Continuation from the previous 93 parts, the whole series can be found at https://www.nikoport.com/columnstore/.
This blog post will talk about some of the common problematic practices for the Columnstore Indexes and how to avoid or solve them.
It is not intended as a bashing of the Columnstore Indexes but as a guide of how to detect and resolve them. This is the first blog post in the series of the blog posts about the common problems and solutions.
The focus of this particular blog post is the Partitioning. An enterprise-feature only before the SQL Server 2016 with Service Pack 1, after which it became all-edition one, it has been one of the most beloved feature for any BI & Data Warehousing professionals working with big amounts of data, for managing and loading the data.
Some of the recent investments (specifically for the SQL Server 2016 the TRUNCATE statement supporting on the partition level and all the online rebuilds in the previous editions of the SQL Server) has enabled even wider range of the solutions – with my personal hopes lying on the partition level statistics one fine day. :)
A lot of people are expecting the partitioning to bring some performance improvements by eliminating the partitions, and surely it happens a number of times but there are more quirks about Columnstore Indexes partitioning than one might initially think.
Let’s us start wit the setup first and for the tests, I will use my own generated copy of the TPCH database (1GB version), that I have done with the help of the HammerDB.
As usually, the location of my backup file is C:\Install and I will use the following script to restore and reconfigure the database on SQL Server 2014 & 2016 instances (with an obvious difference that the compatibility level will be set to 120 & 130 accordingly)
/*
* This script restores backup of the TPC-H Database from the C:\Install
*/
USE [master]
if exists(select * from sys.databases where name = 'tpch')
begin
alter database [tpch]
set SINGLE_USER WITH ROLLBACK IMMEDIATE;
end
RESTORE DATABASE [tpch]
FROM DISK = N'C:\Install\tpch_1gb_new.bak' WITH FILE = 1, NOUNLOAD, STATS = 1
alter database [tpch]
set MULTI_USER;
GO
GO
ALTER DATABASE [tpch] SET COMPATIBILITY_LEVEL = 130
GO
USE [tpch]
GO
EXEC dbo.sp_changedbowner @loginame = N'sa', @map = false
GO
USE [master]
GO
ALTER DATABASE [tpch] MODIFY FILE ( NAME = N'tpch', FILEGROWTH = 256152KB )
GO
ALTER DATABASE [tpch] MODIFY FILE ( NAME = N'tpch_log', SIZE = 1200152KB , FILEGROWTH = 256000KB )
Let’s convert 2 biggest tables of the TPCH (lineitem & orders) to the columnstore, by creating the copies of the respective tables with Clustered Columnstore Indexes:
USE [tpch]
GO
drop table if exists dbo.lineitem_cci;
-- Data Loding
SELECT [l_shipdate]
,[l_orderkey]
,[l_discount]
,[l_extendedprice]
,[l_suppkey]
,[l_quantity]
,[l_returnflag]
,[l_partkey]
,[l_linestatus]
,[l_tax]
,[l_commitdate]
,[l_receiptdate]
,[l_shipmode]
,[l_linenumber]
,[l_shipinstruct]
,[l_comment]
into dbo.lineitem_cci
FROM [dbo].[lineitem];
GO
-- Create Clustered Columnstore Index
create clustered columnstore index cci_lineitem_cci
on dbo.lineitem_cci;
USE [tpch]
GO
DROP TABLE IF EXISTS dbo.orders_cci;
SELECT [o_orderdate]
,[o_orderkey]
,[o_custkey]
,[o_orderpriority]
,[o_shippriority]
,[o_clerk]
,[o_orderstatus]
,[o_totalprice]
,[o_comment]
into dbo.orders_cci
FROM [dbo].[orders];
create clustered columnstore index cci_orders_cci
on dbo.orders_cci;
GO
Partitioning
Remember kids – Partitioning is NOT a PERFORMANCE IMPROVEMENT !
It is a data management improvement that might or might not deliver some improvements.
Partitioning your data wrongly with Columnstore Indexes will be a huge killer for your performance.
The issue here is when you are dealing with partitioning in Columnstore Indexes (especially with the Clustered Columnstore ones), you need to watch out for the size of the row groups and if they are too small (times less than 1048576 rows), your performance will suffer greatly.
