Continuation from the previous 37 parts, starting from https://www.nikoport.com/2013/07/05/clustered-columnstore-indexes-part-1-intro/
In the past I have been writing quite a lot on the matter of the Columnstore structures and their performance, and so it’s definitely time to make some explanations of what is going on within a SQL Server memory once we are using Clustered Columnstore Indexes.
First of all, it is important to understand that ever since SQL Server 2012 that had introduced Nonclustered Columnstore Indexes, there have been massive changes to the internal memory structures, and once working with Columsntore we are not using Buffer Pool exclusively.
Columnstore Object Pool
Since SQL Server 2012, we have a special space in memory (Cache Store) reserved for the Columnstore Indexes (Clustered & Nonclustered) and it’s name is Columnstore Object Pool. This Cache Store is located outside of the Buffer Pool and it receives new 8k Memory Pages from any-page allocator, such as Buffer Pool itself. The only interesting parts of the Columnstore Indexes for Columnstore Object Pool are the compressed segments, and all other structures such as Delta-Stores and Deleted Bitmaps to my understanding are located in the good old Buffer Pool.
Columnstore Object Pool uses Large Pages stored sequentially for allocation. In practice Large Pages allocation allows to allocate space in chunks from 2MB to 16MB instead of just 4KB.
Internals
I understand that at the moment when we are reading Columnstore data from the disk, it is being read directly into Columnstore Object Pool without decompression, and then all the respective pages from the Segments are decompressed into Buffer Pool for returning the result. And so we are basically dealing with 2 copies of Columnstore data at the same time – one is compressed in the Columnstore Object Pool and the other one is decompressed version of it in the Buffer Pool.
If we are trying to read the Segments which are already contained in Columnstore Object Pool, then we should simply read the decompressed information from the Buffer Pool (should the respective page being purged from Buffer Pool it is immediately read back into Buffer Pool), but in the case when we are accessing new Segments which are not contained in Columnstore Object Pool yet, then we are getting them from the disk and decompressing into Buffer Pool before returning information.
It is important to understand that Columnstore Object Pool and Buffer Pool essentially are looking to get memory pages from the same source, and that they are “fighting” for the same resources which means that in the cases when we do not have enough memory, we shall be dealing with memory pressure issues.
The amount of memory allocated to the Columnstore Object Pool is tracked by the new Memory Clerk – CACHESTORE_COLUMNSTOREOBJECTPOOL.
Also, we have a brand new DMV since SQL Server 2012 – sys.dm_os_memory_broker_clerks, undocumented as you would expected. :) This DMV delivers information about principal memory consumers in our SQL Server instance.
Since Columnstore Indexes are not NUMA aware and I do not expect this to change soon, because I do not believe that the effort put into it will meet the bar of the price/improvement at Microsoft. Which is a pity.
Showcase
I shall be using Contoso Retail DW database for the showcase.
