Continuation from the previous 115 parts, the whole series can be found at https://www.nikoport.com/columnstore/
After delaying for a couple of years (yes, strangely there is other priority in my life, besides this blog post series) – I am finally putting a couple of the notes on the partitioning for the Columnstore Indexes. Even though this blog series is not a stranger to the Partitioning subject with 4 blog posts referring Columnstore Indexes – part 14 (“Partitioning”), Columnstore Indexes – part 15 (“Partitioning Advanced”), Columnstore Indexes – part 94 (“Use Partitioning Wisely”) & Columnstore Indexes – part 103 (“Partitioning 2016 vs Partitioning 2014”), but the practical (and not the performance) aspects & specifics of working with the Columnstore Indexes were always on my todo list until this very blog post.
In this blogpost I will want to focus on 2 of the most common operations over the Partitioned tables, the MERGE & the SPLIT, because there are some little specifics that will affect your DWH, once you migrate it to Columnstore Indexes over from the Rowstore ones.
The Setup
To test the partitioning scripts, please download the free ContosoRetailDW database, at Microsoft’s page.
My Data & Log files are configured to be restored to the following path on this test instance: c:\Data\SQL16\, but feel free to change them according to your test server:
USE [master]
alter database ContosoRetailDW
set SINGLE_USER WITH ROLLBACK IMMEDIATE;
RESTORE DATABASE [ContosoRetailDW]
FROM DISK = N'C:\Install\ContosoRetailDW.bak' WITH FILE = 1,
MOVE N'ContosoRetailDW2.0' TO N'C:\Data\SQL16\ContosoRetailDW.mdf',
MOVE N'ContosoRetailDW2.0_log' TO N'C:\Data\SQL16\ContosoRetailDW.ldf',
NOUNLOAD, STATS = 5;
alter database ContosoRetailDW
set MULTI_USER;
GO
GO
ALTER DATABASE [ContosoRetailDW] SET COMPATIBILITY_LEVEL = 130
GO
ALTER DATABASE [ContosoRetailDW] MODIFY FILE ( NAME = N'ContosoRetailDW2.0', SIZE = 2000000KB , FILEGROWTH = 128000KB )
GO
ALTER DATABASE [ContosoRetailDW] MODIFY FILE ( NAME = N'ContosoRetailDW2.0_log', SIZE = 400000KB , FILEGROWTH = 256000KB )
GO
Let us add 5 new file groups (1 for the pre-2007 data, and then for each of the years 1 data file (2007,2008,2009,2010).
-- Add 5 new filegroups to our database
alter database ContosoRetailDW
add filegroup OldColumnstoreData;
GO
alter database ContosoRetailDW
add filegroup Columnstore2007;
GO
alter database ContosoRetailDW
add filegroup Columnstore2008;
GO
alter database ContosoRetailDW
add filegroup Columnstore2009;
GO
alter database ContosoRetailDW
add filegroup Columnstore2010;
GO
-- Add 1 datafile to each of the respective filegroups
alter database ContosoRetailDW
add file
(
NAME = 'old_data',
FILENAME = 'C:\Data\SQL16\old_data.ndf',
SIZE = 10MB,
FILEGROWTH = 125MB
) to Filegroup [OldColumnstoreData];
GO
alter database ContosoRetailDW
add file
(
NAME = '2007_data',
FILENAME = 'C:\Data\SQL16\2007_data.ndf',
SIZE = 500MB,
FILEGROWTH = 125MB
) TO Filegroup Columnstore2007;
GO
alter database ContosoRetailDW
add file
(
NAME = '2008_data',
FILENAME = 'C:\Data\SQL16\2008_data.ndf',
SIZE = 500MB,
FILEGROWTH = 125MB
) to Filegroup Columnstore2008;
GO
alter database ContosoRetailDW
add file
(
NAME = '2009_data',
FILENAME = 'C:\Data\SQL16\2009_data.ndf',
SIZE = 500MB,
FILEGROWTH = 125MB
) TO Filegroup Columnstore2009;
