The main idea about Result Set Caching is very simple – you take the already processed results from the complex expensive queries and store it accessible so when the very same query arrives asking for the result again, the server won’t spend seconds/minutes processing the query again, but will recognise the query and read the results from the local cache.
For a good number of years, the result set caching was an exclusive feature of the concurrent commercial & non-commercial Data Platforms such as Oracle (12c) and MySQL (Yes, I know that it was depricated long time ago in MySQL 5.6 around 2013 and even REMOVED in MySQL 8.0, but in fact it still exists in previous versions (the end of support for which is marked in around 4 years – October 2023!!!) and can be enabled by those who know how and WHEN to enable it).
The difficulty here is that the result invalidation is a pretty sensitive topic and in a generic system that is more OLTP-focused (including HTAP) it makes not much sense, but in the Data Warehouse environment and especially in Data Warehouses implemented on disitributed systems, the risk of cache invalidation is relatively low (after your ETL is done, you do not expect the results to change or someone to update registers on row-by-row basis) and the benefit is huge (allows you to improve the read scale of the system, which is a general objective of the Data Warehouse during the day (non-ETL times)).
Some people will instantly mention Redis, which is a great solution for some of the performance problems but it might not be the easiest thing to set for a BI professional and paying extra money for some of the work that the engine itself is capable of doing. The discussion of which option is cheaper is definitely out of scope for this blog post and I honestly see usage patterns in favour and against using the local In-Database caching.
In this passing year of 2019 (this blog post is written in the late December of 2019), Microsoft has announced the new feature Azure SQL DW Resut Set Caching (or should I write now Azure Synapse Result Set Caching? :)). Another exclusive feature for the Azure SQL DW (such as Ordered Clustered Columnstore Indexes). Available only with Azure DW Generation 2 (to my knowledge there were no chances of keeping the Generation 1 beyond June the 1st 2019 anyway), the Result Set Caching will store the results of the read queries within the control node of the Azure SQL DW and return it to the user.
Setting up Azure SQLDW Result Set Caching
Contrary to some of the older documentation, which can still be found around, you can set up the Result Set Caching directly from the master database with the ALTER DATABASE [yourDatabaseName] SET RESULT_SET_CACHING ON/OFF and to be honest that is the only way that I managed to make it work;
The required privilege for this action is to be either member of dbmanager database role or to have Server Level Principla Login, and if your login and user are none of that, you will need a system administrator or a DBA to set it up for you.
Let’s run the configuration query inside the master database on our Azure Sql Server Instance:
ALTER DATABASE resultsetcaching
SET RESULT_SET_CACHING ON;
To verify the status of the database configuration we shall rely on the good old sys.databases DMV, which on Azure SQL DW includes a new column for that purpose – is_result_set_caching_on:
SELECT is_result_set_caching_on, *
FROM sys.databases
WHERE name = 'resultsetcaching';

Given latest developments where for every new option we would receive a great number of knobs, Microsoft also allows us to control the result caching on the individual session level with the command SET RESULT_SET_CACHING ON/OFF, such as in
SET RESULT_SET_CACHING ON SELECT ... SET RESULT_SET_CACHING OFF SELECT ...
In Practice
Let’s do some testing and execute the same query a couple of times, first with the Result Set Caching activated and then a couple of times without Result Set Caching and see if it brings any performance benefits.
