Continuation from the previous 120 parts, the whole series can be found at https://www.nikoport.com/columnstore/.
Yesterday, Kevin Farlee (Program Manager for Columnstore Indexes) announced that Columnstore Indexes have finally found their way into Standard Tier of the Azure SQL Database, I decided not to delay the research and dive straight into available solution.
After the official announcement that COlumnstore Indexes became part of All (Web,Standard,Express & even Local) editions for SQL Server in November of 2016, it was only a question of time when Microsoft Data Platform leadership would find resources & time to make something similar on their prime cloud offer – the Azure SQL Database and without any doubt, I am incredibly grateful to the effort that Kevin Farlee lead.
The Setup
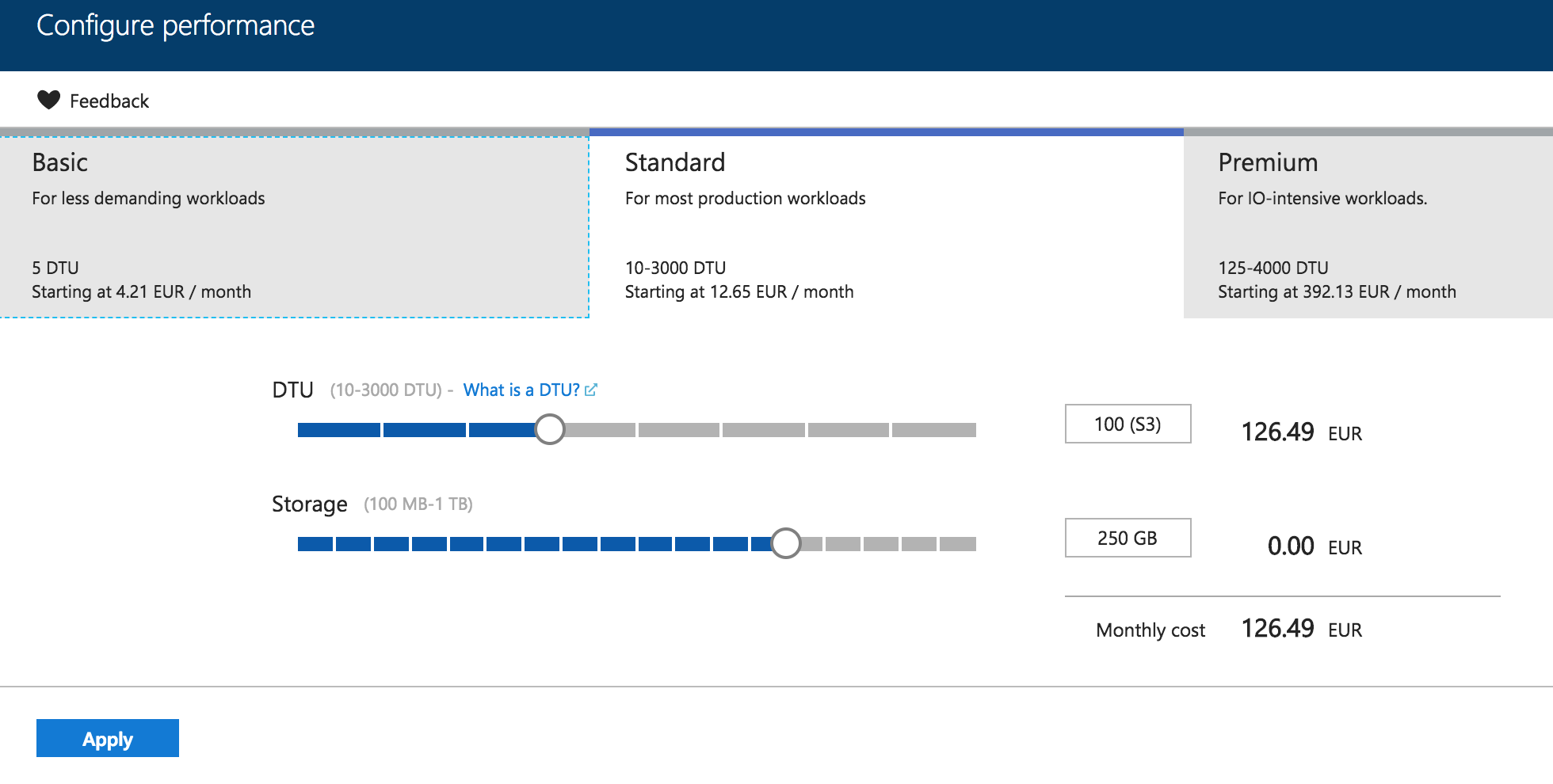 For the start I decided to create the recommended and supported instance of the Azure SQL Database – the Standard 3 (S3) that should support all features and allow the usage of the Columnstore Indexes for the query processing. Without query processing the only advantage from Columnstore Indexes will be the storage compression (2-3 times better than the best RowStore available one), which can still help you to get better performance out of the Azure SQL Database on the lower tiers – IO throttling is the common limit on the PAAS offerings where you pay a couple of bucks (euros) for an incredibly offer that includes disaster recovery by default, security, etc.
