Continuation from the previous 116 parts, the whole series can be found at https://www.nikoport.com/columnstore/
An important issue I have faced already a couple of times in production servers was the usage of the Nonclustered Columnstore Indexes vs the usage of Clustered Columnstore Indexes. It seems that there is enough confusions about options and their availability, plus the global overview of the further development of the features might help you future planning of the upgrades.
The title of the blog post is limited in the sense that I do not refer to In-Memory solutions, while they are certainly part of this blog post, but hey – I am not calling it “the mother of all columnstore indexes until 2018” :)
I have taken 4 currently available SQL Server versions (2012,2014,2016 & 2017) that support Columnstore Indexes and tried to describe and list the available scenarios and their support.
Since Microsoft Azure SQL Database & Azure SQL DataWarehouse are prominently important members of the daily business for growing part of the IT, I am also including SOME informations on their support.
For the scenarios at the moment I am currently taking the following ones under consideration:
– Data Warehouse (also Business Intelligence / Reporting Solution) – we load data into denormalised tables, during the defined periods and process massive amounts of information.
– OLTP with HTAP (Hybrid Transaction Analytical Processing) – this is your OLTP workload on which we want to do some real-time reporting
Of course we are leaving a lot of hybrid solutions because world of data is changing steadily, but I found that we can mostly classify the workloads in 1 of these 2 scenarios for the start (oh yes, I anticipate a number of versions of this blog post)
SQL Server 2012
In SQL Server 2012 life was easy for the choice of the Columnstore Index – we have had only the Nonclustered Columnstore Indexe which was also read-only, making partition switching and disabling/modifying table/enabling scenarios as possible, and for that reason the only supported scenario as the Data Warehouse. As long as we had not nit the limitations of the Batch Execution Mode (LEFT JOIN, UNION ALL, IN, EXISTS, etc) or the engine limitations (Numeric 18 precision, LOBs, etc) we could use the Nonclustered Columnstore Indexes for our DWH/Reporting scenario:

Known limitations:
– Severely Limited Batch Execution Mode (Joins, Predicates, No Mixed Mode, No Single-Threaded Execution)
– Unsupported Data Types: CLR, Spatial, LOBs, Uniqueidentifier, XML, SQLVariant, RowVersion
– No Numeric Data Types with precision superior to 18
– No Snapshot & Read Committed Snapshot Isolation Modes (AlwaysOn Availability Groups are fine with the Readable Secondaries because Nonclustered Columnstore Indexes are non-updatable)
– No Data Sorting for Build/Rebuild Process
– No Transactional Replication Support
– No CDC / CT Support
– No Filetable / Filestream
– No Triggers (you can create them but can’t modify the table)
SQL Server 2014
SQL Server 2014 was a ground-breaking release which brought the support of the updatable Columnstore Index – the Clustered Columnstore Index, while the Nonclustered Columnstore Index remained non-updatable.
One would jump on the conclusion that everything for the Data Warehouse scenario would be using the Clustered Columnstore Index only, but there are a couple of important exceptions/gotchas that need to be taken in account.
On the picture below, you will still find that the Data Warehouse scenario is the only one being supported with no solution for the OLTP ones (the insane locking of the pure Clustered Columnstore will kill any hope for the OLTP table within seconds):

General Limitations:
– No Single-Threaded Execution for the Batch Execution Mode
– No Online Rebuild Operations
– Unsupported Data Types: CLR, Spatial, LOBs, XML, SQLVariant, RowVersion
– No Snapshot & Read Committed Snapshot Isolation Modes (AlwaysOn Availability Groups are fine with the Readable Secondaries because Nonclustered Columnstore Indexes are non-updatable)
– No Data Sorting for Build/Rebuild Process
– No Transactional Replication Support
– No CDC / CT Support
– No Filetable / Filestream
– No Triggers (you can create them but can’t modify the table)
– No In-Memory support (can’t create either Clustered or Nonclustered Columnstore)
– No Calculated Columns
Exceptions for DHW – to choose Nonclustered Columnstore when:
– only a subset of the columns of the table and need to avoid the unsupported data types
– require Primary/Foreign Keys
– require Unique Constraints
– require Short-Range Scans or Point Lookups (and hence the Nonclustered Rowstore Indexes)
– require using Snapshot or Read Committed Snapshot isolation levels
– require using Availability Groups Readable Secondaries
SQL Server 2016
SQL Server 2016 was the greatest release since SQL Server 2005, bringing the biggest number of features and improvements, which for the Columnstore Indexes meant 3 distinct architectures:
– Disk-based Clustered Columnstore (mainly designed for DWH)
– Disk-based UPDATABLE Nonclustered Columnstore (mainly designed for the HTAP scenarios (OLTP + Real-Time Reporting))
– In-Memory Clustered Columnstore (mainly designed for the In-Memory HTAP scenarios)
The Disk-Based HTAP support became possible, because Nonclustered Columnstore Index finally became updatable, allowing to add/modify/delete rows in the table, as well as the any needed meta-data modifications for it.
