Continuation from the previous 129 parts, the whole series can be found at https://www.nikoport.com/columnstore/.

 Almost 2 years ago (22nd of March 2018) in Columnstore Indexes – part 121 (“Columnstore Indexes on Standard Tier of Azure SQL DB”) I have already mentioned that Columnstore Indexes were available in Azure SQL Database in Standard 3 (S3) edition and higher, while people I meet keep on mentioning and believing that in order to get Columnstore Indexes one needs to use Premium editions.
Almost 2 years ago (22nd of March 2018) in Columnstore Indexes – part 121 (“Columnstore Indexes on Standard Tier of Azure SQL DB”) I have already mentioned that Columnstore Indexes were available in Azure SQL Database in Standard 3 (S3) edition and higher, while people I meet keep on mentioning and believing that in order to get Columnstore Indexes one needs to use Premium editions.
Since that blog post a lot of time has passed and in the mean time we have got new tiers with new generations of provisioned General Purpose tiers (Generation 4, Generation 5, FSv2 Series & M Series) appearing, plus the Serverless Tier and not to forget the very promising Hyperscale tier … besides the Azure SQL Database Managed Instance of course, which has already been generally available for some time and the good old Elastic Pools which were never mentioned in original article.
 Let’s find out how it looks today, at the very end of the 2019 calendar year in this blog post, taking step by step on the creation and basic steps with each of the available above mentioned generations/types of Azure SQL Database, to make sure that we can be successful with running Columnstore Indexes.
Let’s find out how it looks today, at the very end of the 2019 calendar year in this blog post, taking step by step on the creation and basic steps with each of the available above mentioned generations/types of Azure SQL Database, to make sure that we can be successful with running Columnstore Indexes.
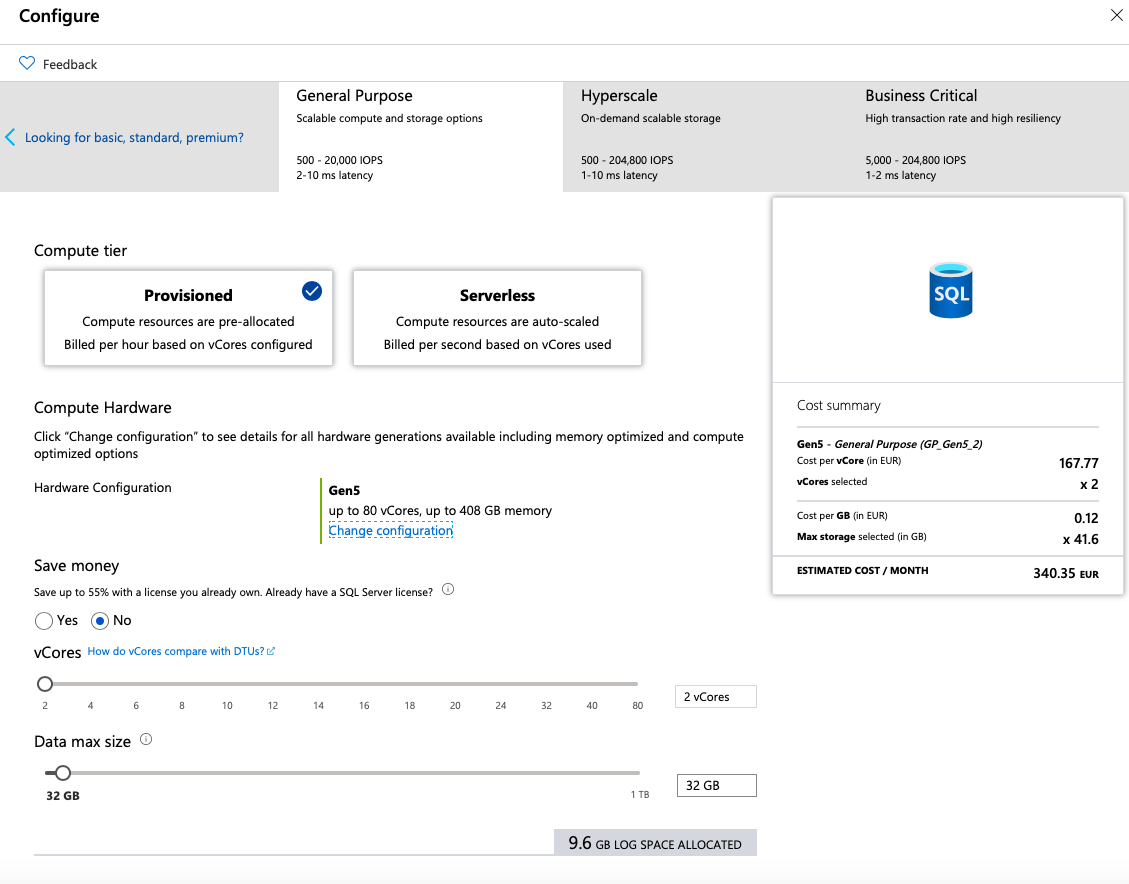
When creating a new Azure SQL Database the following options are presented (and you can see them on the right side of this text) and the clear message there is that default choice are the new provisioned tiers, while the older, DTU-based tiers (basic, standard & premium) are a kind of hidden from the initial screen and one needs to click on the top left corner in order to achieve them.