For showing the result, I will create a copy the dbo.lineitem table where I shall partition it by day, making on average the size of each of the row groups to be equal to 2375 rows.
The following script will define the partition for each of the dates between 1st of January 1992 and 1st of January of 1999:
DECLARE @bigString NVARCHAR(MAX) = '', @partFunction NVARCHAR(MAX); ;WITH cte AS ( SELECT CAST( '1 Jan 1992' AS DATE ) testDate UNION ALL SELECT DATEADD( day, 1, testDate ) FROM cte WHERE testDate < '31 Dec 1998' ) SELECT @bigString += ',' + QUOTENAME( CONVERT ( VARCHAR, testDate, 106 ), '''' ) FROM cte OPTION ( MAXRECURSION 5000 ) SELECT @partFunction = 'CREATE PARTITION FUNCTION fn_DailyPartition (DATE) AS RANGE RIGHT FOR VALUES ( ' + cast(STUFF( @bigString, 1, 1, '' )as nvarchar(max)) + ' )' EXEC sp_Executesql @partFunction CREATE PARTITION SCHEME ps_DailyPartScheme AS PARTITION fn_DailyPartition ALL TO ( [PRIMARY] );
Now let us create a partitioned copy of the dbo.lineitem table, for having less space on my disk drive I went with loading data into an existing Columnstore Index and compressing it with ALTER INDEX REORGANIZE (COMPRESS_ALL_ROW_GROUPS = ON):
-- Data Loding
SELECT [l_shipdate]
,[l_orderkey]
,[l_discount]
,[l_extendedprice]
,[l_suppkey]
,[l_quantity]
,[l_returnflag]
,[l_partkey]
,[l_linestatus]
,[l_tax]
,[l_commitdate]
,[l_receiptdate]
,[l_shipmode]
,[l_linenumber]
,[l_shipinstruct]
,[l_comment]
into dbo.lineitem_cci_part
FROM [dbo].[lineitem]
where 1 = 0;
GO
-- Create Clustered Index
create clustered index cci_lineitem_cci_part
on dbo.lineitem_cci_part ( [l_shipdate] )
WITH (DATA_COMPRESSION = PAGE)
ON ps_DailyPartScheme( [l_shipdate] );
-- Create Clustered Columnstore Index
create clustered columnstore index cci_lineitem_cci_part
on dbo.lineitem_cci_part
WITH (DROP_EXISTING = ON)
ON ps_DailyPartScheme( [l_shipdate] );
insert into dbo.lineitem_cci_part (l_shipdate, l_orderkey, l_discount, l_extendedprice, l_suppkey, l_quantity, l_returnflag, l_partkey, l_linestatus, l_tax, l_commitdate, l_receiptdate, l_shipmode, l_linenumber, l_shipinstruct, l_comment)
SELECT [l_shipdate]
,[l_orderkey]
,[l_discount]
,[l_extendedprice]
,[l_suppkey]
,[l_quantity]
,[l_returnflag]
,[l_partkey]
,[l_linestatus]
,[l_tax]
,[l_commitdate]
,[l_receiptdate]
,[l_shipmode]
,[l_linenumber]
,[l_shipinstruct]
,[l_comment]
FROM [dbo].[lineitem]
alter index cci_lineitem_cci_part
on dbo.lineitem_cci_part