Let’s kick off with a usual procedure of restoring the database, dropping all Primary & Foreign Keys and creating 4 Clustered Columnstore Indexes on our principal Fact Tables:
USE [master] alter database ContosoRetailDW set SINGLE_USER WITH ROLLBACK IMMEDIATE; RESTORE DATABASE [ContosoRetailDW] FROM DISK = N'C:\Install\ContosoRetailDW.bak' WITH FILE = 1, MOVE N'ContosoRetailDW2.0' TO N'C:\Data\ContosoRetailDW.mdf', MOVE N'ContosoRetailDW2.0_log' TO N'C:\Data\ContosoRetailDW.ldf', NOUNLOAD, STATS = 5; alter database ContosoRetailDW set MULTI_USER; GO use ContosoRetailDW; alter table dbo.[FactOnlineSales] DROP CONSTRAINT PK_FactOnlineSales_SalesKey alter table dbo.[FactStrategyPlan] DROP CONSTRAINT PK_FactStrategyPlan_StrategyPlanKey alter table dbo.[FactSales] DROP CONSTRAINT PK_FactSales_SalesKey alter table dbo.[FactInventory] DROP CONSTRAINT PK_FactInventory_InventoryKey alter table dbo.[FactSalesQuota] DROP CONSTRAINT PK_FactSalesQuota_SalesQuotaKey alter table dbo.[FactOnlineSales] DROP CONSTRAINT FK_FactOnlineSales_DimCurrency alter table dbo.[FactOnlineSales] DROP CONSTRAINT FK_FactOnlineSales_DimCustomer alter table dbo.[FactOnlineSales] DROP CONSTRAINT FK_FactOnlineSales_DimDate alter table dbo.[FactOnlineSales] DROP CONSTRAINT FK_FactOnlineSales_DimProduct alter table dbo.[FactOnlineSales] DROP CONSTRAINT FK_FactOnlineSales_DimPromotion alter table dbo.[FactOnlineSales] DROP CONSTRAINT FK_FactOnlineSales_DimStore alter table dbo.[FactStrategyPlan] DROP CONSTRAINT FK_FactStrategyPlan_DimAccount alter table dbo.[FactStrategyPlan] DROP CONSTRAINT FK_FactStrategyPlan_DimCurrency alter table dbo.[FactStrategyPlan] DROP CONSTRAINT FK_FactStrategyPlan_DimDate alter table dbo.[FactStrategyPlan] DROP CONSTRAINT FK_FactStrategyPlan_DimEntity alter table dbo.[FactStrategyPlan] DROP CONSTRAINT FK_FactStrategyPlan_DimProductCategory alter table dbo.[FactStrategyPlan] DROP CONSTRAINT FK_FactStrategyPlan_DimScenario alter table dbo.[FactSales] DROP CONSTRAINT FK_FactSales_DimChannel alter table dbo.[FactSales] DROP CONSTRAINT FK_FactSales_DimCurrency alter table dbo.[FactSales] DROP CONSTRAINT FK_FactSales_DimDate alter table dbo.[FactSales] DROP CONSTRAINT FK_FactSales_DimProduct alter table dbo.[FactSales] DROP CONSTRAINT FK_FactSales_DimPromotion alter table dbo.[FactSales] DROP CONSTRAINT FK_FactSales_DimStore alter table dbo.[FactInventory] DROP CONSTRAINT FK_FactInventory_DimCurrency alter table dbo.[FactInventory] DROP CONSTRAINT FK_FactInventory_DimDate alter table dbo.[FactInventory] DROP CONSTRAINT FK_FactInventory_DimProduct alter table dbo.[FactInventory] DROP CONSTRAINT FK_FactInventory_DimStore alter table dbo.[FactSalesQuota] DROP CONSTRAINT FK_FactSalesQuota_DimChannel alter table dbo.[FactSalesQuota] DROP CONSTRAINT FK_FactSalesQuota_DimCurrency alter table dbo.[FactSalesQuota] DROP CONSTRAINT FK_FactSalesQuota_DimDate alter table dbo.[FactSalesQuota] DROP CONSTRAINT FK_FactSalesQuota_DimProduct alter table dbo.[FactSalesQuota] DROP CONSTRAINT FK_FactSalesQuota_DimScenario alter table dbo.[FactSalesQuota] DROP CONSTRAINT FK_FactSalesQuota_DimStore; GO Create Clustered Columnstore index PK_FactSales on dbo.FactSales;
I will kick off with cleaning up everything by removing all clean buffers:
DBCC DropCleanBuffers;
Now let us verify the health status of our Cache in SQL Server instance, by issuing the following query to dm_os_memory_cache_counters DMV and specifying Columnstore Object Pool:
select name, type, pages_kb, pages_in_use_kb, entries_count, entries_in_use_count from sys.dm_os_memory_cache_counters where type = 'CACHESTORE_COLUMNSTOREOBJECTPOOL';
![]() Notice that this DMV has suffered some major changes in 2012 version of SQL Server – there is no more separation into Single & Multiple Changes – this has been all very well documented at the dm_os_memory_cache_counters page.
