This blog post is a part of the whole Batch Mode series, which can be found at the Nikoport Batch Mode page.
This post will focus on some of the initial limitations of the Batch Execution Mode on the Rowstore Indexes.
Please consider this as something that is absolutely expected to change in the future releases, and even though in some cases I seriously ask myself if the fixes will come rather late then soon, I still expect them to solve them all.
In any case without jumping ahead to the conclusion let’s consider what the Batch Execution on the Rowstore Indexes technically is. For me, it is a rather huge improvement over the previous hacks to inject the Batch Mode into the queries with the non-Columnstore Indexes … And given that the infrastructure for the processing of the Hash Match, Window Aggregates, Hash Join, different types of Sort and other operators supporting Batch Execution Mode, the essential 2 missing pieces were:
– Heuristics (and take a look at the Batch Mode – part 3 (“Basic Heuristics and Analysis”) for more details). Deciding when to kick of with the Batch Execution Mode is absolutely essential and this is the part which gives me a lot of fears of the scenarios when it shall kick off absolutely unnecessary, killing of the
– The Index Scan iterator which would kick off with the Batch Mode, eliminating potentially a huge improvement of the data processing, should our tables have a huge number of rows.
Do not get me wrong, there were some stuff that I know and do not to put here, and there must have been tons of details that unless we become programmers at Microsoft – we shall never find out, but I consider those 2 pieces to be the biggest blocks in the implementation.
We have already seen how Batch Mode can successfully turbo-charge the queries and improve them, I have also shown at Batch Mode – part 2 (“Batch Mode on Rowstore in Basics”) an example of TPCH query, making the Batch Mode over the Rowstore Indexes to perform significantly slower, and in this blog post, let’s consider a couple of more scenarios where things do not go exactly the way we expect them to go over, by default.
A good table
Let’s build a “good” table with a Clustered Primary Key on the Rowstore Indexes to which we shall load just 2 million rows:
DROP TABLE IF EXISTS dbo.RowstoreDataTable;
CREATE TABLE dbo.RowstoreDataTable (
C1 BIGINT NOT NULL,
Constraint PK_RowstoreDataTable_Rowstore PRIMARY KEY CLUSTERED (C1),
) WITH (DATA_COMPRESSION = PAGE);
INSERT INTO dbo.RowstoreDataTable WITH (TABLOCK)
SELECT t.RN
FROM
(
SELECT TOP (2000000) ROW_NUMBER()
OVER (ORDER BY (SELECT NULL)) RN
FROM sys.objects t1
CROSS JOIN sys.objects t2
CROSS JOIN sys.objects t3
CROSS JOIN sys.objects t4
CROSS JOIN sys.objects t5
) t
OPTION (MAXDOP 1);
Let’s execute a rather dull aggregation over the only column that it contains and half the result while converting to the Decimal and grouping in the chunks of 10:
SELECT SUM(C1)/2. FROM dbo.RowstoreDataTable GROUP BY C1 % 10
You will find the execution plan of this query below – with all expected iterators running in the Batch Execution Mode:

Everything is shiny – this is the standard we expect to have, if running a similar calculations against a single table, right ?
