A couple of months a very exciting announcement has been made by Microsoft (that went totally ignored by the vast majority of the market) – the implementation of the Materialized Views in Azure SQL DW (Also known as Azure Synapse Analytics).
For some people it might have been “just another announcement about product we do not use (yet)” or maybe “this will never be in my Express Edition” or I even admit existence of the people who went like “another marketing rebranding of 20+ years old tech”.
In the mean time, this feature has already went into GA (General Availability) … and it seems like the large majority of the folks is still sleeping
AND … No, it is not the feature you are used to on Sql Server. These are not your grandparents old-school indexed views (though we might have an interesting conversation on their respective limitations).
Let us start this conversation with the definition of what the Materialized Views are – essential a copy of a particular aggregation query that containing physical copy of the query result set. You can also call it a caching mechanism that allows to optimise the complexity of the joins & aggregation operations by not spending the unnecessary CPU cycles for repeating the same operation over & over again.
So in a way, you can consider them to be a family-related feature to the Results Set Caching feature, that was announced by Microsoft for Azure SQL DW (Azure Synapse Analytics) at the same time.
The word Snapshot is also being used when relating to the materialized views. The reason behind the word Snapshot usage is that the update to the materialized view is controlled by the data designer/dba/developer/whoeverisresponsibletomakethingswork(TM), meaning that you can have situations when the materialised view is actually lagging behind the real time information. This is one of the reasons why the most frequent users of the materialized views are the Data Warehouse people and not the OLTP applications. In Data Warehouse environment we have the control over the ETL execution time and can choose the exact moment when the respective Cube/Model/Materilized View are refreshed with the updated information – either manually or preferably automatically.
Readers who are bound to the Sql Server and have ever used indexed views (available since Sql Server 2000) might notice that what they have used before is actually a more constrained version of the same feature (Materialized View), where the synchronisation is absolute – with no lagging involved at all. As being pointed in a number of places, the requirement for the deterministic nature of the functions within the indexed views (and as a matter of a fact within the materialised views in Azure SQL DW now as well) can be a pain in the neck, but that’s a long conversation on what needs to be done to make indexed views work for more people.
Looking at the other successful database engines – Oracle, DB2, PostgreSQL, Amazon DynamoDB, you name it (without MySQL). Most of the Data Platforms are already there and some have pretty impressive implementations, I might add :)
Materialized Views
The requirements and the creation process for the materialized view is very similar to the indexed views, except some little, but still very important details:
- There are no indexed views on Azure SQL DW, making this feature to be the answer to that feature given the specificity of the MPP
- The usage of the analytical functions is required with the Materialized Views and the supported analytical functions are MAX, MIN, AVG, COUNT, COUNT_BIG, SUM, VAR & STDEV
- You are required to indicate the distribution (probably only in Azure SQL DW for the moment, so I hope once this feature will come to Azure SQL DB this requirement will fade away)
- There is no CREATE OR ALTER MATERIALIZED VIEW command, meaning you will still need to do the old job of determining if the view exists and then eventually alter it. Please consider not doing DROP & CREATE operations since they might take quite a significant period of time – depending on the complexity of the original source query and the amount of data to be stored within a materialized view.
- In order to drop the view, the command to use is DROP VIEW and not DROP MATERIALIZED VIEW
- You can use MIN/MAX aggregations in the Materialized View, Woohoo! There are some requirements for that, but we shall just look at it later in this post
- Grouping data is limited to 32 columns
- Even though the materialized views are unique feature, they are presented as the views to the regular SSMS user. The sys.views DMV contains a new column has_snapshot (inherited from the view sys.all_views), which just might have some usage for the materialized views
- The materialized view will be automatically disabled once a DELETE or an UPDATE shall be executed against one of the used tables. In order to make view become enabled again, you should execute the REBUILD command (a kind of a manual snapshot, I would call it)
- Since Materialized Views require stable schema and the only views with SCHEMABINDING and the indexed views that are not supported on Azure SQL DW – this means you simply can not reference any views
- Dealing with the partitioned tables is tricky and if you are switching partitions (ALTER TABLE SWITCH command) – you are out of luck and will need to disable
The most interesting part is that in the official documentation the feature is named as CREATE MATERIALIZED VIEW AS SELECT – meaning we can’t possibly use any of the CTEs or is this just someones pun for getting the CMVAS acronym … (this does not look familiar to me to say at least). Well, not to say that CTEs are welcome in the indexed views, but that direct mention and the continuous lack of support for the subqueries and so many other features makes the impression to be quite a subpar.
