Continuation from the previous 86 parts, the whole series can be found at https://www.nikoport.com/columnstore/.
A very long time desired feature from my side was something that I have described in the Connect Item – allowing calculation measures on the row group level does not seem to be getting close to the reality, or at least until the next major release, but 1 day before SQLSaturday in Munich, I have accidentally found something in the engine of the SQL Server 2016 RTM that made me very happy.
A long time requested feature of the indexed views supporting columnstore indexes was rather silently inserted into the engine and I am very excited about blogging about it.
My favourite free database ContosoRetailDW comes to the rescue once again (with the original backup being stored in C:\Install\ folder:
USE master;
alter database ContosoRetailDW
set SINGLE_USER WITH ROLLBACK IMMEDIATE;
RESTORE DATABASE [ContosoRetailDW]
FROM DISK = N'C:\Install\ContosoRetailDW.bak' WITH FILE = 1,
MOVE N'ContosoRetailDW2.0' TO N'C:\Data\ContosoRetailDW.mdf',
MOVE N'ContosoRetailDW2.0_log' TO N'C:\Data\ContosoRetailDW.ldf',
NOUNLOAD, STATS = 5;
alter database ContosoRetailDW
set MULTI_USER;
GO
Use ContosoRetailDW;
GO
ALTER DATABASE [ContosoRetailDW] SET COMPATIBILITY_LEVEL = 130
GO
ALTER DATABASE [ContosoRetailDW] MODIFY FILE ( NAME = N'ContosoRetailDW2.0', SIZE = 2000000KB , FILEGROWTH = 128000KB )
GO
ALTER DATABASE [ContosoRetailDW] MODIFY FILE ( NAME = N'ContosoRetailDW2.0_log', SIZE = 400000KB , FILEGROWTH = 256000KB )
GO
Now, let us consider the following query, which is calculating the Monthly sales for the FactOnlineSales:
select Month(Datekey), Sum(SalesAmount) from dbo.FactOnlineSales group by Month(Datekey) order by Sum(SalesAmount) desc;
which is producing the following execution plan:

On my test Virtual Machine, the above query makes lob logical reads 3988 and it takes 1750 ms of the CPU time, while lasting 604 ms. This is a pretty good result, but we can certainly improve it by creating an indexed view.
Let’s create the indexed view on our test table:
create view dbo.vFactOnlineSales WITH SCHEMABINDING AS select DateKey, SUM(SalesAmount) as SumTotal, COUNT_BIG(*) as CountBig from dbo.FactOnlineSales sales inner join dbo.DimProduct prod on sales.ProductKey = prod.ProductKey group by DateKey
This view will calculate the totals for each of the distinct dates that we have in our FactOnlineSales table.
The next step for the improvement would be to create the unique clustered rowstore index on our test view:
create unique clustered index pk_vFactOnlineSales on dbo.vFactOnlineSales (DateKey)
And now we are ready to implement the updatable nonclustered colummnstore index on this view
create nonclustered columnstore index cci_vFactOnlineSales on dbo.vFactOnlineSales (DateKey,SumTotal)
which is working perfectly without any troubles in all (tested on SQL Server 2016 CU 1).
Let’s run the sample aggregation query against our new indexed view:
select Month(Datekey), Sum(SumTotal) from dbo.vFactOnlineSales group by Month(Datekey) order by Sum(SumTotal) desc
With 166 ms spent on the query execution, 248 ms of the CPU Time and the 3976 Lob Logical Reads, the query has definitely got some small boost, but its far from the performance that an indexed view can provide and as a matter of a fact, the execution plan shows that the Query Optimiser has decided not to use our indexed view:
![]()
To solve this situation, one will have to use the NOEXPAND hint that will force the Query Optimiser (the need for it arises most probably because the total estimated cost of my query is around 0.0096…, while minimum threshold for parallelism is set to 50 :))
select Month(Datekey), Sum(SumTotal) from dbo.vFactOnlineSales with (noexpand) group by Month(Datekey) order by Sum(SumTotal) desc;
Take a look at the execution plan:

The single threaded performance is not a problem here, since we get 36 ms for the total execution time, with 0 ms of the CPU time, and … just 14 lob logical reads.
