Continuation from the previous 90 parts, the whole series can be found at https://www.nikoport.com/columnstore/.
Given the improvements and the availability of the of the programability surface for every edition (with some insignificant & logical limitations) that I have blogged about in
SQL Server 2016 SP1 – Programmability Surface for everyone!, I believe everyone using Microsoft Data Platform has rejoyced greatly. Of course, now everyone can have Columnstore Indexes on every SQL Server edition!
There are some noticeable limitations that were announced right from the start, such as the maximum size of the Columnstore Object Pool (you can find more information about it here – Columnstore Indexes – part 38 (“Memory Structures”)), but there are more limitations to the Standard Editions and inferior ones and it is extremely important to know them, to understand them in order to make the right decision – when your Business is ready/needed to upgrade to the Enterprise Edition of the SQL Server.
I have run a number of possible tests against freshly restored Standard Edition of SQL Server 2016 with Service Pack 1 and these are a number of items that I have found to be functioning differently in comparison to the Enterprise Edition of SQL Server 2016 Service Pack1, and this blog post will go through them.
First of all there is a limitation on the Columnstore Object Pool size with 32 GB, which should not be the biggest problem in the real world, because you can still run your queries against TB-big tables, you will simply not being able to keep them inside your memory all the time.
For the rest of the discoveries, we shall better run some queries and for that I have set up an 8-core Virtual Machine in Azure with a Standard Edition of SQL Server 2016 Service Pack 1:
![]()
For the setup I will use my favourite ContosoRetailDW free database and the traditional script to restore the database, drop the Primary Clustered Key from the FactOnlineSales table and to create a Clustered Columnstore Index on it:
USE [master]
alter database ContosoRetailDW
set SINGLE_USER WITH ROLLBACK IMMEDIATE;
RESTORE DATABASE [ContosoRetailDW]
FROM DISK = N'C:\Install\ContosoRetailDW.bak' WITH FILE = 1,
MOVE N'ContosoRetailDW2.0' TO N'C:\Data\ContosoRetailDW.mdf',
MOVE N'ContosoRetailDW2.0_log' TO N'C:\Data\ContosoRetailDW.ldf',
NOUNLOAD, STATS = 5;
alter database ContosoRetailDW
set MULTI_USER;
GO
ALTER DATABASE [ContosoRetailDW] SET COMPATIBILITY_LEVEL = 130
GO
ALTER DATABASE [ContosoRetailDW] MODIFY FILE ( NAME = N'ContosoRetailDW2.0', SIZE = 2000000KB , FILEGROWTH = 128000KB )
GO
ALTER DATABASE [ContosoRetailDW] MODIFY FILE ( NAME = N'ContosoRetailDW2.0_log', SIZE = 400000KB , FILEGROWTH = 256000KB )
GO
use ContosoRetailDW;
-- Drop the Primary Key from the FactOnlineSales table
ALTER TABLE dbo.[FactOnlineSales] DROP CONSTRAINT [PK_FactOnlineSales_SalesKey];
-- Create Clustered Columnstreo Index on the FactOnlineSales table
create clustered columnstore Index PK_FactOnlineSales
on dbo.FactOnlineSales;
Now, let’s run a couple of queries against our Columnstore Table to see what is functioning differently, when compared to the Enterprise Edition, but before that to make sure I obtain the parallelism easily without torturing Query Optimiser and making the understanding of the article more easy – I have configured a couple of settings for my SQL Server Instance (PLEASE DO NOT DO THIS ON THE PRODUCTION INSTANCE!)
 Besides the Max Threshold for Parallelism set to 1, Maximum Degree Of Parallelism set to 8, I have set a whole set of the options through DSC (Desired State Configuration) that we typically apply on the Windows Servers that running SQL Server (including max server memory, IFI, etc).
Besides the Max Threshold for Parallelism set to 1, Maximum Degree Of Parallelism set to 8, I have set a whole set of the options through DSC (Desired State Configuration) that we typically apply on the Windows Servers that running SQL Server (including max server memory, IFI, etc).
