This is the the 7th blog post in the series about Azure Arc enabled Data Services.
The initial post can be found at Azure Arc for Data Services, part 1 – Intro and the whole collection can be found at Azure Arc enabled Data Services.
In this blog post we shall focus on the customisation and modifications to the Azure Arc enabled Data Services Data Controller. Previously we have have already created Data Controller on simple plain Kubernetes cluster in Azure Arc for Data Services, part 3 – Configuring on a plain vanila Kubernetes and for the AKS in Azure Azure Arc for Data Services, part 4 – Configuring on a AKS, but this time I want to do less GUI and more look into the underlying details, which might change in future releases, since at the moment of this post publishing, we are still months away from the GA (General Availability).
Before starting with the deployment of the Data Controller from the command line we need to make sure that we have all the required elements defined, such as:
- Azure Subscription ID
- Azure Resource Group
- Azure Region
- Storage Class that will be used for Data Controller deployment
- Your Kubernetes cluster profile (AKS with default or with premium storage, EKS, KubeADM, Rancher, etc)
- Kubernetes Namespace where the DC will be deployed
- The connectivity Mode (Direct or Indirect) you should have already decided previously
Some of those informations you will find in your Azure subscription and will have to create them (with the help of the Azure CLI, for example), and for the others we can check them with the help of kubectl command, such as in the case of the storage classes:
kubectl get sc -n arc;

from which I can pick one (or for the data and log storage of the SQL Managed Instance different) storage classes, for example. Let’s go forward with the default.
To see the available supported deployment profiles, you can execute the following command:
azdata arc dc config list
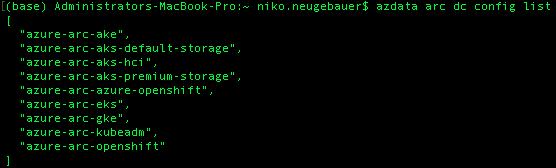
Regarding the namespaces, in my case, on my AKS Kubernetes cluster I have the ARC namespace already created (kubectl create namespace arc)
kubectl get sc -n arc;
![]()
and from the output above you can see that the namespace is empty as required currently.
and so armed with the requirements fulfilled (check Azure Arc for Data Services, part 2 – Requirements and Tools if needed)
let’s consider the command that will allow us to create the controller without any hustle :)
AZDATA ARC DC CREATE
This command will take the following arguments:
-n = name of the Data Controller
–profile-name = the profile name of the deployment (azure-arc-aks-default-storage in my test case)
–namespace = Kubernetes namespace to deploy Data Controller
–connectivity-mode = indirect or direct deployment connectivity mode
–location = the Azure region where the Data Controller will be registered (as a matter of a fact, should be very much connected to the Kubernetes cluster location)
–subscription = Azure Subscription Id
–resource-group = The name of the Azure Resource Group
–storage-class = the class of the storage used for the Data Controller deployment
And so let’s simply execute the command with the respective parameters, this time deploying in indirect connectivity mode:
azdata arc dc create -n aksarc --profile-name azure-arc-aks-default-storage --namespace arc --connectivity-mode indirect --location westeurope --subscription X --resource-group dataarc --storage-class default;