Notice that this DMV has suffered some major changes in 2012 version of SQL Server – there is no more separation into Single & Multiple Changes – this has been all very well documented at the dm_os_memory_cache_counters page.
I have no idea why it has been always 32KB occupied by the Columnstore Object Pool by default, but I was unable to get rid of it – maybe this is some basic art of pre-fetching and initialising it, I hope that with the time this can be clarified.
Let us take a look into the Memory Clerks of SQL Server tracking Columnstore Object Pool allocations.
select name, type, memory_node_id, pages_kb, page_size_in_bytes, virtual_memory_reserved_kb, virtual_memory_committed_kb ,shared_memory_reserved_kb, shared_memory_committed_kb from sys.dm_os_memory_clerks where type = 'CACHESTORE_COLUMNSTOREOBJECTPOOL';
![]() We can see the very same 32KB pre-allocated from the 8KB pages, but with no real space has been given out yet.
We can see the very same 32KB pre-allocated from the 8KB pages, but with no real space has been given out yet.
For all I understand we have issued a couple of queries even though reading system informations, and so we should have some memory allocated to Buffer Pool while no space being allocated to the Columnstore Object Pool:
select * from sys.dm_os_memory_broker_clerks;
![]() As expected we have just one entry at the moment with ~18 MB allocated to Buffer Pool and no active Memory being allocated to Columnstore Object Pool.
As expected we have just one entry at the moment with ~18 MB allocated to Buffer Pool and no active Memory being allocated to Columnstore Object Pool.
From now I will be checking on my segments of FactSales table in order to construct a query that has a predictable and calculate-able size of the Segments that my future query shall be reading – in this case I am checking on the SalesKey column and its Segments.
select column_id, segment_id, row_count, base_id, min_data_id, max_data_id, on_disk_size
from sys.column_store_segments seg
inner join sys.partitions part
on seg.partition_id = part.partition_id
where column_id = 1 and
part.object_id = object_id('FactSales');
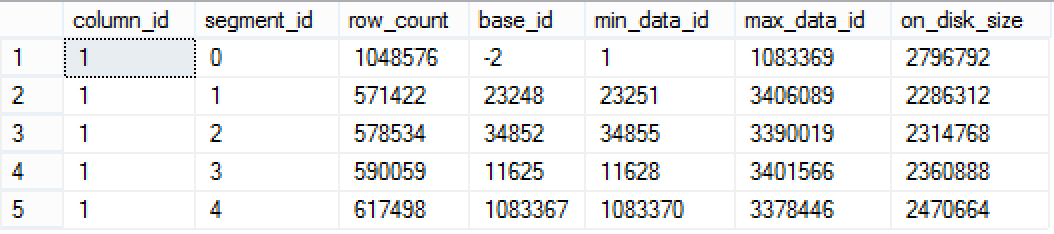 These result mean that in order to get a good segment elimination we can read SalesKey from 1 to 11628, which in my current situation shall guarantee that only the very first Segment with ID = 0.
These result mean that in order to get a good segment elimination we can read SalesKey from 1 to 11628, which in my current situation shall guarantee that only the very first Segment with ID = 0.
Before advancing with a query that involves SalesAmount, let’s check on the size of the first Segment (ID = 0) of the FactSales table, where the id of the column is equal to 16:
select column_id, segment_id, row_count, base_id, min_data_id, max_data_id, on_disk_size
from sys.column_store_segments seg
inner join sys.partitions part
on seg.partition_id = part.partition_id
where column_id = 16 and
part.object_id = object_id('FactSales');
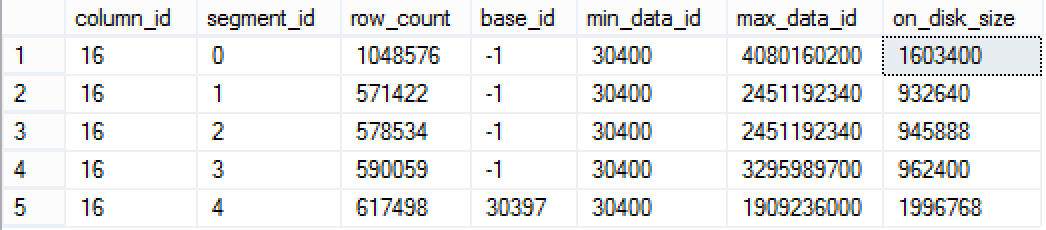 Here we are with the exact sizes for each of the SalesAmount Segments.