Since this release we can finally talk about multiple scenario support, with a good HTAP & DWH support, but let us start with a Data Warehouse support:
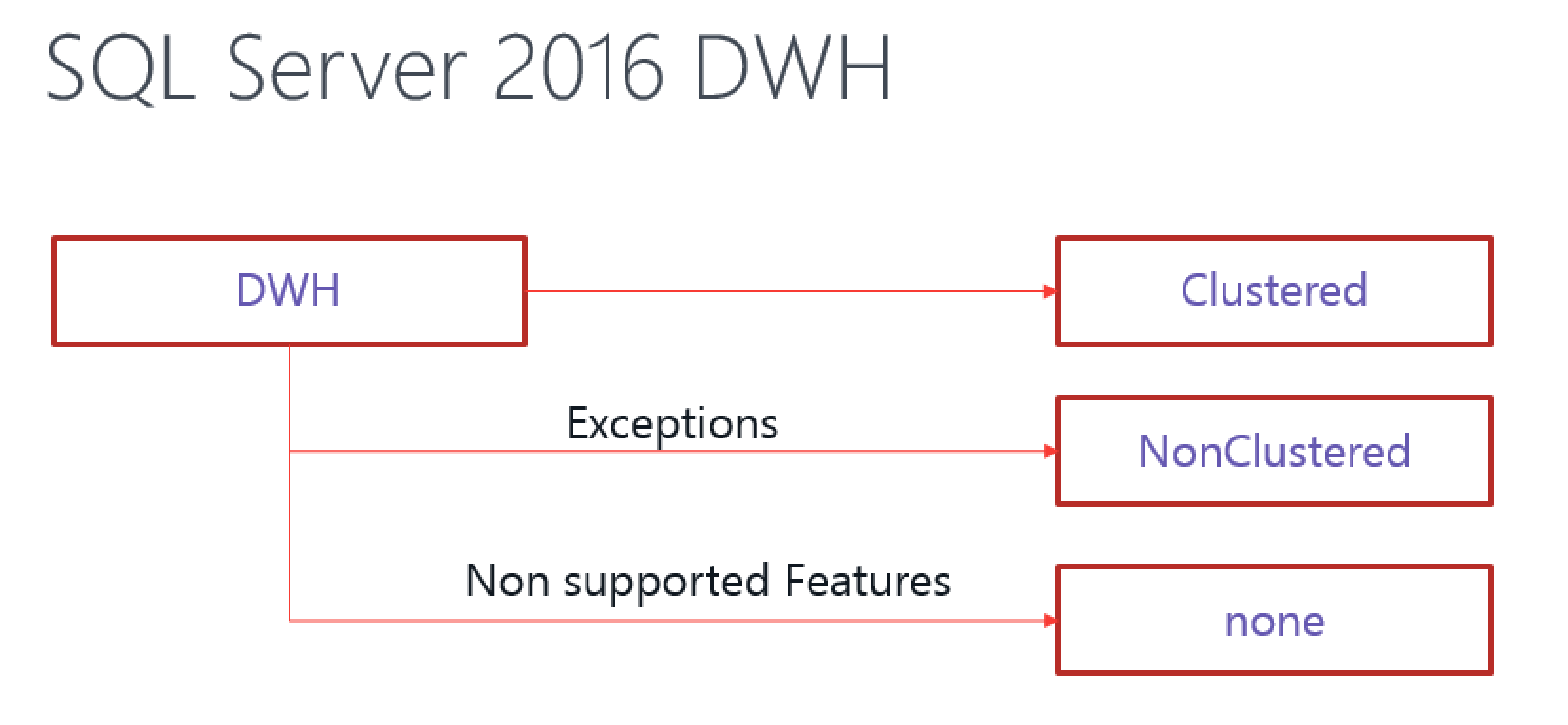
For the Data Warehouse scenario we should choose Clustered Columnstore Index by default and in the most situations it should be enough. Of course, there are some exceptions for the technology, and here you will find some of them listed (and mostly the new feature additions for the supporting of the Nonclustered Columnstore Index are this exceptions worth noting):
Exceptions for DHW – to choose Nonclustered Columnstore when:
– only a subset of the columns of the table and need to avoid the unsupported data types
– only a subset of the data is needed for processing (use filtered Nonclustered Columnstore Index for this purpose)
– CDC & CT (Change Data Capture & Change Tracking)
– Transactional Replication (Nonclustered Columnstore Index supports it and actually even filtered Nonclustered Columnstore Index is included in the support)
– Indexed Views (only Nonclustered Columnstore Index is supported)
Now, let us take a look at the HTAP scenarios, where Microsoft provided ways to work with both Disk-Based and In-Memory scenarios. I will not dive here for the reasons of choosing the In-Memory over the Disk-Based solutions, but Latches would be one of the definitive key-words here:
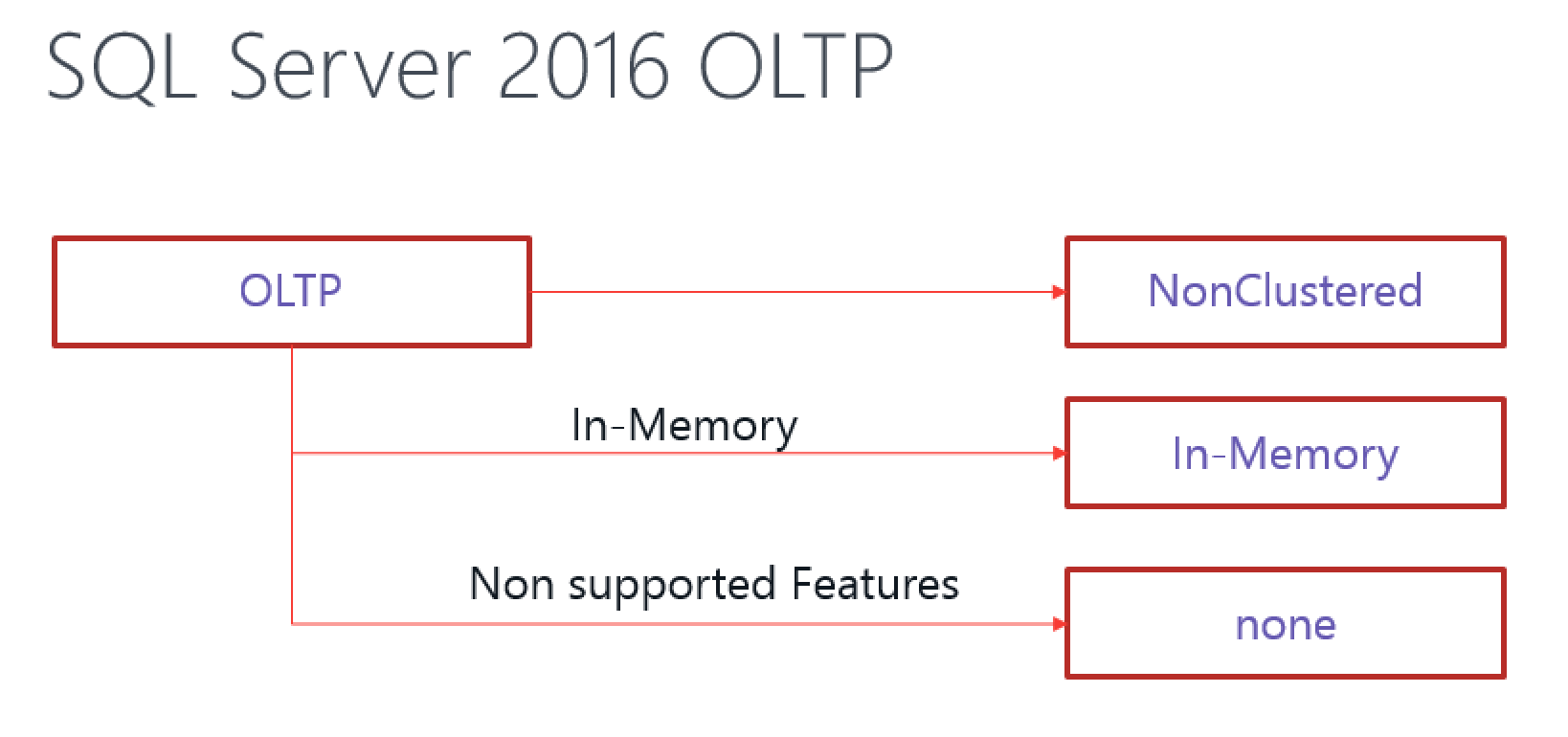
There are some pretty obvious cases when you will have to choose Disk-based Nonclustered Columnstore Indexes over the In-Memory Columnstore Indexes:
– When needing Foreign Keys to the tables that need to be kept On-Disk (too big for In-Memory, Unsupported Data Types, etc)
– Unsupported Data Types (CLR, LOBs, XML, SQLVariant, RowVersion)
– Computed Columns (which can be avoided in Nonclustered Columnstore Indexes)
Another extra warning goes for avoiding using Natively Compiled Stored Procedure (they can’t use In-Memory Clustered Columnstore Index)
Still there are some limitations to be noted (besides obvious one-sided support for Nonclustered Columnstore Index for some of the features):
General Limitations:
– Unsupported Data Types: CLR, Spatial, LOBs
– No Data Sorting for Build/Rebuild Process
– No Replication Support
– No Filetable / Filestream
– No Triggers
– No Calculated Columns
SQL Server 2017
SQL Server 2017 has brought mostly bug-fixes and some important delightful features support for the existing architectures, such as LOBs support for the Clustered Columnstore Indexes, non-persisted Computed Columns for Clustered Columnstore Indexes or Online Rebuilds for the Nonclustered Columnstore Indexes.
