Continuation from the previous 117 parts, the whole series can be found at https://www.nikoport.com/columnstore/.
As a logical continuation from the blog post Columnstore Indexes – part 91 (“SQL Server 2016 Standard Edition Limitations”), this blogpost will focus on the SQL Server 2017 and different editions – in my case I shall test Standard and Express Editions, while Enterprise/Developer Editions have received all the functionalities that I have tested before. The reason behind this attempt is to keep up with the different versions that Microsoft is launching and to provide a place for the reference. Besides that it is always nice to check on the previous versions editions limitations, you know – just in case there are some sudden, undocumented changes :)
In SQL Server 2017 these are some of the additions that were made to the Columnstore Indexes:
- NCCI Online Rebuild
- LOBs for CCI
- Computed Columns for CCI
- Trivial Plans
- Machine Learning Services
- Batch Mode Adaptive Joins
- Batch Mode Memory Grant Feedback
and so let us start going through them 1 by 1, but before that let us setup 2 Virtual Machine with SQL Server 2017 RTM Enterprise & Standard Editions (and I will use Azure for that purpose), or you can install them both parallel on the same VM.
The almost everlasting free database ContosoRetailDW & TPCH 1 GB (generated by free utility HammerDB) will be used again for the tests. Notice that as always in my blog posts, I am using the backup from the C:\Install\ folder:
USE [master]
alter database ContosoRetailDW
set SINGLE_USER WITH ROLLBACK IMMEDIATE;
RESTORE DATABASE [ContosoRetailDW]
FROM DISK = N'C:\Install\ContosoRetailDW.bak' WITH FILE = 1,
MOVE N'ContosoRetailDW2.0' TO N'C:\Data\ContosoRetailDW.mdf',
MOVE N'ContosoRetailDW2.0_log' TO N'C:\Data\ContosoRetailDW.ldf',
NOUNLOAD, STATS = 5;
alter database ContosoRetailDW
set MULTI_USER;
GO
GO
ALTER DATABASE [ContosoRetailDW] SET COMPATIBILITY_LEVEL = 140
GO
ALTER DATABASE [ContosoRetailDW] MODIFY FILE ( NAME = N'ContosoRetailDW2.0', SIZE = 2000000KB , FILEGROWTH = 128000KB )
GO
ALTER DATABASE [ContosoRetailDW] MODIFY FILE ( NAME = N'ContosoRetailDW2.0_log', SIZE = 400000KB , FILEGROWTH = 256000KB )
GO
Now, let us drop the primary key on the FactOnlineSales table and create a Clustered Columnstore Index on this table:
use ContosoRetailDW; GO ALTER TABLE dbo.[FactOnlineSales] DROP CONSTRAINT [PK_FactOnlineSales_SalesKey]; create clustered columnstore Index PK_FactOnlineSales on dbo.FactOnlineSales;
For the TPCH 1 GB Version, here is the setup script that will be useful for the examples below:
/*
* This script restores backup of the TPC-H Database from the C:\Install
*/
USE [master]
if exists(select * from sys.databases where name = 'tpch')
begin
alter database [tpch]
set SINGLE_USER WITH ROLLBACK IMMEDIATE;
end
RESTORE DATABASE [tpch]
FROM DISK = N'C:\Install\tpch_1g.bak' WITH FILE = 1, NOUNLOAD, STATS = 1
alter database [tpch]
set MULTI_USER;
GO
-- SQL Server 2017
ALTER DATABASE [tpch] SET COMPATIBILITY_LEVEL = 140
GO
USE [tpch]
GO
EXEC dbo.sp_changedbowner @loginame = N'sa', @map = false
GO
USE [master]
GO
ALTER DATABASE [tpch] MODIFY FILE ( NAME = N'tpch', FILEGROWTH = 256152KB )
GO
ALTER DATABASE [tpch] MODIFY FILE ( NAME = N'tpch_log', SIZE = 1200152KB , FILEGROWTH = 256000KB )
GO
-- Create Clustered Columnstore Index table as a copy of line item:
-- Data Loding
SELECT [l_shipdate]
,[l_orderkey]
,[l_discount]
,[l_extendedprice]
,[l_suppkey]
,[l_quantity]