Here we are with the exact sizes for each of the SalesAmount Segments.
Now let’s run the query, cleaning out buffers in advance:
DBCC DropCleanBuffers; select Sum([SalesAmount]) from FactSales where SalesKey < 11628;
Mathematics for Columnstore Allocations:
In total we are dealing with around 4 MB of compressed Segments, because of the following formula (1603400 + 2796792)/1024 = 4297.06 KB, but will the amount of information be exactly what we expect:
select name, type, pages_kb, pages_in_use_kb, entries_count, entries_in_use_count from sys.dm_os_memory_cache_counters where type = 'CACHESTORE_COLUMNSTOREOBJECTPOOL'; select name, type, memory_node_id, pages_kb, page_size_in_bytes, virtual_memory_reserved_kb, virtual_memory_committed_kb ,shared_memory_reserved_kb, shared_memory_committed_kb from sys.dm_os_memory_clerks where type = 'CACHESTORE_COLUMNSTOREOBJECTPOOL'; select * from sys.dm_os_memory_broker_clerks;
 What we actually see here is that we have 26 entries in Columnstore Object Pool which are occupying 4840 KB in total, value which is a little bit superior to what I have calculated earlier.
What we actually see here is that we have 26 entries in Columnstore Object Pool which are occupying 4840 KB in total, value which is a little bit superior to what I have calculated earlier.
What is going on ?
I decided to try to take a look into DMV sys.dm_os_buffer_descriptors to see if there is anything that I can understand and relate to:
select object_name(object_id) as TableName, page_type, row_count, type_desc
from sys.allocation_units as alloc
inner join sys.partitions as part
on alloc.container_id = part.partition_id
inner join sys.dm_os_buffer_descriptors buff
on buff.allocation_unit_id = alloc.allocation_unit_id
where alloc.type = 2 and object_id = object_id('FactSales')
order by buff.page_type;
 There are 13 pages currently cached and TEXT_TREE_PAGE as well as TEXT_MIX_PAGE both correspond to the LOB data used to store Columnstore Indexes, while IAM_PAGE is an Index Allocation Map which keeps track of the Extents in each of the 4 GB space. IAM tracking includes Columnstore Indexes, which are stored as LOBs.
There are 13 pages currently cached and TEXT_TREE_PAGE as well as TEXT_MIX_PAGE both correspond to the LOB data used to store Columnstore Indexes, while IAM_PAGE is an Index Allocation Map which keeps track of the Extents in each of the 4 GB space. IAM tracking includes Columnstore Indexes, which are stored as LOBs.
Very interesting information, which brings more understanding into memory allocations, but it gives me more confusion at the moment than the actual answers.
Current Solution
We can consult the contents of the sys.dm_os_memory_cache_entries DMV, which returns information & statistics about all entries in caches in our instance for Columnstore Object Pool, maybe it can put some light into the matter of "missing" memory space:
select name, entry_data, pages_kb from sys.dm_os_memory_cache_entries where type = 'CACHESTORE_COLUMNSTOREOBJECTPOOL';
 This is where I am going to speculate quite a bit, and so here we go:
This is where I am going to speculate quite a bit, and so here we go:
object_type = 1 -> this is our actual Segment
object_type = 2 -> this is a Global Dictionary
object_type = 4 -> this is a Local Dictionary
object_type = 6 -> this item is appearing only when we have no dictionaries assigned to our Segment (both local and global dictionaries references are pointing to -1), and so I call it a "Future Dictionary" :) It can be easily recognised since it's column_id is always set to -1.
