There is so much to think about when talking/writing about the SQL Server on the cloud VMs, and in this blog post I am going to touch on one of the less spoken and might be – one of the most controversial topics of SQL Server on Azure VM Disk Caching.
Warning: the topic of caching is pretty much the same when you are looking at any other cloud, such as AWS or Google.
Microsoft has been extremely clear in the best practices recommendation for the SQL Server workloads on Azure VMs:
– use read caching for the data drives/storage pools
– use no caching for the log drives/storage pools
– use read caching for the temp db drives/storage pools
Sounds simple and direct, isn’t it ?
Let me borrow your attention for the next couple of minutes pointing to some situations where you might want to reconsider the best practices.
Azure Disk Caching
Before advancing any further, let’s remind ourselves what Azure Disk Caching is.
This is an internal optimization that will use the locally attached SSD storage aka D-drive (on the respective Virtual Machines that support it), storing the information from the slower drives that is asked frequently, in order to optimize the reading and/or writing operations.
The IO operations executed for this purpose will account towards the total Virtual Machine IO account and thus shall be throttled if they will be over the defined limit.
You see, that is a KIND OF IMPORTANT …
Current VM Caching
The documentation provided by Microsoft is very much straight forward (and I do remember the old times, when it was everything but far from being explicit and clear), specifying in details for each of the VMs family limitations, because as you might be surprised – the values are different when you are doing caching or when you do not.