In-Memory
Let’s build an In-Memory table with the same 2 Million Rows and try running the very same query against it:
ALTER DATABASE Test ADD FILEGROUP [Test_Hekaton] CONTAINS MEMORY_OPTIMIZED_DATA GO ALTER DATABASE Test ADD FILE(NAME = Test_HekatonDir, FILENAME = 'C:\Data\TestXtp') TO FILEGROUP [Test_Hekaton]; GO
DROP TABLE IF EXISTS dbo.HekatonDataTable;
CREATE TABLE dbo.HekatonDataTable (
C1 BIGINT NOT NULL,
Constraint PK_HekatonDataTable_Hekaton PRIMARY KEY NONCLUSTERED (C1)
) WITH (MEMORY_OPTIMIZED = ON, DURABILITY = SCHEMA_AND_DATA);
INSERT INTO dbo.HekatonDataTable
SELECT t.RN
FROM
(
SELECT TOP (2000000) ROW_NUMBER()
OVER (ORDER BY (SELECT NULL)) RN
FROM sys.objects t1
CROSS JOIN sys.objects t2
CROSS JOIN sys.objects t3
CROSS JOIN sys.objects t4
CROSS JOIN sys.objects t5
) t
OPTION (MAXDOP 1);
Running our test query against this table produces the following execution plan in the SQL Server 2019 CTP 2.0:
SELECT SUM(C1)/2. FROM dbo.HekatonDataTable GROUP BY C1 % 10

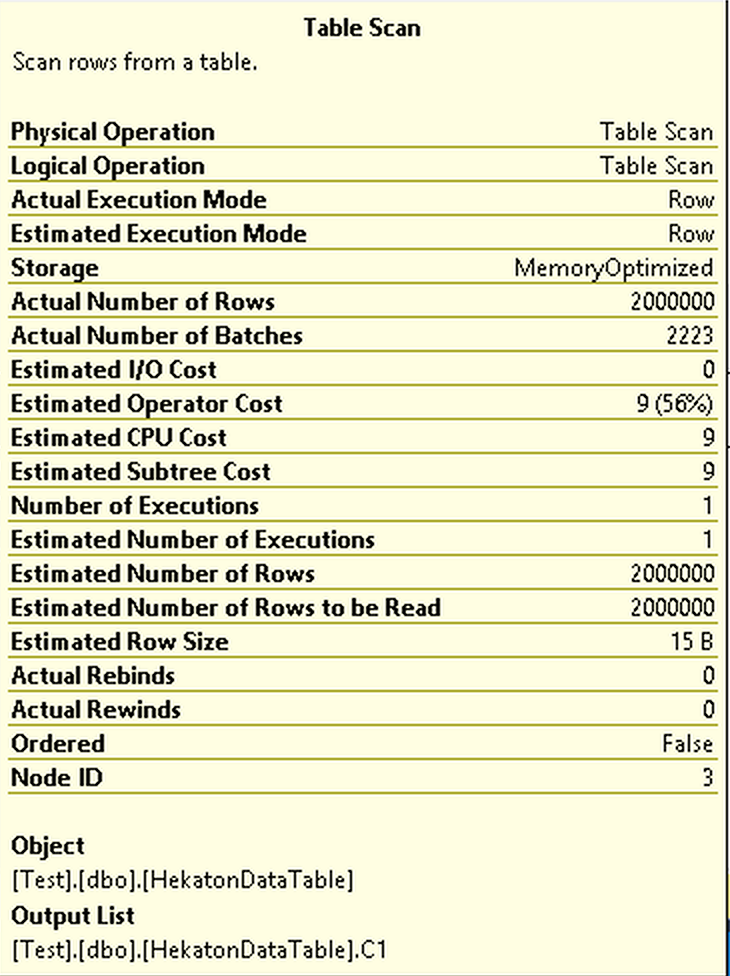 While both Compute Scalar & Hash Match iterators run in the Batch Execution Mode, the Table Scan of the dbo.HekatonDataTable is being executed in the Row Execution Mode, like if we would apply an old hack against it by joining an empty table with a Columnstore Index. The amount of the performance lost will be proportional to the amount of data that is stored in our In-Memory table and it does not really matter if the table is a persisted or a schema-only, to my understanding we won’t be able to escape the traditional slow Row Execution Mode process for data extraction from the In-Memory table and we shall have to pass through the adapter converting the rows into batches for the later Batch Mode execution. This penalty is nothing extraordinary in its nature, but still a rather disappointing situation, given quite honestly the lack of love and investment that after initial 2 releases that In-Memory technology has received. I do not expect this fix to appear rather fast, but in the end, for the consistency there will be a need for it.
While both Compute Scalar & Hash Match iterators run in the Batch Execution Mode, the Table Scan of the dbo.HekatonDataTable is being executed in the Row Execution Mode, like if we would apply an old hack against it by joining an empty table with a Columnstore Index. The amount of the performance lost will be proportional to the amount of data that is stored in our In-Memory table and it does not really matter if the table is a persisted or a schema-only, to my understanding we won’t be able to escape the traditional slow Row Execution Mode process for data extraction from the In-Memory table and we shall have to pass through the adapter converting the rows into batches for the later Batch Mode execution. This penalty is nothing extraordinary in its nature, but still a rather disappointing situation, given quite honestly the lack of love and investment that after initial 2 releases that In-Memory technology has received. I do not expect this fix to appear rather fast, but in the end, for the consistency there will be a need for it.
