Continuation from the previous 97 parts, the whole series can be found at https://www.nikoport.com/columnstore/.
Continuing with the spirit of the previous blog post on the string data type limitations I decided to add a couple more items that are showing some current limitations of the Columnstore Indexes and the Batch Execution Mode and the solutions to solve these limitations. In this post I will consider just 2 items: NULL Expressions and the String Aggregates with MIN & MAX functions.
There are more items but I am putting them into separate blog posts, because of their importance and impact.
For the queries I will be using the same version generated copy of the TPCH database (1GB version), that I have used previously. If you want to have one, use the good old HammerDB (free) or any other software to generate it.
Below you will find the script for restoring the backup of TPCH from the C:\Install\
USE [master]
if exists(select * from sys.databases where name = 'tpch')
begin
alter database [tpch]
set SINGLE_USER WITH ROLLBACK IMMEDIATE;
end
RESTORE DATABASE [tpch]
FROM DISK = N'C:\Install\tpch_1gb_new.bak' WITH FILE = 1, NOUNLOAD, STATS = 1
alter database [tpch]
set MULTI_USER;
GO
GO
ALTER DATABASE [tpch] SET COMPATIBILITY_LEVEL = 130
GO
USE [tpch]
GO
EXEC dbo.sp_changedbowner @loginame = N'sa', @map = false
GO
USE [master]
GO
ALTER DATABASE [tpch] MODIFY FILE ( NAME = N'tpch', FILEGROWTH = 256152KB )
GO
ALTER DATABASE [tpch] MODIFY FILE ( NAME = N'tpch_log', SIZE = 1200152KB , FILEGROWTH = 256000KB )
As previously, here is the setup script for creating a table with the Clustered Columnstore Index:
USE [tpch]
GO
DROP TABLE IF EXISTS dbo.lineitem_cci;
-- Data Loding
SELECT [l_shipdate]
,[l_orderkey]
,[l_discount]
,[l_extendedprice]
,[l_suppkey]
,[l_quantity]
,[l_returnflag]
,[l_partkey]
,[l_linestatus]
,[l_tax]
,[l_commitdate]
,[l_receiptdate]
,[l_shipmode]
,[l_linenumber]
,[l_shipinstruct]
,[l_comment]
into dbo.lineitem_cci
FROM [dbo].[lineitem];
GO
-- Create Clustered Columnstore Index
create clustered columnstore index cci_lineitem_cci
on dbo.lineitem_cci;
GO
NULL Expressions
Columnstore & Data Types allowing NULLs – they are ain’t no friends. At all.
Notice, that NULLs are a very essential part of the Database, they represent UNKNOWN and for the additive or semi-additive facts, they are essential elements of a good Data Warehouse. It just happens that contrary to the Rowstore Indexes, they can represent significant trouble for the query processing, because they are not being pushed into the Storage Engine and as a result a filter iterator will be included in the execution plan at a later stage, representing greater resource spending (memory & time) until the rows will get filtered out of the execution plan.
Here is a rather simple query, that includes a very bad practice of using ISNULL function as a predicate condition:
SELECT TOP 3 l_shipinstruct , SUM(l_quantity) as Quantity , COUNT(distinct l_orderkey) as DistinctOrders FROM [dbo].[lineitem_cci] li WHERE ISNULL(l_shipmode,'RAIL') = 'RAIL' GROUP BY l_shipinstruct ORDER BY SUM(l_quantity) DESC
The relevant part of the execution plan is presented below (and notice that I have set the Parallelism Threshold to be equal to 1, I needed to test some very interesting hypothesis):

You can see a filter iterator taking estimated 9% of the resources and filtering over 5,1 million rows that were taken out of the lineitem_cci table (Columnstore Index Scan operation). Before it took place all of the table data was read and the values for the aggregate values were calculated, meaning a significant resource waste (when the data was filtered and while it was occupying memory).
 The predicate properties of the Columnstore Index Scan are shown on the left picture and you can see that nothing has been pushed into the Storage Engine, making this query perform quite slow. On my local test VM it takes on average 0.7 seconds to execute while spending over 1.9 seconds of the CPU time. This happens because of the inability of the Columnstore Indexes to push NULL expression predicate into the storage engine.
The predicate properties of the Columnstore Index Scan are shown on the left picture and you can see that nothing has been pushed into the Storage Engine, making this query perform quite slow. On my local test VM it takes on average 0.7 seconds to execute while spending over 1.9 seconds of the CPU time. This happens because of the inability of the Columnstore Indexes to push NULL expression predicate into the storage engine.
To solve this problem in this test case I will need to rewrite the query and remove the NULL expression by substituting it by = ‘RAIL’ OR IS NULL logic:
SELECT TOP 3 l_shipinstruct , SUM(l_quantity) as Quantity , COUNT(distinct l_orderkey) as DistinctOrders FROM [dbo].[lineitem_cci] li WHERE l_shipmode = 'RAIL' OR l_shipmode IS NULL GROUP BY l_shipinstruct ORDER BY SUM(l_quantity) DESC
This query takes 0.24 seconds to execute (~3 times faster than the original one) and it spends just 0.68 seconds of the CPU time (again around 3 times less than the original query). The secret is quite visible in the execution plan:

