This is the the 11th blog post in the series about Azure Arc enabled Data Services.
The initial post can be found at Azure Arc for Data Services, part 1 – Intro and the whole collection can be found at Azure Arc enabled Data Services.
In the previous blog posts we have created a simple SQL Managed Instance and went a bit further by configuring the stuff that we need, but that is by far not the end of the capabilities of the Azure Arc enabled Data Services. By that I mean that with a single command, we can deploy a given (and limited by the stretch of our available Kubernetes cluster) Availability Groups.
Yes, you’ve read it correctly.
An Availability Group.
On Linux.
In a Container.
On Kubernetes.
This is by far the greatest pitch line that the Microsoft could have given a couple of years ago, and it would sound totally insane, but here we are – reaching within a couple of months for the GA (General Availability) of this release.
For the start, I have a simple AKS cluster, which main resources I can list through the usual command:
kubectl get all -n arc

As described in Azure Arc for Data Services, part 6 – Data Controller, we have our usual elements Bootstrapper, Controller, ControlDB, LogsDB & MetricsDB pods with the respective UI pods as well, plus the ManagementProxy – all is usual and fine.
Now instead of a single instance of SQL Managed Instance (sounds very interesting this sentence is), let us specify the newest parameter for our AZDATA CLI command, the parameter that allows us to specify the number of replicas : –replicas (note that right now it does not have a corresponding short form and quite honestly, it might be for the better):
azdata arc sql mi create -n sqlha --replicas 3
In the command above, I am requesting the creation of an availability group with 3 replicas – 1 primary and 2 secondaries.
It take significantly more time to create those 3 pods with the respective containers, plus all the necessary elements, so depending on your Kubernetes cluster state and capacity you might see different results.

After inputting the name of the administrator of my SQL Managed Instance and the respective password and a couple of minutes I have the final result – the SQL Managed Instance with the Availability Group.
Let’s first take a look and see the elements that were created in our Kubernetes Cluster:
kubectl get all -n arc
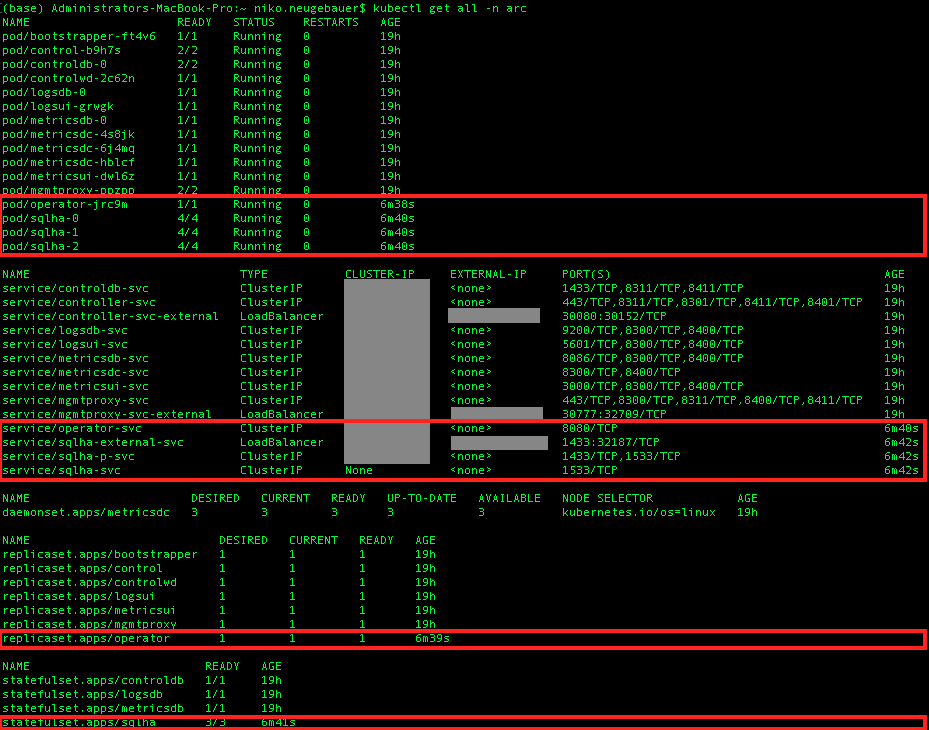
As you can notice on the image above, the elements that were created as the result of the SQL MI AG creation command are marked with the red rectangle.
Contrary to the single instance deployment, we get not just 1, but whole 4 pods!
– 3 Availability Group pods that are similar to the single instance
– 1 new pod that contains operator pod … I will make a wild guess right at this place that this one is connected to the control of which instance of the AG is the primary replica.