,[l_returnflag]
,[l_partkey]
,[l_linestatus]
,[l_tax]
,[l_commitdate]
,[l_receiptdate]
,[l_shipmode]
,[l_linenumber]
,[l_shipinstruct]
,[l_comment]
into dbo.lineitem_cci
FROM [dbo].[lineitem];
GO
-- Create Clustered Columnstore Index
create clustered columnstore index cci_lineitem_cci
on dbo.lineitem_cci;
Nonclustered Columnstore Index Online Rebuild
The detailed description and the tests against the Enterprise Edition can be found at Columnstore Indexes – part 96 (“Nonclustered Columnstore Index Online Rebuild”)
Attempting creating a Nonclustered Columnstore Index with the following code
CREATE NONCLUSTERED COLUMNSTORE INDEX NCCI_FactOnlineSales ON dbo.FactOnlineSales (OnlineSalesKey, DateKey, StoreKey, ProductKey, PromotionKey, CurrencyKey, CustomerKey, SalesOrderNumber, SalesOrderLineNumber, SalesQuantity, SalesAmount, ReturnQuantity, ReturnAmount, DiscountQuantity, DiscountAmount, TotalCost, UnitCost, UnitPrice, ETLLoadID, LoadDate, UpdateDate) WITH (ONLINE = ON, DROP_EXISTING = ON);
on the SQL Server 2017 Standard and on the SQL Server 2017 Express Edition, will provoke the following error message, delivering very clearly the message that this functionality is not supported:
Msg 1712, Level 16, State 1, Line 3 Online index operations can only be performed in Enterprise edition of SQL Server.
This is totally expected, since Online operations were always part of the enterprise edition, and having a particular index support operation ported to any other edition would be something beyond any surprise.
Large object binaries (LOBs) for Clustered Columnstore Index
Described already in Columnstore Indexes – part 92 (“Lobs”), the supported for the Large Object Binaries was missing for the Data Warehouse scenario since the very first version of the SQL Server with Columnstore Indexes (SQL Server 2012) until finally in SQL Server 2017 we have received this functionality.
Though very much limited with the compression engine (LOBs over 8MB are getting less to progressively no compression), they allow to unlock a couple of key scenarios, such as where some design mistakes were made and it is too expensive at the moment to make such change.
The following script will ensure the new creation for the table ManyLobs and then inserts some data into it:
drop table if exists dbo.ManyLobs;
create table dbo.ManyLobs
(
id int not null PRIMARY KEY,
LobData varchar(max) null,
Index CCI_ManyLobs CLUSTERED COLUMNSTORE
);
INSERT INTO ManyLobs
SELECT RowNumber, CAST( REPLICATE('a', RowNumber) as VARCHAR(MAX))
FROM (
SELECT TOP (1048576) ROW_NUMBER()
OVER (ORDER BY (SELECT NULL)) as RowNumber
FROM master..spt_values t1
CROSS JOIN master..spt_values t2
) subquery;
It might take a while for this code to finish, but it works fine on the Standard Edition of SQL Server 2017 as well as on the Express Edition of the SQL Server 2017 RTM.
This is also quite expected functionality, since it makes absolutely no sense to limit Data Type usage on the particular version of the SQL Server. Especially since Service Pack 1 for SQL Server 2016, which democratised the usage of the programming surface for every edition, as explained in SQL Server 2016 SP1 – Programmability Surface for everyone!
Computed Columns for Clustered Columnstore Indexes
One of the very late addition to the SQL Server 2017 engine, the Clustered Columnstore Indexes started supporting non-persisted computed columns as described in Columnstore Indexes – part 108 (“Computed Columns”).
