Continuation from the previous 96 parts, the whole series can be found at https://www.nikoport.com/columnstore/.
After many years of using & fighting the String data type in Columnstore Indexes, I have finally decided to write a blog post that is dedicated to them and show some of the cases that I have meet.
For the queries I will be using the same version generated copy of the TPCH database (1GB version), that I have used previously. If you want to have one, use the good old HammerDB (free) or any other software to generate it.
Below you will find the script for restoring the backup of TPCH from the C:\Install\
/*
* This script restores backup of the TPC-H Database from the C:\Install
*/
USE [master]
if exists(select * from sys.databases where name = 'tpch')
begin
alter database [tpch]
set SINGLE_USER WITH ROLLBACK IMMEDIATE;
end
RESTORE DATABASE [tpch]
FROM DISK = N'C:\Install\tpch_1gb_new.bak' WITH FILE = 1, NOUNLOAD, STATS = 1
alter database [tpch]
set MULTI_USER;
GO
GO
ALTER DATABASE [tpch] SET COMPATIBILITY_LEVEL = 130
GO
USE [tpch]
GO
EXEC dbo.sp_changedbowner @loginame = N'sa', @map = false
GO
USE [master]
GO
ALTER DATABASE [tpch] MODIFY FILE ( NAME = N'tpch', FILEGROWTH = 256152KB )
GO
ALTER DATABASE [tpch] MODIFY FILE ( NAME = N'tpch_log', SIZE = 1200152KB , FILEGROWTH = 256000KB )
As previously, here is the script to create a copy of Lineitem_CCI table, which is a copy of the original Lineitem table, but it includes the Clustered Columnstore index:
USE [tpch]
GO
DROP TABLE IF EXISTS dbo.lineitem_cci;
-- Data Loding
SELECT [l_shipdate]
,[l_orderkey]
,[l_discount]
,[l_extendedprice]
,[l_suppkey]
,[l_quantity]
,[l_returnflag]
,[l_partkey]
,[l_linestatus]
,[l_tax]
,[l_commitdate]
,[l_receiptdate]
,[l_shipmode]
,[l_linenumber]
,[l_shipinstruct]
,[l_comment]
into dbo.lineitem_cci
FROM [dbo].[lineitem];
GO
-- Create Clustered Columnstore Index
create clustered columnstore index cci_lineitem_cci
on dbo.lineitem_cci;
GO
String Columns in Fact Tables
Having Strings in Fact tables is something that is quite normal, but to be honest, in the most cases – does not make a lot of sense, since we are trying to keep there the information that can be calculated and/or aggregated. Notice that I have written in the most cases and NOT in all cases, because there are some noticeable exceptions. Additionally if you are “feeding” SSAS Tabular with your table this might be much easier to do it directly (hey, there is a solution through the views for that, I was told :)).
In this blog post, I am focusing not on the exceptions but on the typical cases where its not the best option and so here is a basic solution I just wanted to present you an optimised structure, which contains a tinyint column referring to the new table with distinct data for the ShipMode.