GO
alter database ContosoRetailDW
add file
(
NAME = '2010_data',
FILENAME = 'C:\Data\SQL16\2010_data.ndf',
SIZE = 500MB,
FILEGROWTH = 125MB
) TO Filegroup Columnstore2010;
GO
The partitioning function & scheme, shall be defined as specified below:
-- Create the Partitioning scheme
create partition function pfOnlineSalesDate (datetime)
AS RANGE RIGHT FOR VALUES ('2007-01-01', '2008-01-01', '2009-01-01', '2010-01-01');
-- Define the partitioning function for it, which will be mapping data to each of the corresponding filegroups
create partition scheme ColumstorePartitioning
AS PARTITION pfOnlineSalesDate
TO ( OldColumnstoreData, Columnstore2007, Columnstore2008, Columnstore2009, Columnstore2010 );
Now we are ready to drop the Primary Clustered Key on the FactOnlineSales table and after creating the obligatory partitioned Clustered Rowstore Index, we can finally create partitioned Clustered Columnstore Index:
---- Drop our existing PK
ALTER TABLE [dbo].[FactOnlineSales] DROP CONSTRAINT [PK_FactOnlineSales_SalesKey]
-- Creation of a traditional Clustered Index
Create Clustered Index CCI_FactOnlineSales
on dbo.FactOnlineSales (DateKey)
ON ColumstorePartitioning (DateKey)
-- Create Partitioned Clustered Columnstore Index
Create Clustered Columnstore Index CCI_FactOnlineSales
on dbo.FactOnlineSales
with (DROP_EXISTING = ON)
ON ColumstorePartitioning (DateKey);
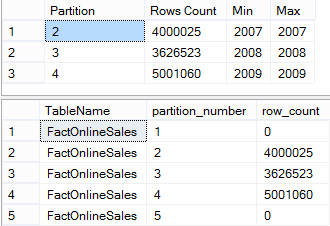
To check if everything is correct, I suggest using the following queries, displaying the number of rows per partition and the respective minimal year as the maximum year, stored within each of the partitions:
-- Check the Partitioning Information
SELECT $PARTITION.pfOnlineSalesDate(DateKey) AS Partition, COUNT(*) AS [Rows Count]
, Min(Year(DateKey)) as [MinYear], Max(Year(DateKey)) as [MaxYear]
FROM dbo.FactOnlineSales
GROUP BY $PARTITION.pfOnlineSalesDate(DateKey)
ORDER BY Partition ;
SELECT OBJECT_NAME(st.object_id) as TableName, partition_number, row_count
FROM sys.dm_db_partition_stats st
WHERE st.object_id = object_id('dbo.FactOnlineSales')
AND index_id = 1
ORDER BY partition_number;
As per picture below, you can see that we have 4, ~3.6 & 5 million rows in each of the partitions for the respective years 2007, 2008 & 2009, while the archive (pre-2007) and the year 2010 partition remains empty:
Merging Partitions
Let’s start with a simple test of merging the 2007 partition with the year 2008, by issuing the following command:
ALTER PARTITION FUNCTION pfOnlineSalesDate ()
MERGE RANGE ('2008-01-01');
It might ready you a reasonably huge surprise, but this command will fail, if you are using the Columnstore Indexes.
Msg 35344, Level 15, State 1, Line 26 MERGE clause of ALTER PARTITION statement failed because two nonempty partitions containing a columnstore index cannot be merged. Consider disabling the columnstore index before issuing the ALTER PARTITION statement, then rebuilding the columnstore index after ALTER PARTITION is complete.
The very same command will function without any problem, if we would simply avoid creating Clustered Columnstore Index …
The reason behind this limitation has to do with the fact that Columnstore Indexes do not sort or control the boundaries of the data, and this is biting the total implementation in such operations.