I have created a small table on the select VMs just to prove the point and note that I am not considered the constrained cores, but the tendency will be very much repeatable:
| VM Family | vCPU | Cached Read MB/s | Uncached Read MB/s |
|---|---|---|---|
| Standard_E8s_v3 | 8 | 128 | 192 |
| Standard_E16s_v3 | 16 | 256 | 384 |
| Standard_E32s_v3 | 32 | 512 | 768 |
| Standard_E64s_v3 | 64 | 1024 | 1200 |
| Standard_DS13_v2 | 8 | 256 | 384 |
| Standard_DS14_v2 | 16 | 512 | 768 |
| Standard_D8s_v3 | 8 | 128 | 192 |
| Standard_D16s_v3 | 16 | 256 | 384 |
| Standard_D32s_v3 | 32 | 512 | 768 |
| Standard_D64s_v3 | 64 | 1024 | 1200 |
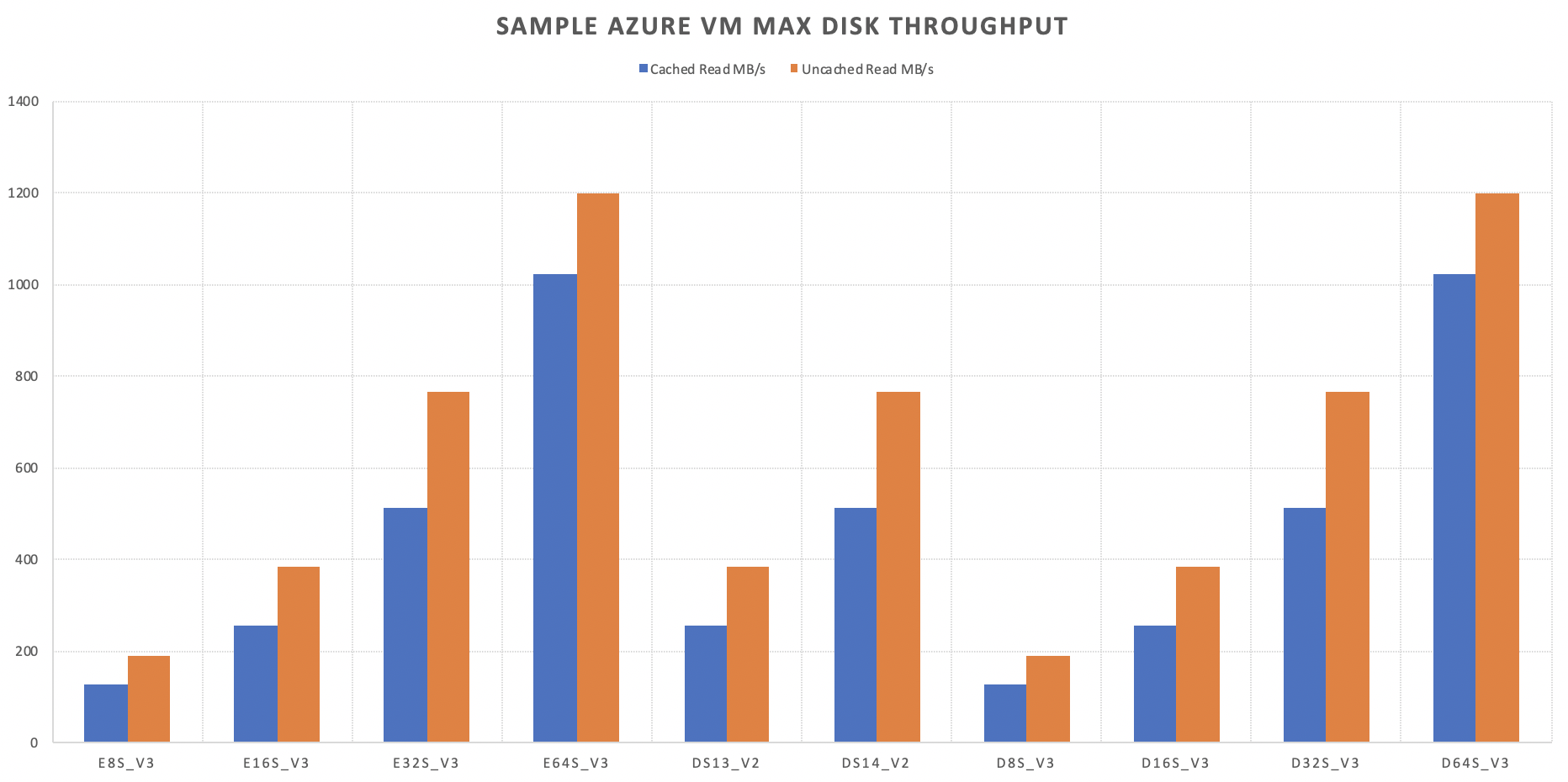
As it very clearly visible, the uncached throughtput for the VM’s is basically ALWAYS better then the cached one and only starting with the 64 cores (for the sampled VMs) the difference between the Cached & Uncached throughput will start to go down in terms of the percentage, being well 50% improvement for the Virtual Machines with less then 64 cores.
This IS very very significant in my experience.
IO-Intensive
Think about all the diversity in big IO-intensive operations, such as:
– ETL processes for Business Intelligence and Data Warehouses
– Regular Updates for the big tables
– Big Table Scans
– Backups
– RESTORING databases (including Direct Seeding)
– CHECKDB
– and so many more
In this blog post, I will be focusing on the Premium SSD Managed Disks, the kind most of my current clients are using, but of course you mileage will vary according to your experience, and no, 1 TB is not the most popular size … haha :)
Let’s say we are measuring our throughput in 1 TB drives (P30 , more information on the diverse disks, their limitations and respective prices can be found in the documentation). This managed ssd disk will give us up to 200 MB/second throughput which is pretty impressive.