LOBs
As we all know, LOBs are almost always one of the last feature to be implemented & supported – think Online Rebuilds, even Columnstore Indexes (Clustered) got them in SQL Server 2017, while Nonclustered Columnstore Indexes still do not support them at all. This has probably to do with the amount of changes, complexity and storage requirements, and there won’t be a huge exception for the Batch Execution Mode – consider the following example below where I create a new table that would almost be a copy of the original “good” one, but with a second column C2, that will be using VARCHAR(MAX) and where shall simply store NULLs:
DROP TABLE IF EXISTS dbo.RowstoreWithLOBDataTable;
CREATE TABLE dbo.RowstoreWithLOBDataTable (
C1 BIGINT NOT NULL,
C2 VARCHAR(MAX) NULL,
Constraint PK_RowstoreWithLOBDataTable_RowstoreWithLOB PRIMARY KEY CLUSTERED (C1),
) WITH (DATA_COMPRESSION = PAGE);
INSERT INTO dbo.RowstoreWithLOBDataTable WITH (TABLOCK)
(C1)
SELECT t.RN
FROM
(
SELECT TOP (2000000) ROW_NUMBER()
OVER (ORDER BY (SELECT NULL)) RN
FROM sys.objects t1
CROSS JOIN sys.objects t2
CROSS JOIN sys.objects t3
CROSS JOIN sys.objects t4
CROSS JOIN sys.objects t5
) t
OPTION (MAXDOP 1);
The only thing that will change is that we shall insert a predicate searching for the NOT NULL rows in C2:
SELECT SUM(C1)/2. FROM dbo.RowstoreWithLobDataTable WHERE C2 IS NOT NULL GROUP BY C1 % 10
The execution plan will tell the whole story about how it affects the query, but the point here to make is that not a single iterator in this case will run in the Batch Execution Mode:

One of the very important points here is that it is enough just to search for the data in the LOB column in order to avoid the Batch Execution Mode, you do not have to aggregate on it – and this will be a very big factor for some of the installations I know, where just a simple message column defined with a wrong data type will do a huge damage by not allowing the Batch Execution Mode to kick in.
I do not expect this one to be solved quickly and this worries me much more then just In-Memory tables.
XML
XML ? What on the planet Earth do you mean by that, Niko ?
Now, in the age of JSON, who cares about the XML ?
Well … A lot of application around still do, and they will … :)
Let’s build another test table dbo.RowstoreXMLDataTable with an additional column C2, containing XML, that will contain primitive copy of the C1 row number surrounded by the delightful? <root> tag:
DROP TABLE IF EXISTS dbo.RowstoreXMLDataTable;
CREATE TABLE dbo.RowstoreXMLDataTable (
C1 BIGINT NOT NULL,
C2 XML NOT NULL
Constraint PK_RowstoreXMLDataTable PRIMARY KEY CLUSTERED (C1),
INDEX IX_RowstoreXMLDataTable_C1 NONCLUSTERED (C1) WHERE C1 > 500000
) WITH (DATA_COMPRESSION = PAGE);
INSERT INTO dbo.RowstoreXMLDataTable WITH (TABLOCK)
SELECT t.RN, '' + CAST(t.RN as VARCHAR(10)) + ' '
FROM
(
SELECT TOP (2000000) ROW_NUMBER()
OVER (ORDER BY (SELECT NULL)) RN
FROM sys.objects t1
CROSS JOIN sys.objects t2
CROSS JOIN sys.objects t3
CROSS JOIN sys.objects t4
CROSS JOIN sys.objects t5
) t
OPTION (MAXDOP 1);
Running the summing query over our XML column will result in the following execution plan:
SELECT SUM(C2.value('(/root)[1]', 'bigint' ) )/2.
FROM dbo.RowstoreXMLDataTable
GROUP BY C1 % 10

The execution plan has got it all … The Table Valued Functions, UDX, Stream Aggregates, etc. The only thing missing is the Batch Execution Mode and it ain’t coming back home.
While I am not the biggest fan of XML, it is a still very much needed format and its support should be implemented. It is not as high on the priority list as the LOBs but still pretty neat thing to have.
Spatial
You did not expected it, did not you ?
