Continuation from the previous 89 parts, the whole series can be found at https://www.nikoport.com/columnstore/.
This blog post is focusing on a very important improvement to the limitation of the In-Memory Columnstore Indexes that was existing in SQL Server 2016, but was solved in the Service Pack 1 – the possibility to add the Columnstore Indexes to the Memory-Optimised table as fast as the other indexes, be it Hash or Nonclustered BW-Tree index.
In Columnstore Indexes – part 81 (“Adding Columnstore Index to InMemory Tables”) I have shown that while adding a Nonclustered Index to Memory-Optimised table, it takes a very short amount of time compared to adding the Clustered Columnstore Index
and in Columnstore Indexes – part 89 (“Memory-Optimised Columnstore Limitations 2016”), I have shown the impact to the persistent storage after adding Columnstore Index, which is doubling the occupied space of the original table, while the Nonclustered Indexes (Hash or BW-Tree) would simply add a couple of MB most probably reflecting the meta-information overhead.
With an incredible Service Pack 1 Microsoft has triumphantly announced that all editions (Standard, Web, Express and even Local) will get the most advanced programming capabilities of Columnstore, In-Memory, Database Snapshot, Compression, Partition & many others, plus that there are some incredible features for the T-SQL (CREATE OR ALTER) and Execution Plan details (Actual Information on processed Rows, used Trace Flags, etc),
but at the same time there are some quite important improvement under the hood that will make you want to use Service Pack 1 for SQL Server 2016 immediately. One of this features is the fast addition of the Columnstore Index to the Memory-Optimised tables. Let take it to the test by restoring a copy of the ContosoRetailDW free database:
USE master;
alter database ContosoRetailDW
set SINGLE_USER WITH ROLLBACK IMMEDIATE;
RESTORE DATABASE [ContosoRetailDW]
FROM DISK = N'C:\Install\ContosoRetailDW.bak' WITH FILE = 1,
MOVE N'ContosoRetailDW2.0' TO N'C:\Data\SQL16\ContosoRetailDW.mdf',
MOVE N'ContosoRetailDW2.0_log' TO N'C:\Data\SQL16\ContosoRetailDW.ldf',
NOUNLOAD, STATS = 5;
alter database ContosoRetailDW
set MULTI_USER;
GO
Use ContosoRetailDW;
GO
ALTER DATABASE [ContosoRetailDW] SET COMPATIBILITY_LEVEL = 130
GO
ALTER DATABASE [ContosoRetailDW] MODIFY FILE ( NAME = N'ContosoRetailDW2.0', SIZE = 2000000KB , FILEGROWTH = 128000KB )
GO
ALTER DATABASE [ContosoRetailDW] MODIFY FILE ( NAME = N'ContosoRetailDW2.0_log', SIZE = 400000KB , FILEGROWTH = 256000KB )
GO
Do not forget to set the compatibility level to 130, otherwise you will be missing enough important features that require it. Now, let’s add a Memory-Optimised Filegroup to our database:
ALTER DATABASE [ContosoRetailDW] ADD FILEGROUP [ContosoRetailDW_Hekaton] CONTAINS MEMORY_OPTIMIZED_DATA GO ALTER DATABASE [ContosoRetailDW] ADD FILE(NAME = ContosoRetailDW_HekatonDir, FILENAME = 'C:\Data\SQL16\ContosoXtp') TO FILEGROUP [ContosoRetailDW_Hekaton];
For the test, I will use an empty Memory-Optimised table where I shall load 2 million rows from the original FactOnlineSales table.
