Continuation from the previous 57 parts, the whole series can be found at https://www.nikoport.com/columnstore/.
I have previously blogged on the predicate pushdown matter in the post Columnstore Indexes – part 49 (“Data Types & Predicate Pushdown”), and from the published table one could see that the vast majority of the data types are being supported for predicate pushdown in SQL Server 2014.
The most important data type(s) missing the predicate pushdown support is(are) definitely all string ones – (n)char & (n)varchar. In a perfect people would avoid to use character fields for fact tables, but in the real world – well … :)
The missing feature has a major impact on any query involving a character predicate and especially in SQL Server 2016 where the Operational Analytics will allow to create an updatable Nonclustered Columnstore Index over the operational tables, where a lot of string columns to be found.
At Ignite, Microsoft has revealed that it is including String predicate support in SQL Server 2016, and so I decided to take CTP 2.1 for a test drive.
The theory & the basics
With a numeric data type the situation is quite simple, we simply compare the value on the Storage level (one level above SQLOS) and determine if it serves the used predicate or not. With character fields, the situation is a little bit more complex than this – we have a number of ways to search for the content inside our character fields with such operators as ‘LIKE’, for example.
Given this challenge, this is how the Microsoft SQL Server Team decided to implement predicate pushdown for the String data types.
The key aspect of the compression strategy for the string data types in Columnstore Indexes are the Dictionaries. Since the first version of Columnstore Indexes in SQL Server 2012, we always have had 2 types of the dictionaries – the global ones(serves all Segments of a particular column) and the local ones(serve just one single Segment of a particular column).
To determine if the row satisfy the search criteria, we can do string comparison on the dictionary level, and if we are lucky – even a short dictionary string will help us to identify a good number of rows that satisfying our search criteria.
Whenever we execute a search inside some string, the strategy that is being executed on by the Query Optimiser is the following:
1. Search for the applied predicate inside the dictionaries to determine the rows that are satisfying the criteria.
2. Identify the rows that are using the found dictionaries. These rows will be identified as R1.
3. Identify the other rows, that have not been selected with the help of the dictionary. These rows that are not elegible for the dictionary search optimisation will marked as R2.
4. All of the columnstore rows will be returned from the Columnstore Index Scan iterator, where it will simply pass through all identified rows (R1) and will apply the searched predicate filter on the unoptimised R2 rows to filter out the rows applying to the search criteria (R3).
5. The final result returned by the Filter iterator will be the sum of the R1 + R3 rows.