DROP TABLE IF EXISTS dbo.SpatialDataTable; CREATE TABLE dbo.SpatialDataTable ( c1 int primary key, c2 geometry ); CREATE SPATIAL INDEX IX_SpatialDataTable_c2 ON dbo.SpatialDataTable(c2) WITH ( BOUNDING_BOX = ( xmin=-16, ymin=16, xmax=-9, ymax=21 ), GRIDS = ( LEVEL_3 = HIGH, LEVEL_2 = HIGH ) ); INSERT INTO dbo.SpatialDataTable WITH (TABLOCK) (c1) SELECT t.RN FROM ( SELECT TOP (2000000) ROW_NUMBER() OVER (ORDER BY (SELECT NULL)) RN FROM sys.objects t1 CROSS JOIN sys.objects t2 CROSS JOIN sys.objects t3 CROSS JOIN sys.objects t4 CROSS JOIN sys.objects t5 ) t OPTION (MAXDOP 1);
DECLARE @g GEOMETRY = 'POINT(-112.33 65.4332)'; SELECT SUM( c1 )/2. FROM dbo.SpatialDataTable WITH(INDEX(IX_SpatialDataTable_c2)) WHERE c2.STDistance(@g) <=(30 * 1000) GROUP BY c1 % 10;
Which is pity and given that it is nice feature, totally underused by the Data Professionals:

We still have some iterators execution with the Batch Mode, but the Scanning of the Spatial Indexes is a slow RBAR. :)
Given the complexity of the task and demand for it, I do not expect this one to get fixed until 2038. :)
Interesting here is that we can actually see the last_optimization_level property for the Batch Mode Heuristics to show a real value of 2 ...
Cursors
Nope. Like in the case with Columnstore Indexes.
Full Text
Ha!
Bitmap Filters
At this point we are back to the TPCH drawing board and the query 19 is still here to stay - giving us some of the most incredible headaches, and not because the Batch Mode is not enabled in it - it is.
Below again the Batch Mode over Rowstore and Row Mode over Rowstore TPCH Query 19:
SELECT SUM(L_EXTENDEDPRICE* (1 - L_DISCOUNT)) AS REVENUE
FROM LINEITEM, PART
WHERE (P_PARTKEY = L_PARTKEY AND P_BRAND = 'Brand#12' AND P_CONTAINER IN ('SM CASE', 'SM BOX', 'SM PACK', 'SM PKG') AND L_QUANTITY >= 1 AND L_QUANTITY <= 1 + 10 AND P_SIZE BETWEEN 1 AND 5
AND L_SHIPMODE IN ('AIR', 'AIR REG') AND L_SHIPINSTRUCT = 'DELIVER IN PERSON')
OR (P_PARTKEY = L_PARTKEY AND P_BRAND ='Brand#23' AND P_CONTAINER IN ('MED BAG', 'MED BOX', 'MED PKG', 'MED PACK') AND L_QUANTITY >=10 AND L_QUANTITY <=10 + 10 AND P_SIZE BETWEEN 1 AND 10
AND L_SHIPMODE IN ('AIR', 'AIR REG') AND L_SHIPINSTRUCT = 'DELIVER IN PERSON')
OR (P_PARTKEY = L_PARTKEY AND P_BRAND = 'Brand#34' AND P_CONTAINER IN ( 'LG CASE', 'LG BOX', 'LG PACK', 'LG PKG') AND L_QUANTITY >=20 AND L_QUANTITY <= 20 + 10 AND P_SIZE BETWEEN 1 AND 15
AND L_SHIPMODE IN ('AIR', 'AIR REG') AND L_SHIPINSTRUCT = 'DELIVER IN PERSON')
SELECT SUM(L_EXTENDEDPRICE* (1 - L_DISCOUNT)) AS REVENUE
FROM LINEITEM, PART
WHERE (P_PARTKEY = L_PARTKEY AND P_BRAND = 'Brand#12' AND P_CONTAINER IN ('SM CASE', 'SM BOX', 'SM PACK', 'SM PKG') AND L_QUANTITY >= 1 AND L_QUANTITY <= 1 + 10 AND P_SIZE BETWEEN 1 AND 5
AND L_SHIPMODE IN ('AIR', 'AIR REG') AND L_SHIPINSTRUCT = 'DELIVER IN PERSON')