reorganize with (COMPRESS_ALL_ROW_GROUPS = ON);
Now I am ready to test a couple of simple queries, let's start by simply showing the total discounts from our sales:
set statistics time, io on select SUM(l_discount) from dbo.lineitem_cci select SUM(l_discount) from dbo.lineitem_cci_part
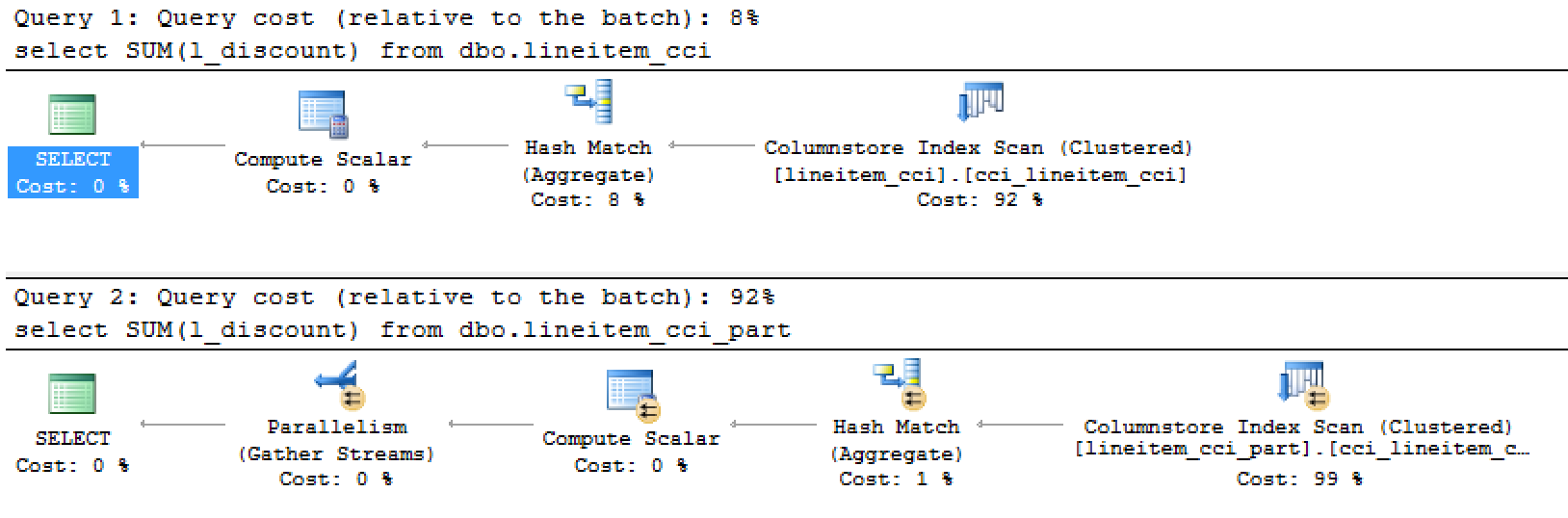
Needless to say that looking at the execution plans you notice that the actual execution plan shows 10 times difference between them, even though both tables contain the very same data!
The query cost for the partitioned table is staggering - it is around 10 times bigger (~8.8) vs (~0.81) for the first query.
The execution times reflect in part this situation: 12 ms vs 91 ms. Non-partitioned table performs almost 9 times faster overall and the spent CPU time is reflecting it: 15 ms vs 94 ms. Remember, that both tables are Columnstore Indexes based ! Partitioning your table in a wrong way will contain a huge penalty that might not be directly detectable through the execution plan of the complex queries. Well, you might want to use the CISL, just saying :)
For better understanding of the impact here is the script for the same table but partitioned per month:
DECLARE @bigString NVARCHAR(MAX) = '',
@partFunction NVARCHAR(MAX);
;WITH cte AS (
SELECT CAST( '1 Jan 1992' AS DATE ) testDate
UNION ALL
SELECT DATEADD( month, 1, testDate )
FROM cte
WHERE testDate < '31 Dec 1998'
)
SELECT @bigString += ',' + QUOTENAME( CONVERT ( VARCHAR, testDate, 106 ), '''' )
FROM cte
OPTION ( MAXRECURSION 5000 )
SELECT @partFunction = 'CREATE PARTITION FUNCTION fn_MonthlyPartition (DATE) AS RANGE RIGHT FOR VALUES ( ' + cast(STUFF( @bigString, 1, 1, '' )as nvarchar(max)) + ' )'
print @partFunction;
EXEC sp_Executesql @partFunction
CREATE PARTITION SCHEME ps_MonthlyPartScheme
AS PARTITION fn_MonthlyPartition
ALL TO ( [PRIMARY] );
drop table if exists dbo.lineitem_cci_part_month
-- Data Loding
SELECT [l_shipdate]
,[l_orderkey]
,[l_discount]
,[l_extendedprice]
,[l_suppkey]
,[l_quantity]
,[l_returnflag]
,[l_partkey]
,[l_linestatus]
,[l_tax]
,[l_commitdate]
,[l_receiptdate]
,[l_shipmode]
,[l_linenumber]
,[l_shipinstruct]
,[l_comment]
into dbo.lineitem_cci_part_month
FROM [dbo].[lineitem]
where 1 = 0;
GO
-- Create Clustered Index
create clustered index cci_lineitem_cci_part_month
on dbo.lineitem_cci_part_month ( [l_shipdate] )
WITH (DATA_COMPRESSION = PAGE)
ON ps_MonthlyPartScheme( [l_shipdate] );