You can ensure that this is doable & make sense, by running the following query:
-- View different Ship Modes SELECT l_shipmode, COUNT(*) FROM [dbo].[lineitem_cci] GROUP BY l_shipmode
So, back to our restructured table, which I will call lineitem_cci_optimised and which will contain a substitute column l_shipmode_new differing from the original l_shipmode:
CREATE TABLE [dbo].[lineitem_cci_optimised]( [l_shipdate] [date] NULL, [l_orderkey] [bigint] NOT NULL, [l_discount] [money] NOT NULL, [l_extendedprice] [money] NOT NULL, [l_suppkey] [int] NOT NULL, [l_quantity] [bigint] NOT NULL, [l_returnflag] [char](1) NULL, [l_partkey] [bigint] NOT NULL, [l_linestatus] [char](1) NULL, [l_tax] [money] NOT NULL, [l_commitdate] [date] NULL, [l_receiptdate] [date] NULL, l_shipmode_new tinyint NOT NULL, -- Our new shipmode, stored as a tinyint column [l_linenumber] [bigint] NOT NULL, [l_shipinstruct] [char](25) NULL, [l_comment] [varchar](44) NULL ) ON [PRIMARY] GO CREATE CLUSTERED COLUMNSTORE INDEX [cci_lineitem_cci_optimised] ON [dbo].[lineitem_cci_optimised] WITH (DROP_EXISTING = OFF, COMPRESSION_DELAY = 0) ON [PRIMARY] GO
Now let’s create the Dimension table for the ShipMode, which I will call DimShipMode and let us fill it with the distinct data from the lineitem_cci table:
DROP TABLE IF EXISTS dbo.DimShipMode;
CREATE TABLE dbo.DimShipMode(
shipmode_id tinyint IDENTITY(1,1) NOT NULL PRIMARY KEY CLUSTERED,
shipmode char(10) NOT NULL );
INSERT INTO dbo.DimShipMode
(shipmode)
VALUES ('UNKNOWN');
INSERT INTO dbo.DimShipMode
(shipmode)
SELECT l_shipmode
FROM [dbo].[lineitem_cci]
GROUP BY l_shipmode;
INSERT INTO dbo.lineitem_cci_optimised
(l_shipdate, l_orderkey, l_discount, l_extendedprice, l_suppkey, l_quantity, l_returnflag, l_partkey, l_linestatus, l_tax, l_commitdate, l_receiptdate, l_shipmode_new, l_linenumber, l_shipinstruct, l_comment)
SELECT [l_shipdate]
,[l_orderkey]
,[l_discount]
,[l_extendedprice]
,[l_suppkey]
,[l_quantity]
,[l_returnflag]
,[l_partkey]
,[l_linestatus]
,[l_tax]
,[l_commitdate]
,[l_receiptdate]
,m.shipmode_id --- This is our ShipMode, but stored as a
,[l_linenumber]
,[l_shipinstruct]
,[l_comment]
FROM [tpch].[dbo].[lineitem_cci] c
INNER JOIN dbo.DimShipMode m
ON c.l_shipmode = m.shipmode;
alter table [dbo].[lineitem_cci_optimised]
WITH CHECK ADD CONSTRAINT [fk_lineitem_cci_optimised_shipmode]
FOREIGN KEY([l_shipmode_new])
REFERENCES [dbo].DimShipMode (shipmode_id);
Let’s run 2 queries comparing the performance of this 2 solutions (original one with just 1 table and the modified one with the Dimension table:
SET STATISTICS TIME, IO ON SELECT TOP 3 l_shipinstruct , SUM(l_quantity) as Quantity , COUNT(distinct l_orderkey) as DistinctOrders , MAX(l_comment) as BiggestComment FROM [dbo].[lineitem_cci] WHERE ISNULL(l_shipmode,'RAIL') = 'RAIL' and l_comment not like 'furiosly%' GROUP BY l_shipinstruct; SELECT TOP 3 l_shipinstruct , SUM(l_quantity) as Quantity , COUNT(distinct l_orderkey) as DistinctOrders5 , MAX(l_comment) as BiggestComment FROM [dbo].[lineitem_cci_optimised] cci INNER JOIN dbo.DimShipMode ship ON cci.l_shipmode_new = ship.shipmode_id WHERE ISNULL(ship.shipmode,'RAIL') = 'RAIL' and l_comment not like 'furiosly%' GROUP BY l_shipinstruct;
While the first query takes 11.5 seconds on my Virtual Machine, the second one takes only 4,5 seconds! This is a huge difference which is happening partly due to the some other string limitations, which are naturally not taking place over the dimension table – which is a regular Rowstore table.
Notice that this number were just over 2 times because I was running the query on the Developer Edition (same features as in Enterprise Edition) of SQL Server 2016 – on Standard & Express the string predicate pushdown for some parts of such queries will not work, making the first query perform even slower in comparisson.