Here we shall be considering only General Purpose tiers that promise to deliver the latency between 2-10 milliseconds and from 500 to 20000 IOPS. Given that the Business Critical is a “moral child of the Premium offering” (yeah, that is definitely my point of view) and delivers much higher SLA and performance (1-2 milliseconds and 5000 to 204800 IOPs), if it works for General Purpose – it will work for the Business Critical tiers as well.
Generation 4
 Besides already available announcement that Generation 4 CPUs of the Azure SQL Database is approaching the end of life (see Azure SQL Database Gen 4 hardware approaching end of life in 2020) and become unsupported in January 2023, we can still create and people still use Generation 4 of the CPUs.
Besides already available announcement that Generation 4 CPUs of the Azure SQL Database is approaching the end of life (see Azure SQL Database Gen 4 hardware approaching end of life in 2020) and become unsupported in January 2023, we can still create and people still use Generation 4 of the CPUs.
After successfully creating a GEN 4 1 CPU core Azure SQL Database, I connected to the instance and executed the following script, which is a simple copy of the original script from the Columnstore Indexes – part 121 (“Columnstore Indexes on Standard Tier of Azure SQL DB”) blog post.
DROP TABLE IF EXISTS dbo.SampleDataTable
CREATE TABLE dbo.SampleDataTable (
C1 BIGINT NOT NULL,
INDEX CCI_SampleDataTable CLUSTERED COLUMNSTORE
);
INSERT INTO dbo.SampleDataTable WITH (TABLOCK)
SELECT
t.RN
FROM
(
SELECT TOP (10 * 1048576) ROW_NUMBER()
OVER (ORDER BY (SELECT NULL)) RN
FROM sys.objects t1
CROSS JOIN sys.objects t2
CROSS JOIN sys.objects t3
CROSS JOIN sys.objects t4
CROSS JOIN sys.objects t5
) t
OPTION (MAXDOP 1);
It was executed without any problem, giving us a new table with Clustered Columnstore Index, 10485760 rows and 10 fully compressed Row Groups, which you can consult by executing the following query:
select *
FROM sys.dm_db_column_store_row_group_physical_stats;

Running a simply aggregation query produces the following execution plan –
SELECT C1 % 5, SUM(C1) as SomeSum
FROM dbo.SampleDataTable
GROUP By C1 % 5;
![]()
with a beautiful icon (LOL – non-existent) of the Columnstore Index Scan, meaning that we really do process a Clustered Columnstore Index here.
I confess that at this point I was pretty much intrigued
Running the query against the sys.dm_os_performance_counters DMV will give us the idea about the target and the total memory available to our Azure SQL Database instance:
SELECT object_name as ObjectName, counter_name as CounterName, CAST(cntr_value / 1024. as DECIMAL(9,2)) as MaxMemoryInMB
FROM sys.dm_os_performance_counters
WHERE counter_name IN ('Total Server Memory (KB)', 'Target Server Memory (KB)');

You can see on the picture above the numbers – 4.5 GB for the target available and the 1 GB for the total memory of our Azure SQL Database instance. These numbers correspond somewhere in the middle between S2 and S3 instance and they might be the precisely at the tipping point that Microsoft considers to be viable for the Columnstore Technology. The target memory to consider are (5.8 GB (S3) > 4.5 GB (Gen4_1) > 3.0 GB (S2)) while a similar model will be followed for the total server memory as well (2.2 GB (S3) > 1.0 GB (Gen4_1) > 0.5 GB (S2)).