The most improvement were generic for all Columnstore Indexes, such as Adaptive Query Processing, allowing to adjust execution plan strategies during the execution, Trivial Plan elimination, etc.
The Data Warehouse scenario for SQL Server 2017 looks like this:

Exceptions for DHW – to choose Nonclustered Columnstore when:
– only a subset of the columns of the table and need to avoid the unsupported data types
– only a subset of the data is needed for processing (use filtered Nonclustered Columnstore Index for this purpose)
– CDC & CT (Change Data Capture & Change Tracking)
– Transactional Replication (Nonclustered Columnstore Index supports it and actually even filtered Nonclustered Columnstore Index is included in the support)
– Indexed Views (only Nonclustered Columnstore Index is supported)
– Online Rebuilds are required (this is new for SQL Server 2017, since Nonclustered Columnstore Indexes finally started supporting it)
As for the Nonclustered Columnstore Indexes, they became more exciting by getting the Online Rebuild operations, narrow update strategies, but generally there were no ground-breaking changes.
With the support of the LOBs and non-persisted computed columns for the Clustered Columnstore Indexes, the number of scenarios where a resolution would be the limited usage of the Clustered Columnstore Indexes has increased, but I won’t recommend it unless in absolutely exceptional case.
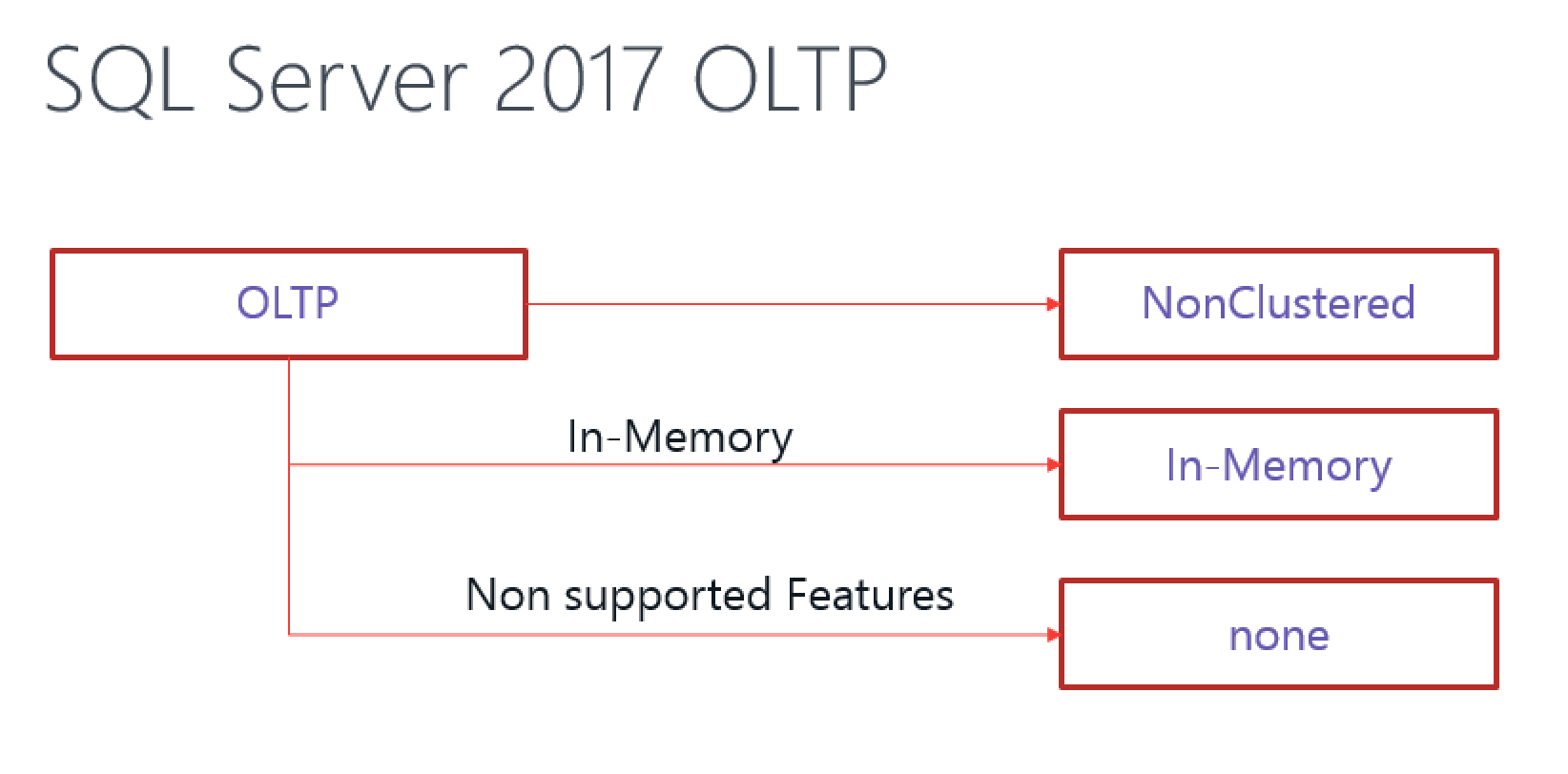
There are some pretty obvious cases when you will have to choose Disk-based Nonclustered Columnstore Indexes over the In-Memory Columnstore Indexes:
– When needing Foreign Keys to the tables that need to be kept On-Disk (too big for In-Memory, Unsupported Data Types, etc)
– Unsupported Data Types (CLR, etc)
Another extra warning goes for avoiding using Natively Compiled Stored Procedure (they can’t use In-Memory Clustered Columnstore Index)
Still there are some limitations to be noted (besides obvious one-sided support for Nonclustered Columnstore Index for some of the features):
General Limitations:
– Unsupported Data Types: CLR, Spatial, LOBs, XML, SQLVariant, RowVersion
– No Data Sorting for Build/Rebuild Process
– No Replication Support
– No Filetable / Filestream
– No Triggers
– No persisted Calculated Columns