Take a look at the execution plans:
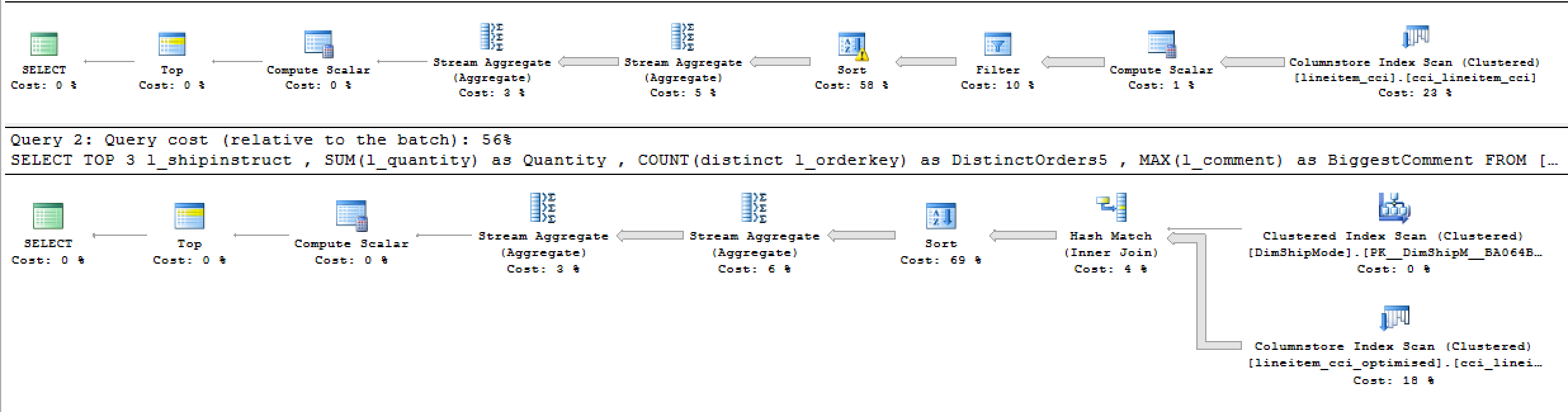
A lot of problems from the first query are easy to expose: almost 6 million rows are being extracted from the Columnstore Index scan, the estimation for the output rows of the Filter iterator are wrong and the Sort iterator have to spill on the TempDB.
The second query does not suffer from these problems and performs reasonably well, at least doubling the performance of the original query.
No Row Group elimination
This is one of the huge items in the Columnstore Indexes – the inability of the string data types (char,varchar,varchar,nvarchar) to eliminate the Row Groups. I have blogged a couple of years ago in Columnstore Indexes – part 49 (“Data Types & Predicate Pushdown”) and unfortunately, so far nothing has changed in this area.
It is not an easy item, because a letter A comes before letter B, but at the same time what about letter A & letter a ? What about a, á, à, ã & â ? What about all the different symbols ?
Sorting there can be very tricky, especially with so many different encodings.
I am still waiting and hoping that Microsoft will implement some sort of the Row Group elimination for the string data types, even if only for the standard collation – because already so many workloads will benefit from it. I have seen huge amounts of data that are using string codes as the surrogate keys, and such string codes are a mixture of english letters, spaces, traces and numbers. This type of strings for the default encoding should support Row Group elimination.
Delta-Stores Predicate Pushdown
This is an important limitation, which will be hitting the HTAP (Operational Analytics) workloads quite hard, because the queries on the hot data will be hitting the Delta-Stores (or Tail Row Group for Memory-Optimised Columnstore Indexes).