And so we actually see that while reading 1 Row Group from 2 different Columns we have 1 "Future" Dictionary for Column 1 (SalesKey) and 2 Dictionaries (Global & Local) for the Column 16 (SalesAmount).
We can confirm this findings by issuing the following query to the sys.column_store_segments DMV:
select segment_id, column_id, primary_dictionary_id, secondary_dictionary_id
from sys.column_store_segments seg
join sys.partitions part
on seg.hobt_id = part.hobt_id
where object_id= object_id('FactSales')
and column_id in (1,16) and segment_id = 0;
 Now that we have this information, we can go further and consult the sizes of those 2 dictionaries with ids 0 & 1, and so I issue the next query to find out this information from sys.column_store_dictionaries DMV:
Now that we have this information, we can go further and consult the sizes of those 2 dictionaries with ids 0 & 1, and so I issue the next query to find out this information from sys.column_store_dictionaries DMV:
select object_name(object_id) as TableName, column_id, dictionary_id, on_disk_size
from sys.column_store_dictionaries dict
join sys.partitions part
on dict.hobt_id = part.hobt_id
where object_id= object_id('FactSales')
and column_id in (1,16);
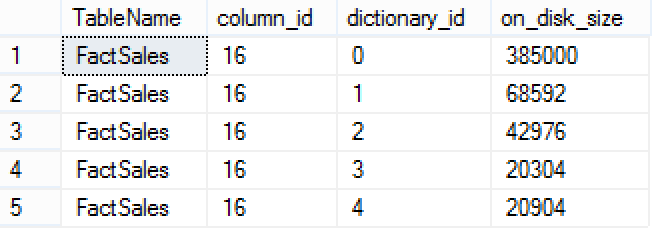 I can see 385000 & 68592 bytes respectively occupied by those dictionaries, and since they occupy space in Columnstore Object Pool we should definitely add them to our equation.
I can see 385000 & 68592 bytes respectively occupied by those dictionaries, and since they occupy space in Columnstore Object Pool we should definitely add them to our equation.
Final Result: (1603400 (Segment) + 2796792 (Segment) + 385000(Global Dictionary) + 68592 (Local Dictionary) )/1024 = 4740.02 KB
This means that we are still missing around 100KB of space, and I hope that some answers will arrive in the future.
I know that the "Future Dictionary" should occupy some space, but I have no information on how much, I have checked to verify if Deleted Bitmaps are already occupying some space, but this does not seems to be the case.
At the moment I am inclined to believe that this space is separated between the "Future Dictionary" and the rest should be some kind of pre-reserved memory space from the Large Pages, such as those 32KB that are reserved by the default as well as some free pre-allocated space, ready to be used.
to be continued ...
With bigger test data sizes it will become easier to interpret the results because small constant memory consumers will be insignificant. No longer necessary to wonder about 100kb unexplained allocations.
Hi Tobi,
agreed – I am looking forward to write about some findings in the near future.
Lg,
Niko
Thanks for the interesting article, Niko. It led me to look more deeply into the way columnstore uses memory, and I found a few things that may be of interest while using larger data sets than your scenario:
* The “object_id” in sys.dm_os_memory_cache_entries.entry_data seems to be the segment_id. This becomes clear when loading a columnstore with hundreds of segments. There is still an entry for object_id -1 that is likely a special entry, as you mentioned.