CREATE TABLE [dbo].[FactOnlineSales_Hekaton]( [OnlineSalesKey] [int] NOT NULL, [DateKey] [datetime] NOT NULL, [StoreKey] [int] NOT NULL, [ProductKey] [int] NOT NULL, [PromotionKey] [int] NOT NULL, [CurrencyKey] [int] NOT NULL, [CustomerKey] [int] NOT NULL, [SalesOrderNumber] [nvarchar](20) NOT NULL, [SalesOrderLineNumber] [int] NULL, [SalesQuantity] [int] NOT NULL, [SalesAmount] [money] NOT NULL, [ReturnQuantity] [int] NOT NULL, [ReturnAmount] [money] NULL, [DiscountQuantity] [int] NULL, [DiscountAmount] [money] NULL, [TotalCost] [money] NOT NULL, [UnitCost] [money] NULL, [UnitPrice] [money] NULL, [ETLLoadID] [int] NULL, [LoadDate] [datetime] NULL, [UpdateDate] [datetime] NULL, Constraint PK_FactOnlineSales_Hekaton PRIMARY KEY NONCLUSTERED HASH ([OnlineSalesKey]) WITH (BUCKET_COUNT = 2000000) ) WITH (MEMORY_OPTIMIZED = ON, DURABILITY = SCHEMA_AND_DATA); insert into dbo.FactOnlineSales_Hekaton select top 2000000 * from dbo.FactOnlineSales; CHECKPOINT;
Checking on the file System directly one can see the checkpoint files added with around 450 MB of occupied space, which looks exactly like the results for the SQL Server 2016 RTM tests that I did previously:
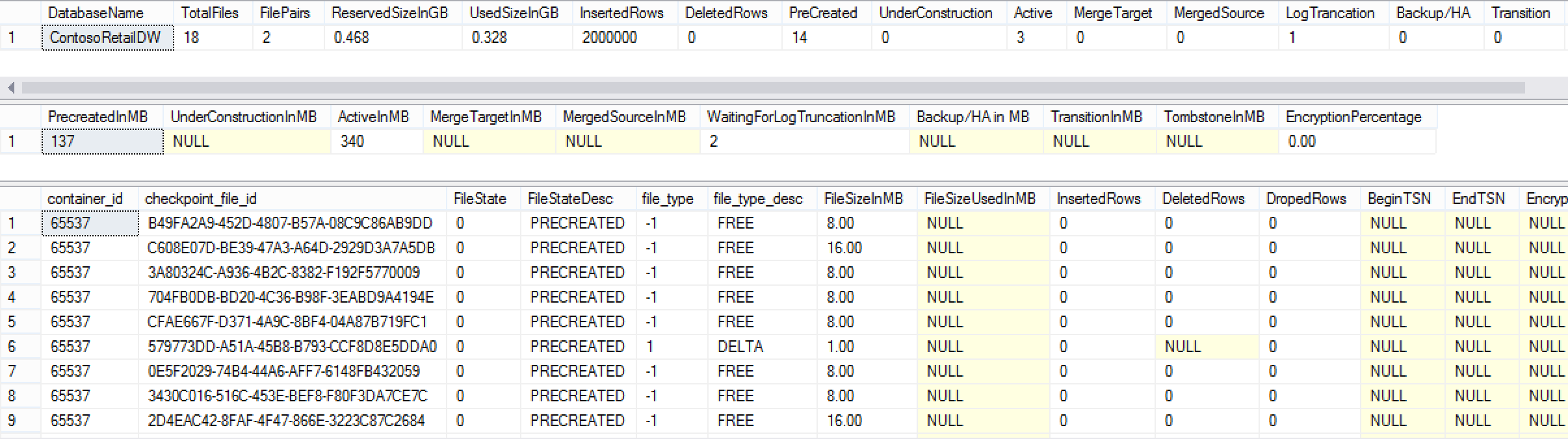
Using the MOSL, let’s see the detailed information on the Checkpoint Files after the initial load of 2 million rows: here we can confirm that everything is still the same:
exec dbo.memopt_GetCheckpointFiles;
Now let’s test the addition of the Columnstore Index to our Memory-Optimised table:
set statistics time, io on alter table dbo.FactOnlineSales_Hekaton add INDEX NCCI_FactOnlineSales_Hekaton CLUSTERED COLUMNSTORE;
You gotta put your cup of coffee down, before looking at the results: 218 ms of the CPU time and the total elapsed time was just 2064 ms ! The total elapsed time simply went down from over 7 seconds down to just 2 second! Regarding the used CPU time there is a huge difference with the original RTM CPU time being around 4.1 seconds vs 0.2 seconds in the Service Pack 1.
Incredible! That is one amazing addition in “just a Service Pack”!