For the start I decided to create the recommended and supported instance of the Azure SQL Database – the Standard 3 (S3) that should support all features and allow the usage of the Columnstore Indexes for the query processing. Without query processing the only advantage from Columnstore Indexes will be the storage compression (2-3 times better than the best RowStore available one), which can still help you to get better performance out of the Azure SQL Database on the lower tiers – IO throttling is the common limit on the PAAS offerings where you pay a couple of bucks (euros) for an incredibly offer that includes disaster recovery by default, security, etc.
Once the database was successfully created on my Azure SQL Server (logical one), using SQL Operations Studio (Yes, I am a long-time MAC guy who finally gets rid of the Windows VMs for a number of tasks), I created a new test table that I have called dbo.SampleDataTable and where I loaded 10 perfect Row Groups:
DROP TABLE IF EXISTS dbo.SampleDataTable
CREATE TABLE dbo.SampleDataTable (
C1 BIGINT NOT NULL,
INDEX CCI_SampleDataTable CLUSTERED COLUMNSTORE
);
INSERT INTO dbo.SampleDataTable WITH (TABLOCK)
SELECT
t.RN
FROM
(
SELECT TOP (10 * 1048576) ROW_NUMBER()
OVER (ORDER BY (SELECT NULL)) RN
FROM sys.objects t1
CROSS JOIN sys.objects t2
CROSS JOIN sys.objects t3
CROSS JOIN sys.objects t4
CROSS JOIN sys.objects t5
) t
OPTION (MAXDOP 1);
This has worked perfectly without any typical error messages that someone using Standard Tiers of the Azure SQL Database is used to. :) This alone will be a huge deal breaker for any development of the Data Warehouses/Business Intelligence/Reporting solutions on Azure SQL Database.
But let us not stop and celebrate right away, we need to do more tests then a typical presenter copies & pastes from the documentation. :)
We need to check on the internal structure to verify how good the Row Groups are, if they are trimmed under some regular or maybe even under some exotic type of pressure, and for this goals, I will use again my free and open-sourced Columnstore Library CISL:
EXECUTE dbo.cstore_GetRowGroupsDetails;
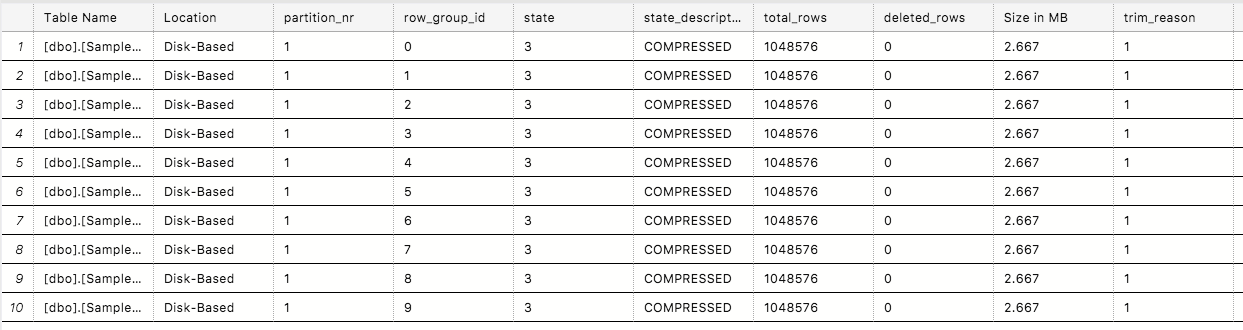
You can see that everything is fine and that all 10 Row Groups are perfect (ha, with just 1 integer column I would be shocked to find otherwise) and that there are conspiracy theories and that no pressure has been applied to throttle down the performance or internal structures.
