Continuation from the previous 14 parts, starting from https://www.nikoport.com/2013/07/05/clustered-columnstore-indexes-part-1-intro/
This specific post is a direct continuation of the previous one from the part 14, so the database at the moment should have the FactOnlineSales table already partitioned.
Lets see what is actually happens when we shall start updating our partitioned database, but lets check on the structure of our Row Groups at the moment, by executing the following statement:
select *
from sys.column_store_row_groups rg
where rg.object_id = object_id('FactOnlineSales')
order by rg.partition_number, rg.row_group_id;
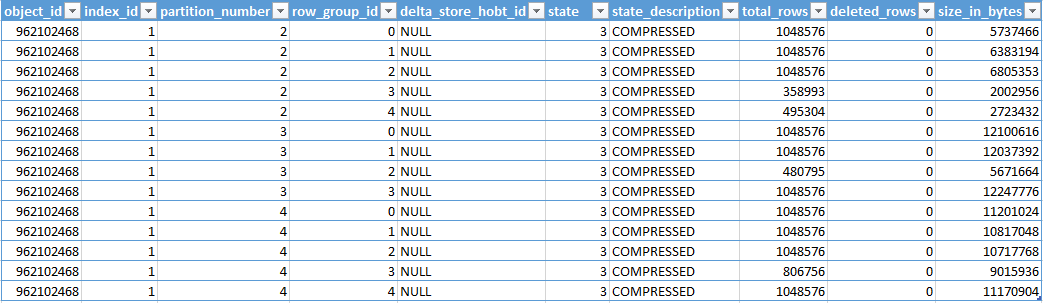 It looks like we are actively using 3 partitions with a total of 14 segments distributed over them.
It looks like we are actively using 3 partitions with a total of 14 segments distributed over them.
It is enough of the status-quo, lets update a number of rows belonging to the first partition:
update [dbo].[FactOnlineSales] set UpdateDate = GetDate() where DateKey = '2007-07-22 00:00:00.000';
 Well, now it looks like we have got a new Row Group – a new Delta-Store, which was located on the partition that we have updated. Notice, that we have also have a number of rows deleted on each of the Segments, which makes a perfect sense since as I already explained before – the update operation is actually an Insert of a new rows into the Delta-Store plus an updated of the Deleted Bitmap with marking the respective original rows as deleted. The sum of the deleted rows over the 2nd partition is exactly equals to 11113 rows inserted into a new Delta-Store, and so this way we see that the operation was executed correctly.
Well, now it looks like we have got a new Row Group – a new Delta-Store, which was located on the partition that we have updated. Notice, that we have also have a number of rows deleted on each of the Segments, which makes a perfect sense since as I already explained before – the update operation is actually an Insert of a new rows into the Delta-Store plus an updated of the Deleted Bitmap with marking the respective original rows as deleted. The sum of the deleted rows over the 2nd partition is exactly equals to 11113 rows inserted into a new Delta-Store, and so this way we see that the operation was executed correctly.
Now let us try to update a different partition for the year 2008 (partition number 3), and lets see which result it will give us:
update [dbo].[FactOnlineSales] set UpdateDate = GetDate() where DateKey = '2008-08-16 00:00:00.000';
Lets check our internals situation:  Awesome! We have updated a different partition and it has automatically created a new open Delta-Store which is local to this partition, and so now we have a situation of 2 Delta-Stores being simultaneously open for the same table.
Awesome! We have updated a different partition and it has automatically created a new open Delta-Store which is local to this partition, and so now we have a situation of 2 Delta-Stores being simultaneously open for the same table.
Note: Partitioning has a lot of potential for the applications which require a lot of updates and inserts into the Clustered Columnstore Index – if you manage to do the inserts into different partitions there will be a great potential gain of speed and avoidance of the Clustered Columnstore Locking which as already tested uses IX and X locks on the active Delta-Stores.
It looks like these simple statements are actually touching on just one partition, lets see if it works for every partition and how the execution plan does look like. Lets update the year 2009 (last partition):
update [dbo].[FactOnlineSales] set UpdateDate = GetDate() where DateKey = '2009-07-07 00:00:00.000';
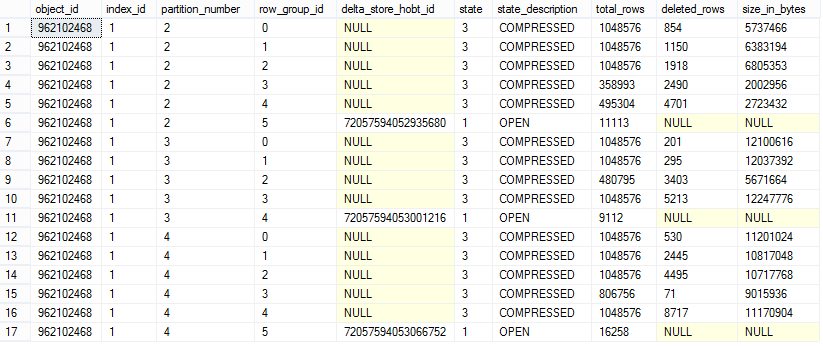 The results are as expected for the DMV’s, the new Delta-Store was created, but what about the execution statistics ?