What about the Checkpoint Files and their impact on the disk:
exec dbo.memopt_GetCheckpointFiles;
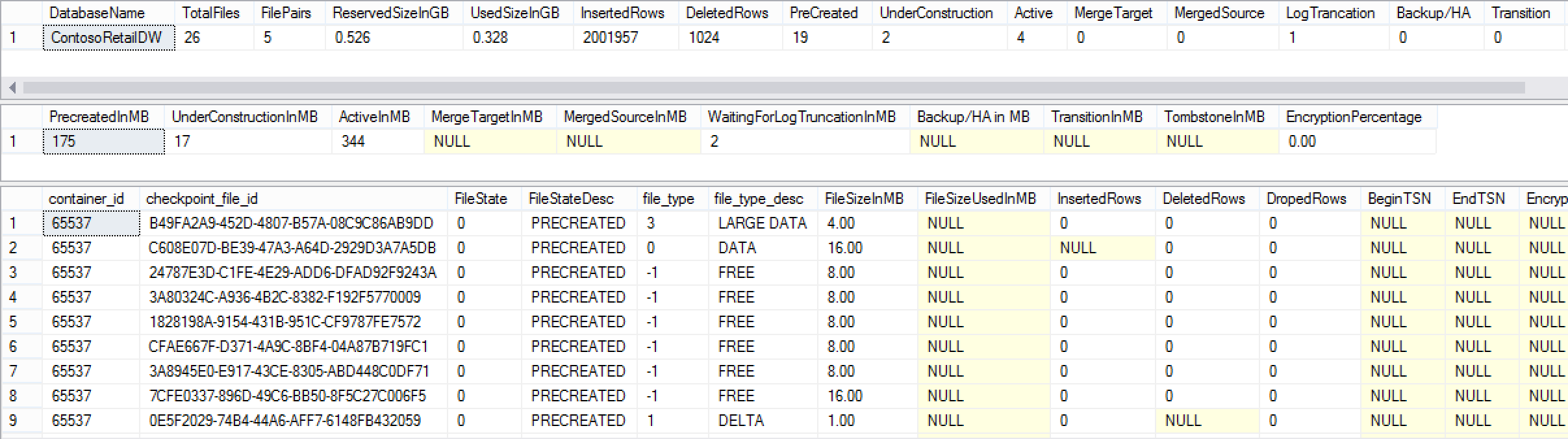
Here we can see the the total size of the reserved space went from 476 MB to 526 MB, meaning that we have increased 50 MB in total, but the used space was kept intact on 328 MB in comparison to the RTM version where the 672 MB of the space were used. The difference here is huge with 0 MB vs 340 MB, justifying the impact of the operation speed.
What about the changes for Nonclustered Hash Indexes? Are there any ?
Let’s test the addition of the Nonclustered Hash Index to a Memory-Optimised table, but notice that for doing a fair comparison, all previous scripts besides Columnstore index addition should be re-executed again.
set statistics time, io on alter table dbo.FactOnlineSales_Hekaton add INDEX NCCI_FactOnlineSales_Hekaton NONCLUSTERED HASH (OnlineSalesKey, DateKey, StoreKey, ProductKey, PromotionKey, CurrencyKey, CustomerKey, SalesOrderNumber, SalesOrderLineNumber, SalesQuantity, SalesAmount, ReturnQuantity, ReturnAmount, DiscountQuantity, DiscountAmount, TotalCost, UnitCost, UnitPrice, ETLLoadID, LoadDate, UpdateDate) WITH (BUCKET_COUNT = 2000000);
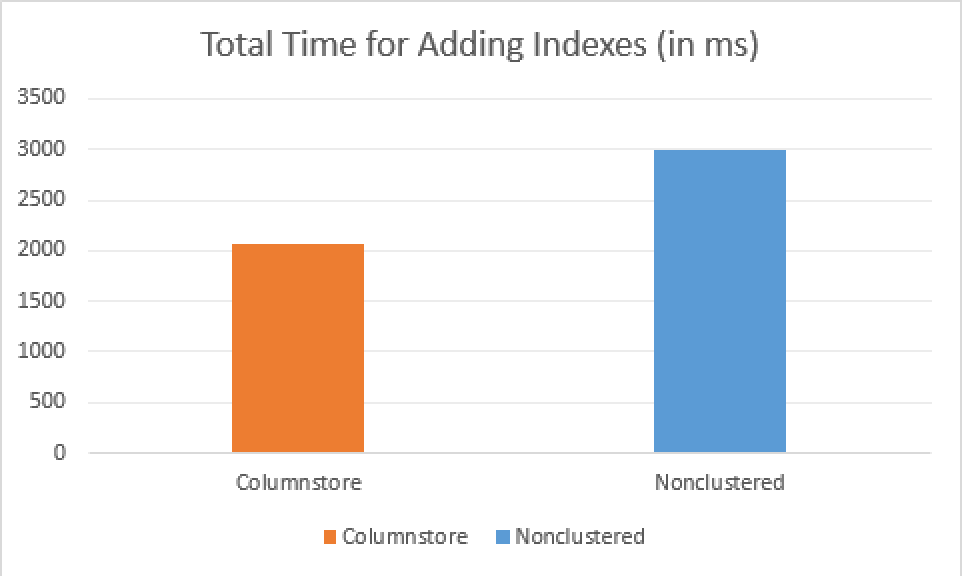 The execution time was the same as for the RTM version of SQL Server 2016 – 2990 ms, while the CPU spent time was 3060 ms.