Testing Materilaized View
Taking on the query that I have executed in the previous blog post about Azure SQL DW (Azure SQLDW Result Set Caching), and making the following necessary adjustments:
- ROUND(SUM(f1.SalesAmount),2) AS [Internet Sales Amount] -> SUM(f1.SalesAmount) since we can’t do expression over the aggregates
- GROUP BY …, d1.HouseOwnerFlag -> GROUP BY CASE
WHEN d1.HouseOwnerFlag = 0 THEN ‘No’
ELSE ‘Yes’
END AS [House Owner] for the same reason of not being able to do calculations over the grouped columns, but need to group on the same criteria
will take form of a materialised view with the help of the Hash Distribution, which in this case does not matter much, because we just have 10 rows to store with the materialized view and our 60 default distributions:
CREATE MATERIALIZED VIEW dbo.v_WomenEnglishEducation
WITH (distribution = hash([Customer Education Level]))
AS
SELECT d1.EnglishEducation AS [Customer Education Level],
d1.HouseOwnerFlag as [House Owner],
COUNT(*) AS [Internet Order Quantity],
SUM(f1.SalesAmount)AS [Internet Sales Amount]
FROM [dbo].[FactInternetSales] f1
INNER JOIN [dbo].[DimCustomer] d1
ON f1.CustomerKey=d1.CustomerKey
INNER JOIN dbo.DimDate dat1
ON f1.ShipDateKey = dat1.DateKey
INNER JOIN [dbo].[DimGeography] d2
ON d1.GeographyKey=d2.GeographyKey
WHERE dat1.fiscalyear >= 2005 and dat1.fiscalyear <= 2009
AND d2.EnglishCountryRegionName<>'United States'
AND d1.Gender='F'
GROUP BY d1.EnglishEducation, d1.HouseOwnerFlag
Running a query that might benefit from the Materialized View usage won’t guarantee its actual usage, since Azure SQL DW is like Sql Server and Azure SQL Database is using Cost-Based Optimizer which means that if the estimations are showing that there will be a benefit the path will be selected, but if processing underlying base tables is still the cheapest way according to the estimations – the original path shall be used.
I guess you should not expect miracles from the Materialized Views, especially if you have worked with indexed views and know how easy it is to get a query which estimated cost will be showing towards the path of the processing the underlying base tables.
Meta Informations
There is some confusion about the details of the feature having multiple descriptions of functioning with the help of the Clustered Columnstore Index, but instead showing in the sys.indexes DMV a regular, clustered Rowstore index and so for the time being, I guess there is no alternative but to leave this part out until I will figure out which part is wrong actually.
Any attempt of creation of the clustered or nonclustered (secondary) indexes against the Materialized View ends with an error message:
Msg 104423, Level 16, State 1, Line 8 Creating index on a view is not supported. Please use the CREATE MATERIALIZED VIEW statement to create a materialized view.
What at the moment is available & functions is the listing of the Materialized views with the help of the following T-SQL statement (joining sys.views & sys.indexes):
SELECT V.name as materializedViewName, V.object_id FROM sys.views V JOIN sys.indexes I ON V.object_id= I.object_id AND I.index_id < 2;

providing us an insight on the views that have indexes ... and I explicitly opted not to include more information here since I find it confusing what kind of indexes are being used.
There are 3 new DMV's which provide some insight over the existing materialized views: sys.pdw_materialized_view_mappings, sys.pdw_materialized_view_distribution_properties & sys.pdw_materialized_view_column_distribution_properties - providing the insights into the physical object name, distribution properties (Hash/Round Robin) used for the materialized view creation, and the details on the columns that are part of this materialised view.
select * from sys.pdw_materialized_view_mappings; select * from sys.pdw_materialized_view_distribution_properties; select * from sys.pdw_materialized_view_column_distribution_properties;
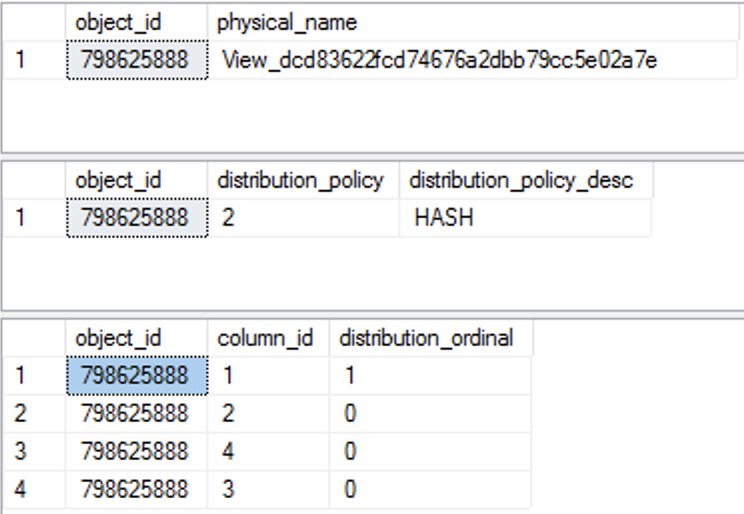 From this properties you can derive your own conclusions and/or actions. Joining this different DMV's to provide more insight soon the used distribution and the ordinal column keys (just join the output of the sys.pdw_materialized_view_column_distribution_properties to the respective sys.columns DMV by the object_id and the column_id) seems to be a rather trivial task, WHICH I have to admit are not too many in the Azure SQL DW DMVs, given that they have had even some rather strong incompatible changes (or maybe simply the documentation was not up to game) - I am not able to distinguish the reasons.