Let’s fire an aggregation query against this table and check on the execution plan:
SELECT SUM(C1) as SomeSum
FROM dbo.SampleDataTable;

 On the pictures on the left you can see the result of the aggregation and the amount of time it took S3 instance of the Azure SQL Database to process the query – some incredible 113 milliseconds. Not a bad result for 10 million rows and a non-premium database instance.
On the pictures on the left you can see the result of the aggregation and the amount of time it took S3 instance of the Azure SQL Database to process the query – some incredible 113 milliseconds. Not a bad result for 10 million rows and a non-premium database instance.
I have ran a couple of different basic functional tests and so far things have performed quite well. I will be testing the restore of the TPCH and will report eventual problems/defects if they will be detected:
SELECT C1 % 5, SUM(C1) as SomeSum
FROM dbo.SampleDataTable
GROUP By C1 % 5;
 The above execution plan is quite … unhandsome, but that’s a start point to understand & verify what is going with the execution of our query. We have a Columnstore Index scan that runs in the Batch Execution Mode, but you won’t be able to see a lot of the usual details right now in the SQL Operations Studio and so I strongly recommend on the real engagements to keep on using SQL Server Management Studio (given that you will find a stable build for your purpose).
The above execution plan is quite … unhandsome, but that’s a start point to understand & verify what is going with the execution of our query. We have a Columnstore Index scan that runs in the Batch Execution Mode, but you won’t be able to see a lot of the usual details right now in the SQL Operations Studio and so I strongly recommend on the real engagements to keep on using SQL Server Management Studio (given that you will find a stable build for your purpose).
Given that you won’t have a whole private CPU core on the Standard tier, do not expect a parallel execution and hence the amount of memory should not be a huge problem unless you are working with a very wide table – and in such case you will need to consider upgrade paths to Premium instances of Azure SQL Database.
Downgrading to S2
In the announcement of the Columnstore Indexes support for the Azure SQL Database Standard Instances, the support of S2 and lower instances (S2,S1,S0) does not guarantee the usage of the Columnstore Indexes and that query will be avoiding them, but the migration from S3 or any P (premium instances) should be working quite fine, with data addition/edition not delivering any problems – let’s check on that by invoking the T-SQL command that will scale our instance to S2 from S3 and after reconnecting to it we should be able to verify that information:
ALTER DATABASE StandardColumnstore
MODIFY (SERVICE_OBJECTIVE = 'S2');
Seconds later I am ready to fire away my test queries against this time S2 instance with
First of all, let’s take a look at the Row Groups internal structures – to verify if they have suffered any changes:
EXECUTE dbo.cstore_GetRowGroupsDetails;
No changes in the underlying structure (and it would be a total disaster if this would take place, because the process of migration from one instance level to another could take large minutes).