Consider the following example where I am creating a table with Clustered Columnstore and load 100.000 rows into it, so that they will stay in the Delta-Store. At the same time I am building the traditional Row Store table with an index on the column that I will be running test query against:
DROP TABLE IF EXISTS dbo.lineitem_delta;
CREATE TABLE [dbo].[lineitem_delta](
[l_shipdate] [date] NULL,
[l_orderkey] [bigint] NOT NULL,
[l_discount] [money] NOT NULL,
[l_extendedprice] [money] NOT NULL,
[l_suppkey] [int] NOT NULL,
[l_quantity] [bigint] NOT NULL,
[l_returnflag] [char](1) NULL,
[l_partkey] [bigint] NOT NULL,
[l_linestatus] [char](1) NULL,
[l_tax] [money] NOT NULL,
[l_commitdate] [date] NULL,
[l_receiptdate] [date] NULL,
[l_shipmode] [char](10) NULL,
[l_linenumber] [bigint] NOT NULL,
[l_shipinstruct] [char](25) NULL,
[l_comment] [varchar](44) NULL
) ON [PRIMARY]
GO
CREATE NONCLUSTERED INDEX [cci_lineitem_delta]
ON [dbo].[lineitem_delta] (l_shipmode)
GO
INSERT INTO dbo.lineitem_delta
(l_shipdate, l_orderkey, l_discount, l_extendedprice, l_suppkey, l_quantity, l_returnflag, l_partkey, l_linestatus, l_tax, l_commitdate, l_receiptdate, l_shipmode, l_linenumber, l_shipinstruct, l_comment)
SELECT TOP 100000
[l_shipdate]
,[l_orderkey]
,[l_discount]
,[l_extendedprice]
,[l_suppkey]
,[l_quantity]
,[l_returnflag]
,[l_partkey]
,[l_linestatus]
,[l_tax]
,[l_commitdate]
,[l_receiptdate]
,[l_shipmode]
,[l_linenumber]
,[l_shipinstruct]
,[l_comment]
FROM [tpch].[dbo].[lineitem_cci];
DROP TABLE IF EXISTS dbo.lineitem_delta;
CREATE TABLE [dbo].[lineitem_delta](
[l_shipdate] [date] NULL,
[l_orderkey] [bigint] NOT NULL,
[l_discount] [money] NOT NULL,
[l_extendedprice] [money] NOT NULL,
[l_suppkey] [int] NOT NULL,
[l_quantity] [bigint] NOT NULL,
[l_returnflag] [char](1) NULL,
[l_partkey] [bigint] NOT NULL,
[l_linestatus] [char](1) NULL,
[l_tax] [money] NOT NULL,
[l_commitdate] [date] NULL,
[l_receiptdate] [date] NULL,
[l_shipmode] [char](10) NULL,
[l_linenumber] [bigint] NOT NULL,
[l_shipinstruct] [char](25) NULL,
[l_comment] [varchar](44) NULL
) ON [PRIMARY]
GO
CREATE NONCLUSTERED INDEX [cci_lineitem_delta]
ON [dbo].[lineitem_delta] (l_shipmode)
GO
INSERT INTO dbo.lineitem_delta
(l_shipdate, l_orderkey, l_discount, l_extendedprice, l_suppkey, l_quantity, l_returnflag, l_partkey, l_linestatus, l_tax, l_commitdate, l_receiptdate, l_shipmode, l_linenumber, l_shipinstruct, l_comment)
SELECT TOP 100000
[l_shipdate]
,[l_orderkey]
,[l_discount]
,[l_extendedprice]
,[l_suppkey]
,[l_quantity]
,[l_returnflag]
,[l_partkey]
,[l_linestatus]
,[l_tax]
,[l_commitdate]
,[l_receiptdate]
,[l_shipmode]
,[l_linenumber]
,[l_shipinstruct]
,[l_comment]
FROM [tpch].[dbo].[lineitem_cci]
Now, let’s consider the test queries:
set statistics io on select distinct l_shipmode from dbo.lineitem_cci_delta where l_shipmode = 'AIR' select distinct l_shipmode from dbo.lineitem_delta where l_shipmode = 'AIR'
Here are the STATISTICS IO results:
Table 'lineitem_cci_delta'. Scan count 2, logical reads 1915, physical reads 0, read-ahead reads 0, lob logical reads 0, lob physical reads 0, lob read-ahead reads 0. Table 'lineitem_delta'. Scan count 1, logical reads 47, physical reads 0, read-ahead reads 0, lob logical reads 0, lob physical reads 0, lob read-ahead reads 0.
The thing is that while for a regular table you can alter its indexes, adding the right index to increase the performance, for the Columnstore Indexes – there is no chance to create an additional index on it, and most probably this is a good thing. (because of potential mess that some software would eventually create on this)
Notice that adding the Nonclustered Indexes on the top of the Columnstore Index might or might not solve the problem you are fighting. In the example I am have shown above, adding Nonclustered Index will not help, because on SQL Server 2016 the query will still be using the Columnstore Index:
CREATE NONCLUSTERED INDEX [cci_lineitem_cci_delta_l_shipmode] ON [dbo].[lineitem_cci_delta] (l_shipmode);
This happens because for the String Predicate Pushdown the Columnstore Indexes are relying on the dictionaries, which simply do not exist for the Delta-Stores.