Generation 5
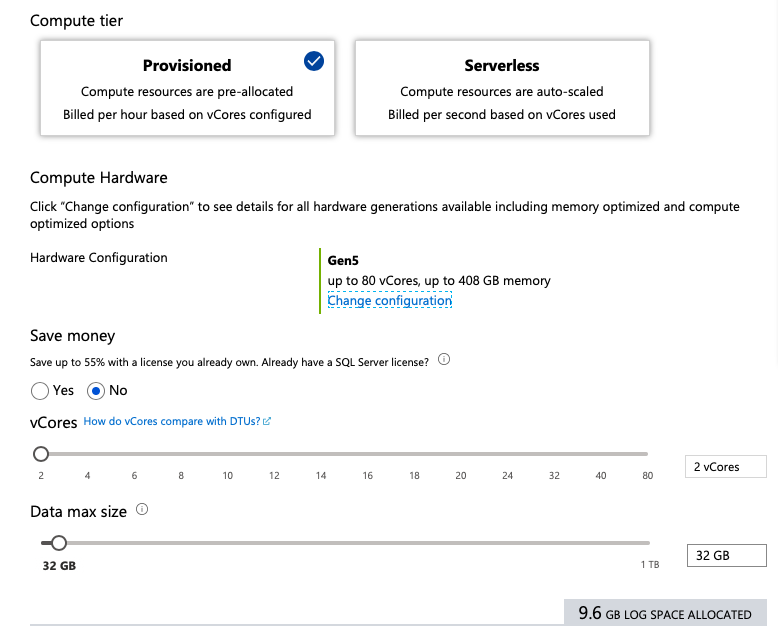 While officially Microsoft gives 5.1 GB per vCore for Generation 5 versus 7.0 GB per vCore for Generations 4, it is declared as the present and the near-term future for Azure SQL Database. From my personal point of view, the list of disadvantages of the Generation 5 is significant (besides the already mentioned RAM limitations, the frequency goes down from 2.4 GHz to 2.3 GHz, hyper-threading versus the physical cores), the most significant limitations is that attribution of the cores is based on multiplier of 2 – meaning that you can’t have 1 vCPU core or 3 vCPU cores for your application – you will have to work with 2, 4, 6, 8 .. 80 vCores, which will result in significantly increased costs (2 times).
While officially Microsoft gives 5.1 GB per vCore for Generation 5 versus 7.0 GB per vCore for Generations 4, it is declared as the present and the near-term future for Azure SQL Database. From my personal point of view, the list of disadvantages of the Generation 5 is significant (besides the already mentioned RAM limitations, the frequency goes down from 2.4 GHz to 2.3 GHz, hyper-threading versus the physical cores), the most significant limitations is that attribution of the cores is based on multiplier of 2 – meaning that you can’t have 1 vCPU core or 3 vCPU cores for your application – you will have to work with 2, 4, 6, 8 .. 80 vCores, which will result in significantly increased costs (2 times).
The list of advantages is pretty slim though important, including accelerated networking, more potential cores to apply (up to 80 versus 24 vCPU cores on Generation 4 at maximum), higher limit for the total RAM to get (408 GB vs 168 GB for Generation 4).
After scaling my test Azure SQL Database instance from Generation 4 with 1 vCPU core to Generation 5 with 2 vCPU cores – I ran the same basic script to recreate test table with a Clustered Columnstore Index:
DROP TABLE IF EXISTS dbo.SampleDataTable
CREATE TABLE dbo.SampleDataTable (
C1 BIGINT NOT NULL,
INDEX CCI_SampleDataTable CLUSTERED COLUMNSTORE
);
INSERT INTO dbo.SampleDataTable WITH (TABLOCK)
SELECT
t.RN
FROM
(
SELECT TOP (10 * 1048576) ROW_NUMBER()
OVER (ORDER BY (SELECT NULL)) RN
FROM sys.objects t1
CROSS JOIN sys.objects t2
CROSS JOIN sys.objects t3
CROSS JOIN sys.objects t4
CROSS JOIN sys.objects t5
) t
OPTION (MAXDOP 1);
and the rest of tests which just work without any problem.