To test the computed columns I went with the script, borrowed from the original blog post, that creates a copy of the FactOnlineSales table with a non-persisted computed column:
DROP TABLE IF EXISTS [dbo].[FactOnlineSales_Computed]; CREATE TABLE [dbo].[FactOnlineSales_Computed]( [OnlineSalesKey] [int] NOT NULL, [DateKey] [datetime] NOT NULL, [StoreKey] [int] NOT NULL, [ProductKey] [int] NOT NULL, [PromotionKey] [int] NOT NULL, [CurrencyKey] [int] NOT NULL, [CustomerKey] [int] NOT NULL, [SalesOrderNumber] [nvarchar](20) NOT NULL, [SalesOrderLineNumber] [int] NULL, [SalesQuantity] [int] NOT NULL, [SalesAmount] [money] NOT NULL, [ReturnQuantity] [int] NOT NULL, [ReturnAmount] [money] NULL, [DiscountQuantity] [int] NULL, [DiscountAmount] [money] NULL, [TotalCost] [money] NOT NULL, [UnitCost] [money] NULL, [UnitPrice] [money] NULL, [ETLLoadID] [int] NULL, [LoadDate] [datetime] NULL, [UpdateDate] [datetime] NULL, [EarnedAmount] as ([SalesAmount] - [ReturnAmount] - [DiscountAmount] - [TotalCost]) ) ON [PRIMARY] TRUNCATE TABLE [dbo].[FactOnlineSales_Computed] ; insert into [dbo].[FactOnlineSales_Computed] with (tablockx) (OnlineSalesKey, DateKey, StoreKey, ProductKey, PromotionKey, CurrencyKey, CustomerKey, SalesOrderNumber, SalesOrderLineNumber, SalesQuantity, SalesAmount, ReturnQuantity, ReturnAmount, DiscountQuantity, DiscountAmount, TotalCost, UnitCost, UnitPrice, ETLLoadID, LoadDate, UpdateDate) select OnlineSalesKey, DateKey, StoreKey, ProductKey, PromotionKey, CurrencyKey, CustomerKey, SalesOrderNumber, SalesOrderLineNumber, SalesQuantity, SalesAmount, ReturnQuantity, ReturnAmount, DiscountQuantity, DiscountAmount, TotalCost, UnitCost, UnitPrice, ETLLoadID, LoadDate, UpdateDate from dbo.FactOnlineSales create clustered index PK_FactOnlineSales_Computed on dbo.FactOnlineSales_Computed (OnlineSalesKey) with (data_compression = page); create clustered columnstore index PK_FactOnlineSales_Computed on dbo.FactOnlineSales_Computed with (drop_existing = on, maxdop = 1);
On both Standard & Express Editions of SQL Server 2017 this script was executed successfully, leaving no doubts about the feature support. Like in the case of the of the Large object binaries (LOBs) for Clustered Columnstore Index, this is a programability feature which must be supported in all SQL Server editions in SQL Server 2017 and t works perfectly.
Trivial Plans
One rather small (relatively other features, as I imagine), but an incredibly useful improvement was described in Columnstore Indexes – part 109 (“Trivial Plans in SQL Server 2017”) – is the ability to automatically produce Fully Optimised execution plans for the Database, which compatibility level is set to 140.
Running on both instances (Standard & Express), the following script, while altering the compatibility level between 140 (SQL Server 2017) & 130 (SQL Server 2016), will produce different execution plan for the SELECT COUNT_BIG(*) operation – the fast one (with FULL optimisation in 140 compatibility level) and slow one (with TRIVIAL optimisation in 130 compatibility level):
EXEC sys.sp_configure N'show advanced options', N'1'; RECONFIGURE; GO EXEC sys.sp_configure N'cost threshold for parallelism', N'50' RECONFIGURE WITH OVERRIDE GO ALTER DATABASE [ContosoRetailDW] SET COMPATIBILITY_LEVEL = 130; SELECT COUNT_BIG(*) FROM dbo.FactOnlineSales;
SQL Express Full Plan
SQL Express Trivial Plan
You can see the fully optimised execution plan and the trivial execution plan on the left side of this text, both were taken from the SQL Server 2017 Express Edition.
At the end of the experiments, please, do not forget to set the compatibility level back to SQL Server 2017:
ALTER DATABASE [ContosoRetailDW] SET COMPATIBILITY_LEVEL = 140;
I am happy that this feature has got no Edition dependence, this is a needed improvement that simply increases the value of the offer and can actually be achieved in a lot of different ways, event without parallelism kicking in.
Described in Columnstore Indexes – part 114 (“Machine Learning Services”), the improvement for the Columnstore Indexes in SQL Server 2017
While the Standard Edition of the SQL Server 2017 supports Machine Learning Services (In-Database), there is no such option for the Express Edition of the SQL Server 2017, because for that purpose you will need Express Edition with Advanced Services.