Let’s advance and execute a simple query that will be forced to run in parallel, to check if it is running with Batch Execution Mode and if everything corresponds to the typical processing of the Enterprise Edition:
set statistics time, io on select sum(SalesQuantity * UnitPrice ) from dbo.FactOnlineSales
If we look at the execution plan of our query, it looks quite expectable – running in paralleled doing all the task one would expect it to do:

But should we take a look at the properties of the Columnstore Index scan, there are a couple of very interesting details to uncover:
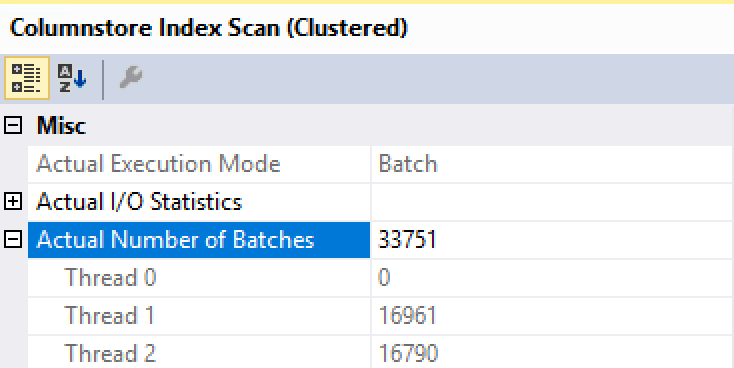 First of all the Columnstore Index Scan runs with Batch Execution Mode, and that should make everyone very happy (there has never been a Batch Mode on the Standard Edition of SQL Server before 2016 with Service Pack 1), but take a more detailed look at the Actual Number of Batches – it shows that there are only 2 cores doing the work instead of 8 that I have configured for the SQL Server instance and I would expect to function in the Enterprise Edition of the SQL Server.
First of all the Columnstore Index Scan runs with Batch Execution Mode, and that should make everyone very happy (there has never been a Batch Mode on the Standard Edition of SQL Server before 2016 with Service Pack 1), but take a more detailed look at the Actual Number of Batches – it shows that there are only 2 cores doing the work instead of 8 that I have configured for the SQL Server instance and I would expect to function in the Enterprise Edition of the SQL Server.
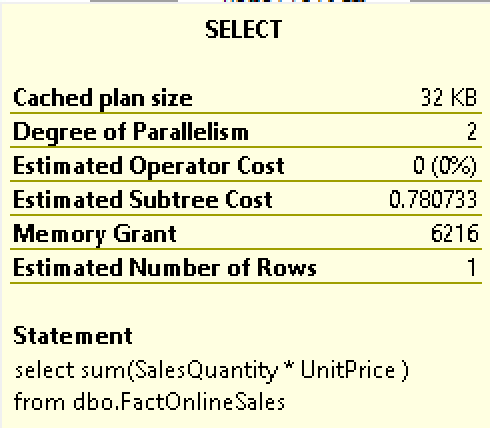 Taking a more detailed look at the properties of the query, shows that indeed the used degree of the parallelism is capped to 2, even though when looking into the XML of the execution plan reveals EstimatedAvailableDegreeOfParallelism = “4”.
Taking a more detailed look at the properties of the query, shows that indeed the used degree of the parallelism is capped to 2, even though when looking into the XML of the execution plan reveals EstimatedAvailableDegreeOfParallelism = “4”.
This is definitely a cap of the Standard Edition, that will prevent your Columnstore Queries that run with Batch Execution Mode to use more than 2 Cores in Parallel. Should your queries run in the Row Execution Mode, all of the configured CPU Cores will be potentially used for processing.
Also notice, I can easily run 4 parallel queries for my SQL Server Instance – thus using the potential of my SQL Server Instance to the maximum. Notice that for the Web & Express Edition, the limitation will be stronger, making queries to run in Batch Mode in Single-Threaded fashion only.