I have created a plain simple DW200C Azure SQL DW (Azure Synapse Analytics) instance with a sample database AdventureWorks and run the following queries, extracting some aggregated information on the sales to women between 2005 and 2007 inclusive, grouping by Education and House Ownership:
SET RESULT_SET_CACHING ON;
SELECT d1.EnglishEducation AS [Customer Education Level],
CASE
WHEN d1.HouseOwnerFlag = 0 THEN 'No'
ELSE 'Yes'
END AS [House Owner],
COUNT(*) AS [Internet Order Quantity],
ROUND(SUM(f1.SalesAmount),2) AS [Internet Sales Amount]
FROM [dbo].[FactInternetSales] f1
INNER JOIN [dbo].[DimCustomer] d1
ON f1.CustomerKey=d1.CustomerKey
INNER JOIN dbo.DimDate dat1
ON f1.ShipDateKey = dat1.DateKey
INNER JOIN [dbo].[DimGeography] d2
ON d1.GeographyKey=d2.GeographyKey
WHERE dat1.fiscalyear >= 2005 and dat1.fiscalyear <= 2007
AND d2.EnglishCountryRegionName<>'United States'
AND d1.Gender='F'
GROUP BY d1.EnglishEducation, d1.HouseOwnerFlag
ORDER BY d1.EnglishEducation, d1.HouseOwnerFlag;
SET RESULT_SET_CACHING OFF;
SELECT d1.EnglishEducation AS [Customer Education Level],
CASE
WHEN d1.HouseOwnerFlag = 0 THEN 'No'
ELSE 'Yes'
END AS [House Owner],
COUNT(*) AS [Internet Order Quantity],
ROUND(SUM(f1.SalesAmount),2) AS [Internet Sales Amount]
FROM [dbo].[FactInternetSales] f1
INNER JOIN [dbo].[DimCustomer] d1
ON f1.CustomerKey=d1.CustomerKey
INNER JOIN dbo.DimDate dat1
ON f1.ShipDateKey = dat1.DateKey
INNER JOIN [dbo].[DimGeography] d2
ON d1.GeographyKey=d2.GeographyKey
WHERE dat1.fiscalyear >= 2005 and dat1.fiscalyear <= 2007
AND d2.EnglishCountryRegionName<>'United States'
AND d1.Gender='F'
GROUP BY d1.EnglishEducation, d1.HouseOwnerFlag
ORDER BY d1.EnglishEducation, d1.HouseOwnerFlag;
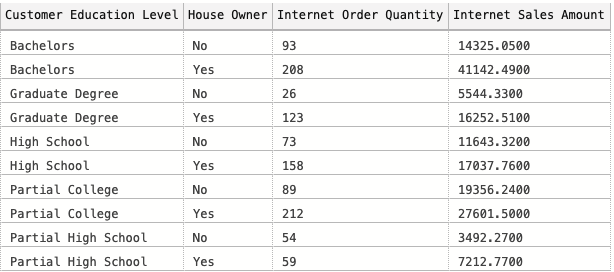 I just put some result on the output, because as you can imagine there are some certain limits on the amount of the output that will be cached and that will be not. Besides the basic logical stuff, such as having deterministic functions only (functions which output will not be varying depending on the execution), not using System Objects or UDFs (and it seems that scalar UDF inlining is not a part of Azure SQL DW yet), no row-level security or column-level security enabled, the main thing and which seems to be pretty good decision as far as I am concerned – the row size larger than 64KB won’t be cached period.
I just put some result on the output, because as you can imagine there are some certain limits on the amount of the output that will be cached and that will be not. Besides the basic logical stuff, such as having deterministic functions only (functions which output will not be varying depending on the execution), not using System Objects or UDFs (and it seems that scalar UDF inlining is not a part of Azure SQL DW yet), no row-level security or column-level security enabled, the main thing and which seems to be pretty good decision as far as I am concerned – the row size larger than 64KB won’t be cached period.
I wish there would be a limited number of rows (1.048.576 rows for all I know) that will be prevented from caching. Such outputs will be polluting the cache for no good reason and might provide quite questionable advantages (also this is pretty much subjective).
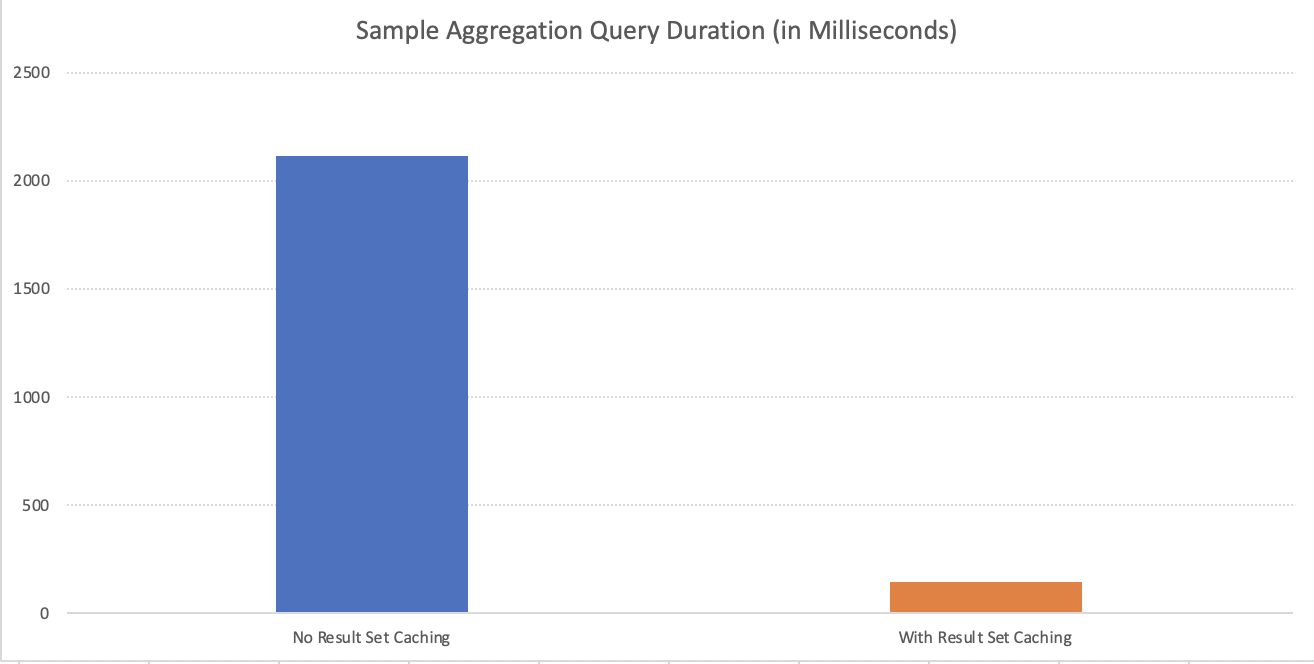 The average execution time (really after the initial one which will have the same processing time for cached as for the uncached result sets, plus the additional time to store the results locally in the control node, the difference is abysmal, which is very much expected. For this specific query (and think about it in the terms that the more complex query there is – the more difference there will be), the difference is between 2116 milliseconds for the uncached execution versus just 142 milliseconds for the usage of cached result set in Azure SQL DW.