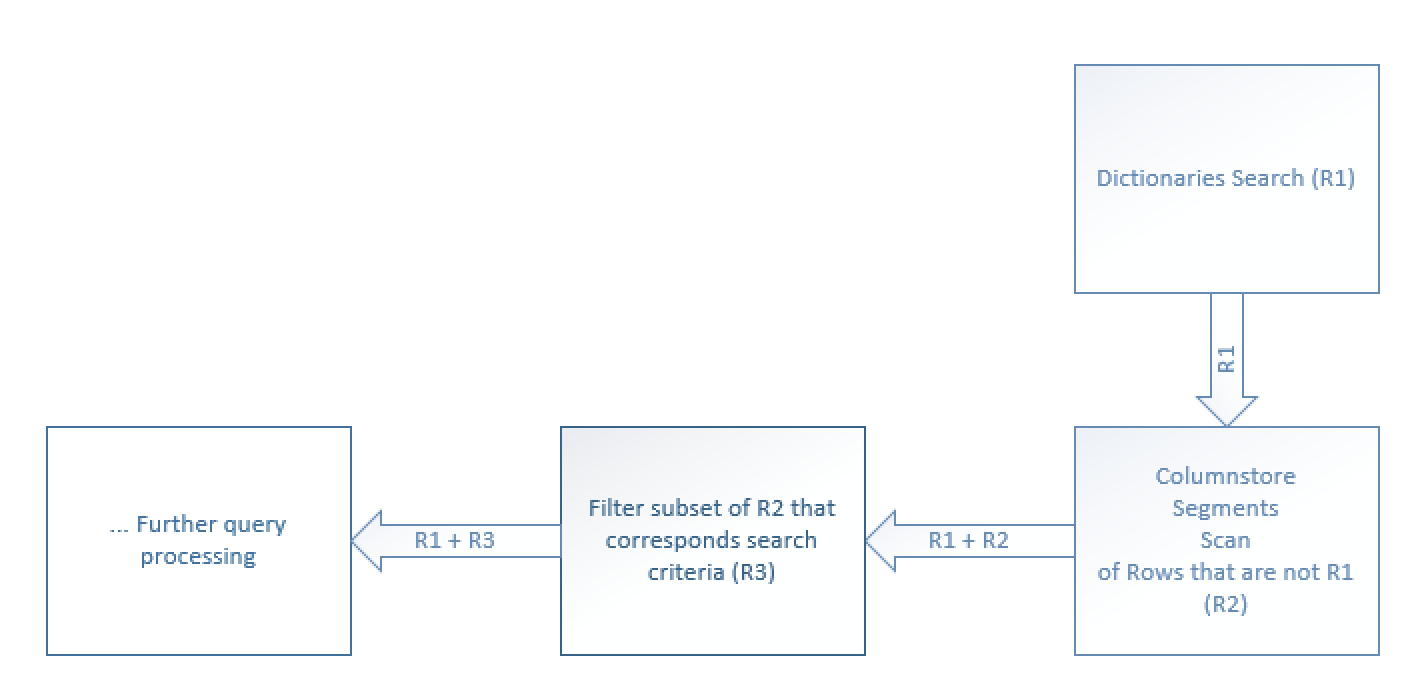 On the diagram on the left, you can see the basic positive (LIKE) process described. For the negative search (NOT LIKE), the logic will be the same, though I believe it would be much more efficient to filter out the not matching rows immediately, because this way we would simply avoid forwarding any of the rows from the Columnstore Index Scan to the filter operator, if they were found in the dictionary already.
On the diagram on the left, you can see the basic positive (LIKE) process described. For the negative search (NOT LIKE), the logic will be the same, though I believe it would be much more efficient to filter out the not matching rows immediately, because this way we would simply avoid forwarding any of the rows from the Columnstore Index Scan to the filter operator, if they were found in the dictionary already.
You might think – hey, but I do not see any significant IO improvement here, because every row will be read anyway!
Well, its all about the CPU instructions & execution time optimisation here, so we should see a significant win in the terms of the execution time, because a true direct search inside a string is very resource intensive operation, which compared to a dictionary search can come really close to nothing.
The Tests
Using the free database ContosoRetailDW, I am restoring it to my local VM and after dropping the primary key constraint (yeah, all the foreign keys are still in place, because we are rocking SQL Server 2016 – more on this, hopefully in a week).
Notice that I am setting the compatibility level explicitly to 130, because otherwise the new improvements for the queries simply will be deactivated.
USE master;
alter database ContosoRetailDW
set SINGLE_USER WITH ROLLBACK IMMEDIATE;
RESTORE DATABASE [ContosoRetailDW]
FROM DISK = N'C:\Install\ContosoRetailDW.bak' WITH FILE = 1,
MOVE N'ContosoRetailDW2.0' TO N'C:\Data\ContosoRetailDW.mdf',
MOVE N'ContosoRetailDW2.0_log' TO N'C:\Data\ContosoRetailDW.ldf',
NOUNLOAD, STATS = 5;
alter database ContosoRetailDW
set MULTI_USER;
GO
GO
ALTER DATABASE [ContosoRetailDW] SET COMPATIBILITY_LEVEL = 130
GO
ALTER DATABASE [ContosoRetailDW] MODIFY FILE ( NAME = N'ContosoRetailDW2.0', SIZE = 2000000KB , FILEGROWTH = 128000KB )
GO
ALTER DATABASE [ContosoRetailDW] MODIFY FILE ( NAME = N'ContosoRetailDW2.0_log', SIZE = 400000KB , FILEGROWTH = 256000KB )
GO
ALTER TABLE dbo.[FactOnlineSales] DROP CONSTRAINT [PK_FactOnlineSales_SalesKey];
create clustered columnstore Index PK_FactOnlineSales
on dbo.FactOnlineSales;
The query I that I will be executing for the test purposes will be the following simple one, which is including 2 string predicates for searching at the FactOnlineSales table, containing ~12.6 Million Rows:
set statistics time, io on dbcc dropcleanbuffers dbcc freeproccache select sum(SalesAmount), sum(SalesAmount) - sum(SalesAmount*prom.DiscountPercent) from dbo.FactOnlineSales sales inner join dbo.DimPromotion prom on sales.PromotionKey = prom.PromotionKey where SalesOrderNumber like N'2008%' and SalesOrderNumber not like N'%000' option (recompile, maxdop 2);
 Here is the relevant part from the execution plan, we can clearly see the Columnstore Index Scan iterator processing the dictionaries and scanning the Segments (I am starting to wish to gain a better visual insight into these type of operations, because Columnstore Indexes become progressively more complex structures with more internal processes that they almost justify their own execution sub-plan existence).