This is not the totally unexpected limitation of the Standard Edition, but one should be aware that it exists.
Let’s run another query, trying to see if the aggregate pushdown works correctly (for more information on Aggregate Pushdown, please consult the following article Columnstore Indexes – part 59 (“Aggregate Pushdown”)):
set statistics time, io on
select max(SalesQuantity)
from dbo.FactOnlineSales;
The execution time on my VM was very fast, making the total elapsed time to be just 63 ms, but if you look at the execution plan, you will get a little bit surprised, since it shows no aggregate pushdown taking place:

In Enterprise Edition the functioning Aggregate Pushdown looks in the following way in the execution plan, where no rows are coming of the Columnstore Index Scan:

This means that Aggregate Pushdown is disabled for the Non-Enterprise Editions of SQL Server and that’s a pity, but still your workloads on Standard Edition will function extremely fast and in my test for this simple query the difference was just around 2 times (it takes around 30 ms to run this query on the Enterprise Edition of the SQL Server 2016 with Service Pack 1).
Another interesting scenario that was enabled in SQL Server 2016 were String Predicate Pushdown. As you know, for the long time Strings have been probably the only data type that was largely ignored for the performance improvements, mostly because of its complexity – I believe. Let’s see if another improvement that requires 130 compatibility level is functioning on the Standard Edition of SQL Server 2016 with Service Pack 1.
Let’s run a simple test query:
select sum(SalesAmount), sum(SalesAmount) - sum(SalesAmount*prom.DiscountPercent) from dbo.FactOnlineSales sales inner join dbo.DimPromotion prom on sales.PromotionKey = prom.PromotionKey where SalesOrderNumber like N'2008%' and SalesOrderNumber not like N'%000'
Looking at its execution plan, you will notice that there is a Filter iterator, outside of the Clustered Columnstore Index Scan:
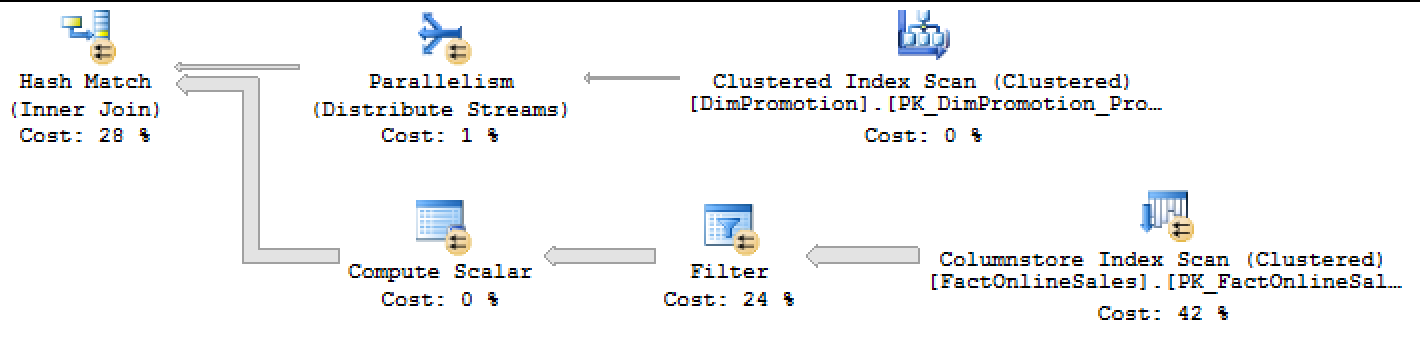
This filter iterator is our string predicate, which has not been pushed down to the Storage Engine for faster elimination, costing us effectively some of the IO and the CPU Cycles for filtering out the results at the later stage.