Notice that I am not including some of the limitations, such as 8 bytes for the aggregate predicate pushdown, seeing them as more generic Batch Mode limitations, which should disappear eventually, and not preventing choosing Columnstore Indexes.
Azure SQL Database
Azure SQL Database is the same SQL Server 2017 we used to love, but it is being constantly updated/patched and by the time you are reading this article, it is possible that the engine is already containing some new bits from the SQL Server vNext.
Currently you will need to use Premium Edition of the Azure SQL Database, but as Kevin Farlee mentioned at PASS Summit, there are considerations to bring the Columnstore Indexes over to the Standard Edition (S3), but the amount of the resources they consume is largely incompatible with any smaller editions currently.
I do not hold my breath, even though for the development purposes it would be nice to have a small instance (S1 maybe) handling a couple of queries with Columnstore Indexes.
Azure SQL DataWarehouse
There is only one Columnstore Index that you can create in Azure SQLDW, the Clustered Columnstore Index, which is the default one, unless that you want a Rowstore one. Being a MPP (Massive Parallel Processing) solution, Azure SQL DW is expected to provide an incredible solution at the point where Azure SQLDB can not be of effective help anymore, right ? :)
Attempting to create a Nonclustered Columnstore Index, produces the following error message, being very
Msg 104420, Level 16, State 1, Line 1 Creation of non-clustered columnstore index is not supported in PDW.
After all, we are talking about DWH – Data Warehouse scenario right ?
Final Thoughts
You can see that with every single release the priority is changing and more scenarios and features are being supported. While I would love Microsoft to spend a couple of years making full parity for every type of the Columnstore Index and every scenario a par available Rowstore features as the very basis, I do realize that it is the newer features that attracts the clients and gets you press accolades and acclamations.
I still keep the hope that the people responsible for the engine will find a fine balance between new shiny stuff, and things that clearly improve the productivity and allow easier migrations to SQL Server.
In the mean time you can use this blog post as the guiding light.
to be continued with Columnstore Indexes – part 118 (“SQL Server 2017 Editions Limitations”)