From this properties you can derive your own conclusions and/or actions. Joining this different DMV's to provide more insight soon the used distribution and the ordinal column keys (just join the output of the sys.pdw_materialized_view_column_distribution_properties to the respective sys.columns DMV by the object_id and the column_id) seems to be a rather trivial task, WHICH I have to admit are not too many in the Azure SQL DW DMVs, given that they have had even some rather strong incompatible changes (or maybe simply the documentation was not up to game) - I am not able to distinguish the reasons.
About MIN & MAX
The inability of the indexed views to deal with the MIN & MAX calculations is being known for many years and hence while the following setup script that I have executed against the latest & greatest Sql Server 2019 instance on Azure VM works:
CREATE TABLE dbo.SrcDataTable (
C1 BIGINT NOT NULL
)
SET NOCOUNT ON
INSERT INTO dbo.SrcDataTable
SELECT t.RN
FROM
(
SELECT TOP (10 * 1048576) ROW_NUMBER()
OVER (ORDER BY (SELECT NULL)) RN
FROM sys.objects t1
CROSS JOIN sys.objects t2
CROSS JOIN sys.objects t3
CROSS JOIN sys.objects t4
CROSS JOIN sys.objects t5
CROSS JOIN sys.objects t6
CROSS JOIN sys.objects t7
CROSS JOIN sys.objects t8
) t
OPTION (MAXDOP 1);
CREATE CLUSTERED COLUMNSTORE INDEX cci_SrcDataTable ON dbo.SrcDataTable;
DROP VIEW IF EXISTS dbo.vMaxTest;
GO
CREATE VIEW dbo.vMaxTest
WITH SCHEMABINDING
AS
SELECT MAX(c1) as MaxC1
FROM dbo.SrcDataTable;
GO
Any attempt to create a physical UNIQUE clustered index will fail
CREATE UNIQUE CLUSTERED INDEX CLIX_vMaxTest ON dbo.vMaxTest (MaxC1)
with the following error message:

while in Azure SQL DW we are able to create a source table with 60 million rows, since I want to have a reasonably good distribution Row Group sizes:
DROP TABLE dbo.SampleDataTable;
CREATE TABLE dbo.SampleDataTable (
C1 BIGINT NOT NULL
)WITH (HEAP);
SET NOCOUNT ON
INSERT INTO dbo.SampleDataTable
SELECT t.RN
FROM
(
SELECT TOP (60 * 1048576) ROW_NUMBER()
OVER (ORDER BY (SELECT NULL)) RN
FROM sys.objects t1
CROSS JOIN sys.objects t2
CROSS JOIN sys.objects t3
CROSS JOIN sys.objects t4
CROSS JOIN sys.objects t5
CROSS JOIN sys.objects t6
CROSS JOIN sys.objects t7
CROSS JOIN sys.objects t8
) t
OPTION (MAXDOP 1);
CREATE CLUSTERED COLUMNSTORE INDEX cci_SampleDataTable ON dbo.SampleDataTable;
we can ALMOST advance to create our newly baked materialized view with the following almost default code:
CREATE MATERIALIZED VIEW dbo.vMaxTest WITH (distribution = round_robin) AS SELECT MAX(c1) as MaxC1 FROM dbo.SampleDataTable;
but the below presented error message
![]()
indicates us that we need to add a specific reserved word FOR_APPEND, which apparently should serve for better selection of the processing algorithm and thus enabling to do the job efficiently.
Why is it not determined by the creation automatically is something that really boggles my mind.