Here is the relevant part from the execution plan, we can clearly see the Columnstore Index Scan iterator processing the dictionaries and scanning the Segments (I am starting to wish to gain a better visual insight into these type of operations, because Columnstore Indexes become progressively more complex structures with more internal processes that they almost justify their own execution sub-plan existence).
 The execution plan does not guarantee us a true predicate pushdown, it is only after we see the sequence of the Columnstore Index Scan and a Filter iterators, that we can check on the properties of the Columnstore Index Scan then determining there if the predicate is being truly listed under the properties.
The execution plan does not guarantee us a true predicate pushdown, it is only after we see the sequence of the Columnstore Index Scan and a Filter iterators, that we can check on the properties of the Columnstore Index Scan then determining there if the predicate is being truly listed under the properties.
Yeah, this is definitely not the best way, but right now I honestly do not have any better ideas about how to make it more clear. If you have a good idea, please make sure to raise a Connect Item, because I am confident that everyone would profit from a better visual analysis of the execution plans.
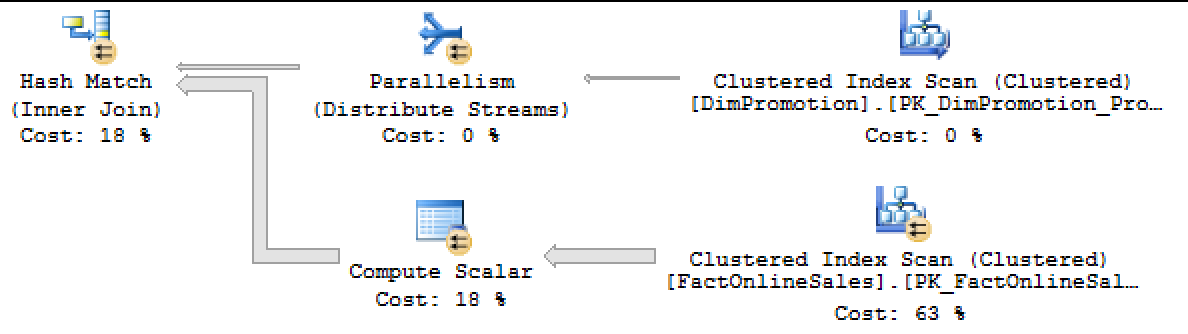 Now let us compare with the execution plan for SQL Server 2014. On the left side you can see the relevant part that I took from SQL Server 2014 – where one could easily notice 2 important parts:
Now let us compare with the execution plan for SQL Server 2014. On the left side you can see the relevant part that I took from SQL Server 2014 – where one could easily notice 2 important parts:
– the absence of the Filter iterator
– the excessive estimated cost for the Columnstore Index Scan
These are the best indications that the Predicate is not being pushed down to the storage level.