Here are the images with the achieved results for the better visualisation:
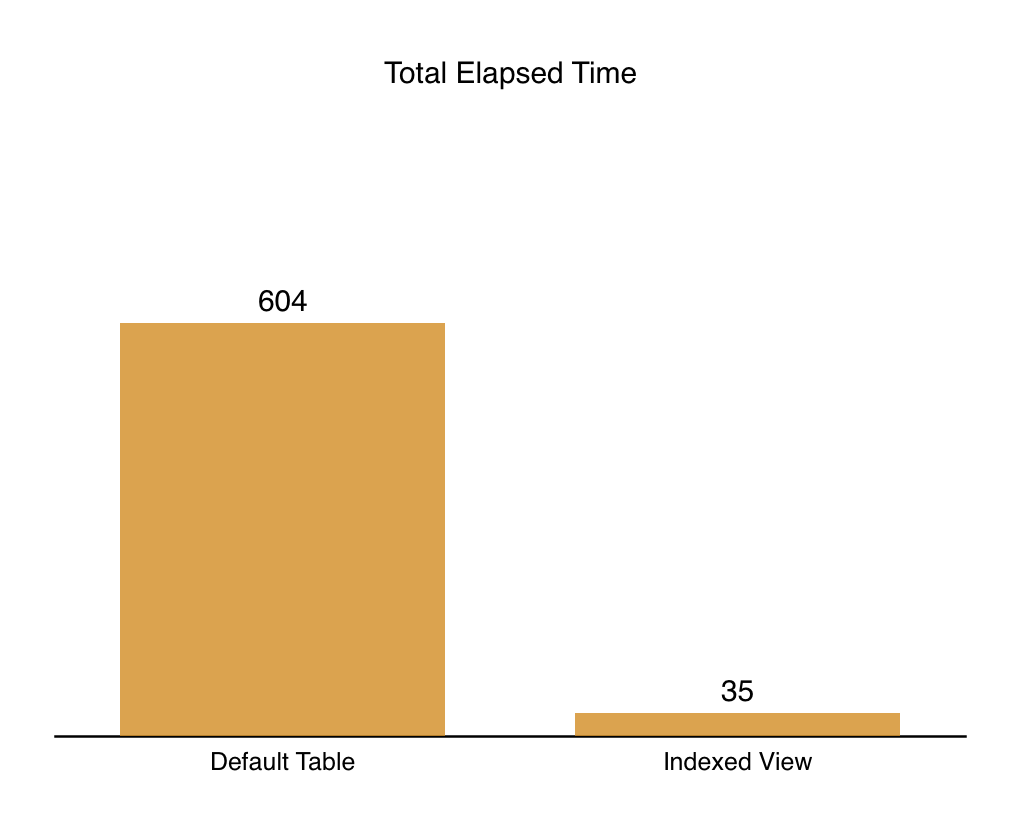 Think about this primitive example as a framework for achieving different goals, such as improving complex aggregation calculations or the problem solving of the 130 compatibility level that removed Batch Execution Mode from the processing if no columnstore indexes are involved in the query.
Think about this primitive example as a framework for achieving different goals, such as improving complex aggregation calculations or the problem solving of the 130 compatibility level that removed Batch Execution Mode from the processing if no columnstore indexes are involved in the query.
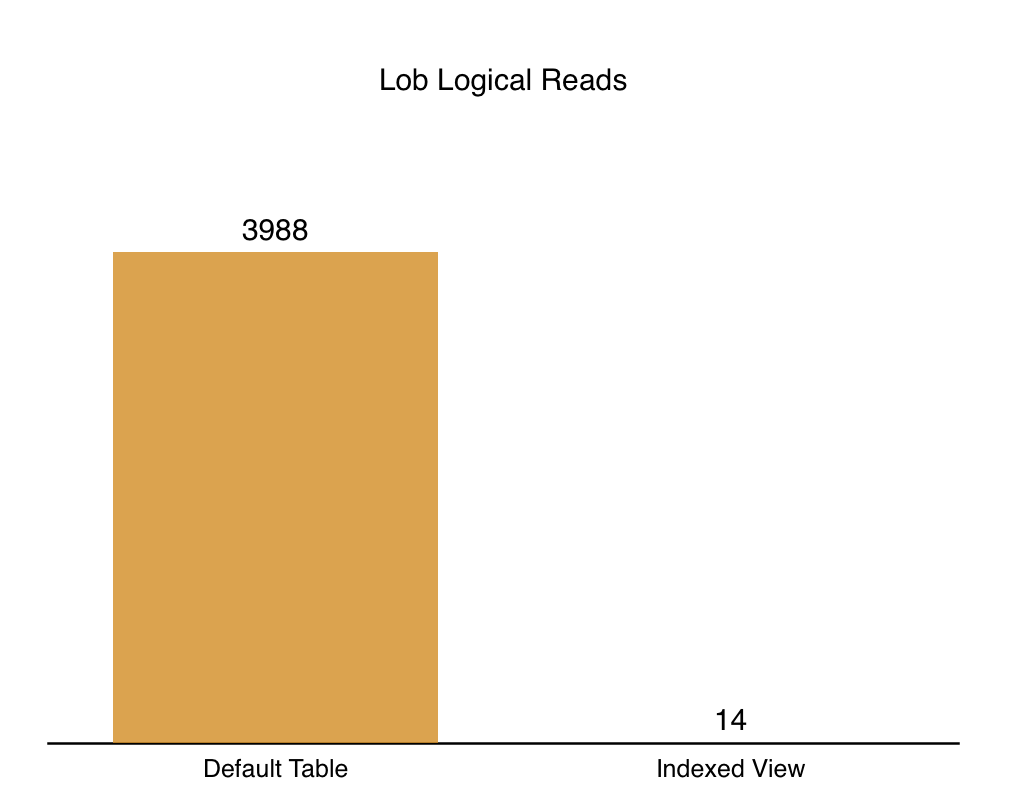
From the perspective of the disk access, this is where you will definitely win at least a couple of times with the amount of the disk access while processing the information, amount of memory that you will need to store and process (think hashing and sorting for the late materialisation phases), and you will pay less for the occupied storage.
Another noticeable thing was that the memory grants for the Indexed Views query was smaller compared to the query that was processing the original columnstore table FactOnlineSales.
Clustered Columnstore Indexes
With Nonclustered Columnstore Indexes supported for the purpose of the Indexed Views, the next logical question here is – what about the Clustered Columnstore Indexes ?
Let’s try them out on a new view, that I will call vFactOnlineSales2:
create view dbo.vFactOnlineSales2 WITH SCHEMABINDING AS select DateKey, SUM(SalesAmount) as SumTotal, COUNT_BIG(*) as CountBig from dbo.FactOnlineSales sales inner join dbo.DimProduct prod on sales.ProductKey = prod.ProductKey group by DateKey;
Let’s try to build the clustered columnstore index on it:
create clustered columnstore index cci_vFactOnlineSales on dbo.vFactOnlineSales2;