 There are no filters to be found within the execution plan, and the Clustered Columnstore Index scan returns ~857.000 rows, while the original plan had almost 6 million rows being returned and processed. This happens because of the pushed predicate into the storage engine in the second execution plan, as you can see on the left picture. We are doing IS NULL comparison and do not use any NULL expressions, which allows engine to optimise the execution.
There are no filters to be found within the execution plan, and the Clustered Columnstore Index scan returns ~857.000 rows, while the original plan had almost 6 million rows being returned and processed. This happens because of the pushed predicate into the storage engine in the second execution plan, as you can see on the left picture. We are doing IS NULL comparison and do not use any NULL expressions, which allows engine to optimise the execution.
To prove that for the Rowstore Indexes the NULL expressions are pushed into the Storage Engine, here is the same query which is being executed against the original Rowstore table dbo.lineitem:
SELECT TOP 3 l_shipinstruct , SUM(l_quantity) as Quantity , COUNT(distinct l_orderkey) as DistinctOrders FROM [dbo].[lineitem] li WHERE ISNULL(l_shipmode,'RAIL') = 'RAIL' GROUP BY l_shipinstruct ORDER BY SUM(l_quantity) DESC

 The execution plan is naturally different, because we have no Columnstore Indexes and no batch mode, but the 857.556 rows being filtered out of the Clustered Index Scan are the good news which can be verified by checking the properties of this operation showing the NULL expression successfully being pushed into the storage engine.
The execution plan is naturally different, because we have no Columnstore Indexes and no batch mode, but the 857.556 rows being filtered out of the Clustered Index Scan are the good news which can be verified by checking the properties of this operation showing the NULL expression successfully being pushed into the storage engine.
The lesson here is simple – be aware that in SQL Server 2016 this is still a limitation and check your execution plans on the NULL expressions and do your best to rewrite them if the query performance needs to be improved.
String Aggregates enhanced
Coming back to the topic of Strings I wanted to add another item to the list of items and solutions described in the previous blog post Columnstore Indexes – part 97 (“Working with Strings”).
The issue is that Max & Min aggregations on the strings are not supported in Batch Mode and even though your query will make expectations on running well, it will be executed in the Row Mode and if you dare to mix it with other Aggregate operations, you will be punished with the DOP 1 for the query.
Consider a simple query, aggregating on a large string:
SELECT TOP 3 l_shipinstruct , MAX(l_comment) as BiggestComment FROM [dbo].[lineitem_cci] li GROUP BY l_shipinstruct ORDER BY SUM(l_quantity) DESC