The average execution time (really after the initial one which will have the same processing time for cached as for the uncached result sets, plus the additional time to store the results locally in the control node, the difference is abysmal, which is very much expected. For this specific query (and think about it in the terms that the more complex query there is – the more difference there will be), the difference is between 2116 milliseconds for the uncached execution versus just 142 milliseconds for the usage of cached result set in Azure SQL DW.
Monitoring and controlling Result Sets Cache:
There are 2 new DBCC Commands that will provide us with the information on the space used by the Result Set on the control node (DBCC SHOWRESULTCACHESPACEUSED) and the command to drop the result set cache (DBCC DROPRESULTSETCACHE).
DBCC SHOWRESULTCACHESPACEUSED;
![]() The output of this command (DBCC SHOWRESULTCACHESPACEUSED) will show in KB the amount of space reserved in total for the cache, how many KB are used for the table and the indexes and how much of the reserved space in KB is still to be used. In our case the sizes are tiny and work perfectly without any significant impact or delay.
The output of this command (DBCC SHOWRESULTCACHESPACEUSED) will show in KB the amount of space reserved in total for the cache, how many KB are used for the table and the indexes and how much of the reserved space in KB is still to be used. In our case the sizes are tiny and work perfectly without any significant impact or delay.
We can search within the sys.dm_pdw_exec_requests DMV with the help of the command, request & session_ids or even labels for the command and by displaying the result_cache_hit column we can determine if the query used result cache or it had either miss (no previous results found) or the caching was not enabled at all. In my case I just filtered by the executed command, since there is nothing else going on the server:
SELECT result_cache_hit, command, [status], request_id, session_id, total_elapsed_time, [label], error_id, database_id FROM sys.dm_pdw_exec_requests WHERE command like N'SELECT d1.EnglishEducation %'

On the picture above you can see 2 queries where one of them is read from the Result Set Cache and the second one is being read directly from the source tables. Wonderful thing, I might say :)
The cached results will be stored within the control node database and will consume a maximum of 1TB storage.
The results will be evicted from the cache if not referenced in the last 48 hours.
Queries which are a cache hit will simply return the data from the result cache instead of running the full plan creation and retrieving the data across all of the distributions.
In the event of the query being a Cache miss, it will populate a result set table in the cache DB synchronously for the next execution of the statement.
Only pure select statements are cached against non-system and non-external objects which have no run time constraints or row level security predicates.
Limitations:
The query must be the exact copy with all elements being equal to the previous one, and if any parameters change (and query hash with it logically), it will be considered a different query with of course different results, as for example I limit in the first query below the fiscal year by 2007 and in the second with 2009 as the maximum year and while the results will be the same (there is no extra data for 2008 and 2009), the query is different and so the caching won’t take place on the first execution.
