This is the the 4th blog post in the series about Azure Arc enabled Data Services.
The initial post can be found at Azure Arc for Data Services, part 1 – Intro and the whole collection can be found at Azure Arc enabled Data Services.
If you are already using Azure and AKS (Azure Kubernetes Services), or using AKS in a different data centre, you should know that there is a possibility of running Azure Arc enabled Data Services on AKS, wherever you might have them – on premises or in a different cloud. This will guarantee a seamless transition into Azure environment, should you choose it.
This blog post is dedicated to show you how to set up the Azure AKS (Azure Kubernetes Services) and Azure Arc enabled Data Services on it.
You can indeed create a new AKS deployment in a number of ways, including Azure CLI and Powershell, beside the others, but here I will rather straight forward use the Portal for the beginners.
Create AKS through Portal
![]() To start with the Azure Kubernetes Service creation, select or search and then select the respective Kubernetes Services inside the Azure Portal.
To start with the Azure Kubernetes Service creation, select or search and then select the respective Kubernetes Services inside the Azure Portal.
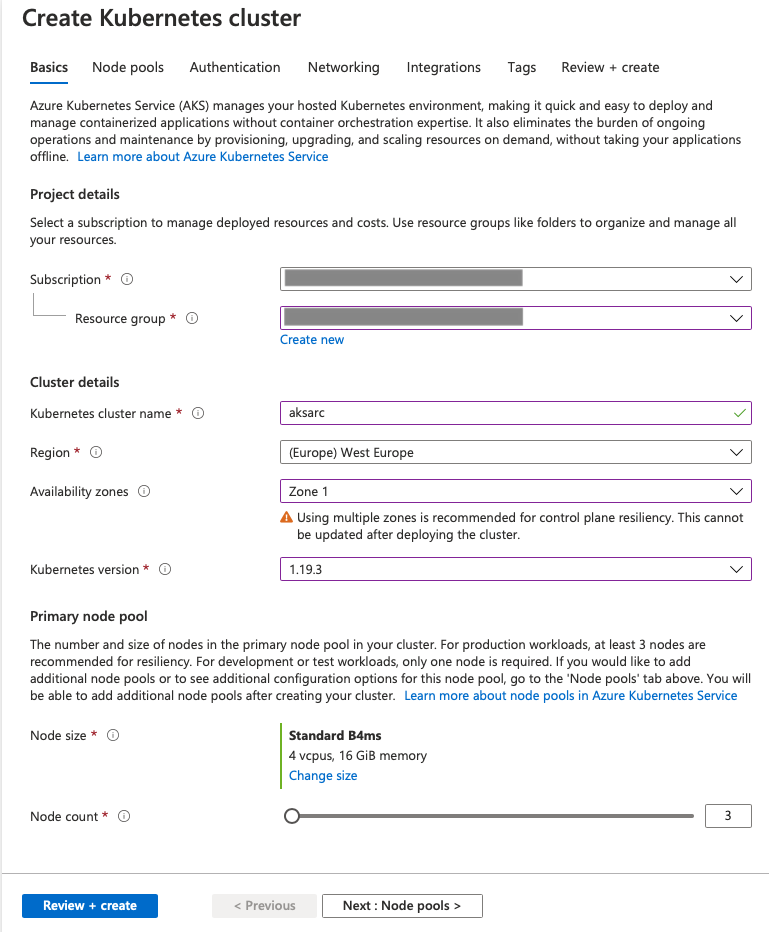 The first tab is where you can choose the subscription, Resource Group, Kubernetes Cluster name (aksarc in my case), the Region and the availability zones (IMPORTANT: Currently the PVC (Persistant Volume Claim) mapping to the pods fails and hence is not supported, so you need to choose just one specific Availability Zone if you want to deploy Azure Arc Data Controller successfully), and then, specifying the size of the node (aka VM) and the count of the nodes.