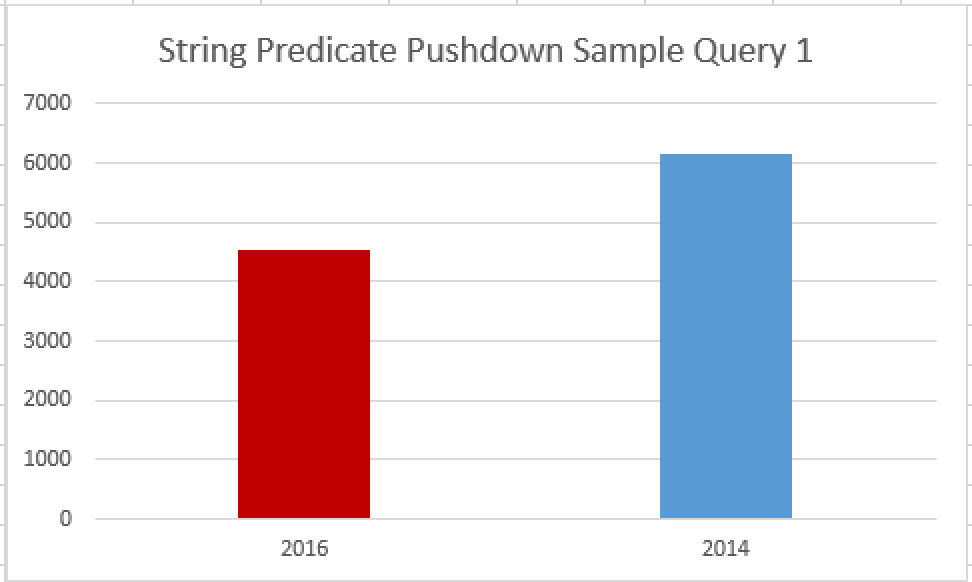 That’s interesting, but what about the execution times between different SQL Server versions? They are very significant in my books, even given that we are considering a Non-RTM version of SQL Server 2016 and my other test VM was hooked up with SQL Server 2014 SP1. The total execution time on SQL Server 2016 was 4548 ms with 8499 ms of CPU time burned, while on SQL Server 2014 SP1 it was 6146 ms for the total execution time and 10858 ms for the CPU time.
That’s interesting, but what about the execution times between different SQL Server versions? They are very significant in my books, even given that we are considering a Non-RTM version of SQL Server 2016 and my other test VM was hooked up with SQL Server 2014 SP1. The total execution time on SQL Server 2016 was 4548 ms with 8499 ms of CPU time burned, while on SQL Server 2014 SP1 it was 6146 ms for the total execution time and 10858 ms for the CPU time.
1.6 Seconds difference in the total time represents around 25% of the difference and for the CPU time it represents 2.7 Seconds. For a small simple query on a rather small table (12.6 million rows) this represents a nice improvement, especially since we do not need to do anything with our existing query.
From what I have seen so far, the better findings in the R1 phase (dictionary search) are, the bigger the difference between SQL Server 2014 & SQL Server 2016 will be.
Segment Elimination
To test the Segment Elimination I suggest to consider a typical query one would face in a lot of projects, where people simply filter on textual columns:
set statistics io on select max(SalesAmount) from dbo.FactOnlineSales where SalesOrderNumber >= '2008' and SalesOrderNumber < '2009'
Let's see the textual output with the results, since they are so accessible in SQL Server 2016:
... Table 'FactOnlineSales'. Segment reads 13, segment skipped 0. ...
What ?!
Why oh why???
Oh wait, this might have to do with the fact that there is a Segment dealignment problem, running the query agains our FactOnlineSales table have shown that we have 100% dealignment. :s
Ok, let's solve the problem in the good old way, by rebuilding the rowstore clustered index and then building the clustered columnstore index with MAXDOP = 1 on it:
create clustered index PK_FactOnlineSales on dbo.FactOnlineSales (SalesOrderNumber desc) with (drop_existing = on, maxdop = 1); create clustered columnstore index PK_FactOnlineSales on dbo.FactOnlineSales with (drop_existing = on, maxdop = 1);
Let's check the segment alignment:
select segment_id, min_data_id, max_data_id from sys.column_store_segments where column_id = 8 /* SalesOrderNumber */ order by segment_id;
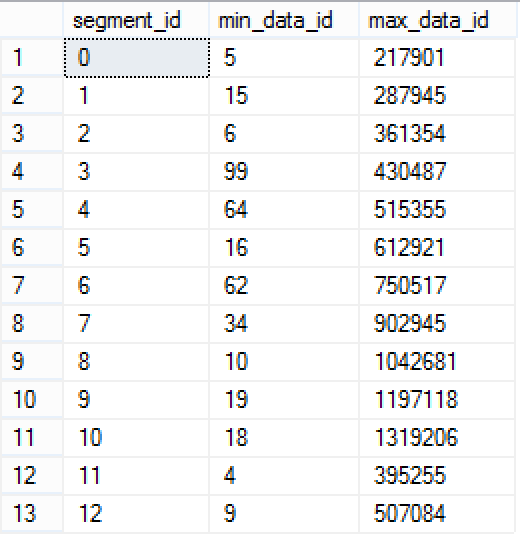 Looking at the results I can only feel the cold rising through my vertebral column - there is no alignment at all!