Yes, the Clustered Columnstore Index Scan runs with the Batch Execution Mode, but what about the Hash Match iterator, that is expected to have spent 95% of the query execution resources ?
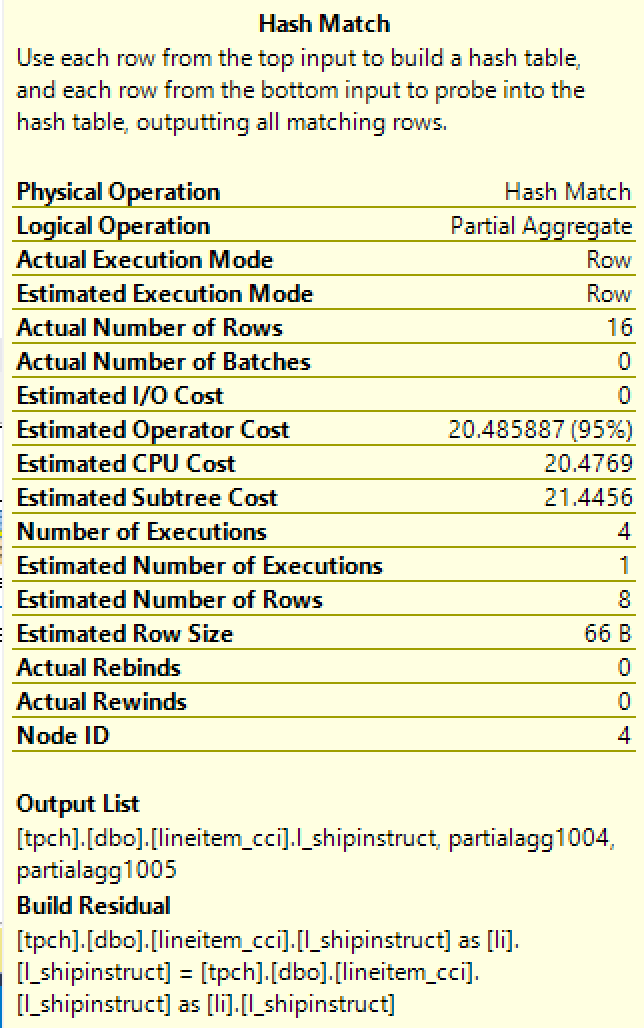 It is being executed in Row Execution Mode, greatly slowing down the overall process and it is easy to imagine that this iterator shall spent those 95% of the resources there, especially since the whole table is being processed without any possibility of the predicate pushdown (take at the blogpost 97 for more info). Sounds bad? Do not go away, there is more on the string aggregations …
It is being executed in Row Execution Mode, greatly slowing down the overall process and it is easy to imagine that this iterator shall spent those 95% of the resources there, especially since the whole table is being processed without any possibility of the predicate pushdown (take at the blogpost 97 for more info). Sounds bad? Do not go away, there is more on the string aggregations …
Here is the query that I was testing a couple of weeks ago:
SELECT TOP 3 l_shipinstruct , SUM(l_quantity) as Quantity , COUNT(distinct l_orderkey) as DistinctOrders , MAX(l_comment) as BiggestComment FROM [dbo].[lineitem_cci] li WHERE ISNULL(l_shipmode,'RAIL') = 'RAIL' GROUP BY l_shipinstruct ORDER BY SUM(l_quantity) DESC
![]()
Single core execution with spilling sort iterator ? Even though the Stream Aggregate iterator is showing 8% of the resources cost, it is being executed within the Row Execution Mode, because of the way that the MAX String Aggregate is implemented.
The reason for all this troubles ? Mixing String Aggregates with the other Aggregates.
Putting a different data type into the Max operation will take this query to execute with multiple cores and almost completely in the Batch Execution Mode:
SELECT TOP 3 l_shipinstruct , SUM(l_quantity) as Quantity , COUNT(distinct l_orderkey) as DistinctOrders , MAX(l_quantity) as BiggestComment FROM [dbo].[lineitem_cci] li WHERE ISNULL(l_shipmode,'RAIL') = 'RAIL' GROUP BY l_shipinstruct ORDER BY SUM(l_quantity) DESC

Plus, there is no Sort iterator :)
Well, but the client wants this query to be executed FAST, is there a solution for this ?
Sure thing :)
Like with the most limitations of such type, the typical approach I use is to split the conflicting parts into the separate subqueries and pivot back the results, because every single aggression by itself functions well or reasonable well (Look at the begin of this subchapter on how the Row Execution Mode is headlining the String Aggregations).
The pattern steps are the following:
1. Split each aggregate into a separate query that will be joined on UNION ALL (do not forget to include ALL of the sorting and filtering conditions)
2. Pivot the results from the joined queries and get them the way you need to present to the final user (PIVOT
(
MAX(Result)
FOR Title IN ([Quantity], [DistinctOrders], [BiggestComment])
) as PivotTable) part:
set statistics time, io on SELECT l_shipinstruct, [Quantity], [DistinctOrders], [BiggestComment] FROM ( SELECT TOP 3 'Quantity' as Title , l_shipinstruct , cast(SUM(l_quantity) as Varchar(50)) as Result FROM [dbo].[lineitem_cci] li WHERE l_shipmode = 'RAIL' OR l_shipmode IS NULL GROUP BY l_shipinstruct ORDER BY SUM(l_quantity) DESC UNION ALL SELECT TOP 3 'DistinctOrders' ,l_shipinstruct , CAST( COUNT(distinct l_orderkey) as Varchar(50)) FROM [dbo].[lineitem_cci] li WHERE l_shipmode = 'RAIL' OR l_shipmode IS NULL GROUP BY l_shipinstruct ORDER BY SUM(l_quantity) DESC UNION ALL SELECT TOP 3 'BiggestComment' , l_shipinstruct , MAX(l_comment) FROM [dbo].[lineitem_cci] li WHERE l_shipmode = 'RAIL' OR l_shipmode IS NULL GROUP BY l_shipinstruct ORDER BY SUM(l_quantity) DESC ) res PIVOT ( MAX(Result) FOR Title IN ([Quantity], [DistinctOrders], [BiggestComment]) ) as PivotTable

The execution plan represents a very clear implementation of the 3 joined subqueries and does it runs fast ? 763 ms for the tuned execution plan versus 7334 ms for the original plan. 10 times faster! :)
Final Thoughts
There are definitely some limitations and bugs within the Columnstore Indexes and the Batch Execution Mode (breaking news – like with any other software that me & you, dear reader, are writing), but knowing the team working on this technology – I have no doubt that they will be further improving the current limitations. In the mean time there are workarounds which are not too difficult to implement and they offer easy solutions for the described problems.
to be continued with Columnstore Indexes – part 99 (“Merge”)
The whole query DOP 1 or just a region? Weird product limitation.
Hi tobi,
I believe this is a whole query limitation. This is a kind of a bug that hopefully will be fixed soon.
Best regards,
Niko