SET RESULT_SET_CACHING ON;
SELECT d1.EnglishEducation AS [Customer Education Level],
CASE
WHEN d1.HouseOwnerFlag = 0 THEN 'No'
ELSE 'Yes'
END AS [House Owner],
COUNT(*) AS [Internet Order Quantity],
ROUND(SUM(f1.SalesAmount),2) AS [Internet Sales Amount]
FROM [dbo].[FactInternetSales] f1
INNER JOIN [dbo].[DimCustomer] d1
ON f1.CustomerKey=d1.CustomerKey
INNER JOIN dbo.DimDate dat1
ON f1.ShipDateKey = dat1.DateKey
INNER JOIN [dbo].[DimGeography] d2
ON d1.GeographyKey=d2.GeographyKey
WHERE dat1.fiscalyear >= 2005 and dat1.fiscalyear <= 2007
AND d2.EnglishCountryRegionName<>'United States'
AND d1.Gender='F'
GROUP BY d1.EnglishEducation, d1.HouseOwnerFlag
ORDER BY d1.EnglishEducation, d1.HouseOwnerFlag;
SELECT d1.EnglishEducation AS [Customer Education Level],
CASE
WHEN d1.HouseOwnerFlag = 0 THEN 'No'
ELSE 'Yes'
END AS [House Owner],
COUNT(*) AS [Internet Order Quantity],
ROUND(SUM(f1.SalesAmount),2) AS [Internet Sales Amount]
FROM [dbo].[FactInternetSales] f1
INNER JOIN [dbo].[DimCustomer] d1
ON f1.CustomerKey=d1.CustomerKey
INNER JOIN dbo.DimDate dat1
ON f1.ShipDateKey = dat1.DateKey
INNER JOIN [dbo].[DimGeography] d2
ON d1.GeographyKey=d2.GeographyKey
WHERE dat1.fiscalyear >= 2005 and dat1.fiscalyear <= 2009
AND d2.EnglishCountryRegionName<>'United States'
AND d1.Gender='F'
GROUP BY d1.EnglishEducation, d1.HouseOwnerFlag
ORDER BY d1.EnglishEducation, d1.HouseOwnerFlag;
Any changes to the underlying tables meta-data will evaporate the cache and force new execution, as if we are altering the underlying table DimCustomer by adding a simple new column which won’t be referenced anywhere – the re-execution of the above queries will force a plan renewal:
ALTER TABLE DimCustomer
ADD someId INT NULL;
In the case of the cache miss (as in there is no cached information) – given that the Results Sets Caching is activated, the cache will be repopulated synchronously, meaning that we shall need to add the time for storing the result set in the control node.
The maximum amount of the storage for the Cached Result Set to be used on the Control Node is 1TB, and I expect it to be a function in the terms of the select version of Azure SQL DW.
The Results will be evicted after no query references/re-usage in the past 48 hours.
Where does Result Set Caching Fails:
In the fast-pace data-changing systems, there is not much sense of storing caching results, if they are constantly changing. A system might spend more resources on storing the results instead of spending this time on processing them and fast invalidation of the results at certain point will oblige the system to do just one thing – replace the rcached esults with the new ones.
Final Thoughts
Another exclusive feature for Azure SQL DW (Azure Synapse Analytics). I love it and really happy about it appearance. It might do some magic tricks for the synthetic benchmarks AND real life application scenarios. I am not that scared about failing of this feature and burning the CPU of the Control Node, since given the current Azure SQL DW connection limitations, it should not be the first thing to hit the fan.
Say again, when does this functionality is coming over to Azure SQL Database and Sql Server ? :)
Hello Niko, thanks for that amazing post! It is important to mention that the space used by the cache is not free, if your DW uses 10TB, with result set cache the cost will be for 11TB. At the company I work for we are still evaluating whether this cost pays off the performance with our workload … regards!!!
Hi Bruno,
great comment!
Indeed one has got to be careful with the eventual storage impact on the control node.
As I know we shall agree – the exact size will always depend on the workload and the data involved.
I always think about the relatively to the cost – if you are running not the biggest instances and your processing times are “kind of OK” and you just want to get faster, then it might simply be not worth it, but if you are on the edge of the invested money and can’t scale up – well, that’s a killer feature that can potentially save the day.
Best regards,
Niko Neugebauer
Hi Nico,
very interesting article! Yout explanation is beautiful. Only one mistake (probably typo): command to drop the result set cache is DBCC DROPRESULTSETCACHE, I think.
Best regards,
JanB
Hi JBlazicek,
Thank you very much – I have corrected the typo!
Best regards,
Niko
Hi Niko,
Really great post. Out of curiosity, how would Azure Synapse know when the cache results are outdated?
We are running a fairly large Synapse DW where some tables are updated twice a day so I wouldnt want the users to access older data if it is updated in the underlying table.
Thanks,
Karthik
Hi Karthik,
it looks like the cached results are automatically invalidated when the underlying query data change or they are reset every 48 if the results did not change.
Best regards,
Niko