For comparison, you can see below the part of the execution plan on the enterprise edition where the predicate is a part of the Columnstore Index Scan:
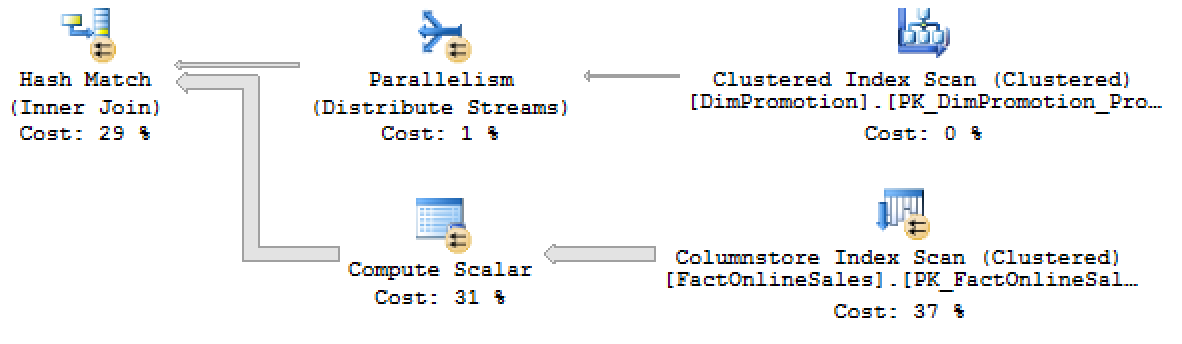
This is another SQL Server 2016 top engine addition and unfortunately the Standard Edition will not have this feature. The solution for this case is to use non-string data types, as you would typically try to do for a Data Warehousing System.
I love the fact that there is a space for optimisations in Standard Edition and this will drive better and more optimised database designs hopefully.
Local Aggregations – similar logic like with Aggregation & String Predicate Pushdowns, the local aggregations looks simply to not exist at all at the Storage Engine level.
If we ran a rather simple aggregation query against our FactOnlineSales table:
select sales.ProductKey, sum(sales.SalesQuantity) from dbo.FactOnlineSales sales group by sales.ProductKey;
we shall notice on the actual number of rows passing from Columnstore Index Scan to the Hash Match iterator is equals to the total number of rows in the table (12.627.600):
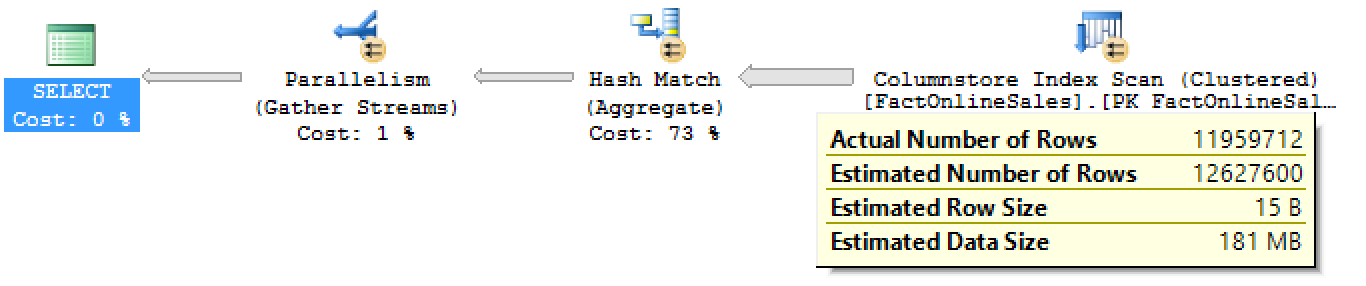
while at the same query running on the Enterprise Edition of SQL Server 2016 with Service Pack 1 shows 11.959.712 rows passing from Columnstore Index Scan to the Hash Match iterator (and notice that the total number of rows is still the same – 12.627.600):
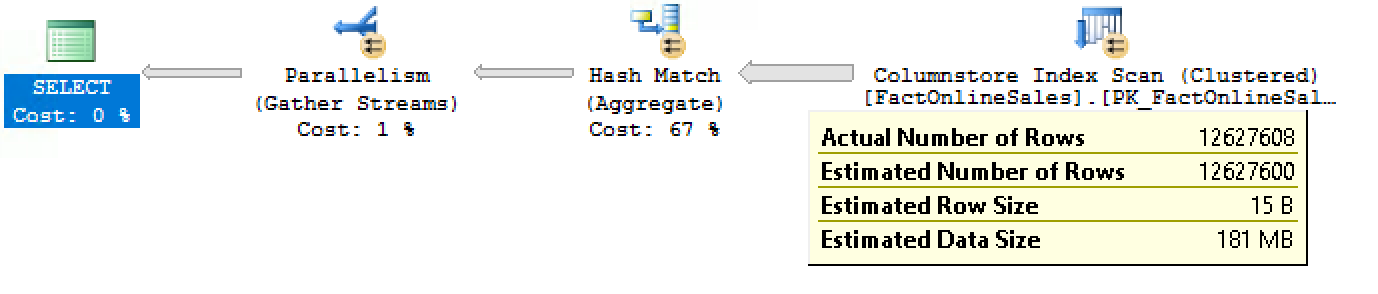