Let’s fire again that primitive aggregation query to see if the Columnstore Index will be used for this purpose (well, we have no other clustered index and that will be a very interesting situation)
SELECT SUM(C1) as SomeSum
FROM dbo.SampleDataTable;

Table ‘dbo.SampleDataTable’ uses a clustered columnstore index. Columnstore indexes are not supported in this service tier of the database. This is something to be expected, because Query Optimiser could not find any alternative for the Clustered Columnstore Index and so it had to abort query execution. But what happens if we would have an additional index on this table? Let’s create one to find out:
CREATE NONCLUSTERED INDEX IX_SampleDataTable_C1
on dbo.SampleDataTable (c1)
WITH (DATA_COMPRESSION = PAGE);

The statement failed because a nonclustered index cannot be created on a table that has a clustered columnstore index. Consider replacing the clustered columnstore index with a nonclustered columnstore index.
Wow, that’s a tough message! It makes sense, because we can not get enough memory for the operation – especially with the Mapping Index we shall have a complicated situation of even more resources required to keep every index up to date, but that’s still won’t make happy everyone. To solve this situation we shall need to drop the Columnstore Index and to recreate a Row Store Index and depending on the amount of data this operation will take quite a lot of time
so here is a small performance tip – upgrade your database to a premium instance, execute that maintenance (changing Columnstore to the RowStore) and only then downgrade to the S2 or lower instance. Overall it will be much faster and not really more expensive.
What about addition of some new 10 million rows to the S2 instance, will it also fail ?
INSERT INTO dbo.SampleDataTable WITH (TABLOCK)
SELECT
t.RN
FROM
(
SELECT TOP (10 * 1048576) ROW_NUMBER()
OVER (ORDER BY (SELECT NULL)) RN
FROM sys.objects t1
CROSS JOIN sys.objects t2
CROSS JOIN sys.objects t3
CROSS JOIN sys.objects t4
CROSS JOIN sys.objects t5
) t
OPTION (MAXDOP 1);
The operations went very swift and another 10 compressed Row Groups were successfully created, as you can see on the picture below:
Everything looks fine, right ?
Let’s try to avoid BULK Load API and try to INSERT some more data:
INSERT INTO dbo.SampleDataTable
VALUES (-1);
This statement went just fine. Let’s try to add 1.000 rows, which are below the threshold for the Bulk Load API activation (102.400):
INSERT INTO dbo.SampleDataTable WITH (TABLOCK)
SELECT
t.RN
FROM
(
SELECT TOP (1000) ROW_NUMBER()
OVER (ORDER BY (SELECT NULL)) RN
FROM sys.objects t1
CROSS JOIN sys.objects t2
CROSS JOIN sys.objects t3
CROSS JOIN sys.objects t4
CROSS JOIN sys.objects t5
) t
OPTION (MAXDOP 1);
This operation took just a second, and should we try to insert 100.000 rows (which are still not using Bulk Load API)
INSERT INTO dbo.SampleDataTable WITH (TABLOCK)
SELECT
t.RN
FROM
(
SELECT TOP (100000) ROW_NUMBER()
OVER (ORDER BY (SELECT NULL)) RN
FROM sys.objects t1
CROSS JOIN sys.objects t2
CROSS JOIN sys.objects t3
CROSS JOIN sys.objects t4
CROSS JOIN sys.objects t5
) t
OPTION (MAXDOP 1);
the operation is still blazing fast.