-- Create Clustered Columnstore Index
create clustered columnstore index cci_lineitem_cci_part_month
on dbo.lineitem_cci_part_month
WITH (DROP_EXISTING = ON)
ON ps_MonthlyPartScheme( [l_shipdate] );
insert into dbo.lineitem_cci_part_month (l_shipdate, l_orderkey, l_discount, l_extendedprice, l_suppkey, l_quantity, l_returnflag, l_partkey, l_linestatus, l_tax, l_commitdate, l_receiptdate, l_shipmode, l_linenumber, l_shipinstruct, l_comment)
SELECT [l_shipdate]
,[l_orderkey]
,[l_discount]
,[l_extendedprice]
,[l_suppkey]
,[l_quantity]
,[l_returnflag]
,[l_partkey]
,[l_linestatus]
,[l_tax]
,[l_commitdate]
,[l_receiptdate]
,[l_shipmode]
,[l_linenumber]
,[l_shipinstruct]
,[l_comment]
FROM [dbo].[lineitem_cci]
alter index cci_lineitem_cci_part_month
on dbo.lineitem_cci_part_month
reorganize with (COMPRESS_ALL_ROW_GROUPS = ON);
Now, let's compare all 3 results of the Total Sales Discounts:
set statistics time, io on select SUM(l_discount) from dbo.lineitem_cci select SUM(l_discount) from dbo.lineitem_cci_part select SUM(l_discount) from dbo.lineitem_cci_part_month
 The query execution time of the monthly partitioned table is extremely close to the non-partitioned one, as one would expect given the number of rows that every row group contains. It took just 15 ms on the average to run the query, when comparing to a non-partitioned table that required 11 ms on the average in my tests in my VM. The CPU time for each of the queries is appears to be equal or indistinguishably similar, being around 15-16 ms in both cases.
The query execution time of the monthly partitioned table is extremely close to the non-partitioned one, as one would expect given the number of rows that every row group contains. It took just 15 ms on the average to run the query, when comparing to a non-partitioned table that required 11 ms on the average in my tests in my VM. The CPU time for each of the queries is appears to be equal or indistinguishably similar, being around 15-16 ms in both cases.
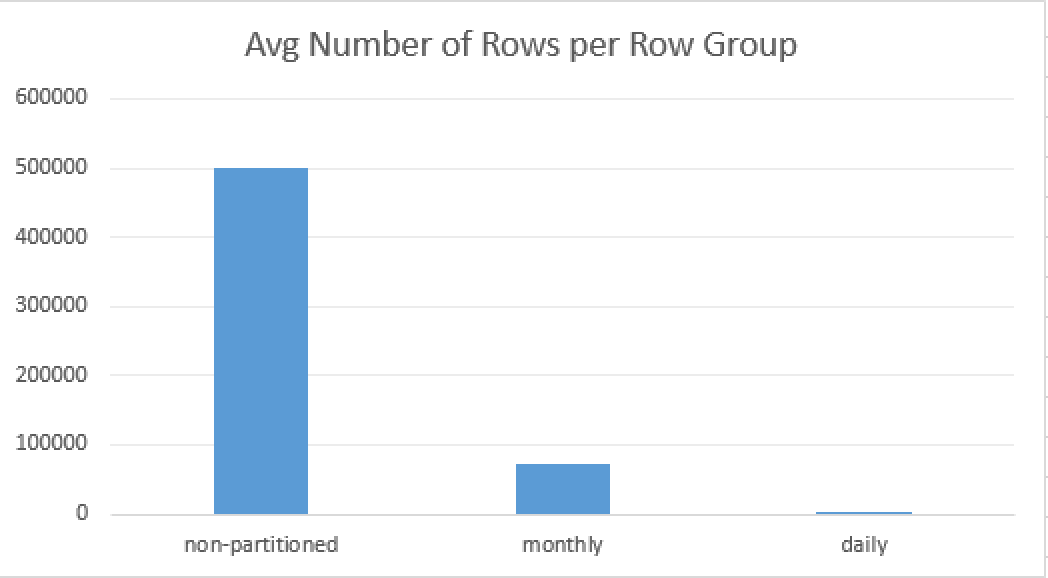 The difference for the execution times lies within the number of partitions, but mostly based on the average size of the Row Group. As you should know, the perfect size for a Row Group would be a 1048576 rows, and an average size for a Row Group for a daily partitioned table is just 2375 rows, while for the monthly-partitioned table this number increases around 35 times to 72270 rows.