Looking at the properties of the iterators at the execution plan in Standard Edition, you will not find any reference of the Local Aggregation and looking inside the XML of the Execution plan will not allow you to find the references for the “ActualLocallyAggregatedRows” attribute.
I guess this feature follows the same line as all aggregation operation that are simply not supported for the SQL Server Standard Edition an that’s fine with me.
Index Rebuild – from what I have seen so far, the Rebuild operation is capped by single-thread in the Standard Editon for the Columnstore Indexes.
Let’s run a Rebuild operation on our table:
alter index [PK_FactOnlineSales] on dbo.FactOnlineSales rebuild;
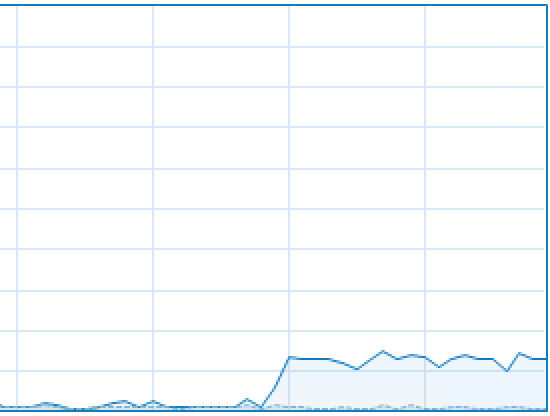 Looking at the Task Manager will show you that just 1 core out of the 8 available for the Virtual Machine is being used for the process, and no – this is definitely not a Dictionary sampling and creation process, since it will stay like this for the duration of whole process.
Looking at the Task Manager will show you that just 1 core out of the 8 available for the Virtual Machine is being used for the process, and no – this is definitely not a Dictionary sampling and creation process, since it will stay like this for the duration of whole process.
Taking a more detailed look at the execution plan will reveal that it was executed with a single thread:

Below this text you will find the execution plan for the Enterprise Editon of the SQL Server 2016 with Service Pack 1, showing that the rebuild operation is being simply throttled for the Standard Edition.