Let's add the desired keyword FOR_APPEND then to our materialized view definition:
CREATE MATERIALIZED VIEW dbo.vMaxTest WITH (distribution = round_robin, FOR_APPEND) AS SELECT MAX(c1) as MaxC1 FROM dbo.SampleDataTable;
and voilá - the creation process runs until completion without any problem at all. This is an interesting requirement and I am wondering if in time it will be superseded by different keywords, such as FOR_ALL or FOR_UPDATE.
Running this calculation against the table will result in the access (GET) of the materialized view as you can see from the execution plan below:
SELECT MAX(c1) as MaxC1 FROM dbo.SampleDataTable;
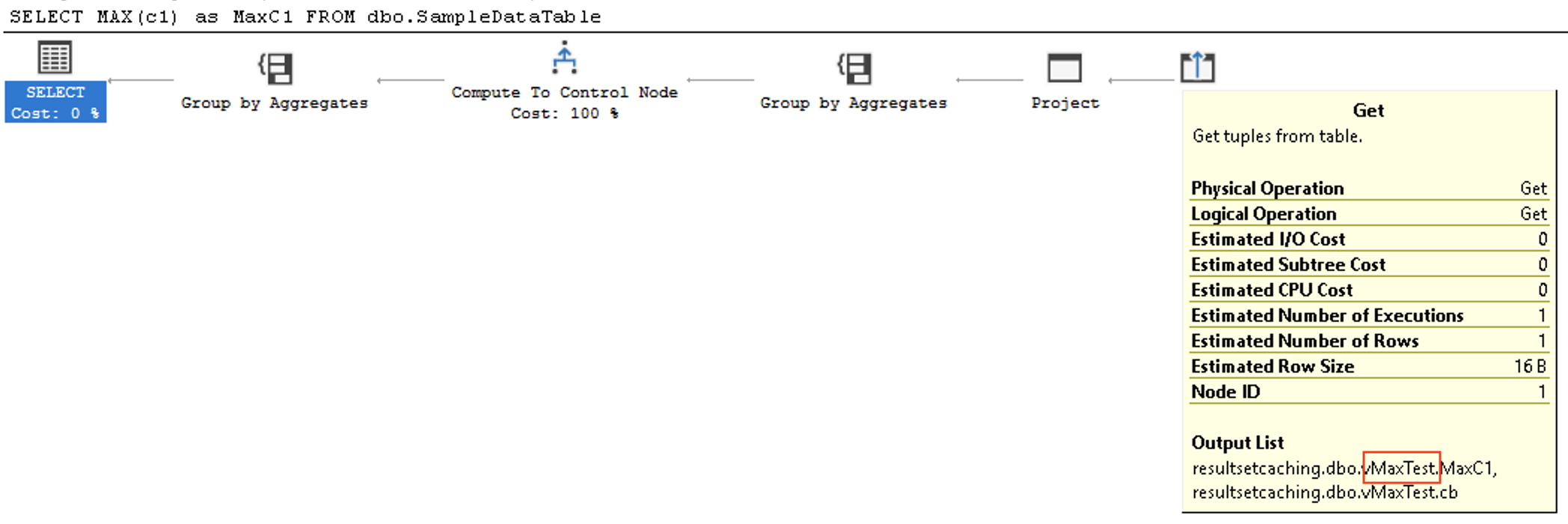
As marked with a red rectangle you can see the access method reaching out to the vMaxTest object instead of the
At the moment, please ignore the [cb] column output, we shall dive into it in the next blog post.
EXPLAIN WITH_RECOMMENDATIONS
Besides the good old EXPLAIN command showing us the estimated execution plan, there is a new WITH_RECOMMENDATIONS argument that will show some recommendations on the improvement of the query execution.
In the output XML there is a whole new section that is dedicated to the materialised views and which will give you ideas about which materialized views might benefit your query (and take it with a grant of salt, please - if you have been using missing_index feature in Sql Server, you might remember the dark paths it would lead you into (starting with the duplicate of the already existing indexes)) and so if we re-execute the same MAX(C1) calculations in the last statement shown in this blogpost
EXPLAIN WITH_RECOMMENDATIONS SELECT MAX(c1) as MaxC1 FROM dbo.SampleDataTable
we shall get a similar kind of output where the manual processing of the query XML will be necessary :)
 This gives me an impression of well-thought user interaction (yeah, not talking about the tools here, since I would cry mostly) with the engine and with the materialized views.
This gives me an impression of well-thought user interaction (yeah, not talking about the tools here, since I would cry mostly) with the engine and with the materialized views.