Looking at the results I can only feel the cold rising through my vertebral column - there is no alignment at all!
This does not look very much different from SQL Server 2014, this does not allow to do a real Segment Elimination based on the String Predicate, and this means that we have not advanced a full step forward in this direction.
Let's run our test query again:
set statistics io on select max(SalesAmount) from dbo.FactOnlineSales where SalesOrderNumber >= '2008' and SalesOrderNumber < '2009'
The results are here:
... Table 'FactOnlineSales'. Segment reads 13, segment skipped 0. ...
This is definitely not the most correct query in the world, but this is definitely the one type of query that through my entire career I am used to face with. Unfortunately, many developers do not understand the difference in data types and using textual ones in every possible way is the most common thing you will see whenever discovering a new database.
I strongly believe that Microsoft should solve the absence of support for the String Predicate Segment Elimination, this would definitely win a lot of friends from those who are using Columnstore Indexes regularly.
to be continued with Columnstore Indexes – part 59 ("Aggregate Pushdown")
Is segment elimination based on string predicates basically possible in 2016 or is it not implemented at all? It was a little unclear to me from the last test whether it does not exist or whether the data distribution prevented it (although I don’t know in what way).
Hi tobi,
Segment Elimination for String looks to be not implemented in SQL Server 2016 CTP 2.1.
Further, any attempts on ordering the data based on the strung column were in vain (the data keeps appearing unordered), this is what the last test have shown.
Regards,
Niko
Right, I did not interpret the test correctly. The data is indeed unordered; unclear to me why that is.
Hi Tobi, hi Niko!
I am not surprised that the metadata in sys.column_store_segments appears unordered. That is not a result of the index not being ordered, but of the way dictionaries work.
The first step of the columnstore creation process is to look at a sample of the table to determine which strings should go into the global dictionary. Because it is a sample, and because (probably) sorting on frequency of strings is involved, those dictionary orders will not be created in alphabetic string order. So when the strings are assigned a dictionary entry number, the order of that numbers does not correspond with either alphabetic order or the order of the rows in the table (which in your demo code is the same)
For the remaining string entries that have to go into the local dictionaries, it is still unlikely that dictionary entries are assigned as rows are processed. Remember that after dividing the table into rowgroups, rows within an individual rowgroup are sorted to optimize compression benefit. I expect local dictionary entries to be assigned in order of processing rows after that sort.
Since the columnstore index itself does not store the string but the dictionary entry number, you cannot see the sorting from the metadata. If ‘A1’ has entry 12345, ‘A2’ has entry 17, and ‘A3’ had entry 3995, then a rowgroup that only contains the three string values A1, A2, and A3 would have a min_data_Id of 17 and a max_data_id of 12345. The next rowgroup might well start with ‘A4’, but since that has dictionary entry number 854, it falls within the boundaries of the first rowgroup and even an equality predicate on A4 would not enable eliminatinig that rowgroup.
Because of this, it is virrually impossible even in theory to do rowgroup elimination for LIKE searches. If the predicate is LIKE ‘A%’, then searching the dictionaries would tell SQL Server that it needs dictionaray entries 17, 854, 3995, and 12345 – a wide enough spread that it is utterly unlikely that any rowgroup can be eliminated.