Grabbing the information on the pods from the container perspective with the following command:
kubectl get pod sqlha-0-o jsonpath='{.spec.containers[*].name}' -n arc
we can discover that besides the regular ones (fluentbit, collected, sql-mi) we have a brand new container: arc-ha-supervisor(base) which must be acting precisely as a supervisor for the control of the replicas within the availability group.
The pod named operator-[guid] contains mssql-ha-operator(base) that must be supporting the Availability Group.
Also, there are not just 2 services as usual, but whole 4:
– the good old pods service
– the habitual external service, but which serves in practice as the entry point for the Availability Group Listenewr.
– a brand new service -p that contains mapping to the 1533 port of the endpoint and on which purpose I have honestly no idea about
– a brand new operator service that must control the availability group, I guess
We kept the number of the replica sets and the stateful set just has 3 pods instead of just 1 as in the case of the single SQL Managed Instance.
Checking the SQL Managed Instance configuration leads to some very interesting discoveries,
azdata arc sql mi show -n sqlha
Cutting through the clutter to the most interesting details at the bottom of the JSON configuration:

we can see the external endpoint (our connection path), the availability group status (Healthy), readyReplicas (the number of replicas that are ready to do the work).
Should any of the replica’s go down, the overall number of ready replicas should go immediately down as well as the status of the Availability Group should change, but we shall dive into that part later in this post.
Connecting
 Well, let us stop digging into the kubernetes stuff and consider what we have in the SQL Managed Instance once we connect to it in the Management Studio.
Well, let us stop digging into the kubernetes stuff and consider what we have in the SQL Managed Instance once we connect to it in the Management Studio.
There can be only 1 availability group per SQL Managed Instance and it’s name is set in stone – containedag, with the automated Availability Group Listener being named containedagListener (well, I think this would would fail on Windows VM on Azure currently).
In any case if you would manage to create another Availability Group, there won’t be any databases to add, since any new database is added to the default Availability Group automatically.
There are so many interesting things about this SQL Managed Instance availability group that I don’t know where to start at best …
– there are 2 default databases containedag_master & containedag_msdb that must be replicated master & msdb databases, the ones that Microsoft wanted to make available in SQL Server 2019. They must be coming really soon. Hopefully.
– every single database that we create is automatically added to the Availability Group and hence some of the operation that older SSMS versions do when creating a database will cause an error, while the database will be successfully created and added to our AG containedag
– Deleting database will work perfectly well, since it will be removed from the Availability Group as well.
– Unless we connect from the containers themselves, I believe there are no ways to connect to the secondary replicas directly (unless we specify ReadOnly ApplicationIntent). After all this is a SQL MANAGED Instance and so we precisely reject our right to manage those instances in a big picture.
– The SQLAgent is still not automatically configured
– The Extended Event “AlwaysOn_health” is not started automatically, against the best practices recommended by Microsoft. This must have something to do with the way the SQL Managed Instance is implemented.
– The type of the cluster as expected is EXTERNAL, as can be seen from the following query against the sys.availability_groups DMV
and note that there is a column that identifies if the availability group is contained or not :) :
select cluster_type, cluster_type_desc, name, is_contained from sys.availability_groups;

– the 2 default databases are protected. We can not remove them (yes, of course I tried that right away!)
ALTER AVAILABILITY GROUP [containedag] REMOVE DATABASE [containedag_msdb];
![]()
– we can not change the most of the Availability Group properties, because those are not allowed to be changed after connecting through the listener.
BUT …
Connecting to the container within our pod, and using the SQLCMD while connecting to the listed port 1533 solves the problem, and here is the sample code below to alter the Availability Group preferences.
kubectl exec -it sqlha-0 -c arc-sqlmi -n arc -- /opt/mssql-tools/bin/sqlcmd -S localhost,1533 -U arcadmin -P MyAwesomePassword8290124538 -Q "ALTER AVAILABILITY GROUP [containedag] SET(AUTOMATED_BACKUP_PREFERENCE = SECONDARY);"
Yes, it is wonderful to say at least.
– we are back to the uneven number of nodes in order to make the quorum workable. I am assuming this since I do not expect an option to be able to set a witness in the blob storage (and for a pure on-premises solution it is totally impossible)
Exposé
In order to work comfortable with the individual nodes, you might choose to expose the services of each of the specific nodes that you want to be able to connect to.