The setup script that should be executed is the following one – it creates a new table with 1048576 rows:
DROP TABLE IF EXISTS dbo.SampleDataTable
CREATE TABLE dbo.SampleDataTable (
C1 BIGINT NOT NULL,
INDEX CCI_SampleDataTable CLUSTERED COLUMNSTORE
);
TRUNCATE TABLE SampleDataTable;
INSERT INTO dbo.SampleDataTable WITH (TABLOCK)
SELECT
t.RN
FROM
(
SELECT TOP (1 * 1048576) ROW_NUMBER()
OVER (ORDER BY (SELECT NULL)) RN
FROM master..spt_values t1
CROSS JOIN master..spt_values t2
CROSS JOIN master..spt_values t3
) t
OPTION (MAXDOP 1);
The test scripts work perfectly for all supported editions, enabling Batch Mode execution for the UDX iterator, transferring data to and from Machine Learning Services, of course only for the Compatibility Level of 140 set for the database
SET STATISTICS TIME, IO ON
ALTER DATABASE [ContosoRetailDW] SET COMPATIBILITY_LEVEL = 130
GO
EXECUTE sp_execute_external_script
@language = N'R'
,@script=N'OutputDataSet<-InputDataSet;'
,@input_data_1 = N'SELECT C1 FROM dbo.SampleDataTable'
WITH RESULT SETS ( (c1 INT) );
ALTER DATABASE [ContosoRetailDW] SET COMPATIBILITY_LEVEL = 140
GO
EXECUTE sp_execute_external_script
@language = N'R'
,@script=N'OutputDataSet<-InputDataSet;'
,@input_data_1 = N'SELECT C1 FROM dbo.SampleDataTable'
WITH RESULT SETS ( (c1 INT) );
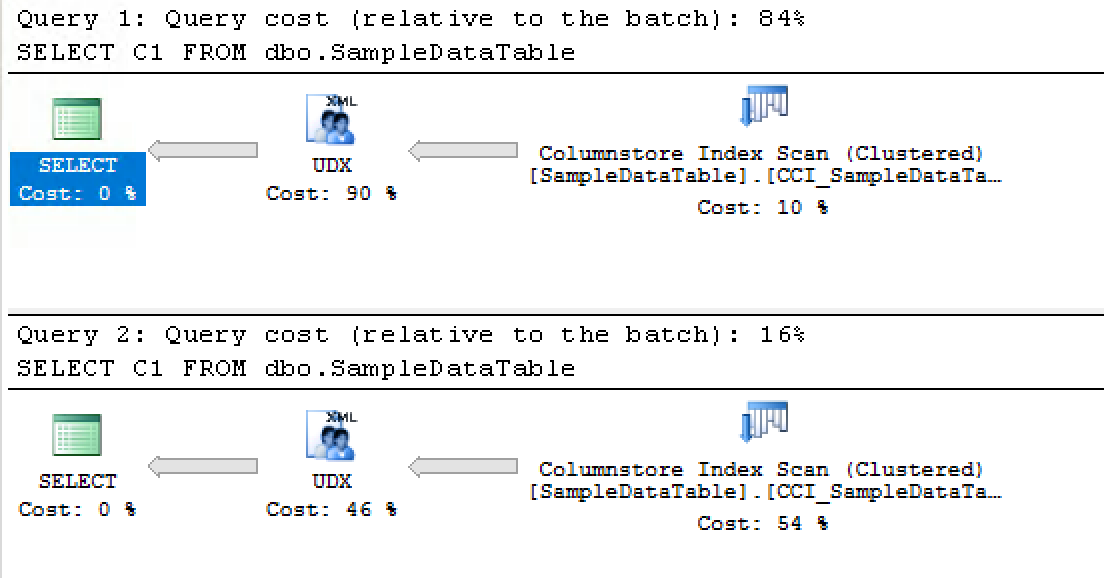
Batch Mode Memory Grant Feedback
Originally described in Columnstore Indexes – part 93 (“Batch Mode Adaptive Memory Grant Feedback”), the very first available improvement of the Adaptive Query Optimiser in SQL Server 2017 - this was the incredible improvement and I remember putting it to work in the January 2017 on the production instance of Azure SQL Database. :)
Picking the query from the original article and modifying it a little bit (with MAXDOP = 1) so that it would be comparable to the Standard Edition of the SQL Server - I will be running the following query against all 3 instances with different editions (Enterprise, Standard & Express) of SQL Server 2017, while measuring the memory grants:
select prod.ProductName, sum(sales.SalesAmount) from dbo.FactOnlineSales sales inner join dbo.DimProduct prod on sales.ProductKey = prod.ProductKey inner join dbo.DimCurrency cur on sales.CurrencyKey = cur.CurrencyKey inner join dbo.DimPromotion prom on sales.PromotionKey = prom.PromotionKey where cur.CurrencyName = 'USD' and prom.EndDate >= '2004-01-01' group by prod.ProductName option (maxdop 1);
 While the execution plans differ (this execution plan has an Adaptive Query Joins on the Enterprise Edition), the memory grant size on the Enterprise edition on the original execution 76 MB, but after a couple of consecutive executions it will eventually lower to 7.3 MB, more than times improvement, because actually not much more than 2 MB of memory will be needed for the successful execution of this plan.