But let us not give up and try to merge the archive years (empty) and the year 2007, by issuing MERGE command to the date 2007-01-01:
-- Merging Partitions
ALTER PARTITION FUNCTION pfOnlineSalesDate ()
MERGE RANGE ('2007-01-01');
Well, it won’t take a second to find out that this operation will give an error as well, but hey – this will be a different error:
Msg 35345, Level 15, State 1, Line 32 MERGE clause of ALTER PARTITION statement failed because two partitions on different filegroups cannot be merged if either partition contains columnstore index data. Consider disabling the columnstore index before issuing the ALTER PARTITION statement, then rebuilding the columnstore index after ALTER PARTITION is complete.
It happens that we are using different file groups for each of the partitions, and if we would use the same file group for the 2 involved partitions, everything would function without any problem – to test this, let us create a new partitioning functioning [pfOnlineSalesDatePrimary] and a scheme [ColumstorePartitioningPrimary] that will be storing all partitions in the Primary Filegroup:
-- Load Data from the original table
SELECT *
into dbo.FactOnlineSalesPrimary
FROM dbo.FactOnlineSales WITH (TABLOCK);
-- Create the Partitioning scheme
create partition function pfOnlineSalesDatePrimary (datetime)
AS RANGE RIGHT FOR VALUES ('2007-01-01', '2008-01-01', '2009-01-01', '2010-01-01');
create partition scheme ColumstorePartitioningPrimary
AS PARTITION pfOnlineSalesDatePrimary
ALL to ([Primary]);
GO
-- Create traditional partitioned Clustered Index
Create Clustered Index CCI_FactOnlineSalesPrimary
on dbo.FactOnlineSalesPrimary (DateKey)
ON ColumstorePartitioningPrimary (DateKey)
-- Create Partitioned Clustered Columnstore Index
Create Clustered Columnstore Index CCI_FactOnlineSalesPrimary
on dbo.FactOnlineSalesPrimary
with (DROP_EXISTING = ON)
ON ColumstorePartitioningPrimary (DateKey);
Now if we try to execute the very same operation of joining the archive and the year 2007, the operation shall not fail, because all data files are to be found within the same filegroup:
ALTER PARTITION FUNCTION pfOnlineSalesDatePrimary ()
MERGE RANGE ('2007-01-01');
I know that you might say, that merging on the left side of the right-ranged partitioning function is something that never ever ever happened to you in production, BUT there are people who already faced this very situation. Really. And so I thought that you better be aware before it will be a little bit late, because splitting partitions is not the easiest thing to do. :)
Splitting Partitions
Splitting partitions – an easy task that you shall never face at the very last moment, when some team forgot to do their job at the end of the year, for example.
For the purpose of the demo, if you have merged the year 2009, please re-run the setup section before proceeding.
Let’s try to split the year 2009 into 2 halfs, separated by the 6 calendar months or simply by the 1st of July and for that purpose, lets mark the filegroup [Columnstore2009] as the next used one and issue split command
ALTER PARTITION SCHEME ColumstorePartitioning
NEXT USED [Columnstore2009]
-- Splitting Partitions
ALTER PARTITION FUNCTION pfOnlineSalesDate ()
SPLIT RANGE ('2009-07-01');
Surprise!
Msg 35346, Level 15, State 1, Line 26 SPLIT clause of ALTER PARTITION statement failed because the partition is not empty. Only empty partitions can be split in when a columnstore index exists on the table. Consider disabling the columnstore index before issuing the ALTER PARTITION statement, then rebuilding the columnstore index after ALTER PARTITION is complete.
We can not split a non-empty partition, when working with Columnstore Indexes !