You can point in the direction that the neither smaller & simpler data types are being supported for the Delta-Stores seeks, but the performance difference is huge, because of the way how data is being processed within the Delta-Stores. In the case of the strings, there is an additional process, which is slowing the filtering of the data.
Consider the following example, where we filter out similar amounts of data (14.578 rows vs 16.225 rows), and the second query, filtering on the integer has a Hash Match, while still performing significantly faster:
set statistics time, io on select distinct l_shipmode from dbo.lineitem_cci_delta where l_shipmode = 'AIR' option(maxdop 1); select distinct l_shipmode from dbo.lineitem_delta where l_quantity > 42 option(maxdop 1);

You can see the suggestion of adding an index to the second query, but it still does not matter – while the first query takes 24 ms, the second one takes only 12 ms, while processing the very same 2.017 data pages.
String Predicate Pushdown with big dictionaries
Some string predicates pushdowns are not like some others. One significant limitation is when we are hitting big dictionaries that contain over 64 thousand entries, even though the predicate pushdown is displayed on the execution plan (XML as well as in the Graphical ones), the predicate pushdown does not take place. I believe that this was implemented in order to avoid slowing down the performance because of way too many dictionary comparison operations, the design decision was taken to do a brute comparison instead.
How on earth can you say that, Niko ? If the execution plans is showing that the predicate pushdown has taken place, how can you discover that ? Well, there is an Extended Event for that :)
For the start, let us take a look at the dictionaries of the table Orders_cci, and the best to do that is by using the CISL function cstore_getDictionaries:
exec dbo.cstore_getDictionaries @tableName = 'orders_cci';
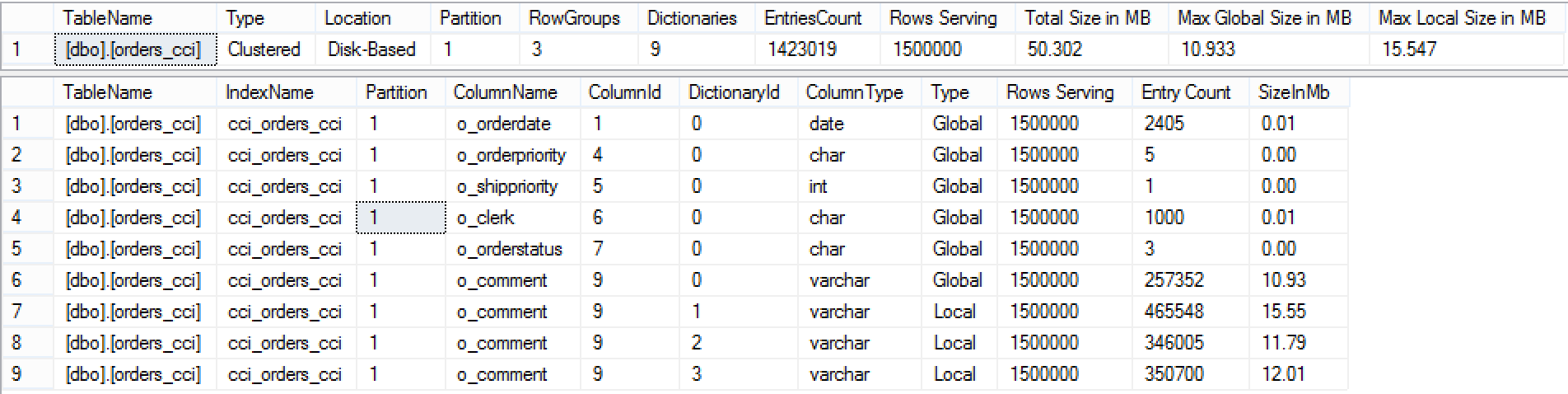
You can easily notice that the column 9, o_comment, has 4 dictionaries with 1 being global and affecting all of the Segments, plus additional 3 local dictionaries, where all of them contains well over 64.000 entries – practically the minimum number of the entries is 257.352, making it more than 4 times bigger to disqualify any of the string predicate pushdowns against this column.