The first tab is where you can choose the subscription, Resource Group, Kubernetes Cluster name (aksarc in my case), the Region and the availability zones (IMPORTANT: Currently the PVC (Persistant Volume Claim) mapping to the pods fails and hence is not supported, so you need to choose just one specific Availability Zone if you want to deploy Azure Arc Data Controller successfully), and then, specifying the size of the node (aka VM) and the count of the nodes.
I have picked a B4ms for my test experiences, a VM with 4 vCPU and 16 GB of RAM, but you are free to play your own game, doing your own selection, respecting the requirements, of course. Be aware that if you are experimenting with the deployments and forget deleting, it might be very expensive.
You are also able to select the Kubernetes version and I rather choose 1.19+ for now, whenever experimenting.
 On the next tab you are able to select additional Node Pools for handling variety of workloads of non-primary usage and I am leaving here it blank. There is no need for the current test purposes to have virtual nodes and so I am not enabling them, and regarding the Virtual Machine Scale Sets – those are disabled, since we do not use Availability Zones.
On the next tab you are able to select additional Node Pools for handling variety of workloads of non-primary usage and I am leaving here it blank. There is no need for the current test purposes to have virtual nodes and so I am not enabling them, and regarding the Virtual Machine Scale Sets – those are disabled, since we do not use Availability Zones.
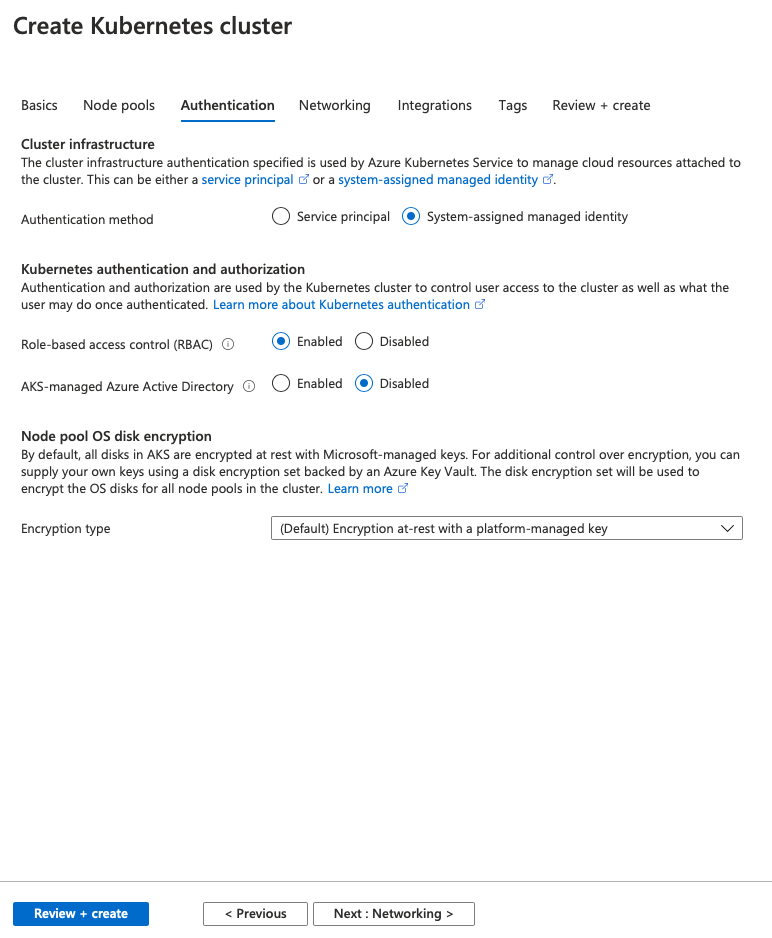
 On the authentication tab you can pick the authentication method (Service Principal vs System-assigned managed identity), RBAC and AKS-managed AAD, plus the encryption type. Again, I am leaving pretty much everything by default here.