Looking just a bit under the hood (and you know, that Columnstore Indexes are little hungry beasts), we can check the Total & the Target amounts of memory attributed to our instance:
SELECT object_name as ObjectName, counter_name as CounterName, CAST(cntr_value / 1024. as DECIMAL(9,2)) as MaxMemoryInMB
FROM sys.dm_os_performance_counters
WHERE counter_name IN ('Total Server Memory (KB)', 'Target Server Memory (KB)');

I can observe in this case 7.6 GB of RAM for the target memory which are good news meaning improvement is well proportional to the number of cores that we are using in our Azure SQL Database (2 in this case and for the 1 vCPU core of the Generation 4 we had just 4.5 GB). The operational memory in this case is obviously enough for the Columnstore Indexes.
Generation FSv2
Announced in the beginning of April of 2019 (New memory and compute optimized hardware options in Azure SQL Database), the FSv2 option is a huge juggernaut which should satisfy some of the most demanding workloads.
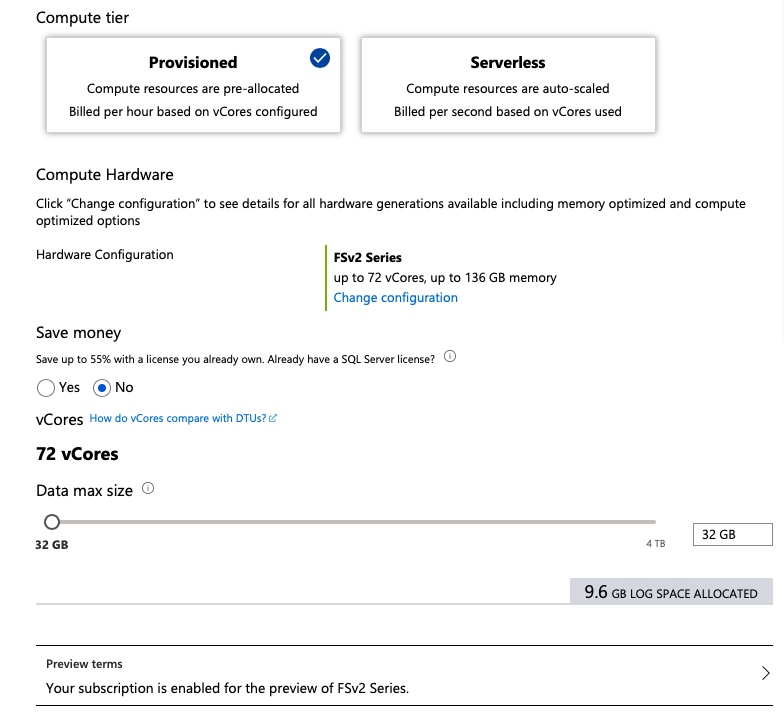 FSv2 provides compute optimized hardware for the workloads that needs to go in some cases beyond what Generation 5 can offer, with the only uncustomizable option of the 72 vCores, it provides less memory then Generation 5 or the M-series (Memory-Optimised), but it will provide higher frequency and pure calculation throughput.
FSv2 provides compute optimized hardware for the workloads that needs to go in some cases beyond what Generation 5 can offer, with the only uncustomizable option of the 72 vCores, it provides less memory then Generation 5 or the M-series (Memory-Optimised), but it will provide higher frequency and pure calculation throughput.
Given that we have 72 vCores, I guess the only question is not if we are really able to use Columnstore Indexes, but mostly how much memory do we have available:
SELECT object_name as ObjectName, counter_name as CounterName, CAST(cntr_value / 1024. as DECIMAL(9,2)) as MaxMemoryInMB
FROM sys.dm_os_performance_counters
WHERE counter_name IN ('Total Server Memory (KB)', 'Target Server Memory (KB)');

Very nice 120 GB are available in this case, but dividing this number through the number of vCPU cores we shall get just 1.6 GB per vCPU core, being extremely small number to be precise, meaning that even if you are running your queries with DOP (Degree Of Parallelism) beyond 64, do not expect real-life Columnstore Indexes to benefit from this configuration – they will force your parallelism down, because of the available memory.
Generation M
![]() According to Microsoft, Memory-Optimised Generation (aka Generation M) provides up to 29 GB of RAM per vCpu core and up to 128 vcores, which potentially allows to reach 3.68 TB of RAM. Yeah, this is really impressive.
According to Microsoft, Memory-Optimised Generation (aka Generation M) provides up to 29 GB of RAM per vCpu core and up to 128 vcores, which potentially allows to reach 3.68 TB of RAM. Yeah, this is really impressive.