and after inputing the name of the administrator user and it’s respective password we shall have a fully deployed Data Controller after a couple of minutes.
This is much easier than going through all the Portal hustles. :)
Of course you could set up the respective variables in making the process more easily repeatable.
If you are going to do multiple deployments, this is the way to go. Important Note: deployments with the help of the Terraform will be considered in a separate blog post. :)
Customizing your Data Controller Deployments
Did you ever ask yourself what options are used by default by the controller and if by any chance we should be able to control and/or alter them ?
Well, this topic has been already thought off by the development team and we can do customisation according to our needs.
In order to advance we need to cleanup the deployed controller with the help of AZDATA ARC DC DELETE command:
azdata arc dc delete -n aksarc -ns arc
In order to create a CUSTOM configuration, first of all we need to create the default one (or you are free to read the documentation and work from scratch/your previous configurations), and in order to kick off we just need to use the command AZDATA ARC DC CONFIG INIT, which will require us to specify the location of the configuration JSON file and the respective selection of the deployment profile:
azdata arc dc config init
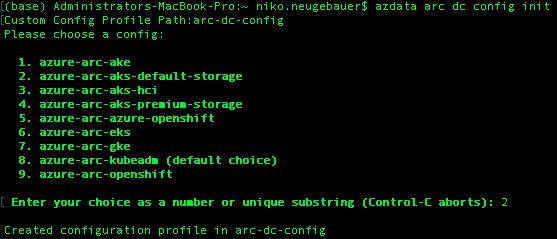
As the alternative you can initalize both of these parameters with the following command, where -p parameter will indicate the path to the folder with the Configuration JSON file to be stored in, -s parameter is the profile indicator and -f will force the overwriting of the destination file, and hence this command is better for any eventual automation:
azdata arc dc config init -p arc-dc-config -s azure-arc-aks-default-storage -f
Notice that there is an interesting profile “azure-arc-aks-dev-test” which is probably used for the tests by the development team.
Let’s consult the content of our file
vi arc-dc-config/control.json
![]()
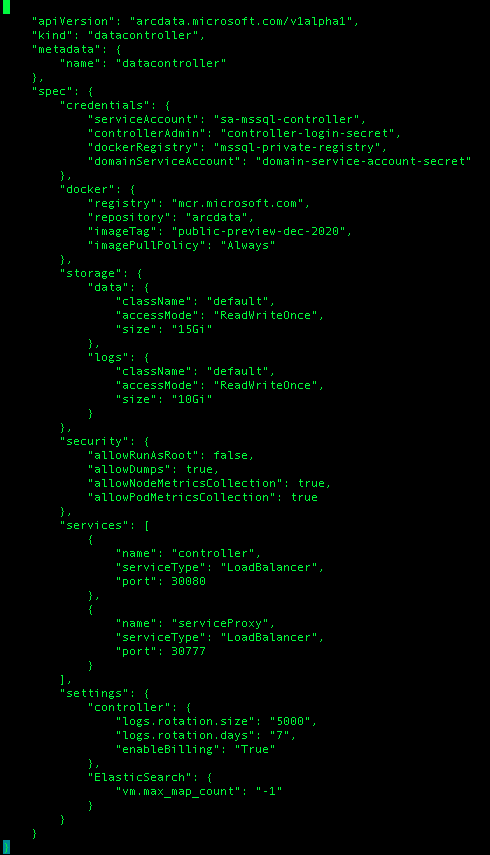 The result of the output will be a control.json file in the “arc-dc-config” folder which will have the following information (I assume that yours will be different, since mine is quite visible is being done in January of 2021 – the imageTag indicates that the container should be using the preview from the December of 2020. :)
The result of the output will be a control.json file in the “arc-dc-config” folder which will have the following information (I assume that yours will be different, since mine is quite visible is being done in January of 2021 – the imageTag indicates that the container should be using the preview from the December of 2020. :)
The other interesting and exciting things to be noticed are the default sizes for the storage of 15GB & 10GB for the data and logs respectively, the registry parameter which can eventually point to a private enterprise approved one, the security options with already previously used allowRunAsRoot that is required for the NFS storage currently and the others which eventually might be tuned to disable some of the responsive troubleshooting actions, such as taking deployment dumps and metrics collection.
The other things are quite visible are the ports for the controller and the service proxy and the settings for the logs of the controller itself, such as size and retention.
There are many setting that can be eventually added here, such as storage class names and other custom settings, which so far I have not seen documented.
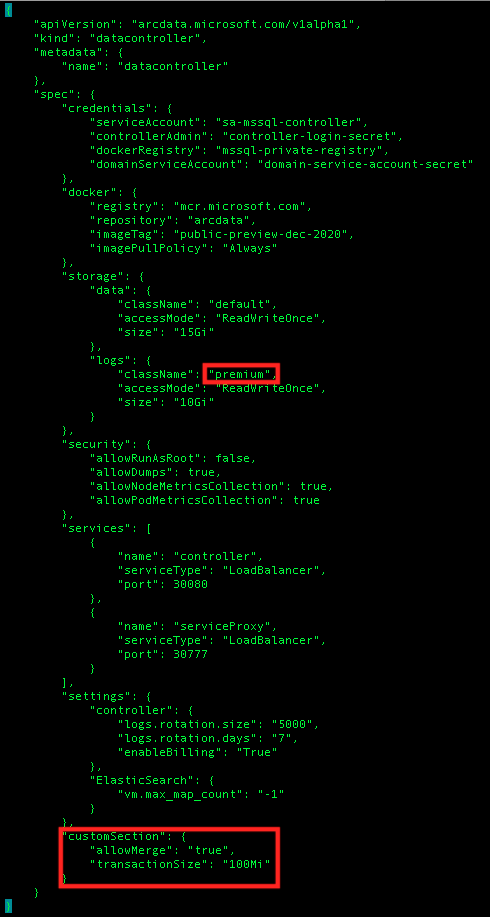
Let’s say that we want to change the default class of our storage to the premium and besides doing it with the help of any editor (hello vi!),
we can use the configuration management from the AZDATA CLI,
and here I am adding a new custom section “spec.customSection” with some random values:
azdata arc dc config add -p arc-dc-config/control.json --json-values 'spec.customSection={"allowMerge":"true","transactionSize":"100Mi"}'
And in order to make our Data Controller and respective logs running even faster, let’s indicate that they should be using the premium storage and for that purpose let’s use REPLACE subcommand of the AZDATA ARC DC CONFIG command:
azdata arc dc config replace -p arc-dc-config/control.json --json-values "spec.storage.logs.className=premium"
If there is a section in the control.json file that is troubling us, we can even remove it with the following command:
azdata arc dc config remove -p arc-dc-config/control.json --json-path '.spec.customSection'
Coming back to our editor and consulting the updated configuration we shall find everything as expected, with no updated storage for the logs and a new custom section:
Now we are ready to do our custom deployment with the help of the same AZDATA ARC DC CREATE command, but we just need to remove the profile parameter and indicate a path (–path parameter) to the folder with control.json configuration file:
azdata arc dc create -n aksarc --namespace arc --connectivity-mode indirect --location westeurope --subscription X --resource-group dataarc --storage-class default --path arc-dc-config

Easy stuff, people! :)
This is one of the ways how you can customize your deployments and as we live in a pretty much automated world, this opportunity should not be ignored.
to be continued with Azure Arc enabled Data Services, part 8 – Indirect Mode Reporting