While the execution plans differ (this execution plan has an Adaptive Query Joins on the Enterprise Edition), the memory grant size on the Enterprise edition on the original execution 76 MB, but after a couple of consecutive executions it will eventually lower to 7.3 MB, more than times improvement, because actually not much more than 2 MB of memory will be needed for the successful execution of this plan.

On the Standard Edition, the original plan will not get modified, no matter how often we shall run the above query - the excessive memory grant warning will remain

You can see a more detailed part of the execution plan on below, where the SELECT iterator is presented with the excessive memory grant warning, as shown above:
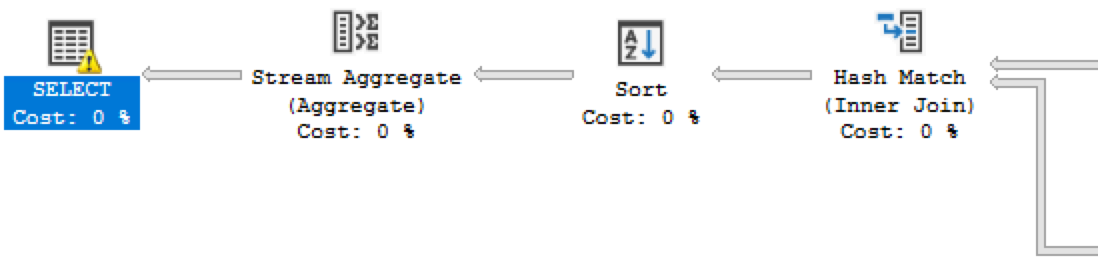
On the Express Edition the situation is even simpler, there is not really much of memory to play with - the instance memory cap of 1GB would make the adjustment attempts look quite miserable and because standard edition does not support this feature, the lower (and actually free) edition does not support as well.
Even though I would love to have Batch Mode Memory Grant Feedback on every single edition, I am fine with this feature being currently a part of the premium (aka Enterprise Edition) subset.
Batch Mode Adaptive Joins
The second Adaptive Query Processor improvement that was described in Columnstore Indexes – part 104 (“Batch Mode Adaptive Joins”), it is a feature that allows to choose the execution path of the particular execution plan dynamically, during its execution.
In SQL Server 2017 we have support for the plans involving Columnstore Indexes only, but it was already announced that in the SQL Server vNext there will be an expansion for this functionality over to the Rowstore Indexes. In short, when we have a Columnstore Index Scan in Batch Mode and a potential choice between Inner Loop Join and a Hash Match, this choice will be done, based on specific cardinality estimations.
To test it, I will use the original queries from my blog post on the TPCH 1GB database:
declare @discount money; select @discount = l_discount from dbo.lineitem_cci l inner join dbo.supplier sup on l.l_suppkey = sup.s_suppkey where l.l_shipdate = '1998-01-01'
You can see from the execution plans below, that the Standard Edition (and Express Edition as well) does not support Adaptive Query Joins currently.