On the authentication tab you can pick the authentication method (Service Principal vs System-assigned managed identity), RBAC and AKS-managed AAD, plus the encryption type. Again, I am leaving pretty much everything by default here.
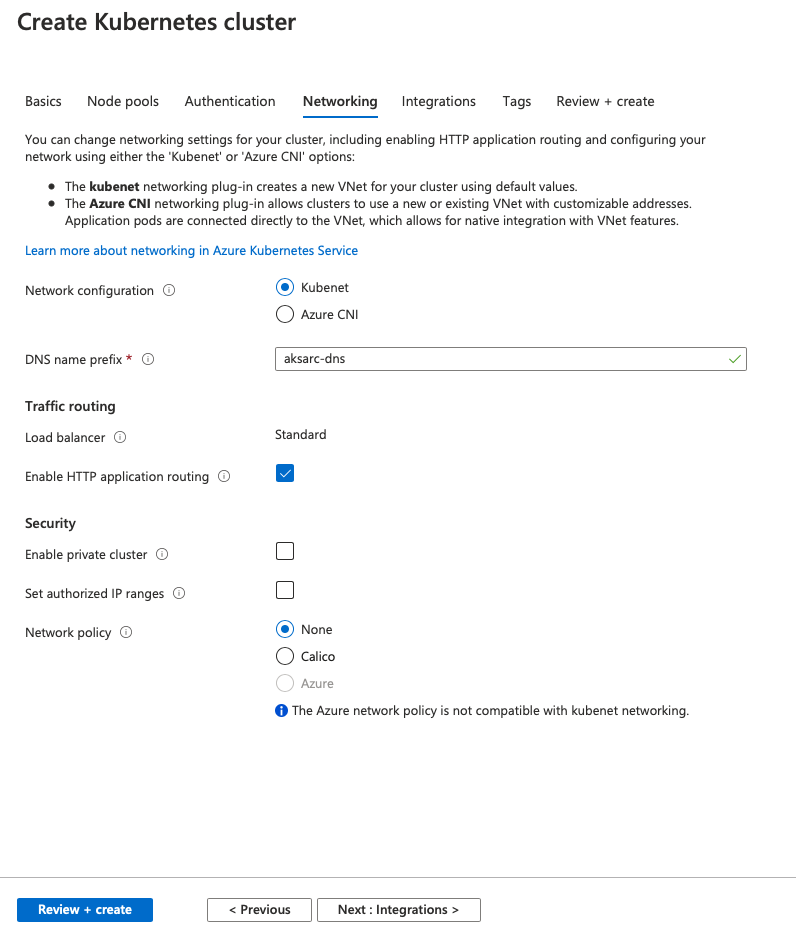 On the Networking tab I leave everything by default right now as well, besides the HTTP application routing, since all those settings are out of the scope of the test project for a basic test of Azure Arc enabled Data Services deployment.
On the Networking tab I leave everything by default right now as well, besides the HTTP application routing, since all those settings are out of the scope of the test project for a basic test of Azure Arc enabled Data Services deployment.
This does not mean that those settings are to be somehow ignored, your network and security are essential for the safe deployment and the times we are living, require a classy security or you will risk to end this trip on the first pages of newspapers in the chapter of security disaster (In Portugal between my friends we call it “getting CMTV-ed”).