Yes, the non-empty partition-splitting operation is not something that you should take on lightly, but it simply (and surely slowly) works with the rowstore indexes! Here is a script to test it out:
-- Load Data from the original table
SELECT *
into dbo.FactOnlineSalesRowstore
FROM dbo.FactOnlineSales WITH (TABLOCK);
-- Create the Partitioning scheme
create partition function pfOnlineSalesDateRowstore (datetime)
AS RANGE RIGHT FOR VALUES ('2007-01-01', '2008-01-01', '2009-01-01', '2010-01-01');
create partition scheme ColumstorePartitioningRowstore
AS PARTITION pfOnlineSalesDateRowstore
TO ( OldColumnstoreData, Columnstore2007, Columnstore2008, Columnstore2009, Columnstore2010 );
GO
-- Creation of a traditional Clustered Index
Create Clustered Index CCI_FactOnlineSalesRowstore
on dbo.FactOnlineSalesRowstore (DateKey)
ON ColumstorePartitioningRowstore (DateKey)
GO
ALTER PARTITION SCHEME ColumstorePartitioningRowstore
NEXT USED [Columnstore2009]
GO
-- Splitting Partitions
ALTER PARTITION FUNCTION pfOnlineSalesDateRowstore ()
SPLIT RANGE ('2009-07-01');
There are workarounds, such as taking out the data out of a partition, splitting it and then reloading data into the respective partitions, but this does not sound like a fun procedure, when we could simply issue 1 command to split the range, but this is something that everyone working with Columnstore Indexes should be aware.
Final Thoughts
Keep a good empty partition free from any data. Set it to unrealistic dates/values if needed, so that you are playing safe.
If you are a consultant and landing on the migration project from Rowstore to Columnstore, keep in mind that it might require a different amount of work, if the partitioning practices of having empty partitions is not well kept. Rowstore is different to Columnstore and the internals do matter, making the learning curve a very interesting/challenging for everyone.
Partitioning is available in every single edition (yes, including Standard Edition), starting with SQL Server 2016 Service Pack 1, meaning that this feature will be finding an increased usage in the nearest months, and if you are working with Data Warehousing and your fact tables are in the 100s of millions of rows, there are few reasons why your tables should not be partitioned.
We can not have every feature in Columnstore Indexes that we have had in the Rowstore, simply because the technologies are sufficiently different and a huge effort of implementing a feature that is not a makeIt/BreakIt for the most SQL Server shops is something that will stay for a long time like this. This has been this way since the original SQL Server 2012 release and 4 versions later I do not remember people crying about it in the way that this would be considered life-changing.
Well, if you still have doubts, here is a Connect Item on one of these topics, that was closed as Won’t Fix:
https://connect.microsoft.com/SQLServer/feedback/details/931294/sql-server-2014-clustered-columnstore-cci-partitioning (Given that Connect is shutting down, this link will probably die in a couple of days)
Here is a screenshot with the essential commentary from 2014 from Microsoft:

to be continued with Columnstore Indexes – part 117 (“Clustered vs Nonclustered”)
Hi Niko,
I don’t understand this part:
“The reason behind this limitation [can’t merge non-empty partitions] has to do with the fact that Columnstore Indexes do not sort or control the boundaries of the data, and this is biting the total implementation in such operations.”
Surely it’s the point of the partition function/scheme to control the boundaries. Why would the columnstore index itself have to be involved in the MERGE at all? Rowgroups don’t span partitions, do they?
Couldn’t SQL Server just move the rowgroups from the merged partition into the destination partition? I realize that may result in suboptimal compression but it would be as good compression as having the two separate rowgroups in two separate partitions.
Hi Steve,
I am not a developer and do not have access to the source code, so all my thoughts and comments are guesses in the best case. :)
What you have described is absolutely correct, but consider the fact that this code will need to support queries that are reading information (avoid loosing rows, avoid scanning them for the second time), and allowing other data modification queries (inserts, deletes & updates) – this will look quite a challenging task, given that the framework should have it own limitations.
I believe that partitioning code is largely written for SQL Server 2012 and they were quite in a hurry to wrap it up before release.
Even though they were improvements, the largest part should have stayed the same (totally guessing here) …
Best regards,
Niko