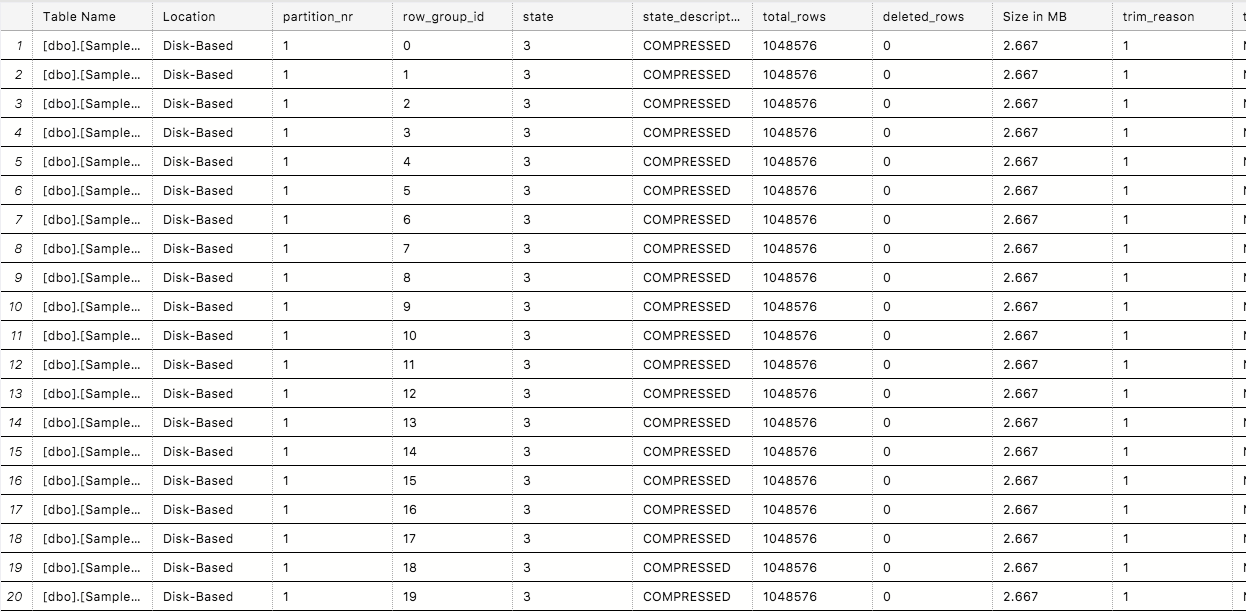
What about the internal storage, are we still using the Delta-Stores, or is there a compressed Row Group already?
EXECUTE dbo.cstore_GetRowGroupsDetails;
![]()
Quite a fine situation with our open Delta-Store that contains 100.000 + 10.000 + 1.000 + 1 row :)
Does it mean that the limitation is only on querying and that all data manipulation operations are supported ? What about DELETE/UPDATE operations:
DELETE TOP(10000000) FROM dbo.SampleDataTable;
UPDATE TOP(10000000) dbo.SampleDataTable
SET C1 = 1;

Msg 35321, Level 16, State 1, Line 1
Table ‘dbo.SampleDataTable’ uses a clustered columnstore index. Columnstore indexes are not supported in this service tier of the database. See Books Online for more details on feature support in different service tiers of Windows Azure SQL Database.
Oops … This is very upsetting. We can not delete any data from our table but we are able to insert into it? This looks like a serious technical limitation that will be upsetting unsuspecting users who will face it.
I am definitely interested in seeing removed in the future. Theoretically marking rows as inactive in the Deleted Bitmap should be a non-memory demanding operation. Yes, because of the Read Committed Snapshot isolation level and potential parallelism it is far from being trivial, but this limitation should be fixed in the future.
What actually happens when we get a full Delta-Store and it will become closed? Will Tuple Mover compress it to the compressed Row Group or will we be getting more and more Delta-Stores?
I have repeated multiple times the loading process of the 100.000 rows so that a closed Delta-Store was achieved (this happens once we load more than 1048576 rows):

Looks quite fine – we have a closed Delta-Store and a new open one!
After waiting for much more than 5 minutes the situation did not change and I decided to take control in my hands and force the compression of the closed Delta-Store with the help of the ALTER INDEX … REORGANIZE command:
ALTER INDEX CCI_SampleDataTable
ON dbo.SampleDataTable
REORGANIZE;
which execution was successful, but it brought no changes to the underlying structure of the Columnstore Index – the closed Delta-Store remained closed and there were no conversion to the compressed Row Group.
I decided not to give up and tried to force the compression with the help of the good old COMPRESS_ALL_ROWGROUPS = ON hint:
ALTER INDEX CCI_SampleDataTable
ON dbo.SampleDataTable
REORGANIZE WITH (COMPRESS_ALL_ROWGROUPS = ON);

The error message leaves no doubt – there is no way we can get data from the Delta-Stores (RowStore) compressed into Row Groups unless we load data with the help of the Bulk Load API.