The SQL Server returns an error message for trying to execute the above operation:
Msg 35305, Level 16, State 1, Line 14
The statement failed because a columnstore index cannot be created on a view. Consider creating a columnstore index on the base table or creating an index without the COLUMNSTORE keyword on the view.
Unfortunately the Clustered Columnstore Index creation is not supported. I guess that the DEV team was waiting on finalising the Updatable Nonclustered Columnstore Index in SQL Server 2016 so that they can include support for the indexed views.
I consider the error message to be quite wrong, since it gives the wrong impression over the current state of the indexed views and their support for the Columnstore Indexes.
I could write a full blog post on the error messages in SQL Server, and who knows, maybe one day I will. :)
Final Thoughts
The existence of the updatable Columnstore Indexes (Nonclustered) in SQL Server 2016 is an incredibly pleasant surprise. I can see a lot of workloads taking advantage of this feature, and I am definitely looking forward to implement it at some of our clients.
I have digged into the internals information of the available views and the Indexed View Columnstore Index does not look different from a regular Nonclustered Columnstore Index and its functionality to my understanding and tests are equal to a typical table with the Nonclustered Columntore Index.
Consider the following script:
drop view if exists vContosoTest; GO create view dbo.vContosoTest WITH SCHEMABINDING AS select OnlineSalesKey, SalesAmount as SumC1 from dbo.FactOnlineSales create unique clustered index pk_vContosoTest on dbo.vContosoTest (OnlineSalesKey) create nonclustered columnstore index cci_vContosoTest on dbo.vContosoTest (SumC1)
Running the cstore_GetRowGroupsDetails function from the CISL, the following result can be observed.