The difference for the execution times lies within the number of partitions, but mostly based on the average size of the Row Group. As you should know, the perfect size for a Row Group would be a 1048576 rows, and an average size for a Row Group for a daily partitioned table is just 2375 rows, while for the monthly-partitioned table this number increases around 35 times to 72270 rows.
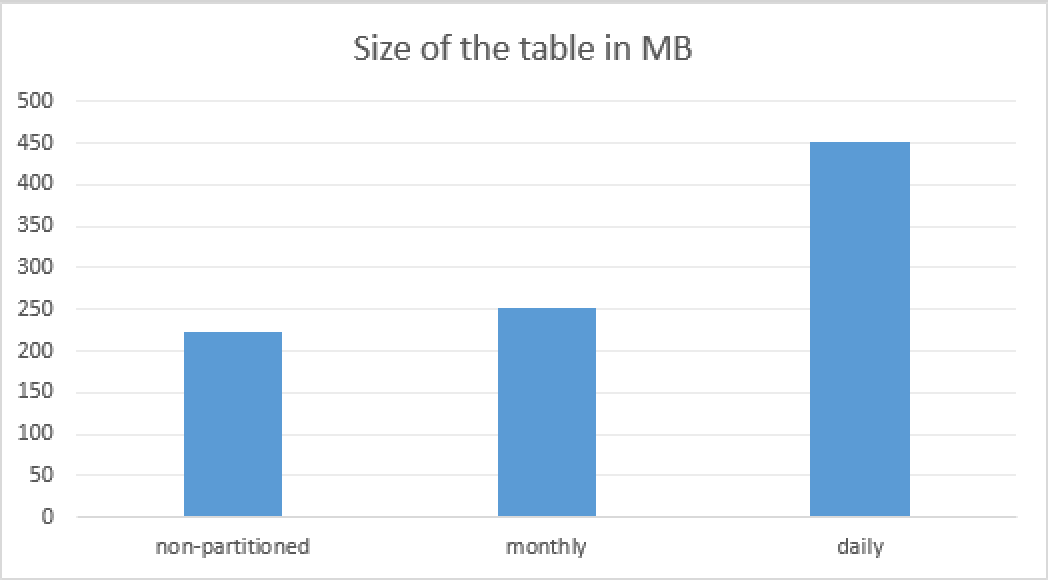 From a different angle you will notice that the actual sizes of the table containing the very same amount of data occupies quite a different amount of space - it takes more than double amount of space ~463MB for a daily partitioned table (with 2828 partitions) when comparing with the original table 227MB. The monthly partitioned table containing just 83 partitions occupies around 257MB which represents less than 15% increase in the size when compared with the original table. A bi-monthly partitioned in this case would be overall more beneficial, though not a critical improvement.
From a different angle you will notice that the actual sizes of the table containing the very same amount of data occupies quite a different amount of space - it takes more than double amount of space ~463MB for a daily partitioned table (with 2828 partitions) when comparing with the original table 227MB. The monthly partitioned table containing just 83 partitions occupies around 257MB which represents less than 15% increase in the size when compared with the original table. A bi-monthly partitioned in this case would be overall more beneficial, though not a critical improvement.
Let us consider the another query, surely just because one single query runs slowly you should not be judging the whole small size partitioning story when using Columnstore Indexes.