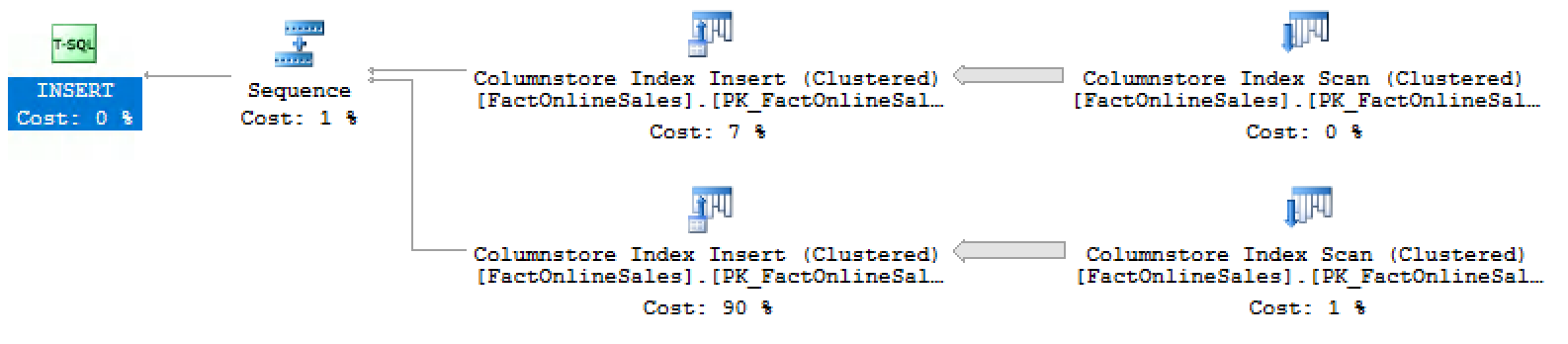
This is another performance cap for the Standard Edition, and this one will have a definitive impact on the overall performance of the SQL Server, and my advice here would fall back to the Partitioning – you can run multiple operations on the same index, but on different partitions – thus actually having a potential performance gain when compared to the single rebuild of the table without partitions.
SIMD Optimisations Support – Single Instruction Multiple Data optimisation allows hardware accelerations for processing multiple data rows within a single instruction operation. In the near future, I will do a whole blog post dedicated to the impact of this optimisation, but for now you should notice that Standard Edition does not support SIMD.
From my point of view, this is a feature, similar to Large Pages (Trace Flag 834) which is supported on the Enterprise Edition only – this is a definitively a performance improvement and not a programability feature.
Here comes the current recap of the limitations:
– Columnstore Object Pool = 32 GB
– MAXDOP = 2 (for Standard Edition) and 1 (for all other editions)
– Aggregate Pushdown = NO
– String Predicate Pushdown = NO
– Local Aggregation = NO
– Index Build/Rebuild = Limited to 1 Core
– SIMD Support – NO
I have no doubt that there are a couple more limitations that I was not able to identify easily, but I expect them to become known in the next years and I will get back to this blog post, updating it with more current information.
to be continued with Columnstore Indexes – part 92 (“Lobs”)
Microsoft just want customer to taste the water!
Well, they invited us to a beautiful data lake. :)
And I am very motivated with swimming ;)
Nice article,
How about SQL Server 2017 Standard about this limitation ?
and How about SQL Server 2017 Express, too ?
Now, I test SQL Server 2017 Express with columnstore and 100M rows.
Hi Yoshihiro,
I expect no general changes in SQL Server 2017, just some of the enterprise performance features are kept off the Standard & Express editions.
Best regards,
Niko Neugebauer
We are eagerly waiting for SIMD article pls
Hi Manish,
It should be out until the end of this year.
Best regards,
Niko
Hi Nico,
You mentioned Partitioning as a way to get around when rebuilding as it uses a single thread. I noticed on microsoft’s features list by edition page that parallelism partitioning is not supported in 2016 and that would potentially reduce the query performance in reporting. Would you be able to test this scenario if not already? Love your amount of work on these articles and I havent got to the end of it yet. :)
Hi Ajai,
thank you for the kind words.
Parallelism you are mentioning is the one that touches on the query processing and not rebuild process. The standard edition will be capped with 2 cores for Columnstore Indexes rebuild as per documentation as well as my tests.
You can use the values by default and you will get a reasonably small skew, and that means if you want the perfect alignment you will need to force MAXDOP = 1.
Best regards,
Niko