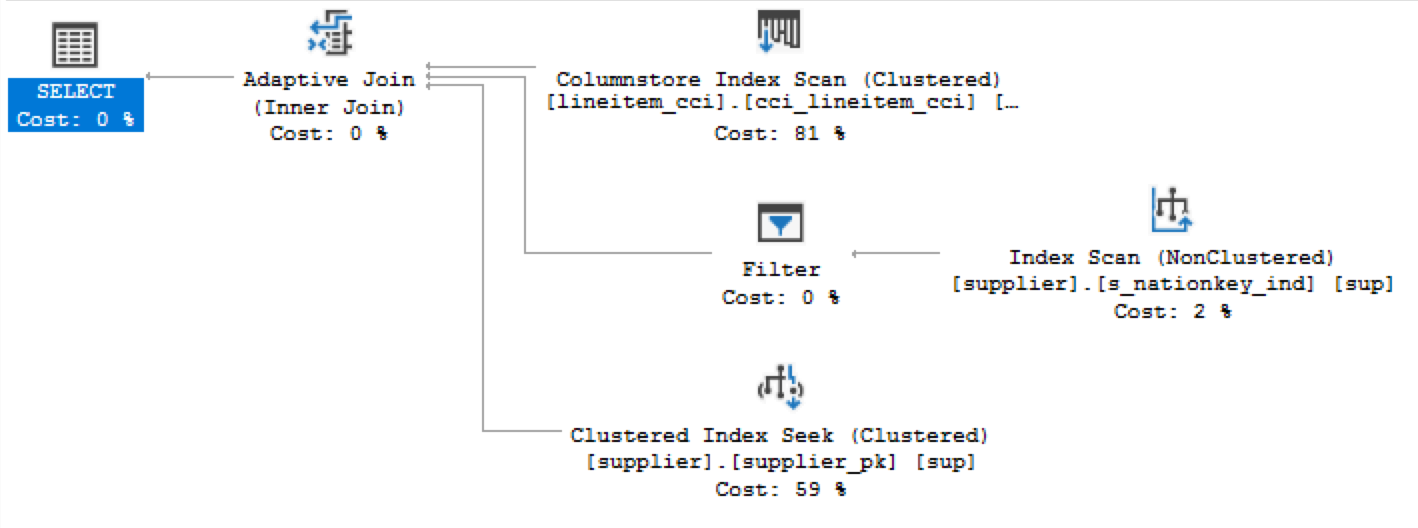
Batch Mode Adaptive Joins - Enterprise Edition

Batch Mode Adaptive Joins - Standard Edition
Unfortunately from my tests I have confirmed that Batch Mode Adaptive Joins are exclusive to the Enterprise Edition of the SQL Server 2017.
Since this functionality falls under intelligent database, I understand why Microsoft decided currently to implement it only for the Enterprise Edition and I consider it to be a true enterprise solution.
The SQL Server 2016 functionalities in SQL Server 2017
Passing through the SQL Server 2016 Enterprise-only functionalities, I decided to check how do they changed in SQL Server 2017, and here are the list of the original Service Pack 1 enablement, making Columnstore Indexes being part of every SQL Server 2016 SP1 edition:
– Columnstore Object Pool = 32 GB
– MAXDOP = 2 (for Standard Edition) and 1 (for all other editions)
– Aggregate Pushdown
– Local Aggregation
– String Predicate Pushdown
– Index Build/Rebuild = Limited to 1 Core
– SIMD Support
while I also decided to add and test one still not documented item
- the Nonclustered Columnstore Index on Indexed View
Regarding the Columnstore Object Pool memory cap, there is not much to add, besides that this number is great and for the total maximum size of the Buffer Pool of 128GB, I have not seen or heard anyone mentioning that the Columnstore Object Pool would be anywhere near the 32GB so far. This is a very generous cap and I hope that it will be taken advantage with better memory assignments for the Columnstore Indexes.
I understand that someone building a Data Warehouse should consider going Enterprise Edition, but its price is absolutely out of question for the medium and small businesses. I expect Azure SQL Database to provide a very capable answer, but not everyone is ready/can/legally allowed to migrate their precious data to the cloud just yet.
The MAXDOP = 2 of the Columnstore Indexes has been a pretty constant and no tests of mine has managed to take the SQL Server into exhibit more cores being available for processing.