The execution time was the same as for the RTM version of SQL Server 2016 – 2990 ms, while the CPU spent time was 3060 ms.
This means that adding a Columnstore Index runs faster than adding a Nonclustered Hash Index, because we have 2 seconds for the Columnstore Index addition while having 3 seconds for Nonclustered Hash Index addition!
That is quite a reversal of the fortune, when comparing to the RTM version!
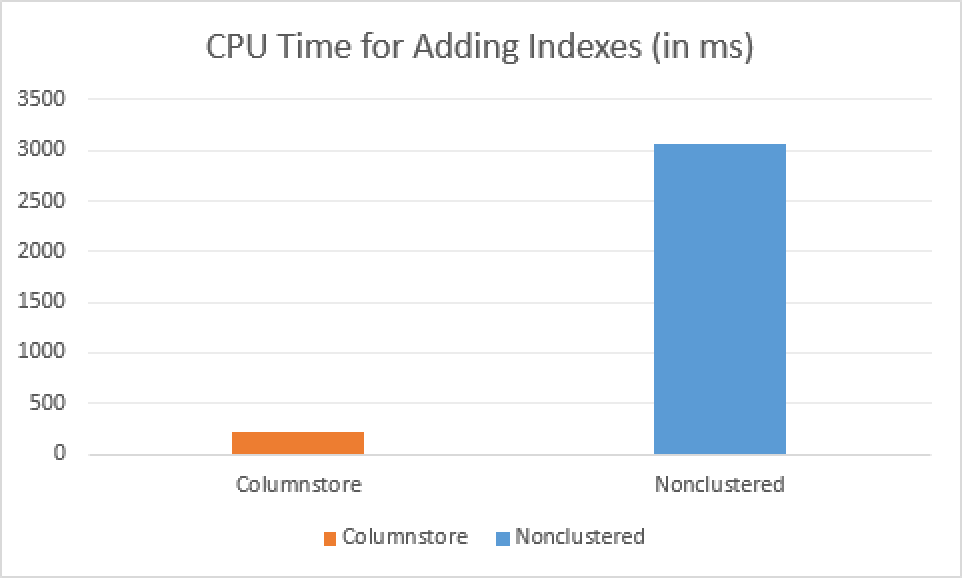 The amount of CPU time spent on the addition of the indexes has suffered a very significant change as well – it takes just 0.2 seconds of the CPU time to add a Columnstore Index while it takes a good 3 seconds to add a Nonclustered Hash Index to a Memory-Optimised Table.
The amount of CPU time spent on the addition of the indexes has suffered a very significant change as well – it takes just 0.2 seconds of the CPU time to add a Columnstore Index while it takes a good 3 seconds to add a Nonclustered Hash Index to a Memory-Optimised Table.
Additional note comes here on the addition of the Nonclustered BW-Tree Index, which spends 4.1 seconds on the total execution, while spending 3.2 of the CPU time – time making the worst time when compared with all other indexes.
From the Checkpoint File perspective we can observe a stable :
exec dbo.memopt_GetCheckpointFiles;
This time we have just received 16 MB of the reserved space and nothing from the point of view of the occupied space.
Another interesting area for the investigation is the addition of the 1957 rows while adding a Columnstore Index while nothing changes when adding a Hash Index. I will be writing on this matter in the near future.