cstore_GetRowGroupsDetails @tableName = 'vContosoTest'
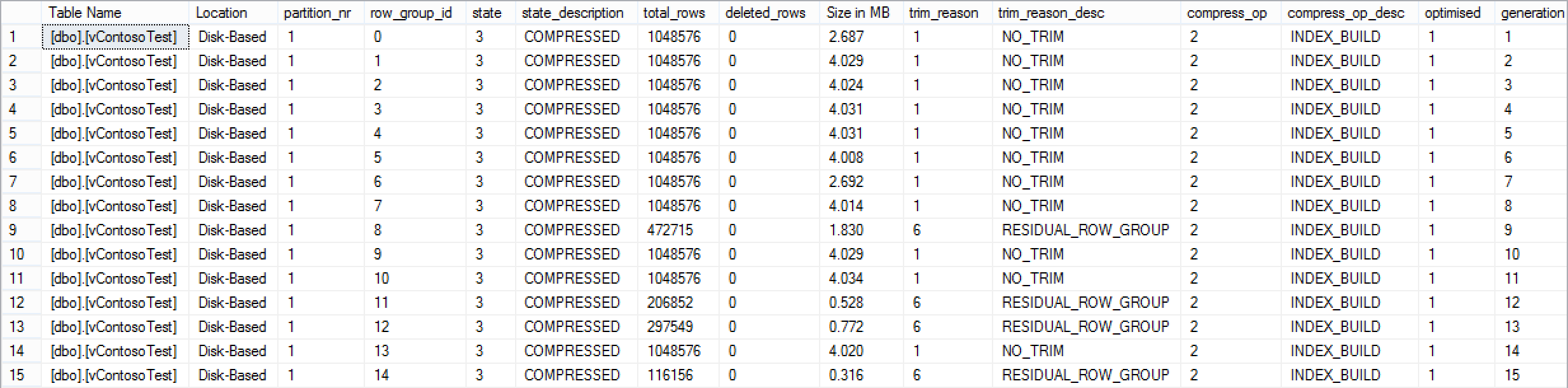
The row groups look quite normal and I guess that until something unexpected is revealed – the indexed view is just another synchronised Columnstore table.
The The CISL (Columnstore Indexes Script Library) will be updated and the upcoming 1.4.0 release will provide insight on the type of the object that it is displaying – to be more precise if we are dealing with a table or with a view that contains a Columnstore Index.
Regarding the performance – I have ran a couple of tests and so far everything seemed to extremely similar to a regular indexed view, and by all the design efforts of the Microsoft, the updatable Clustered Columnstore Index should really work this way.
to be continued with Columnstore Indexes – part 88 (“Minimal Logging in SQL Server 2016”)
The CCI should not work because it is not unique and indexed views previously required uniqueness. That’s unlikely to change.
Indexed views are a fantastic, under-used tool. I think of them as going from O(N) to O(1). The gains can be arbitrarily big. (For that reason it’s hard to make a benchmark in which the absolute perf increase is meaningful. And I’m sure you understand that.)
Hi tobi,
agree with the reasons on the CCI, though I still would love to have an option of having just them on the indexed view, paying additional penalty for the clustered index are way too much for my taste … yeah, but I am not holding my breath for that feature ;)
Best regards,
Niko Neugebauer
Congrats on all the work on these articles!
There are several things I noticed in this post:
1. The very first query plan shows columnstore index scan, where there shouldn’t be any such index (yet)?!?
2. The indexed view joins to DimProduct for no obvious reason. Perhaps there are invalid products which should be filtered out from the result? In any way, it seems redundant.
3. The columnstore index on the indexed view seems to have negligible effect on the execution and I/O. I tried the example with only a rowstore indexed view index (with no columnstore index) and the CPU time and I/O were almost exactly the same with the columnstore variation.
4. The NOEXPAND hint should not be required for Enterprise / Developer Edition of SQL Server. I tried it on Developer edition, and indeed, even without NOEXPAND, the plan uses the indexed view. The optimizer of SQL Standard does not consider indexed view indexes without NOEXPAND.
Hi Ivan,
thank you for the kind words!
Regarding your questions:
1. Nope, this is correct, we are just scanning the Columnstore index and then doing calculations over its data.
2. You are right, this is not a very smart example. I am sorry for that. As far as I remember this was a result of several modifications, which lead to a not-very-sensical result. It still serves as a technical example though.
3. Quite possible.
4. You are right regarding the Enterprise/DEV edition, but I did run on the DEV edition and for some reason it did not work. Did you tried the script against 2016 CU1 ?
Best regards,
Niko
Great article Niko, your material has been invaluable.
This is a great feature, but weirdly Visual Studio cannot deploy to any target database containing a nonclustered columnstore on an indexed view. I’m current using the latest patch on VS 2017 too.
Options are to either not use them, or use them with the knowledge any future changes to your target database will need to be done manually outside of VS. Neither is a great scenario.
Hi Lee,
thank you for the kind words,
to my knowledge what you are describing is one of the problems of the VS – so all you can do is to open a Connect Item and pressure Microsoft to solve the issues.
Best regards,
Niko Neugebauer