OR (P_PARTKEY = L_PARTKEY AND P_BRAND ='Brand#23' AND P_CONTAINER IN ('MED BAG', 'MED BOX', 'MED PKG', 'MED PACK') AND L_QUANTITY >=10 AND L_QUANTITY <=10 + 10 AND P_SIZE BETWEEN 1 AND 10
AND L_SHIPMODE IN ('AIR', 'AIR REG') AND L_SHIPINSTRUCT = 'DELIVER IN PERSON')
OR (P_PARTKEY = L_PARTKEY AND P_BRAND = 'Brand#34' AND P_CONTAINER IN ( 'LG CASE', 'LG BOX', 'LG PACK', 'LG PKG') AND L_QUANTITY >=20 AND L_QUANTITY <= 20 + 10 AND P_SIZE BETWEEN 1 AND 15
AND L_SHIPMODE IN ('AIR', 'AIR REG') AND L_SHIPINSTRUCT = 'DELIVER IN PERSON')
OPTION (USE HINT('DISALLOW_BATCH_MODE'));
This is the query for the Batch Execution Mode:
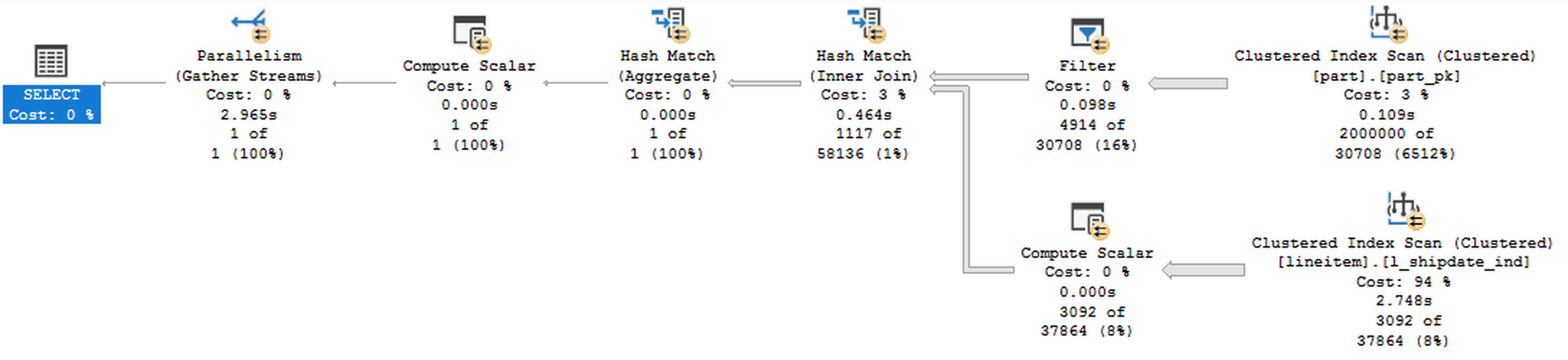
, while the faster query which is using the Row Execution Mode:

The problem in the query above is that the Bitmap Filters are executed at the very late stage, after processing the regular filters, with all the rows being directly read from the dbo.part & dbo.lineitem tables - contrary to the Rowstore Indexes with the Row Execution Mode and being different to the situation of the Columnstore Indexes.
Strings are "kind of evil" and the Batch Mode is not their best friend, especially right now. If you are looking to test your workload right away with CTP 2.0, while working with a lot of strings (and oh so many Data Warehouses do that), please consider waiting a little bit before making a final decision, you will not regret it.
I have been told by Microsoft that this is one of the issues that is being worked on and that it is very much expected to be resolved before the RTM of the SQL Server 2019.
Final Thoughts
The limitations of the Batch Execution Mode on Non-Columnstore Indexes is mostly based on not-Rowstore data sources and their scans. There are some noticeable exceptions, such as LOBs, and they should be kept pretty much in mind.
Mostly those limitations are delighters, and not getting an extra snack is not the same as getting almost entire one.
Given that Microsoft expects the String Filters to get a significant improvement before the RTM, I feel pretty much comfortable looking into the future.
While of course, those perky LOBs, disabling the Batch Execution Mode are nothing short of being fine ... But I am a believer that this limitation will fade away in a relatively near future. (I have no such feedback/information from Microsoft, but I see a huge potential in the massive text processing that will eventually gain its space on SQL Server & Azure SQL Database).
The bottom line is to remember that the feature is called Batch Mode on Rowstore (and if you are not using Row Storage, you are most probably out of luck).
to be continued with Batch Mode – part 5 ("TPC-H Queries")
I am sad to report that, as of SQL2022, the issue with batch mode bitmap filters still applies for binary data types. It runs something like 15x slower than row mode, probably depending on the table size on the bitmap probe side.