Restoring Databases
Imagine that we are using 2 of those 1 TB disks for our data files and (we shall be ignoring the Log & TempDB for the purpose of simplification, but in the real life and espcially if you are running an HA solution as an Availability Groups, never ever even think about ignoring the total IO limitations) – let’s see and calculate the impact for each of the selected virtual machines for RESTORING the 2 TB & the 4 TB databases:

Restoring 2 TB
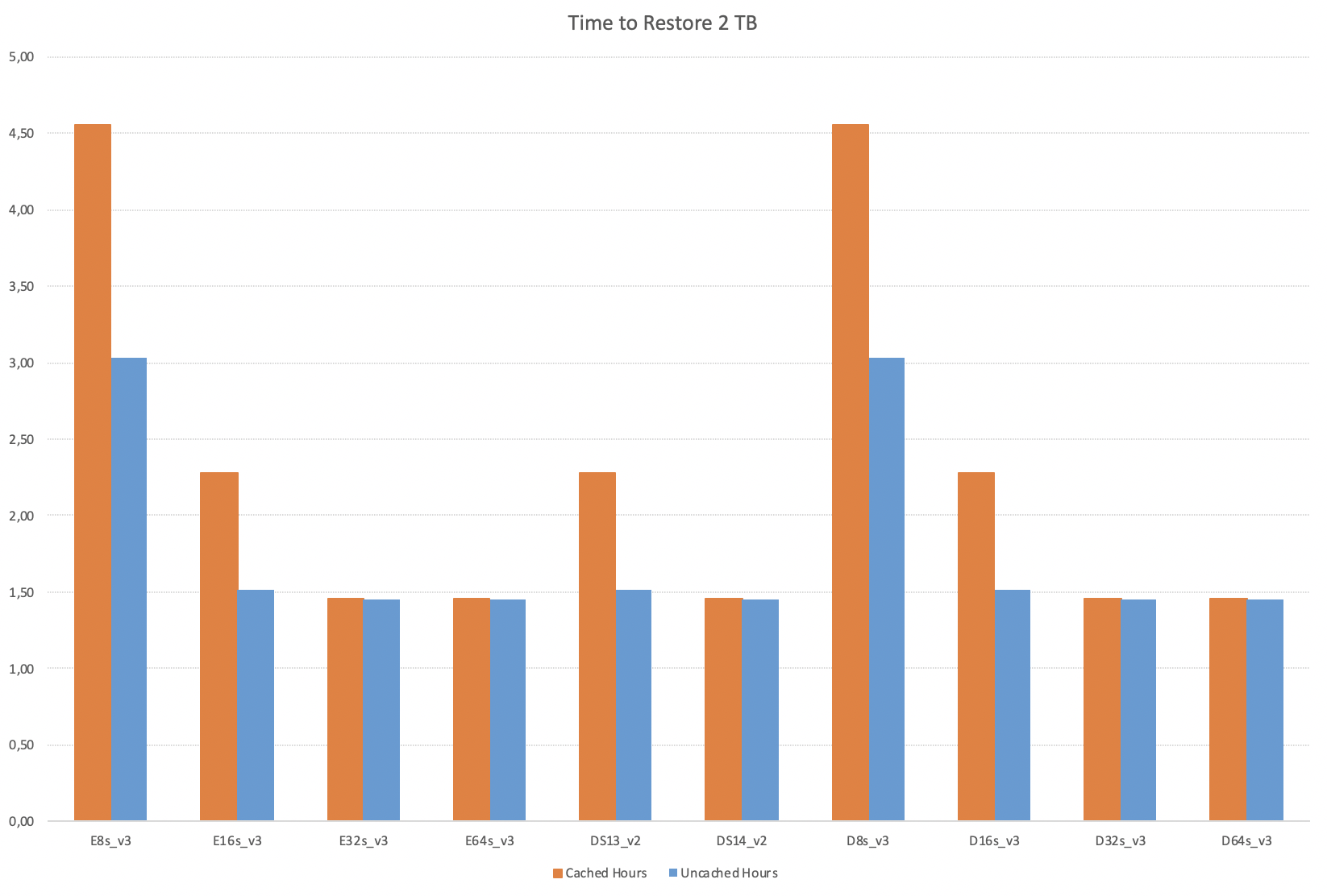
If for some reason (*cough* money *cough*) or not (*cough* BnI *cough*) you are using E[x]s_v3 family of the Virtual Machines for the IO-intensive workloads, you are doing it wrong – DS13_v2 with 8 vCPU will give you the same IO performance as the 64 core E64s_v3 in the pure number of hours.
The main issue I want to highlight here, that when you are using a E8s_V3 in a similar situation – if you would shutdown your Azure VM, change the data disk caching to NONE, restart the VM, restore the database and then again change the disk caching back to the Read-Only, you would still have enough time to have an extra-lunch of well over 1 hour.
Yes, an extra one hour! That’s not a bad value for the business, trust me !
On more IO-capable Virtual Machines, this difference will get easily lost in translation as in my books 30 minutes is not something very much worth extra-effort and risk. But let us not stop there and see what will happen with 4 TB.
Restoring 4 TB

Once we are going to get to bigger databases the difference will start growing very unproportionally and here the good E8s_v3 as well as the D8s_v3 Virtual Machines will give you an intensive 3 hours difference! That would be a good time for a lunch and a bonus nap …
Scaling up to better VMs up to 32 vCPU Uncached will give you a great potential boost, or you can also select DS14_v2 with just 16 cores and be done in just 1.5 hours, contrary to the original 9 hours of the E8s_v3. :)
Restoring 8 TB
As the final delighter (but by no measure the biggest database out there that you will find on Azure), here is the image of the 8 TB restore operation calculation.