I have selected the query 21 from the TPCH performance test and here is the comparison between the non-partitioned and the daily-partitioned tables (notice that they are being used 3 times in the same query):
set statistics time on set nocount on select s_name, count(*) as numwait from supplier, lineitem_cci l1, orders, nation where s_suppkey = l1.l_suppkey and o_orderkey = l1.l_orderkey and o_orderstatus = 'F' and l1.l_receiptdate > l1.l_commitdate and exists ( select * from lineitem_cci l2 where l2.l_orderkey = l1.l_orderkey and l2.l_suppkey <> l1.l_suppkey ) and not exists ( select * from lineitem_cci l3 where l3.l_orderkey = l1.l_orderkey and l3.l_suppkey <> l1.l_suppkey and l3.l_receiptdate > l3.l_commitdate ) and s_nationkey = n_nationkey and n_name = 'GERMANY' group by s_name order by numwait desc, s_name; select s_name, count(*) as numwait from supplier, lineitem_cci_part l1, orders, nation where s_suppkey = l1.l_suppkey and o_orderkey = l1.l_orderkey and o_orderstatus = 'F' and l1.l_receiptdate > l1.l_commitdate and exists ( select * from lineitem_cci_part l2 where l2.l_orderkey = l1.l_orderkey and l2.l_suppkey <> l1.l_suppkey ) and not exists ( select * from lineitem_cci_part l3 where l3.l_orderkey = l1.l_orderkey and l3.l_suppkey <> l1.l_suppkey and l3.l_receiptdate > l3.l_commitdate ) and s_nationkey = n_nationkey and n_name = 'GERMANY' group by s_name order by numwait desc, s_name;
After running both queries a couple of times I have caught the following average execution times:
--CPU time = 861 ms, elapsed time = 293 ms.
--CPU time = 1906 ms, elapsed time = 790 ms.
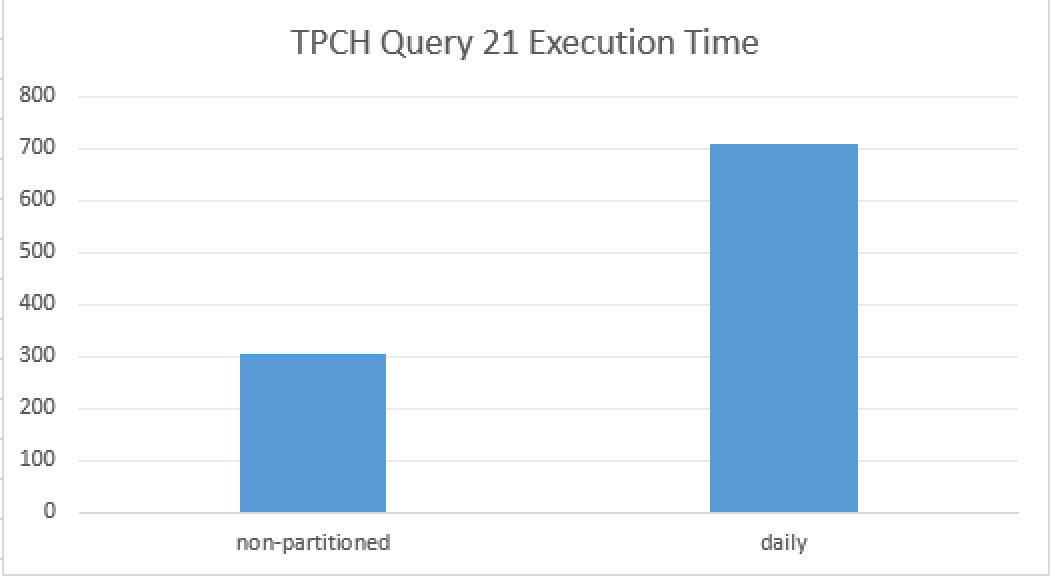 We are talking here about more than double of the actual elapsed execution time difference. This is taking in count that I am running a pretty fast SSD for this VM, and if you are running a traditional storage or in production under heavy load, the execution time should differ in more times.
We are talking here about more than double of the actual elapsed execution time difference. This is taking in count that I am running a pretty fast SSD for this VM, and if you are running a traditional storage or in production under heavy load, the execution time should differ in more times.