The results are as expected for the DMV’s, the new Delta-Store was created, but what about the execution statistics ?![]() Scan count 3, logical reads 87748, physical reads 40, read-ahead reads 31660, … – well these numbers are quite big for a supposed one partition being updated, so lets take a look at the execution plan:
Scan count 3, logical reads 87748, physical reads 40, read-ahead reads 31660, … – well these numbers are quite big for a supposed one partition being updated, so lets take a look at the execution plan:

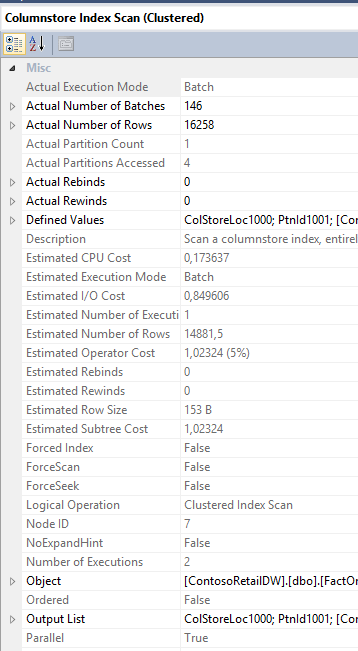 Looks fine actually :) Our partition number 4 was the only one being accessed, so those numbers should correspond to the sizes of the partition Segments. The execution mode is a Batch Mode so everything is fine here, and the operation itself is being paralleled and so the query is fine.
Looks fine actually :) Our partition number 4 was the only one being accessed, so those numbers should correspond to the sizes of the partition Segments. The execution mode is a Batch Mode so everything is fine here, and the operation itself is being paralleled and so the query is fine.
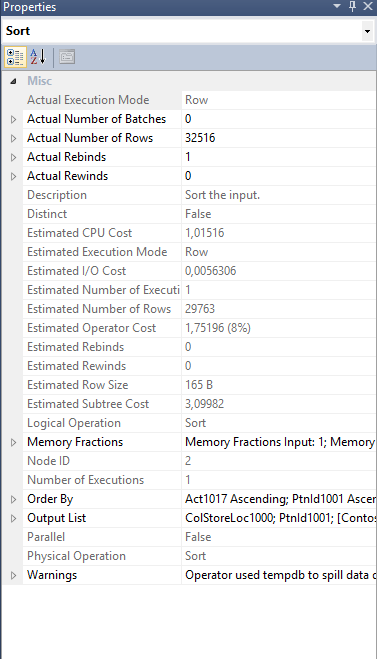 One other important mention deserves the “Sort” operator, which is being executed in the Row Mode, while Microsoft is already promoting that the Spill operation has been upgraded in SQL Server 2014 to be executed in Batch Mode. Maybe because there are just 32K rows being sorted, the batch mode decided to take a rest and only operations over 100K do Spill in Batch Mode, but I was quite disappointed to see it not being applied to the Clustered Columnstore Index update operation. Maybe this is a product of the CTP1 – I don’t know, but I will be testing this functionality in the upcoming blog posts more thoughtfully.
One other important mention deserves the “Sort” operator, which is being executed in the Row Mode, while Microsoft is already promoting that the Spill operation has been upgraded in SQL Server 2014 to be executed in Batch Mode. Maybe because there are just 32K rows being sorted, the batch mode decided to take a rest and only operations over 100K do Spill in Batch Mode, but I was quite disappointed to see it not being applied to the Clustered Columnstore Index update operation. Maybe this is a product of the CTP1 – I don’t know, but I will be testing this functionality in the upcoming blog posts more thoughtfully.
Locking escalation:
I decided to play with the Lock escalation on the Clustered Columnstore Indexes, and so I decided to update around 2/3 of the table, in the hope that this would produce enough locks to block the complete table.