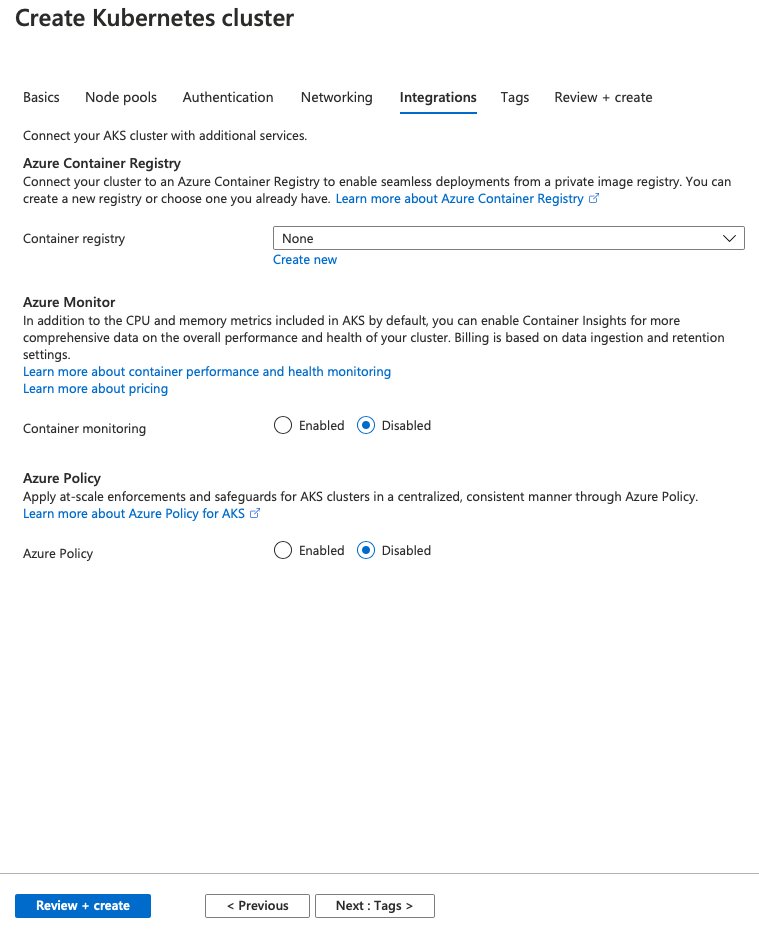
 On the last tab (called “Integrations”) I am just disabling Container Monitoring and leaving Azure Policy disabled as by default and not adding any container registry (in a big enterprise environment, most probably you will have to specify your own registry).
On the last tab (called “Integrations”) I am just disabling Container Monitoring and leaving Azure Policy disabled as by default and not adding any container registry (in a big enterprise environment, most probably you will have to specify your own registry).
After reviewing the tags and the validation, it takes just a couple of minutes (<10 in my experience) to deploy a new AKS cluster successfully.
Creating Azure Arc Data Controller
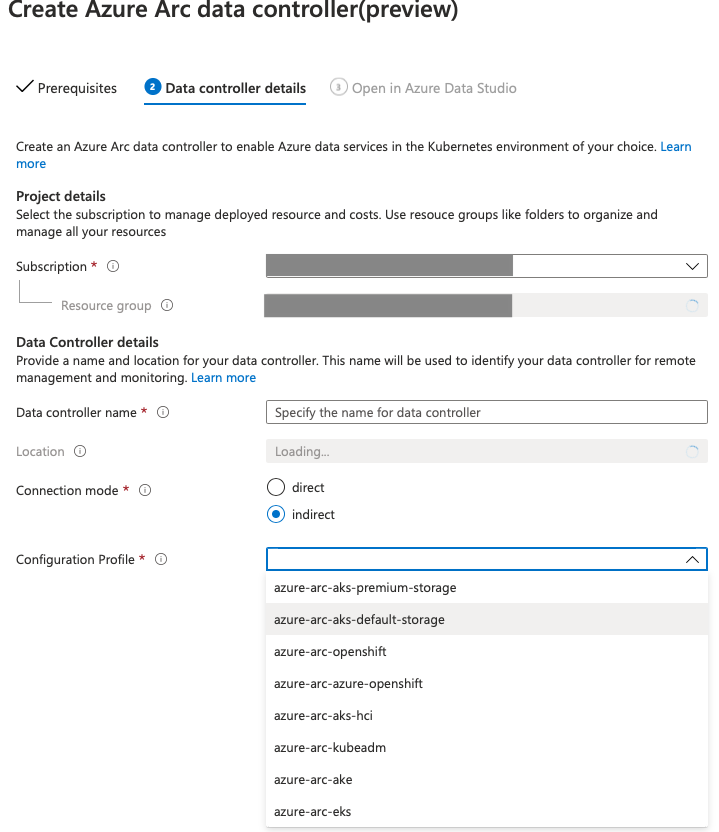 By itself the creation of the Azure Arc Data Controller is pretty much the same as shown in Azure Arc for Data Services, part 3 – Configuring on a plain vanila Kubernetes, with the exception of the decision for the storage profile selection between the default and the premium storage, the decision that apparently at the moment can not be changed.