Interestingly if I am running the same query for the monthly partitioned table, the actual execution time becomes even faster than the non-partitioned table, which is not that surprising given that we are not extracting the content of the whole table, but rather smaller chunks of around 340.000 rows and the bigger Row Groups here are of a less advantage.
Just because you can partitioned your table with thousands of partitions (up to 15.000 to be more precise), it does not mean that you should use the highest available number. Consider merging partitions (and watch out for some of the Columnstore indexes quirks there) if the average row group size is too small, but mostly think very precise about defining it when creating partitioning for the Columnstore Indexes. Research & analyse your data and monitor its developments.
to be continued with Columnstore Indexes – part 95 ("Basic Query Patterns")
Hi Niko,
As you said : partionning is a data management improvement.
But you forgot the main point with partionned tables : “Always querying with the partition key !”.
In your article, you’ve defined ‘l_shipdate’ as the partition key but you didn’t use it in your queries (even in the query 21 from the TPCH).
It’s the worst use case for partionned tables !
Regards,
Hi Franck,
Loading data daily does not mean that I can include the date key into queries. :)
Partitioning is a data management feature and while it can be incredibly useful for the performance – as the article implies: it can hurt it sometimes.
Regarding the data sorting and row group elimination, you can easily do that with CISL doMaintenance function or manually guaranteeing segment alignment and so the same amount of data will be processed even with included partition key, but the decreased size of the Row Groups will kill the performance of the queries.
Best regards,
Niko Neugebauer
This is an excellent example of the side effects of improper partitioning, but I’m also curious about the benefits of proper partitioning. Are there real world examples of horizontal partitioning of clustered columnstore tables with say shared tables across users and partitioning by user or groups of users?
Hi Alton,
Partitioning is mostly a data management feature.
For that purpose if you are loading data by the user (or querying massive amounts with this predicate) – you might see improvements.
The biggest benefit of proper partitioning for me is that you can load data on the needed interval basis and eliminate chunks of information based on the partitioning predicate, besides the additional sorting within the partition.
Best regards,
Niko
Hi Niko,
We have CCIs and Daily partitions on some of our bigger tables and we always query by day and all columns. The problem is most partitions are very small. I guess we should try monthly even yearly partitions, or no partitions?
Hi Kuzey,
Absolutely, please consider & test the increased partitions. Weekly or maybe even monthly.
Best regards,
Niko Neugebauer
Hello Niko,
We are doing a research currently on the usage of the partitioned tables with clustered columnstore index for online analytics. We noticed that execution time for the SELECT with aggregations on non partitioned table with the columnstore index runs significantly faster than the query that runs against a partition table with the same volume of data. Our table is partitioned on date. I currently have only 2 partitions with 17 mil records in one and 1.3 million in the second. All rows in each partition have the same dates.
I see partition elimination in the execution plan ( Seek Predicate). The execution plan also shows the Predicate for the date criteria. For non- partition table the execution plan looks identical, except it does not include partition elimination, hence it does not have Seek Predicate, but only Predicate for the date criteria.
Both tables have partitiondate column, but only one table is partitioned on this column.
When I do a simple aggregation with WHERE clause on the partitiondate column and GROUP BY State the non-partitioned table performs better.
The execution times as following:
Partitioned Table:
SQL Server Execution Times:
CPU time = 2638 ms, elapsed time = 215 ms.
Non-partitioned table:
SQL Server Execution Times:
CPU time = 955 ms, elapsed time = 70 ms.
I have only 10 partitions. Only two are filled with data.
Do you know if there is an overhead for partition tables? Does it do anything internally to select the data first based on Seek Predicate?
Any suggestions on how to investigate the reason for such difference in the execution times?
Thank you very much,
Lana.
Hi Lana,
how many row groups are there per partition, how big are they ?
How many reads do you get in the first query vs the second one ?
How many Row Groups are skipped in both scenarios ?
The partitioned tables tend to be slower, but typically unless they are not very small (just a couple of thousands of rows and a very high number of row groups and partitions) – there should not be such a big difference.
Can you also share the execution plans in order to see what is exactly different in them ?
Best regards,
Niko Neugebauer