Aggregate Pushdown
Originally described in 2015, Columnstore Indexes – part 59 (“Aggregate Pushdown”), Aggregate Pushdown is one incredible functionality that can potentially elevate the performance of the Columnstore Queries to the unbelievable level, executing simple aggregation operations on the Storage Engine level, not pushing millions of rows from the Columnstore Index Scan into the Hash Match aggregation iterator, but already delivering calculated result.
Here is a simple query, that delivers quite distinct execution plans
select max(SalesQuantity)
from dbo.FactOnlineSales;
On the screenshots below you can see the difference between the Enterprise Edition execution plan (the first one) and the Standard/Express Editions execution plan (the second image):


Nothing has changed here from SQL Server 2016 and I honestly would love to see this functionality to be added at least to the Standard Edition, I do not expect this to change anytime soon or not so soon.
Local Aggregation
Local aggregation is actually a very close "relative" to the Aggregate Pushdown, it is also enables to aggregate some of the data at the Storage Engine before pushing it all into the execution plans, and some of the partial aggregation (with GROUP BY, for example) shall be perfectly fitted for it.
For more detailed description follow the Columnstore Indexes – part 80 (“Local Aggregation”).
Let us execute a simple aggregation query against the FactOnlineSales table with a GROUP BY, which shall result in a partial local aggregation of the retrieved information.
select sales.ProductKey, sum(sales.SalesQuantity) from dbo.FactOnlineSales sales group by sales.ProductKey;
The execution plans for the Enterprise (the first image) and the Standard/Express editions (the second image) are presented below:

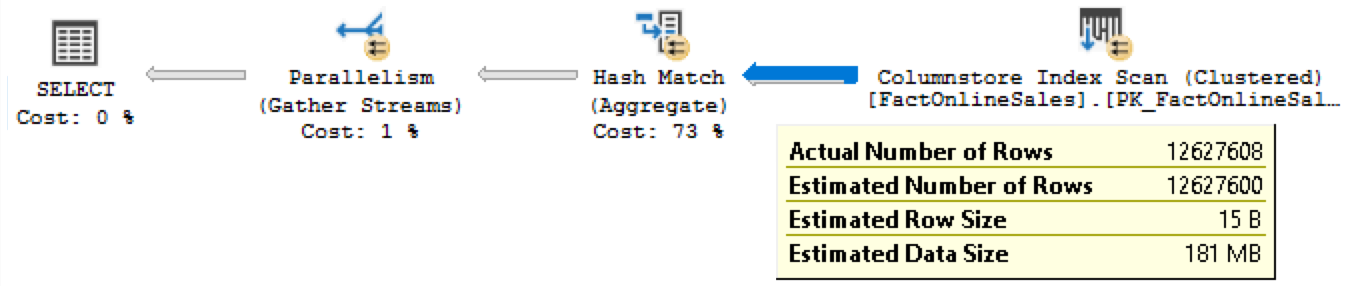
On the first image (Enterprise Edition) you can see that 230609 rows were locally aggregated and simply the result was passed to the Hash Match iterator, while the second image contains the total number of rows from the FactOnlineSales table being pushed into the Hash Match iterator (12627608 rows).
No surprises here, I expect actually the same feature doing the Aggregate Pushdown and so
String Predicate Pushdown
A rather late implementation but an incredibly smart one that the String Predicate Pushdown is. Filtering the searched information through the usage of the dictionaries and elimination of the affected Row Groups is a very smart thing to do, no doubt!
If you are interested in the details, please consult the blogpost Columnstore Indexes – part 58 (“String Predicate Pushdown”), because here I am more interested in testing the support of the different SQL Server 2017 editions:
select sum(SalesAmount), sum(SalesAmount) - sum(SalesAmount*prom.DiscountPercent) from dbo.FactOnlineSales sales inner join dbo.DimPromotion prom on sales.PromotionKey = prom.PromotionKey where SalesOrderNumber like N'2008%' and SalesOrderNumber not like N'%000' option (recompile, maxdop 2);
The execution plans are presented below and you can easily identify the filter operation that distinguished the Standard & Express Edition execution plans:

String Predicate Pushdown - Standard & Express (where Express would simply be Single-Core Execution Plan

String Predicate Pushdown - Enterprise
On the performance side the difference for the given set of data is more than 2 times, the Enterprise Edition is driving through the other editions.