By itself the creation of the Azure Arc Data Controller is pretty much the same as shown in Azure Arc for Data Services, part 3 – Configuring on a plain vanila Kubernetes, with the exception of the decision for the storage profile selection between the default and the premium storage, the decision that apparently at the moment can not be changed.
Notice that here I am configuring everything on the highest level as possible, making it as accessible as possible, but that does not mean that an advanced user would not create an AKS with CLI and with the help of the same command line and AZDATA would not deploy the Azure Arc Data Controller with much higher efficiency or eventually not even automatising the whole process with the help of their favourite tools and scripts.
Getting the Kubernetes Configuration
In order to download the Azure Kubernetes Services configuration, we can use the respective Powershell configuration, saving the generated JSON into the aks-config file.
az aks get-credentials --resource-group dataarc --name aksarc --file aks-config
![]()
I am coping the downloaded cluster configuration into .kube/ folder right away, since merging and different contexts right now are out of the scope of this article:
cp aks-config .kube/config
![]()
Now we are ready to follow the path straight with the downloaded Azure Data Studio notebook, indicating all the necessary parameters for the cluster creation and just in a couple of minutes being able to have our Azure Arc enabled Data Services deployed on AKS.
Again, you can monitor the deployment and the creation of all the elements, such as PVCs and Pods with the help of the following KUBECTL command:
kubectl get all -n arc
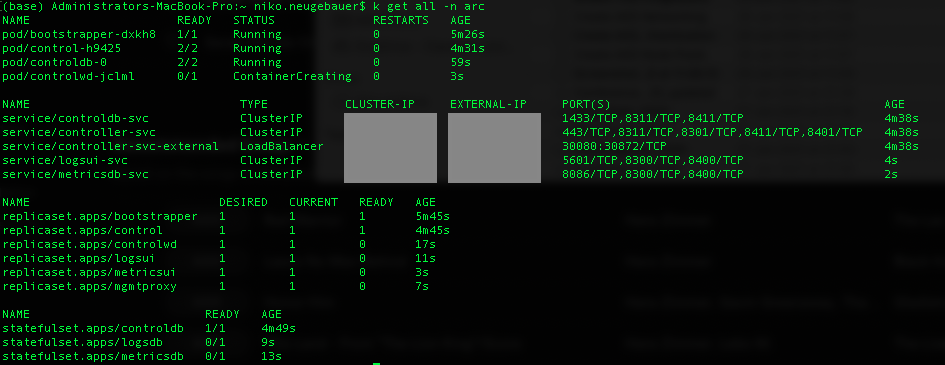
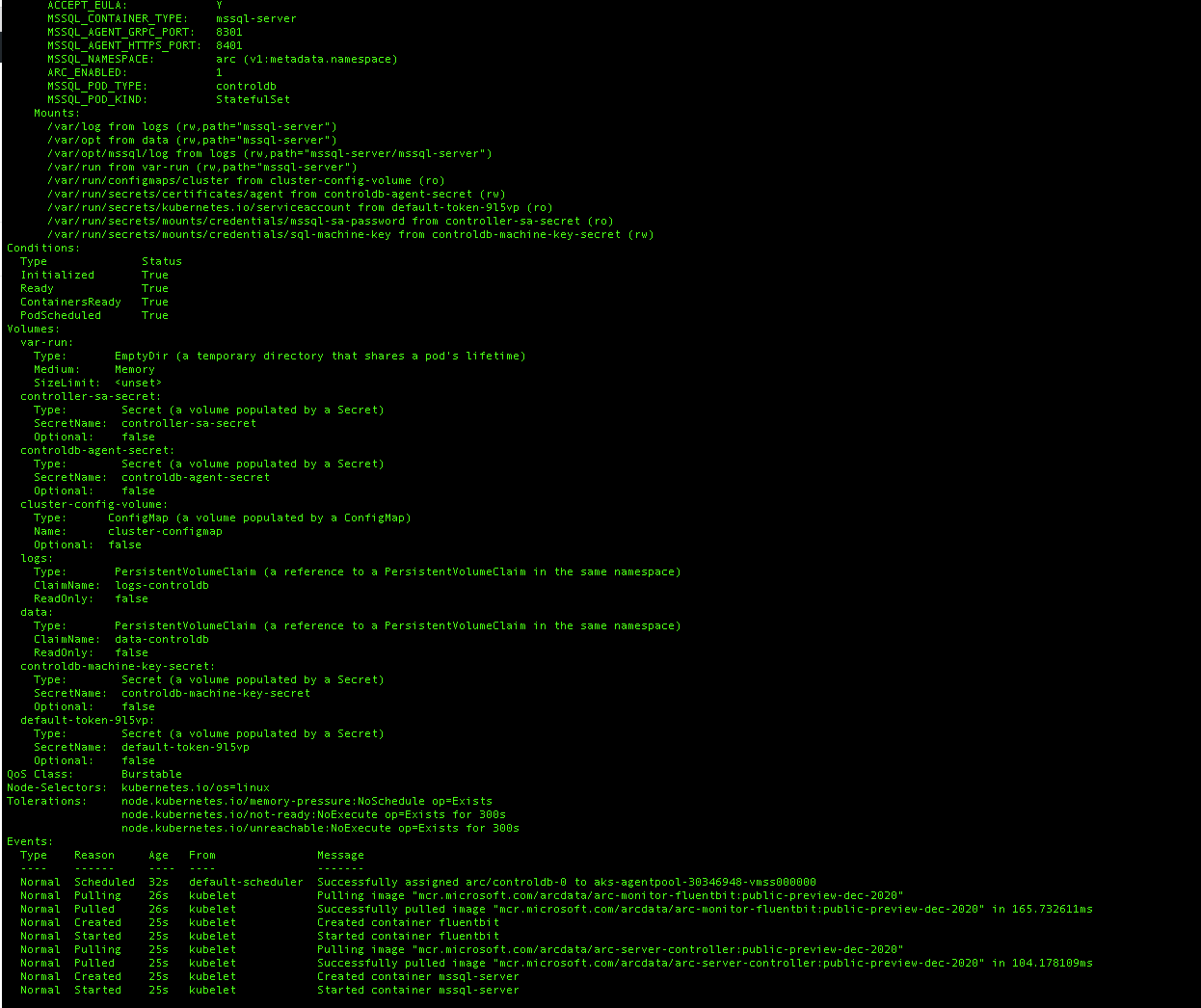
and dive into the individual pod creation process and basic troubleshooting with the help of the KUBECTL describe command:
kubectl describe pods/controldb-0 -n arc
Depending on the involved components it might take some time, you will know for sure after executing the
azdata arc dc status show
and
azdata arc dc endpoint list
as indicated in Azure Arc for Data Services, part 3 – Configuring on a plain vanila Kubernetes
That’s about it, there is really nothing too much special in creation of the AKS and deployment of the Azure Arc enabled Data Services.
In the next blog post I will focus a little bit on the configuration of the Direct Mode for the Metrics reporting and the respective Service Principal, Client and Secret. They are out of the scope for the Azure Arc enabled Data Services, but after some thought I felt that without them, there will be important missing pieces in the narrative.
to be continued with Azure Arc enabled Data Services, part 5 – Service Principals for the Direct Mode