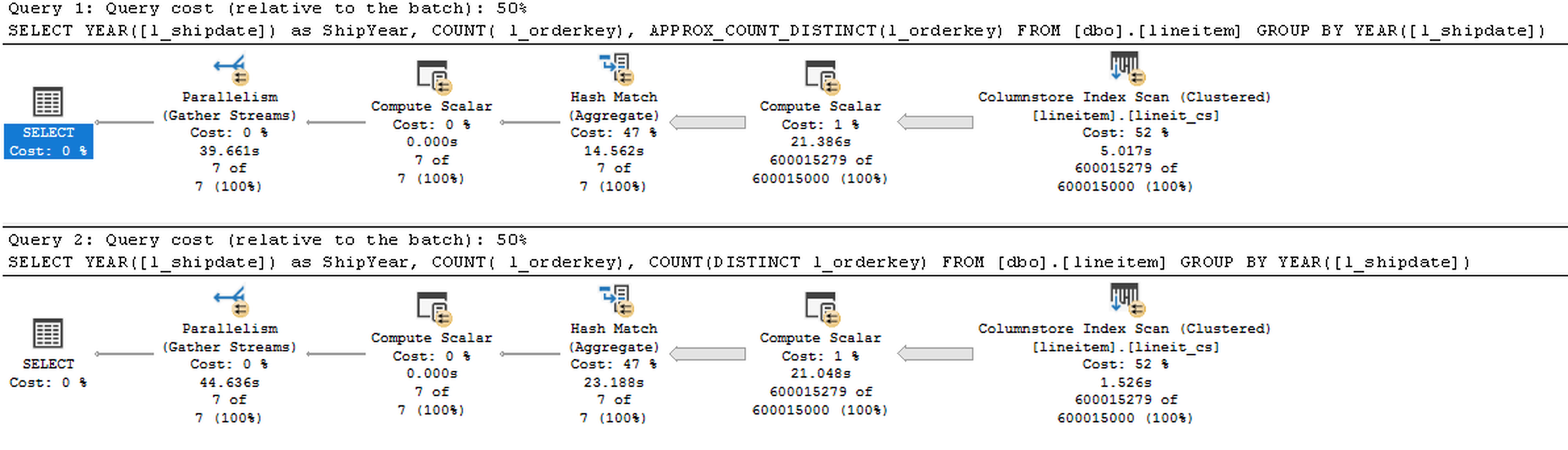
One thing you will instantly notice here, besides the extremely similar execution plans, is that in practice the Memory grants for both queries are equal and requesting around 226 MB, while the execution time for the first query is visibly better, just take a look at the Hash Match (Aggregate) iterator.
Final Thoughts
I love this functionality and so far I have been quite happy with its development, especially since I have not hit any of those 2% of the cases, where the difference between the APPROX_COUNT_DISTINCT & COUNT(DISTINCT) would go up to 20%.
In any case before deciding to substitute COUNT(DISTINCT) with a new APPROX_COUNT_DISTINCT function, a very rigorous testing should be done, confirming that there is time and memory consumption improvements, while the perceived difference of the accounted distinct values is pretty much in the acceptable range, if for some reasons Query Optimiser will decide to follow a different execution, that in the end will be a less efficient one.
In my tests, the bigger the number of rows is (and the biggest one I tested was just 600 Million rows), the better and more evident the performance difference becomes, and that’s why I expect this feature to start shining when your rows are dealing with Billions of rows. Applying this feature against tables with just thousands of rows will not bring you a lot of measurable results, besides a potential headache. :) As a rule of thumb I would say that 10 Million Rows are the very low limit of starting to think about this feature.
The features I want to see in the future releases – Approximate Percentile, Approximate Median, Approximate Top VALUES with some additional space for the Data Quality, such as configurable measuring algorithm and the configurable distance.
In any case I believe that the Approximate Query Processing can win its own space in the not-so-distant future, especially it looks like the rates of data growth are not going very much down…
Thank you Niko for this brilliant post
Hi Parag,
I guess that “thank you” actually goes full way around back to you for the wonderful work.
Best regards,
Niko