* Reading a large columnstore table resulted in enormous churn of the cached data in the “Column store object pool”. Despite my test SQL server have 375GB of memory allocated, only about 3GB is able to be used by the “Column store object pool” before it starts evicting data. By querying the “SQLServer:Memory Broker Clerks” object in sys.dm_os_performance_counters, I was able to see that the number of evictions caused by one large columnstore query was more than 10x the total amount of data able to be cached! Perhaps this is because the buffer pool always has priority and will build up over time to consume most of the available SQL Server memory? In my case, the buffer pool is over 300GB, but this seems like a very good usage of memory to me and makes a lot of sense given that there are a number of very large fact tables used by typical workloads. In any case, it’s very disappointing that my reads on very large rowstore fact tables are typically near 100% buffer cache hits, but result in near 100% misses for columnstore. I wonder if there is some way to improve this by giving the “Column store object pool” equal memory priority to the buffer pool? Why is it separate and not managed directly by the buffer pool? Is this just because the storage model is different and it was easier implementation-wise to make it separate? Does this design choice mean that columnstore data cannot take advantage of the new buffer pool extensions? Lots of ideas for future post topics!
* The number of reads reported when reading from a columnstore table (as reported by SET STATISTICS IO ON) appears to increase as the number of parallel threads reading from the table increases. This behavior does not happen for rowstore tables, and is confusing and a little bit concerning. For example, I created a smaller fact table that contains the same data both page-compressed (1.7GB in size) and as a columnstore (1.0GB in size). Reading the whole table reports 328K reads at MAXDOP 2, but 755K reads at MAXDOP 16! This is compared to a consistent 230K reads for the page-compressed version (strange that rowstore results in fewer reads despite being 70% larger!)
Thanks again for writing so many useful and thought-provoking articles in this series!
Hi Geoff,
thank you for the kind words. :)
Regarding your comments:
1) Agree. :)
2) I am confident that Buffer Pool has much higher priority than Columnstore Object Pool – all my tests has proven this so far.
I have had a number of very interesting conversation on this matter since February, when on German SQLKonferenz people started pointing that this does not make any sense to them. I would love to get some kind of official statement on this item one day.
For me the fact that every time a page gets evicted from Buffer Pool that belongs to the Columnstore Object Pool object, it automatically gets re-read into Buffer Pool. Plus Buffer Pool is the part of the memory which size we truly control since SQL Server 2012 (max server memory), while all other Pools seem to be orphans.
>I wonder if there is some way to improve this by giving the “Column store object pool” equal memory priority to the buffer pool?
Can’t imagine that – Microsoft would implement such functionality only as a last resort.
>Why is it separate and not managed directly by the buffer pool?
It is a different storage model with different objectives. In the 99% of the usage cases Columnstore Indexes are quite secondary to the rest of the objects. Naturally in the DWH world it is different, and so it would be awesome to take a look into APS(PDW) if it has different functionalities.
>Is this just because the storage model is different and it was easier implementation-wise to make it separate?
I believe so. We have an In-Memory processing that is not NUMA-aware, even though 2 versions of SQL Server were released. Does not make a lot of sense to me, but I am guessing that the improvements are considered to be not worth the effort.
>Does this design choice mean that columnstore data cannot take advantage of the new buffer pool extensions?
SUPER-QUESTION! :) Would love to find this one out!
3) The number of reads for Columnstore is very buggy – in CTP1 it was really terrible. I am wondering what is truly inside of the engine, and I hope that we shall get closer to the answers in the upcoming months/years.
Thank you once again for the very constructive comments – I am deeply appreciating your thoughts!
Thanks for all of your replies (and continued posts in this series). I’m glad that others are talking about some of the limitations of the Columnstore Object Pool. I wasn’t able to find a related Connect issue, so I ended up creating a script that reproduces the issue and filing my own Connect issue: https://connect.microsoft.com/SQLServer/feedback/details/1163152/columnstore-does-not-effectively-utilize-cache
I will look for a Connect issue for the number of reads being buggy with Columnstore and parallelism. If I can’t find one, I’ll try to create a test file for that as well and submit a Connect issue in the future.
Hi Geoff,
thanks for sharing – I agree that the Columnstore Object Pool is a kind of a less-privileged memory family member right now.
I have more stuff to share on this topic and hopefully I will be able to post blog posts in the nearest future.
Btw, voting your item up :)
Best regards,
Niko