In order to get it functioning, one needs to host their Azure SQL Database in the respective supported region and besides opening an additional support ticket – also must be running Business Critical Tier. Given the known parameters and Business Critical Tier – Columnstore Indexes will work there without any problem at all.
Serverless
Generation 5
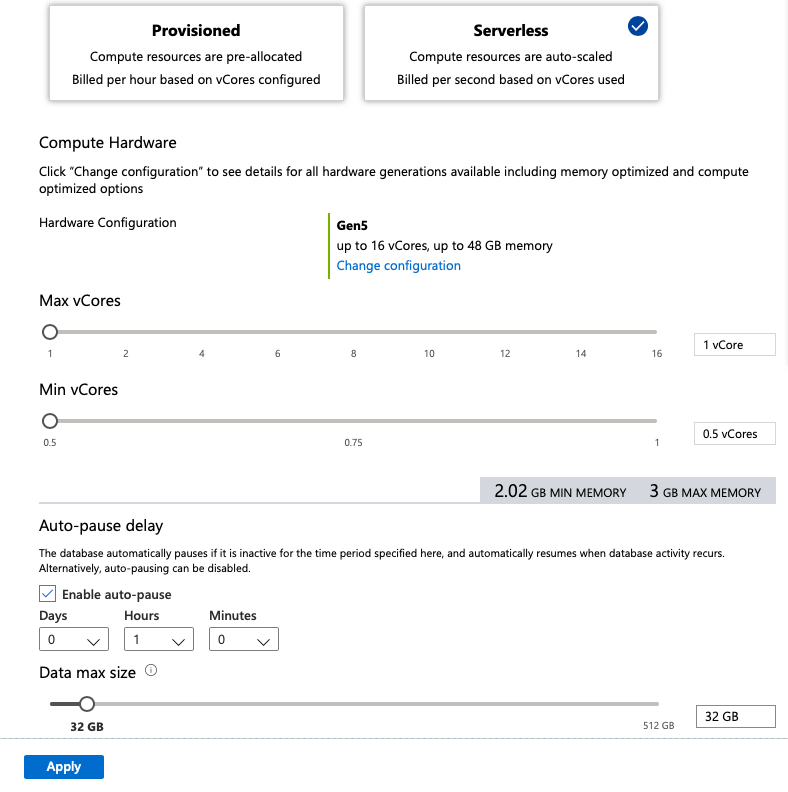 With the appearance of the Azure SQL Database Serverless we received a possibility to get an automated pause/resume functionality for the Azure SQL Database PaaS offering. The only currently available generation is the Generation 5 and it allows us to scale from 1 vCPU to 16 vCPU cores (Maximum performance) and to automatically lower to 0.5 vCPU to 2 vCPU cores (Minimum performance). Those 2 variable parameters permit us to control the amount of memory and computation that will be attributed to our instance . Plus the Auto-pause delay with the current granularity of up to 1 hour (I expect this parameter to lower down to minutes in 2020).
With the appearance of the Azure SQL Database Serverless we received a possibility to get an automated pause/resume functionality for the Azure SQL Database PaaS offering. The only currently available generation is the Generation 5 and it allows us to scale from 1 vCPU to 16 vCPU cores (Maximum performance) and to automatically lower to 0.5 vCPU to 2 vCPU cores (Minimum performance). Those 2 variable parameters permit us to control the amount of memory and computation that will be attributed to our instance . Plus the Auto-pause delay with the current granularity of up to 1 hour (I expect this parameter to lower down to minutes in 2020).
Also notice that current there is no Business Critical offering, just the General Availability.
For the minimum test of the Columnstore Indexes supportability, I have chosen the 0.5 vCPU to 1 vCPU cores (min & max) which will allow the variability between 2.02 GB to 3 GB (officially).
The usual workload test executes fast (since it is pretty much optimised) and works without any problem, but let us check the amount of available memory to our Azure SQL Database
SELECT object_name as ObjectName, counter_name as CounterName, CAST(cntr_value / 1024. as DECIMAL(9,2)) as MaxMemoryInMB
FROM sys.dm_os_performance_counters
WHERE counter_name IN ('Total Server Memory (KB)', 'Target Server Memory (KB)');

In fact we have 1.838 GB which corresponds to 2.02 GB of RAM for the Service providers (since they do not divide numbers through 1024 but through 1000).