Should we even try rebuild the Columnstore Index on S2 instance ?
ALTER INDEX CCI_SampleDataTable
ON dbo.SampleDataTable
REBUILD;
Msg 35321, Level 16, State 1, Line 1 Table 'dbo.SampleDataTable' uses a clustered columnstore index. Columnstore indexes are not supported in this service tier of the database. See Books Online for more details on feature support in different service tiers of Windows Azure SQL Database.
I can not be totally happy about the situation, but a good solution (hopefully a temporal one, until the Standard instances won’t get enough memory) for not loosing new data is here and your new data will be loaded into the Columnstore Index.
Creation of new objects
Can we create a new table with a Clustered Columnstore Index on the S2 instance ?
Let’s try to create a brand new empty table with the Clustered Columnstore Index in it ?
CREATE TABLE dbo.S2 (
C1 BIGINT NOT NULL,
INDEX CCI_S2 CLUSTERED COLUMNSTORE
);

Nope and given what I have observed so far it really makes sense, sometimes I wish that it would simply function and keep data in the open Delta-Store, so the development code would not be broken.
Nonclustered Columnstore Index
We have already seen the recommendation to create a Nonclustered Columnstore Index instead of the Clustered Columnstore Index – it took at the moment of the Nonclustered RowStore Index creation, but once we try to create a table with it:
CREATE TABLE dbo.S2 (
C1 BIGINT NOT NULL,
INDEX CCI_S2 NONCLUSTERED COLUMNSTORE (c1)
);
the very same error messages appears:

The messaging should be corrected and a wrong recommendation should deliver a more clear message, that will leave no doubt that a direct creation of the Nonclustered Columnstore Index currently is impossible.
CCI with Secondary Indexes.
Let’s reset the Service Level of the Azure SQL Database and switch back to S3 where we can try to create additional Nonclustered RowStore Indexes to see if this will work out correctly:
ALTER DATABASE StandardColumnstore
MODIFY (SERVICE_OBJECTIVE = 'S3');
CREATE NONCLUSTERED INDEX IX_SampleDataTable_C1
on dbo.SampleDataTable (c1)
WITH (DATA_COMPRESSION = PAGE);
This statement instead of expected success delivers the following error message meaning that we can not get secondary Nonclustered Rowstore Indexes on our Clustered Columnstore table:
![]()
I confess to be quite shocked with the result of the command, because on the premium instances we can add additional indexes without any problems. Yes, it takes a lot of time and significant amount of resources but it works! :( This limitation should be documented, otherwise people might think that this functionality is not implemented on the Azure SQL Database!
I decided to advance with a migration to the Premium Instance anyway and created there an additional index on our test table dbo.SampleDataTable as you can see below:
ALTER DATABASE StandardColumnstore
MODIFY (SERVICE_OBJECTIVE = 'P1');
CREATE NONCLUSTERED INDEX IX_SampleDataTable_C1
on dbo.SampleDataTable (c1)
WITH (DATA_COMPRESSION = PAGE);
Now, let’s scale back down to S2:
ALTER DATABASE StandardColumnstore
MODIFY (SERVICE_OBJECTIVE = 'S2');
and run our test query which will have a path for the Query Optimiser to use to enable the execution of the query:
SELECT SUM(C1) as SomeSum
FROM dbo.SampleDataTable;

but unfortunately it looks like this solution is not implemented yet and not even a direct hint to the Nonclustered Index helps:
SELECT SUM(C1) as SomeSum
FROM dbo.SampleDataTable WITH (INDEX(IX_SampleDataTable_C1));
I imagine this won’t get fixed on the basis that it is a current limitation that with the time shall fade away as more memory will become available for every tier, but I see a good usage for this scenario in the mean time.