Transaction Log
I have also done some transaction log measurements for the impact on the transaction log with the help of the following statement:
select count(*), sum([log record length]) from fn_dblog(null, null);
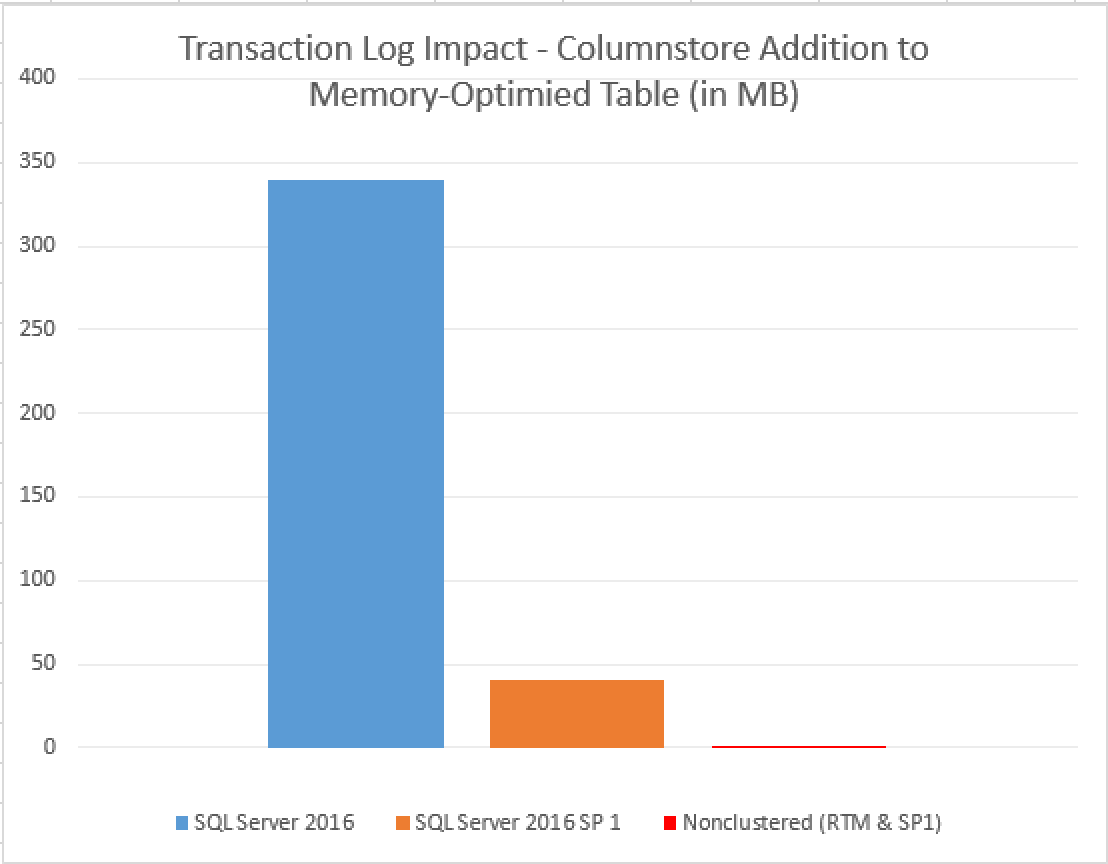
The impact on the transaction log when adding Columnstore Indexes continued to be quite significant, but in comparison of the SQL Server 2016 RTM version where it took 380 MB, in the Service Pack 1 the total impact on the transactional log went down to just 41 MB!
Comparing to the addition of the Nonclustered Hash Index still can’t be truly done, since it is just around 260 KB (yes, Kilobytes) that transaction log receives after this operation, we are talking about difference in around 160 times.
Final Thoughts
We can observe a truly great improvement with Columnstore Indexes in the Service Pack 1 and it is just another reason for upgrading to it, even if you are running SQL Server 2016 RTM.
The next natural step will be guaranteeing that addition of the all indexes to Memory-Optimised table takes place online, in order to keep the business running without any interruption.
Another aspect to keep on improving will be the transaction log – the improvements in Service Pack 1 are great but there is still enough room for the improvement.
to be continued with Columnstore Indexes – part 91 (“SQL Server 2016 Standard Edition Limitations”)
So it means in Sp1 we can add has indexes after columnstore index.
Earlier in blog in RTM version t was throwing error while adding hash index after columnstore index
Thank you
Hi Manish,
even in SQL Server 2017 when you are using In-Memory table with Columnstore Index, you can not add or remove indexes, unless you remove the Columnstore Index.
Best regards,
Niko