This is done in the same way as it was done for Big Data Clusters, by creating a Kubernetes service
kubectl -n arc-cluster expose pod sqlha-2 --port=1533 --name=sqlha-2-p --type=LoadBalancer
We can check on the services list with the following command:
kubectl get services -n arc
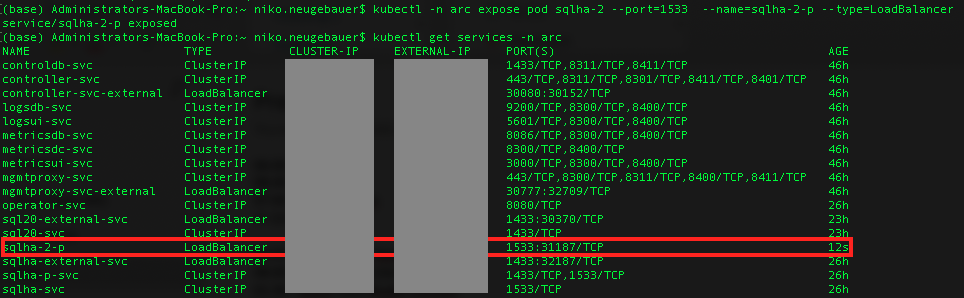
Our service will get it’s own IP, allowing us to connect to it directly.
The interesting part after connecting to the primary is that while we can work with the instance directly, we are not able even to see the availability group:
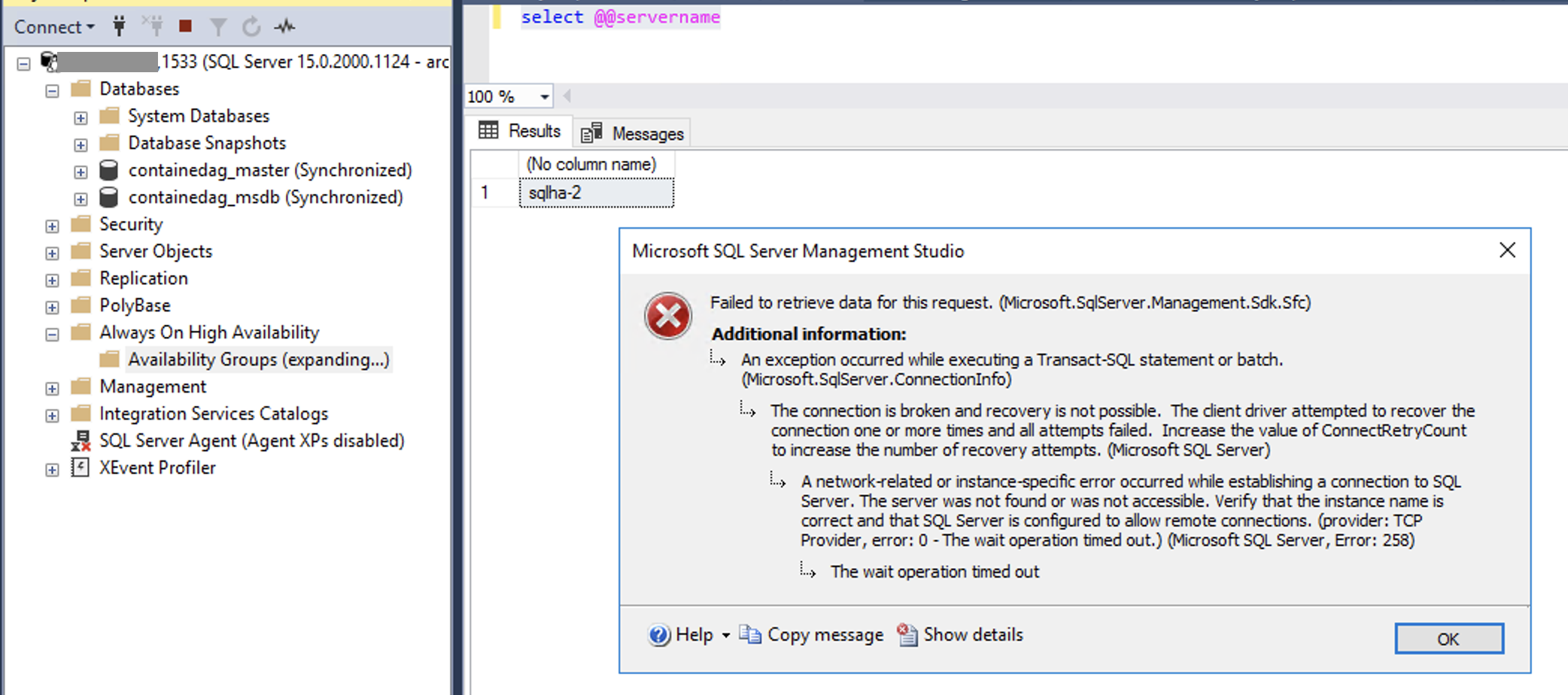
I assume that this has to do a lot with the chosen architecture of the solution and I am looking forward to discover and understand the reasons behind it.
In the end, it is important to delete this entry point after finishing the work, since I do not expect that this is a planned way and should be used as a workaround.
