Continuation from the previous 124 parts, the whole series can be found at https://www.nikoport.com/columnstore/.
It is quite emblematic that this blog post is following the number 124 in the series – Columnstore Indexes – part 124 (“Estimate Columnstore Compression”), because this blogpost is a logical continuation of my original one, publishing the script of my CISL cstore_sp_estimate_columnstore_compression_savings, which supports any SQL Server version with Columnstore Indexes, as well as the Azure SQL Database.
Just a couple of days ago, with the first public release of the SQL Server 2019 CTP 2.0, Microsoft has included a new version of the good old system stored procedure sys.sp_estimate_data_compression_savings that finally supports Columnstore & Columnstore Archival compressions.
I was excited to see this so much waited addition to the relational engine of SQL Server and
sys.sp_estimate_data_compression_savings
Looking at the documentation page of the sys.sp_estimate_data_compression_savings, brings me a very uncomfortable feeling, because even though the documentation states that it was updated in May, I have checked it in the June of 2018 and there were no mention of the Columnstore Indexes, while right now there are a couple of paragraphs referring to it and mentioning SQL Server 2019… Either the update date of the documentation is wrong … or the update date of the documentation is badly wrong ! :)
In any case we can find out that the both Columnstore Compression types are finally supported, but I guess that the SQL Server developers have faced the same issues that I did once developing my own procedure – because Columnstore Indexes are different from the Rowstore ones, it is difficult to decide what kind of index is to be built: “For this reason, when using the COLUMNSTORE and COLUMNSTORE_ARCHIVE options of this procedure, the type of the source object provided to the procedure determines the type of columnstore index used for the compressed size estimate. ”
Another interesting issue with this procedure is that it is supporting Columnstore Indexes as a source, meaning that if you are creating a regular Rowstore Compression – you will be limited by the 32 columns, just in a regular Rowstore case.
I have picked a 10 GB version of the TPCH test database for the purpose of testing and it is a generated copy that can be done with the help of HammerDB (free software).
Columnstore Indexes – part 99 (“Merge”)
Continuation from the previous 98 parts, the whole series can be found at https://www.nikoport.com/columnstore/.
This blog post is focused on the MERGE statement for the Columnstore Indexes, or as I call it – the worst enemy of the Columnstore Indexes. It is extremely difficult to imagine some statement or way of making the worst out of the Columnstore Indexes, if not the infamous MERGE statement. Why ? Because it is not only making Columnstore Indexes perform slow, it will make them perform MUCH SLOWER then any Rowstore Indexes. Yes, you have read right – slower then ANY_ROWSTORE_INDEXES. In fact, this should be a hint that one should apply to the Merge statement, when it is executed against Columnstore Indexes! :)
I decide to dedicate a whole blog post on this matter, mainly to warn people of this pretty problematic statement – I hope not to see it being used for Columnstore Indexes in the future!
MERGE T-SQL statement has a huge number of bugs and potential problems with some statements delivering incorrect results or being canceled – for the details I recommend that you read Use Caution with SQL Server’s MERGE Statement where Aaron Bertrand went into the details of why one should strive to avoid using this statement.
You might point that a couple of years ago, I have already published a blog post on the dangers of using UPDATE statement for the Columnstore Indexes, but as I keep seeing MERGE statement on the production servers, it is clearly deserves an own post.
As in the other blog post I will be using the a generated copy of the TPCH database (10GB version this time, because I want my tests to reflect bigger workloads), that I have generated with HammerDB (free software).
Below is the script for restoring the backup of TPCH from the C:\Install\:
USE [master]
if exists(select * from sys.databases where name = 'tpch')
begin
alter database [tpch]
set SINGLE_USER WITH ROLLBACK IMMEDIATE;
end
RESTORE DATABASE [tpch]
FROM DISK = N'C:\Install\tpch_10gb.bak' WITH FILE = 1, NOUNLOAD, STATS = 1
alter database [tpch]
set MULTI_USER;
GO
GO
ALTER DATABASE [tpch] SET COMPATIBILITY_LEVEL = 130
GO
USE [tpch]
GO
EXEC dbo.sp_changedbowner @loginame = N'sa', @map = false
GO
USE [master]
GO
ALTER DATABASE [tpch] MODIFY FILE ( NAME = N'tpch', FILEGROWTH = 2561520KB )
GO
ALTER DATABASE [tpch] MODIFY FILE ( NAME = N'tpch_log', SIZE = 1200152KB , FILEGROWTH = 256000KB )
Now, let’s do not waste any second and try out the new system Stored Procedure sys.sp_estimate_data_compression_savings which is located in the master database and hence is available in every single database:
EXECUTE [sys].[sp_estimate_data_compression_savings] @schema_name = 'dbo', @object_name = 'lineitem', @index_id = 1, @partition_number = 1, @data_compression = 'COLUMNSTORE';
![]()
On the image above you can clearly see the results pointing towards 2.5 GB of the total size of the expected Columnstore Index, and with just 10 seconds spent – this is a brilliant results, I have to say. What raises me both of my eyebrows are the used sample – 40MB of the original sample size with the current compression setting (NONE) and the 10.7MB for the Columnstore compression.