Comparing to Azure SQL Database DTU-based Editions S2 (Standard 2) which has 3 GB of RAM but does not allow Columnstore Indexes gives a strange feeling of something being more important at the old tier, with maybe virtualisation not allowing to throttle it in a good way and not the memory being the problem, but in any case for the slowest Serverless instance we can count on Columnstore Indexes without any problems.
Hyperscale
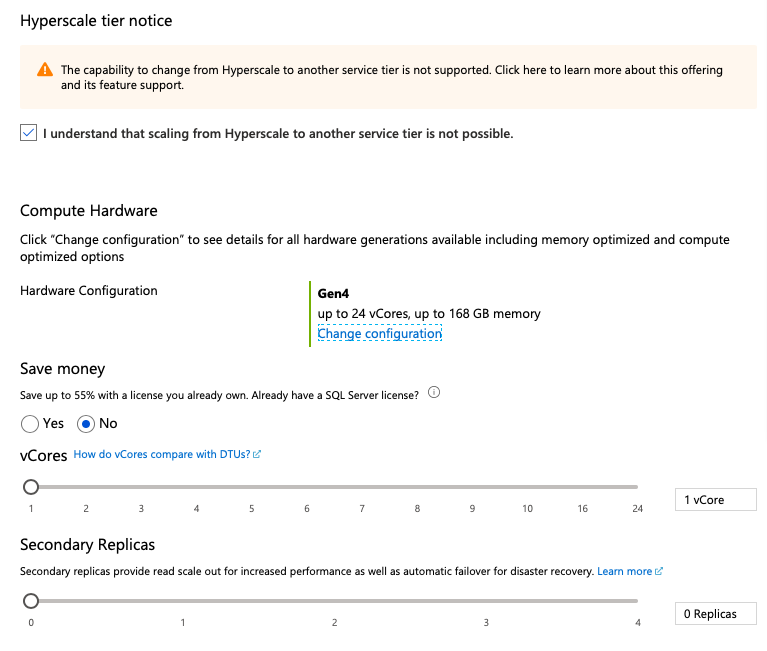 The Hyperscale tier of Azure SQL Database is focused on improving OLTP performance allowing databases to grow up to 200 TB. After rescaling our database to Hyperscale (and this is currently a one-way direction, meaning that we won’t be able to get back to the regular or to Serverless Azure SQL Database), I simply re-executed the test script for a table creation with a Clustered Columnstore Index:
The Hyperscale tier of Azure SQL Database is focused on improving OLTP performance allowing databases to grow up to 200 TB. After rescaling our database to Hyperscale (and this is currently a one-way direction, meaning that we won’t be able to get back to the regular or to Serverless Azure SQL Database), I simply re-executed the test script for a table creation with a Clustered Columnstore Index:
DROP TABLE IF EXISTS dbo.SampleDataTable
CREATE TABLE dbo.SampleDataTable (
C1 BIGINT NOT NULL,
INDEX CCI_SampleDataTable CLUSTERED COLUMNSTORE
);
INSERT INTO dbo.SampleDataTable WITH (TABLOCK)
SELECT
t.RN
FROM
(
SELECT TOP (10 * 1048576) ROW_NUMBER()
OVER (ORDER BY (SELECT NULL)) RN
FROM sys.objects t1
CROSS JOIN sys.objects t2
CROSS JOIN sys.objects t3
CROSS JOIN sys.objects t4
CROSS JOIN sys.objects t5
) t
OPTION (MAXDOP 1);
It works without any problems.
Checking on the Total and Target Server memory amounts gives the picture we have had for the regular Azure SQL Database offering, that was using the Generation 4 vCPU cores
SELECT object_name as ObjectName, counter_name as CounterName, CAST(cntr_value / 1024. as DECIMAL(9,2)) as MaxMemoryInMB
FROM sys.dm_os_performance_counters
WHERE counter_name IN ('Total Server Memory (KB)', 'Target Server Memory (KB)');

Scaling to Generation 5 with 2 vCPU cores and checking on the result will provide us with the similar results as in the case of regular single Azure SQL Database as well:
SELECT object_name as ObjectName, counter_name as CounterName, CAST(cntr_value / 1024. as DECIMAL(9,2)) as MaxMemoryInMB
FROM sys.dm_os_performance_counters
WHERE counter_name IN ('Total Server Memory (KB)', 'Target Server Memory (KB)');

Elastic Pools
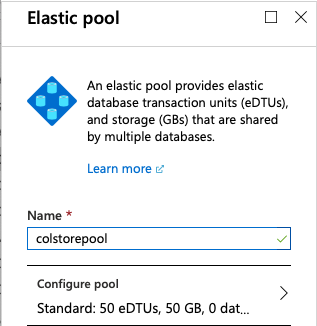 Given that we have discovered that every single Azure SQL Database Offering supports Columnstore Indexes, it is time to get back and check with the Elastic Pools on their support of the Standard Databases with an old DTU models (in Azure SQL Database Elastic Pools terms the units of configuration and consumption are called eDTUs, as elastic DTUs). This is in practice the item that has escaped my original post about Columnstore Indexes and Azure SQL Databases.