Looking at the Row Groups of the table, we can see that we have just 3 Row Groups, where the first one was already affected by the Dictionary Pressure (sure, we are talking about dictionaries with 15MB+)
exec dbo.cstore_getRowGroupsDetails @tableName = 'orders_cci';
![]()
The 2nd and the 3rd Row Groups are cut by the parallel process, but I have no doubt that the 2nd Row Group otherwise would be cut by the dictionary pressure, if the index build process would be executed with just 1 core.
We need to set up our extended events session, and for that please use the following script (of course you can use one from the CISL, but this one is a bit easier):
CREATE EVENT SESSION [CatchStringPredicatePushdowns] ON SERVER ADD EVENT sqlserver.query_execution_column_store_segment_scan_started ADD TARGET package0.ring_buffer WITH (MAX_MEMORY=4096 KB,EVENT_RETENTION_MODE=ALLOW_SINGLE_EVENT_LOSS,MAX_DISPATCH_LATENCY=30 SECONDS,MAX_EVENT_SIZE=0 KB,MEMORY_PARTITION_MODE=NONE,TRACK_CAUSALITY=OFF,STARTUP_STATE=OFF);
4 MB of the Ring Buffer, allowing Single Events Loss.
Start this session and click on Watch Live Data to view the results of the queries we shall be running.
I have introduced a filter condition for filtering out the integer columns (column_sql_data_type<>XE_XVT_I8), plus I have expanded the view of the results with the following columns column_sql_data_type, encoding_type, filter_type, filter_on_compressed_data_type and here is the XML that I have saved so you can simply apply with your Extended Events sessions:
332 137 100 100 193 NE column_sql_data_type XE_XVT_I8