Let us compare it with the results with my CISL cstore_sp_estimate_columnstore_compression_savings function, which execution you can see below:
execute dbo.cstore_sp_estimate_columnstore_compression_savings @schemaName = 'dbo', @tableName = 'lineitem';

Besides providing much more information (sampled rows, %, and the Trimming reasons, etc), options (such as DOP, sampled table persistence, etc) the default usage in this case took a whooping 44 seconds! But most importantly if you look at the estimated results, it will show you that the 4.3 GB is the expected size of the compressed table – which is a huge difference to the original estimation by the sys.sp_estimate_data_compression_savings System Stored Procedure in SQL Server 2019. We are talking here about good 40% of the difference in the estimation and when we are talking about big tables for the Data Warehousing – this can be a crucial factor, in my experience. This is why I have included a parameter to control the number of sampled rows (and by default it is 4 Row Groups – meaning 4.182.712 rows.
I was surprised by this situation and decided to test the complete copy of the lineitem table, which is pretty easy to do with the help of the same CISL function – just specify that the sampling table should be kept:
execute dbo.cstore_sp_estimate_columnstore_compression_savings @schemaName = 'dbo', @tableName = 'lineitem', @rowGroupsNr = 60, @destinationDbName = 'tpch_10', @destinationTable = 'lineitem_cci', @deleteAfterSampling = 0;
The final results were pretty much amazing – 2.1 GB, making the estimation of the sys.sp_estimate_data_compression_savings System Stored Procedure much more precise then my own function! This leaves me very happy and makes me want to investigate and learn how this new stored procedure is capable of providing better estimations.
I decided to test on the other tables within TPCH database and my test on the Orders table have shown a different situation where the 0.7 GB estimation of the sys.sp_estimate_data_compression_savings Stored Procedure were pretty much offbeat when comparing to the CISL dbo.cstore_sp_estimate_columnstore_compression_savings – showing 0.92 GB while the end result was 0.89 GB.
I guess the final answer is that it will depend, but that the estimation of the new stored procedure are not totally offbeat is an incredibly good sign, though I would still keep an eye or even two on the provided estimated results.
SSMS
The SQL Server Management Studio (in short SSMS) that accompanies SQL Server 2019 CTP 2.0 release is SSMS 18.0, and even though I am becoming a lesser fan of it (think all missing Columnstore Features, Mirroring, AG, Stored Procedure, etc, etc bugs), I still try to use its features in order to be able to share with the clients what they can and what they can’t do).