A rather interesting note in my experience is that the Express Edition was capable of delivering an incredibly similar result, even though running with just 1 core the same data that the Standard Edition processed in parallel ...
This is THE FEATURE I would love to see in the Standard & Express Edition as soon as possible. Given the lack of support for the String Row Group Elimination or Joins (to start a few of the cases), I can not consider this option to be a premium one. This should be the most basic Batch Mode functionality and it makes me sad that Microsoft decided to make it Enterprise only ... and not changing their mind for SQL Server 2017. :(
Index Build/Rebuild = Limited to 1 Core
No changes.
SIMD Support
There will be an additional post dedicated to this topic.
The Nonclustered Columnstore Index on Indexed View
The not really documented and not very fast functioning Nonclustered Columnstore Index on the Indexed Views is another feature that I wanted to make sure that worked fine with Standard & Express Editions and for the description and more detailed thoughts in Columnstore Indexes – part 87 (“Indexed Views”)
Below is a little setup script to create an indexed view on our FactOnlineSales table that is joined to the DimProduct, with a unique clustered Rowstore index and Nonclustered Columnstore Index over the columns DateKey & SumTotal.
create view dbo.vFactOnlineSales WITH SCHEMABINDING AS select DateKey, SUM(SalesAmount) as SumTotal, COUNT_BIG(*) as CountBig from dbo.FactOnlineSales sales inner join dbo.DimProduct prod on sales.ProductKey = prod.ProductKey group by DateKey; create unique clustered index pk_vFactOnlineSales on dbo.vFactOnlineSales (DateKey) create nonclustered columnstore index cci_vFactOnlineSales on dbo.vFactOnlineSales (DateKey,SumTotal)
One very important thing to consider is that our test query against the index view on the Standard & Express Editions should consider including NOEXPAND hint, forcing the usage of the Indexed View. This hint is not necessary for the Enterprise Edition, but this is a different conversation and if you are choosing the Indexed Views architecture, you definitely should consider reviewing your application logic:
select Month(Datekey), Sum(SumTotal) from dbo.vFactOnlineSales WITH (NOEXPAND) group by Month(Datekey) order by Sum(SumTotal) desc
You will find the execution plan from the Standard Edition below - it just works. Yes, I know - Just Works is a harsh statement when considering the performance aspects of this implementation, but hey - there are scenarios when building it after the data modification is totally worth it!

:) It just works ;)
------
Final Thoughts
I have compiled a small table with the Columnstore functionalities, and the different SQL Server Editions (Enterprise, Standard, Express) where you can observe easily what is required for the feature to work (compatibility level) and the respective editions that do support or do not support it.
| Feature | Compatibility Level | Enterprise Edition | Standard Edition | Express Edition |
|---|---|---|---|---|
| NCCI Online Rebuild | - | yes | no | no |
| LOBs for CCI | - | yes | yes | yes |
| Computed Columns for CCI | - | yes | yes | yes |
| Trivial Plans | 140 | yes | yes | yes |
| Machine Learning Services | 140 | yes | yes | (no ML Services) |
| Batch Mode Adaptive Joins | 140 | yes | no | no |
| Batch Mode Memory Grant Feedback | 140 | yes | no | no |
| Aggregate Pushdown | 130+ | yes | no | no |
| Local Aggregation | 130+ | yes | no | no |
| String Predicate Pushdown | 130+ | yes | no | no |
| NCCI on the Indexed View | - | yes | yes | yes |
This blog post will be updated occasionally in the nearest future.
to be continued with Columnstore Indexes – part 119 (“In-Memory Columnstore Location”)
Another difference I discovered, BATCH vs ROW mode processing. If you take the query from your “part 66” article,
select *
from dbo.T1
inner join dbo.T2
on T1.c1 = T2.c1_t1;
the query in SQL Standard runs in “row mode” only; SQL Enterprise (Developer) runs in “batch mode”. I am seeing similar results with other queries (using COUNT DISTINCT and aggregates) on small data sets, where we experience an 86% improvement in speeds just running batch vs row mode.