Given that we have discovered that every single Azure SQL Database Offering supports Columnstore Indexes, it is time to get back and check with the Elastic Pools on their support of the Standard Databases with an old DTU models (in Azure SQL Database Elastic Pools terms the units of configuration and consumption are called eDTUs, as elastic DTUs). This is in practice the item that has escaped my original post about Columnstore Indexes and Azure SQL Databases.
Let’s start with configuring the most simple Azure SQL Database Elastic Pool with just 50 eDTUs – corresponding to the Azure SQL Database with just 50 DTUs at maximum (meaning that it will max out at Standard 2 tier (S2)).
Let’s connect to the database that was put inside this pool and try to create a new table with a Clustered Columnstore Index:
DROP TABLE IF EXISTS dbo.SampleDataTable
CREATE TABLE dbo.SampleDataTable (
C1 BIGINT NOT NULL,
INDEX CCI_SampleDataTable CLUSTERED COLUMNSTORE
);
![]()
The error message is very clear – we can’t do that and it makes whole lot of sense: with S2 Azure SQL Database we are unable to create Columnstore Indexes.
Scaling up to 100 eDTUs will result in solution of this problem, even though the “per-database” setting will remain by default set on 50 DTUs at maximum. We still have enough resources in our paid pool to spend and so database can execute the task without any problem.
DROP TABLE IF EXISTS dbo.SampleDataTable
CREATE TABLE dbo.SampleDataTable (
C1 BIGINT NOT NULL,
INDEX CCI_SampleDataTable CLUSTERED COLUMNSTORE
);
INSERT INTO dbo.SampleDataTable WITH (TABLOCK)
SELECT
t.RN
FROM
(
SELECT TOP (10 * 1048576) ROW_NUMBER()
OVER (ORDER BY (SELECT NULL)) RN
FROM sys.objects t1
CROSS JOIN sys.objects t2
CROSS JOIN sys.objects t3
CROSS JOIN sys.objects t4
CROSS JOIN sys.objects t5
) t
OPTION (MAXDOP 1);
This scripts will be executed successfully.
Checking on our service-level objectives will give us the information that we are in a pool
SELECT *
FROM sys.database_service_objectives

Checking on the memory settings, like previously with all Azure SQL Database offerings will show us the following values:
SELECT object_name as ObjectName, counter_name as CounterName, CAST(cntr_value / 1024. as DECIMAL(9,2)) as MaxMemoryInMB
FROM sys.dm_os_performance_counters
WHERE counter_name IN ('Total Server Memory (KB)', 'Target Server Memory (KB)');

Yeah, 19 GB of RAM sounds a kind of solid plan to deal with the Columnstore Indexes on the build side. :)
Notice that this 100 eDTU will come with the price of almost 50% of the cost, but if you are an ISV and optimize by putting Databases into a pool, you just might be getting some serious winning out of it.
So here it is – you need to start with the Elastic Pools and Columnstore Indexes, you will need to start with at least 100 eDTUs, or better consider migrating to the modern generations offerings.
Azure SQL Database Managed Instance
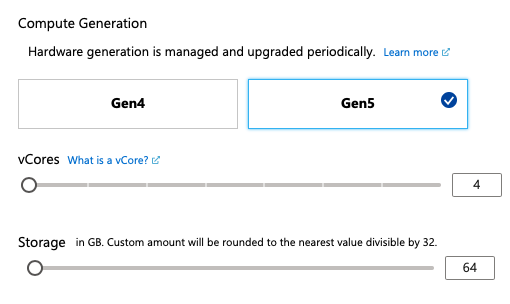 Deployment of any Azure SQL Database Managed Instance implies the choice between Generation 4 and Generation 5 of the vCPU cores with the minimum numbers being 8 for the Gen4 and 4 for the Gen5 respectively. By all previous tests it would get the necessary processing power and the RAM amounts to work successfully with Columnstore Indexes and that’s the reason I am just mentioning it here shortly without going into further detailed tests.