Memory Optimised Columnstore Index
It would be enough to check the current situation with the Hekaton (In-Memory) support to know if there is any chance for the In-Memory Columnstore Indexes:
SELECT DatabasePropertyEx(DB_NAME(), 'IsXTPSupported') as IsXTPSupported;
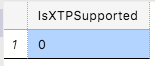 Without In-Memory support there are no Memory-Optimised Columnstore Indexes and hence there is no sense to try it. Of course it would not be enough for someone like me and I did my best trying to create a new Hekaton table, but this is really not supported yet for the Standard instances:
Without In-Memory support there are no Memory-Optimised Columnstore Indexes and hence there is no sense to try it. Of course it would not be enough for someone like me and I did my best trying to create a new Hekaton table, but this is really not supported yet for the Standard instances:
CREATE TABLE [dbo].[InMem](
[Id] int IDENTITY NOT NULL PRIMARY KEY NONCLUSTERED,
) WITH (MEMORY_OPTIMIZED = ON);
Here is a good and valuable insight from the documentation about the downgrades, taken from the official documentation of the Azure SQLDB:
Downgrading to Basic or Standard: Columnstore indexes are supported only on the Premium pricing tier and on the Standard tier, S3 and above, and not on the Basic tier. When you downgrade your database to an unsupported tier or level, your columnstore index becomes unavailable. The system maintains your columnstore index, but it never leverages the index. If you later upgrade back to a supported tier or level, your columnstore index is immediately ready to be leveraged again.
If you have a clustered columnstore index, the whole table becomes unavailable after the downgrade. Therefore we recommend that you drop all clustered columnstore indexes before you downgrade your database to an unsupported tier or level.
Downgrading to a lower supported tier or level: This downgrade succeeds if the whole database fits within the maximum database size for the target pricing tier, or within the available storage in the elastic pool. There is no specific impact from the columnstore indexes.
Memory Pressure
Understanding memory pressure is very important for the Columnstore Indexes and you have got to keep in mind that every Azure SQL Database performance tier has its own amount of RAM that is not configurable and that this difference between even Standard tiers can have a huge impact on the Row Group sizes.
To see how much of RAM we are dealing with in every single instance, please feel free to use the following T-SQL query:
SELECT object_name as ObjectName, counter_name as CounterName, CAST(cntr_value / 1024. as DECIMAL(9,2)) as MaxMemoryInMB
FROM sys.dm_os_performance_counters
WHERE counter_name IN ('Total Server Memory (KB)', 'Target Server Memory (KB)');
The results for S3 and S2 are presented respectively:

S2 Max Memory

S3 Max Memory
but please do not use those as the references, because Microsoft is constantly improving the amounts & types of hardware and so by the time you are reading this paragraph a very different values might be in usage.
To my understanding the biggest different between the current available memory of the S3 and P1 is that it is shared on the Standard tier while it is totally private on the Premium. Upgrading to P2 will allow you to achieve 11.8GB of the Target Server Memory and it will grow accordingly to the further scale-up. You might even consider rebuilding your indexes on the higher instance tier when suffering from Memory Pressure.
Final Thoughts
I know that a lot of effort, time and sweat was put into making Columnstore Indexes available on the Standard instances – and I am without hesitation extremely happy that it is finally took place. I am looking to even more Columnstore Indexes usage, but I definitely would love to see some clean up in the error messages, not directed to the wrong unsupported type of the Nonclustered Columnstore Indexes on Standard 2 (S2) tier.
Given that S4, S6, S7, S9 & S12 instances are already in preview – there will be much more space for the Columnstore Indexes usage in the nearest future and I am happy to see that the democratisation of the Data Platform is taking Microsoft to the leading positions in the battle of the PAAS offers. Your S3 instance suddenly became attractive for much bigger databases and it is absolutely worth celebrating!
The more distant future
I believe that in the even more distant future the current limitations will be lifted. Once the Hardware become more available and the less capable editions will get more RAM – there will be no reasons why S
The performance will still be throttled through the available CPU cores and memory as well (there will be less memory than for the Standard & Premium obviously), but smaller firms will be able to benefit from the Columnstore Indexes for their Data Warehouses – but until then you will need to upgrade to at least S3.
to be continued with Columnstore Indexes – part 122 (“Wait Types”)