Now I decided to set the escalation level explicitly to the table level:
ALTER TABLE dbo.FactOnlineSales SET (LOCK_ESCALATION = TABLE) GO
after that I have executed the following t-sql statement in a different window:
begin tran update dbo.FactOnlineSales set UpdateDate = GetDate() where DateKey < '2008-09-01'
but after updating almost 6.4 million rows this is what I have got with the following locking detection query:
-- What's being locked
SELECT dm_tran_locks.request_session_id,
dm_tran_locks.resource_database_id,
DB_NAME(dm_tran_locks.resource_database_id) AS dbname,
CASE
WHEN resource_type = 'object'
THEN OBJECT_NAME(dm_tran_locks.resource_associated_entity_id)
ELSE OBJECT_NAME(partitions.OBJECT_ID)
END AS ObjectName,
partitions.index_id,
indexes.name AS index_name,
dm_tran_locks.resource_type,
dm_tran_locks.resource_description,
dm_tran_locks.resource_associated_entity_id,
dm_tran_locks.request_mode,
dm_tran_locks.request_status
FROM sys.dm_tran_locks
LEFT JOIN sys.partitions ON partitions.hobt_id = dm_tran_locks.resource_associated_entity_id
JOIN sys.indexes ON indexes.OBJECT_ID = partitions.OBJECT_ID AND indexes.index_id = partitions.index_id
WHERE resource_associated_entity_id > 0
AND resource_database_id = DB_ID()
ORDER BY request_session_id, resource_associated_entity_id
 If you notice a big number of Row Groups being locked, it's because some of them were created during update operation, while others were actually the product of several Update & Rollback attempts. Also, the Row Groups which have an U (Update Lock), are actually empty (no rows and they are marked at the OPEN state).
If you notice a big number of Row Groups being locked, it's because some of them were created during update operation, while others were actually the product of several Update & Rollback attempts. Also, the Row Groups which have an U (Update Lock), are actually empty (no rows and they are marked at the OPEN state).
Don't forget to rollback the transaction after the all requests were done. :)
Now I decided to set the escalation level explicitly to the partition (Auto) level:
ALTER TABLE dbo.FactOnlineSales SET (LOCK_ESCALATION = AUTO) GO
In a new window lets do the same update on our table:
begin tran update dbo.FactOnlineSales set UpdateDate = GetDate() where DateKey < '2008-09-01'
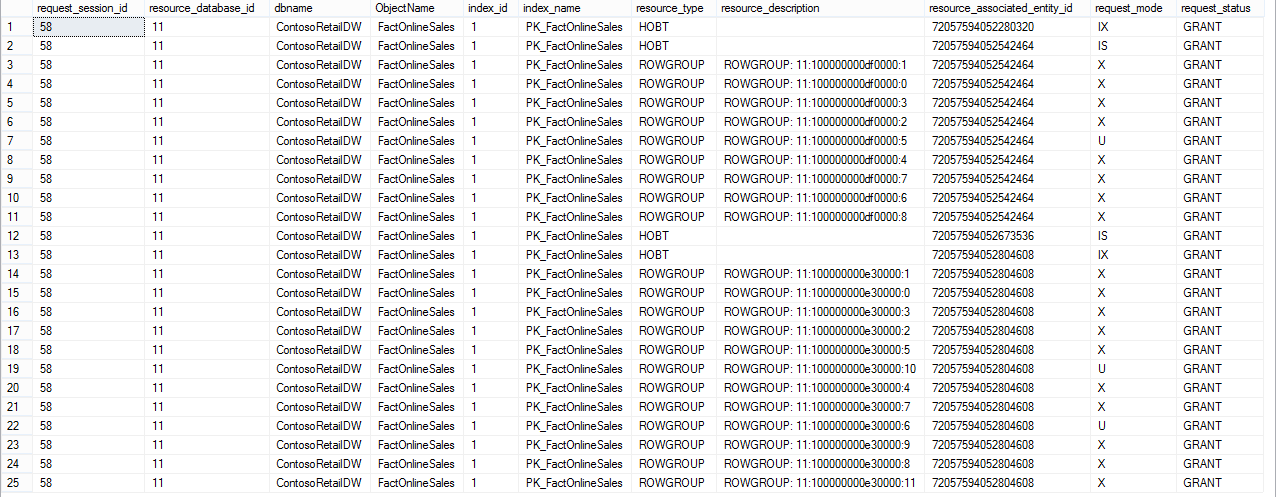
In this case we observe a different behavior: we still have our Row Groups U (Update) and X (Exclusive) locks, but we also have an IX (Intent Exclusive) lock on row of our partitions (that we update completely, but note that partition 1 has no row at the moment), an IS (Intend Shared) lock on the partition we are updating a certain percentage of rows, and IX (Intent Exclusive) lock on the 4th partition which will not be updated at all.
Here comes the image showing the results of the content of the row groups, which were created as the result of this blog post - every time we update the segments - new Delta-Stores are being created, and since we execute rollback on our transactions, the Row Groups stay open until Tuple Mover should recycle them. Note: I have noticed a lot of times it does not happen correctly, but I think that it should be corrected before RTM.

Anyway I decided to correct this situation myself by invoking the following T-SQL on our Clustered Columnstore Index:
alter index PK_FactOnlineSales on [FactOnlineSales] REBUILD
It seems that the partition level lock escalation works, though its functionality in a TABLE mode gets more granular locking, then the one on the PARTITION level. I would have expected it to be functioning otherwise, but lets wait until CTP2 before coming to any conclusions.
to be continued with Clustered Columnstore Indexes - part 16 ("Index Builds")
Pingback: Clustered Columnstore Indexes – part 1 (“Intro”) | Nikoport