Deployment of any Azure SQL Database Managed Instance implies the choice between Generation 4 and Generation 5 of the vCPU cores with the minimum numbers being 8 for the Gen4 and 4 for the Gen5 respectively. By all previous tests it would get the necessary processing power and the RAM amounts to work successfully with Columnstore Indexes and that’s the reason I am just mentioning it here shortly without going into further detailed tests.
I decided to update this segment with the information I obtained on a Managed Instance with Generation 5 with 4 vCPU cores.
The script below works without any problem, of course:
DROP TABLE IF EXISTS dbo.SampleDataTable
CREATE TABLE dbo.SampleDataTable (
C1 BIGINT NOT NULL,
INDEX CCI_SampleDataTable CLUSTERED COLUMNSTORE
);
INSERT INTO dbo.SampleDataTable WITH (TABLOCK)
SELECT
t.RN
FROM
(
SELECT TOP (10 * 1048576) ROW_NUMBER()
OVER (ORDER BY (SELECT NULL)) RN
FROM sys.objects t1
CROSS JOIN sys.objects t2
CROSS JOIN sys.objects t3
CROSS JOIN sys.objects t4
CROSS JOIN sys.objects t5
) t
OPTION (MAXDOP 1);
and naturally it runs successfully without any problem.
Checking on the server memory with the usual script
SELECT object_name as ObjectName, counter_name as CounterName, CAST(cntr_value / 1024. as DECIMAL(9,2)) as MaxMemoryInMB
FROM sys.dm_os_performance_counters
WHERE counter_name IN ('Total Server Memory (KB)', 'Target Server Memory (KB)');

As you can see on the picture above, we have 16.5 GB of Target Server Memory, which is definitely more than enough for good number of Columnstore Indexes operations.
Final Thoughts
It is incredibly awesome to know that Columnstore Indexes are first-class citizens in Azure SQL Database in all editions (just be sure to run S3 on Azure SQL Database or 100+ eDTUs on Elastic Pools for elder offerings). It does not mean that if you pick up a wide table it will perform in a scalable way in all editions – because memory pressure might shred your Row Groups into smaller chunks which will end requiring incredibly bigger amount of CPU work to get done, but it won’t prevent you from trying.
From my side – I feel really happy with the recent developments and I just wish the In-Memory to become the first class citizen in Azure SQL Database as well … In-Memory with Columnstore that is as well … :)
to be continued with Columnstore Indexes – part 131 (“Rebuilding Rowstore Indexes ONLINE”)
Hi Niko, not sure why I missed this blog post of yours, but I have some findings:
Difference between Gen4 and Gen5 is even worse: the raw throughput (data and log io) is half on Gen5. Probably because on 1 physical cpu Gen 5 is counted as twice due to hyperthreading. So pay twice the money, for half the io.
By the way, did you read this comment?
https://techcommunity.microsoft.com/t5/azure-sql-database/scaling-up-an-iot-workload-using-an-m-series-azure-sql-database/ba-p/1106271
“In Azure SQL Database, the need for this specific type of columnstore index maintenance is much reduced, and in many cases eliminated altogether. As part of several recent improvements in columnstore indexes, the background tuple mover thread now automatically merges smaller compressed rowgroups into larger compressed rowgroups.”
Hi Johannes,
thank you for the comment.
I agree with the idea of the hyperthreading in Gen 5 not doing exactly what the most people expect for the resource management … but that’s a bigger topic then just a random comment.
Regarding the Columnstore Index maintenance on Azure:
I have been presenting about the Aggressive Tuple Mover for some time, but yeah – its time to blog about it …
It has been released at the end of 2018 on Azure SQL DW first … There are some interesting details about it, so I better publish them in the next couple of weeks.
Best regards,
Niko
Hi,
what about CCI with secondary (rowstore) indexes on S3 – is it working now?
I part 121 you wrote (if I understood it correctly) that those would only work in Premium instances.
Hi TH,
In http://www.nikoport.com/2018/03/22/columnstore-indexes-part-121-columnstore-indexes-on-standard-tier-of-azure-sql-db/ I have written that CCI works fine in S3 and later Standard Editions and this has not changed so far.
Best regards,
Niko