Here is the T-SQL script I have used for testing the different columns string predicate pushdown (o_comment varchar(79) – over 250.000 entries in the dictionaries, o_clerk char(15) – just 1000 entries in the global dictionary, o_orderpriority char(15) with just 5 entries in the global dictionary:
set statistics time, io on declare @res bigint; select distinct @res = o_orderkey from dbo.orders_cci WHERE o_comment like 'regular%' option (maxdop 1); declare @res bigint; select distinct @res = o_orderkey from dbo.orders_cci WHERE o_clerk > 'Clerk#0000007%' option (maxdop 1); declare @res bigint; select distinct @res = o_orderkey from dbo.orders_cci WHERE [o_orderpriority] like '%4-NOT SPECIFIED%' option (maxdop 1);
The values for the predicates were selected to make things more interesting, with 90K, 451K and ~300K rows being received out of the Columnstore Index Scans:
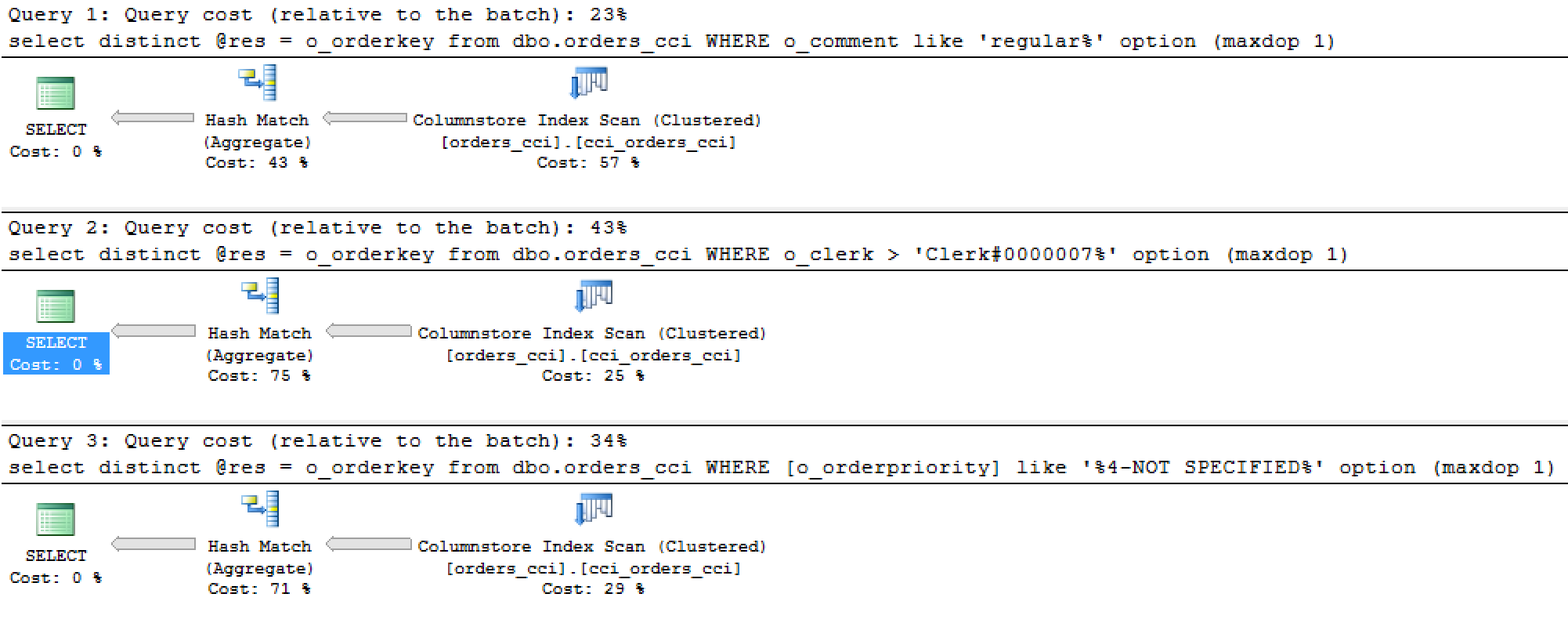
The average execution times are here: 975 ms vs 91 ms vs 69 ms. We are aggregating on the very same column, but the time is hugely wasted somewhere, because we are in fact reading 5 times more data for the 2nd query than for the 1st one!
Take a look at the results of our Extended Events Session “CatchStringPredicatePushdowns”:
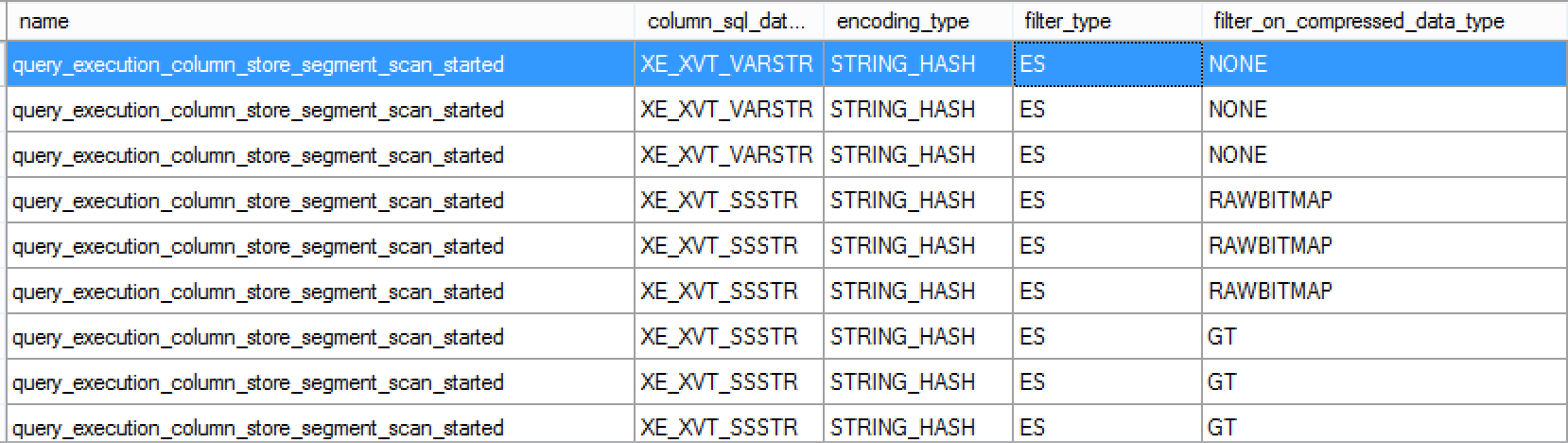
While the first query contains no filtering on the compressed data, the 2nd query is using Raw Bitmap, while the 3rd query is doing GT operation (greater then, I guess?). The 3rd query should be running Greater Than operation, because in practice this is where the dictionary contains just mere 5 values, corresponding the distinct values within the table.