We can do it with the help of the KUBECTL DELETE SVC command
kubectl delete svc sqlha-0-p -n arc
Restores on SQL Managed Instance with High Availability
Right now, as I am writing this blog post, the restores of the databases are not exactly trivial – they need to be executed against the PRIMARY replica, while not being connected through the Availability Group Listener (it will hang on without advancing and without delivering any error messages back), and then by adding it to the Availability Group.
Let’s do a short walk-through:
First, let’s create a database test by connecting directly through the listener.
CREATE DATABASE test;
After a couple of seconds the database will be available in the availability group.
Now let’s take a full backup of our database, that will land on our primary filesystem, more precisely into /var/opt/mssql/data/:
RESTORE DATABASE [test2] FROM DISK = N'/var/opt/mssql/data/test.bak' WITH FILE = 1, MOVE N'test' TO N'/var/opt/mssql/data/test2.mdf', MOVE N'test_log' TO N'/var/opt/mssql/data/test2_log.ldf', NOUNLOAD, STATS = 1;
Step 1. Now, let’s do the restore database [test2] (and once again, in order to work right now, it has to be done against the primary replica (you always need to identify the respective pod, by using SELECT @@SERVERNAME or looking into Availability Group Dashboard, for example) and the container) – they are named sqlha-2 and arc-sqlmi in my case:
kubectl exec -it sqlha-2 -c arc-sqlmi -n arc -- /opt/mssql-tools/bin/sqlcmd -S localhost,1533 -U arcadmin -P MyAwesomePassword8290124538 -Q "RESTORE DATABASE [test2] FROM DISK = N'/var/opt/mssql/data/test.bak' WITH FILE = 1, MOVE N'test' TO N'/var/opt/mssql/data/test2.mdf', MOVE N'test_log' TO N'/var/opt/mssql/data/test2_log.ldf', NOUNLOAD, STATS = 5"

Let’s take a look at the list of the databases and the [test2] will not appear anywhere !
Warning: The statement SELECT * FROM sys.databases WILL NOT RETURN the database at all !
Step 2. Let us add the new added database [test2] to our Availability Group through the same method
kubectl exec -it sqlha-2 -c arc-sqlmi -n arc -- /opt/mssql-tools/bin/sqlcmd -S localhost,1533 -U arcadmin -P MyAwesomePassword8290124538 -Q "ALTER AVAILABILITY GROUP containedag ADD DATABASE Test2;"
And voilá – we have our database [test2] available and listed on the Availability Group!
I wish and hope that this method eventually get improved, since not every single DBA around will be able to execute this tasks correctly.
High Availability
To test high availability, let us do some pod destroying:
the test itself is rather self-explaining – in a single instance configuration it will take the whole time for the pod re-creation to back online, while for the Availability Group the price to pay is the time it will take to failover to one of the secondary instances.
For the purpose of the demo, let’s delete the primary node, salha-0
kubectl delete pod sqlha-0 -n arc;
and checking on the situation we can easily spot the pods that were destroyed and are recovering
kubectl get pods -n arc;
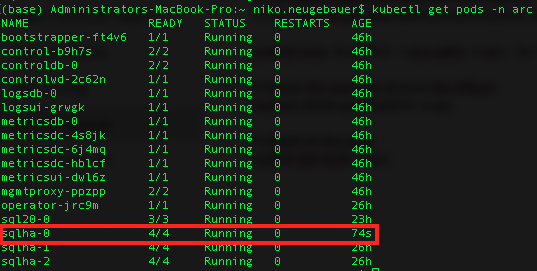
And while on my test Kubernetes cluster it takes around 72 seconds to recover (meaning at least the same downtime for a single instance), a simple automated failover will mean that we shall be ok, as the 3rd replica (sqlha-2) will assume the primary role, as shown on the picture below:

Final Thoughts
Wonderful!
Wonderful, magical, incredible !
If you have ever deployed an Availability Group on premises, that’s kind of not that hard …
If you have ever deployed it on Azure VMs, there is a whole mess with the probes, ILBs and company. Around 4 years ago, I did a heroic (for my skills attempt) attempt of deploying a complete Availability Group on Azure VMs with the help of the Powershell and I felt that it was an overkill for rather ok-ish task.
Seeing a way of making even the most junior person in the infrastructure team deploying a 3 replica availability group – makes me stand up and applaud to the development and program management teams.
This is like Terraform level 500 done with a single command – the level of this awesomeness is pure 100 percent!
p.s. I would love to see the maintenance a little bit easier, for example reconfiguration option (such as instance settings or trace flags) that is will be replicated automatically to every pod – thus guaranteeing consistence between them.
p.p.s. We need to have SQLAgent running by default.
to be continued with Azure Arc enabled Data Services, part 12 – Regular Tasks with the SQL Managed Instance