DBCC PDW_SHOWMATERIALIZEDVIEWOVERHEAD
Like in the case of the Result Set Caching feature, the Materialized Views have received proper DBCC argument, this one is called PDW_SHOWMATERIALIZEDVIEWOVERHEAD, where the good old (and most probably dead as a product can be) PDW (Parallel Data Warehouse) prefix, before being rebranded to APS (sounds like a similar Azure SQL DW -> Azure Synapse Analytics story) with a number of mixed words all together ... Almost GermanLanguageWordCreationStyleIwouldSay (TM) :)
This function will show the overhead of the additional data snapshot processed. Those data snapshots will be created internally and will serve to update the original materialized view with the changes that the underlying base tables have suffered. The idea here is that starting at some certain point the efficiency of processing of those additional snapshots will become low and the re-processing and optimisation of the materialized view will become necessary.
Let us build a simple materialized view based on the AVG function:
CREATE MATERIALIZED VIEW dbo.vFuncTest WITH (distribution = round_robin) AS SELECT AVG(c1) as FuncC1 FROM dbo.SampleDataTable;
and let's see the current overhead:
DBCC PDW_SHOWMATERIALIZEDVIEWOVERHEAD (vFuncTest);

How I wish there would be a more accessible way of adding the object name instead of just object_id... Yes, storing the results in the temporary table and joining with sys.objects DMV does not sound trivial to the most people. No overhead here to be noticed ... We have a 1 to 1 mapping.
Let's update some rows and check the result:
UPDATE dbo.SampleDataTable SET C1 = C1 + 1 WHERE c1 <= 100; DBCC PDW_SHOWMATERIALIZEDVIEWOVERHEAD (vFuncTest);

Yeah, one update ... where the number of actually affected rows is irrelevant, and if we would be updating a columnstore index, then something in the DMV sys.pdw_nodes_column_store_row_groups would reflect that ... In any case let's update it again and check on the overhead:
UPDATE dbo.SampleDataTable SET C1 = C1 + 1 WHERE c1 < 1000; DBCC PDW_SHOWMATERIALIZEDVIEWOVERHEAD (vFuncTest);

This feature has a cool pedigree - we can determine if the underlying tables were changed without a huge effort, and I totally love it.
Rebuilding the view
If view will get a significant overhead or even becomes disabled manually with ALTER MATERIALIZED VIEW DISABLE or automatically (see the next blog post), then a full blown reprocessing aka REBUILD of the materialised view will be needed to get things back where they were originally (hint: one more check for the maintenance procedures!).
Let's test it out with the following code and see if it brings any improvement to the overhead of the materialized view:
ALTER MATERIALIZED VIEW dbo.vFuncTest
REBUILD;
DBCC PDW_SHOWMATERIALIZEDVIEWOVERHEAD (vFuncTest);
Beautiful!
First Impressions
Interesting feature though seems that the feature itself is more like an expansion of the indexed views to the Azure SQL DW (Azure Synapse Analytics) instead of the full-blown materialized views implementation.
I have already found some errors and limitations, which I hope to get fixed & improved - but my basic impression that this is a very useful feature and eventually, after a lot of work, it can become a very important feature for the Data Warehousing workloads.
I do not give up the hope that this feature will have a better future than the original indexed views, but only time will tell.
to be continued with Azure SQL DW Materialized Views (part 2)
I’m a fan of the DBCC command and totally agree about the lack of support for subqueries. Materialized views with subqueries would be very helpful. At one point you mentioned not being able to reference views in the definition – did you mean non-schema bound views? In indexed views, you can include schemabound views, so I would think it’s the same for materialized views…no? Thanks for the note about partitioning too and great post.
Hi Alex,
About not being able to reference views in Materialized Views: What I was referring to are the regular, non-schemabound views, since the indexed views are not supported.
You would get a similar error message if trying to refer a view in your materialized view code:
Msg 4513, Level 16, State 2, Line 6
Cannot schema bind view ‘dbo.vNewFuncs’. ‘dbo.SomeView’ is not schema bound.
Trying to create a view with SCHEMABINDING on Azure SQL DW fails with the following error message:
…
As for the subqueries – nope … not supported …
Best regards,
Niko
I so not see a point in using this feature. I can easily create a table using CTAS as well and it provides me the same time lag of data without any of the shortcomings of materialized views.
Also, I can then force any query to use the aggregated table instead of the raw table.
I think, the equivalent feature in Power bi is much better as it provides support for users, that do not know about the data architecture. These kind of folks are typically not granted access to the underlying dwh.
Hi Tarek,
the thing is – you will have to reprocess and update your CTAS manually, while the indexed views will do that for you in the background. View it as a commodity performance feature.
You can write queries against the materialized view.
Relational Platform is great at controlling permissions and so there would not be a problem.
Best regards,
Niko