This explains the slow execution of the first query, which is also doing huge work of decompressing the Segments and thus producing internally 10 times more IO accesses – 15125 LOB Logical Reads vs 1850 vs 1540 LOB Logical reads .
I have also made another test running the 2nd query with addition of the 1st predicate:
declare @res bigint; select distinct @res = o_orderkey from dbo.orders_cci WHERE o_clerk > 'Clerk#0000007%' and o_comment like 'regular%' option (maxdop 1);
And the Extended Events shown that the Query processing takes place with the o_clerk column being processed first, shortly followed by the non-filterable-on-the-compression (pun intended) o_comment column.
Once again the Strings are bringing some serious limitations to the Columnstore Engine and to the Batch Mode – they are definitely far from being the best friends of the Columnstore Indexes.
Aggregate Predicate Pushdown
I have already blogged about aggregate predicate pushdown Columnstore Indexes – part 59 (“Aggregate Pushdown”), and here I wanted to write a couple of things about the Strings with the most important one being the fact that the Aggregate Predicate Pushdown works with the data types occupying 8 bytes on maximum, meaning that the unless your column is typed with char(8) or nchar(4) or lesser number of bytes, your attempts to do an aggregation over with this column will result in the full scan and the filter being pushed from the Columnstore Index Scan operator.
The worst thing that you will discover after reading this information is that actually the Minimum and the Maximum values for the String data types are not stored within the segments and so the Aggregate Predicate Pushdown does not work on them; the AVG & SUM function does not work on the strings.
That means that the only the COUNT function will be able doing aggregate predicate pushdown on the strings on SQL Server 2016.
Final Thoughts
This area, STRINGS, is where a lot of improvement is needed and I do have hopes that Microsoft will be investing in it, because so many reporting and business intelligence solutions are desperately needing this.
The Row Group Elimination, String Aggregation are the essential parts of the Columnstore Indexes and most DataWarehouses that I have seen were desperately needing it.
Microsoft has already invested in SQL Server vNext with the support of the LOB’s (Columnstore Indexes – part 92 (“Lobs”)), and I do expect more of the missing features to become reality in the next releases of SQL Server.
Right now the best thing you should do is to be aware of the limitations that are connected with the strings usage and seeking the ways to mitigate them, mostly by converting to the different types and using some of the techniques described in this post.
to be continued with Columnstore Indexes – part 98 (“Null Expressions & String Aggregates”)
This work is very much appreciated Tha.nk you sincerely. rkw
Thank you for the kind words, Rick !
Best regards,
Niko
Hey Niko,
I think the 1st example is slow because of the isnull(…, ‘RAIL’) which has to be applied to the whole table. In the dimension example, you have only a few records to run that ISNULL against therefore making it faster. And, when you use the dimension table is does not even make sense to use ISNULL at all due to the INNER JOIN.
I wonder how much faster this would have run: ( l_shipmode = ‘RAIL’ or l_shipmode is null )
Probably closed to those 4.5 seconds….
Hi Alan,
agreed. I have used this example while developing multiple demos (for the NULL Expression Limitations as well – see http://www.nikoport.com/2017/02/15/columnstore-indexes-part-98-null-expressions-and-string-aggregates/) and then decided to leave it for even further show of a potential difference, because in the practice I saw a multiple overlaps of the limitations.
After substituting the NULL Expressions the difference in my test VM is around 450 ms, representing around 10%, which grows significantly as we move into 10GB & 100GB test versions.
Best regards,
Niko