However, it would in theory be possible to do segment elimination for string equality search (WHERE City = ‘Seattle’). With just a single value found in the dictionary (or perhaps a few if case insensitive search is used, but always a low number), it might be possible to eliminate some rowgroups if that value happens to be a low or high value.
Also, for an equality search or LIKE that has no matches (e.g. LIKE ‘A12%’ in the example above). it could be taken one step further – scan the dictionaries, see that there is not a single entry that matches and then eliminate all compressed rowgroups and scan only the delta store.
I wanted to test this so I created an ~8-million row table with just two values in its string column, created a clustered index then created a clustered columnstore index. In sys.column_store_segments, min_data_id and max_data_id were both 5 in the first four rowgroups, both 4 in the second four. I then tested with equality search on an existing string, equality search on a non-existing string, and LIKE search on both an existing and a non-existing prefix. In all four cases, SET STATISTICS IO told me that no rowgroups were eliminated.
Bummer.
Oh, one more thing that I did not test – if a string column has sufficient distinct entries that the global dictionary overflows and local dictionaries are needed, then in theory it would be possible for SQL Server to eliminate some rowgroups: if the string value searched for is from a local dictionary, then only the rowgroups using that local dictionary need too be scanned.
Based on my test results so far I absolutely do not expect this to be the case (at least not in the CTP3 build that I used for me tests). But as I said: I did not actually test this.
Great stuff, Hugo!
Thank you for this writeup.
I have had some conversations with the Columnstore Developers on the topic of Segment Elimination of the String Predicates.
I personally see some possibilities of implementing a limited support for a true segment elimination, based on a concrete default encoding for the start. (there is more on this topic that I have time to write on).
At the beginning 2 lookups against dictionaries for the min & max values would allow to determine if the value is inside the needed range or not. The amount of CPU work saved on bigger tables is not to comparable with anything else.
I have some real production cases of huge tables 1 billion+ where it would bring performance for a whole new level potentially.
Best regards,
Niko Neugebauer
Thanks for introducing me to string predicate pushdown. I had some hope that this would work also when joining a huge fact table with a small dimension table on string columns, but was disappointed. I did open a ticket with Microsoft and they admitted this to be a limitation that should have been documented. They will update documentation, but have no immediate plans for implementing this.
Anyone in favor of better performance, please vote for this one (see the the suggestion for further details): https://connect.microsoft.com/SQLServer/feedbackdetail/view/3134979/support-string-predicate-pushdown-in-for-columnstore-indexes-in-batch-mode-when-joining-on-a-string-column
Hey Niko,
This may not be the place for this question, and it may be a general, hard to answer question, but what could cause a partitioned clustered columnstore index to not push the string predicate into the scan node? I have a dataset that we have tested on Sql Server 2017 and 2019, and I’ve moved the compatibility from 2014 to 2016, 2017, 2019. Table has about 500 million records with 100 columns (mixture of ints, varchars, datetimes) On every version, (I understand this isn’t supported prior to 2016), the query plan is giving an explicit “Filter” node rather than pushing down into the scan. The query is an extremely simple select * from table where an int column = explicit number, and varchar(36) nullable column = explicit string value.
select * from table where Id = 150 and reportName = ‘reportName’
The integer predicate is pushed into the scan node, but the varchar is not. There is no NULL checking going on in the query, and the maximum number of dictionary entries for the partition for the varchar column is 60 entries (very small number of distinct string values in the varchar column). I used the dictionary stored proc from your CILS to check the entry count. The partition has 200 million records with hundreds of dictionaries. I’ve tried searching everywhere and all I can find are articles saying this issue is resolved starting with sql server 2016. I can’t find any evidence of this issue occurring on sql server 2016, 17 or 19. Any help or guidance would be greatly appreciated.
Hi Kevin,
First of all, check if you are using Enterprise Edition since String Predicate Pushdown is an Enterprise Edition feature, then check your compatibility level on the database (must be 130+), and then I would focus on the dictionaries presence and size (are there any, what is their size?). Check the following blog posts for more http://www.nikoport.com/2017/02/01/columnstore-indexes-part-97-working-with-strings/ and http://www.nikoport.com/2017/02/15/columnstore-indexes-part-98-null-expressions-and-string-aggregates/
Best regards,
Niko