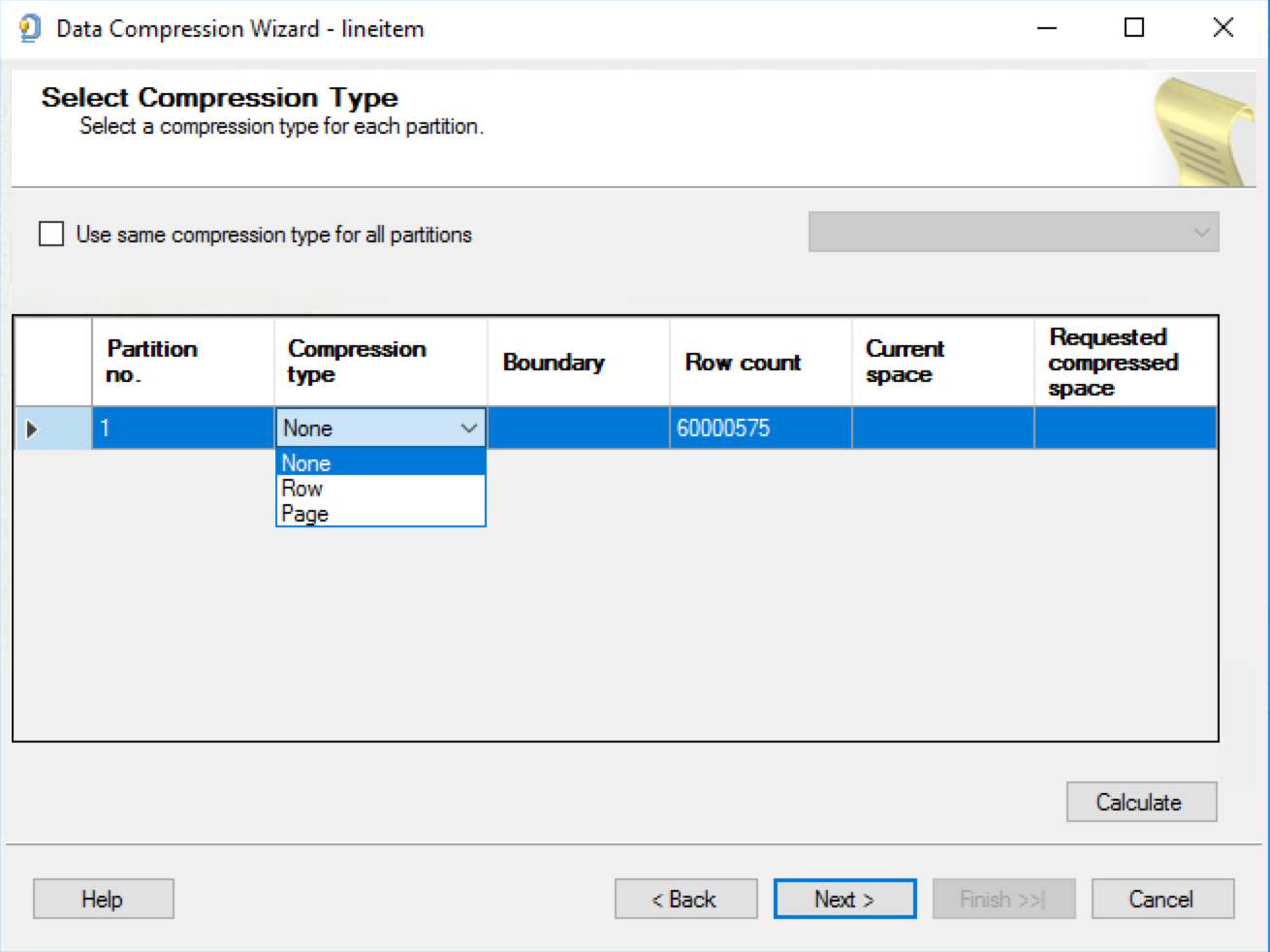 For the purpose of testing the SSMS support of the sp_estimate_data_compression_savings, let’s select the lineitem table from the TPCH 10 GB database, as previously by right clicking on the table name at the Object Explorer, select Storage Menu and selecting “Manage Compression” further. At this point we shall arrive to the screen where we can select partition(s) and corresponding compression type – NONE, ROW, PAGE … and nothing else … There is no way to select COLUMNSTORE or COLUMNSTORE_ARCHIVE compression levels and hence no way to calculate the estimated improvement for the application of the Columnstore Indexes, and while it is reasonable that SSMS is always a couple of steps behind of the SQL Server Engine, a huge number of users who are following visual guide of the GUI will be quite disappointed, and given the lack of the basic Columnstore Indexes functionalities in the SSMS – I see a frightening tendency, rather then the exception.
For the purpose of testing the SSMS support of the sp_estimate_data_compression_savings, let’s select the lineitem table from the TPCH 10 GB database, as previously by right clicking on the table name at the Object Explorer, select Storage Menu and selecting “Manage Compression” further. At this point we shall arrive to the screen where we can select partition(s) and corresponding compression type – NONE, ROW, PAGE … and nothing else … There is no way to select COLUMNSTORE or COLUMNSTORE_ARCHIVE compression levels and hence no way to calculate the estimated improvement for the application of the Columnstore Indexes, and while it is reasonable that SSMS is always a couple of steps behind of the SQL Server Engine, a huge number of users who are following visual guide of the GUI will be quite disappointed, and given the lack of the basic Columnstore Indexes functionalities in the SSMS – I see a frightening tendency, rather then the exception.
I do hope & expect this to be solved by the final release of the SQL Server and hopefully this will support SQL Server 2014+ for the very same purpose.
Final Thoughts
I do not see any magic sauce in the addition to the sys.sp_estimate_data_compression_savings stored procedure and as I told many moons ago – we need this to be backported to SQL Server 2014, 2016 & 2017. With so many examples of great backports lately from the SQL Tiger team, it should be pretty much no brainer to include this in a CU or maybe even in a Service Pack (yeah, for the SQL Server 2017 this will have to be a CU, I know :)).
So many people will profit from this improvement, without having to use additional downloads and installations, without having to explain what this function does or how much was paid for it (nothing, its free) and how much it is supported (as anything free) – I am really grateful for this little but important implementation.
Oh, and I am going to keep my function and develop it a bit further … just because it has more functionalities and you know … just in case ;)
to be continued with Columnstore Indexes – part 126 (“Extracting Columnstore Statistics to Cloned Database”)
Everyone is quick to point out that MERGE has some bugs. Is it really that bad? It always worked fine for me. I understand the egregious bugs are long fixed in recent SQL Server versions.
Hi tobi,
I have already hit multiple bugs in the production. I do not believe that all of them are solved, there are simply mitigations and alternative solution paths, and that’s the reason that Microsoft does not hold them to the highest priority.
Best regards,
Niko
That’s terrible. MERGE is such a useful concept.