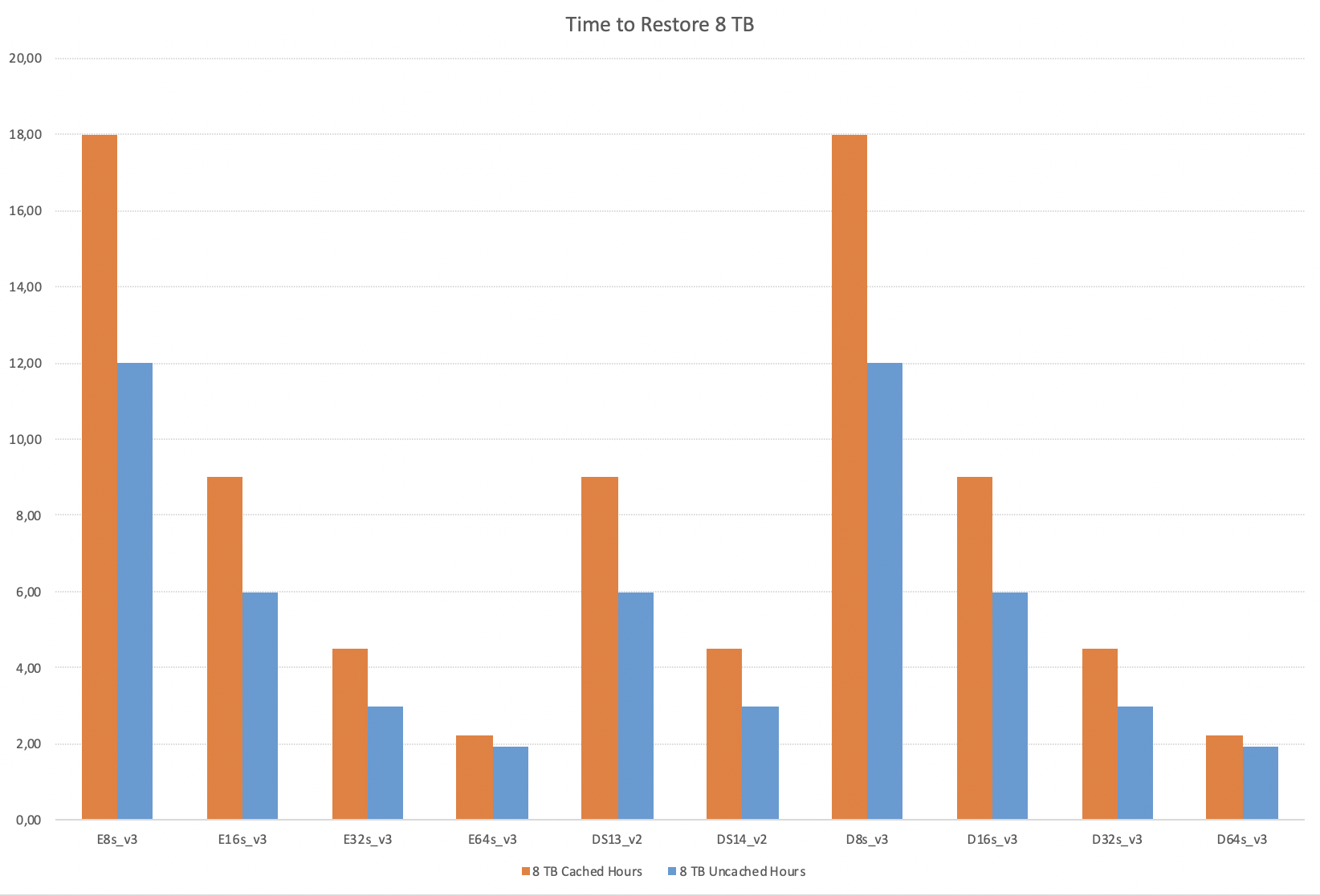
One last thing – if you want to go below the 2 Hours, you better start considering other VMs and other Storage Pools/diks.
Final Thoughts
I strongly suspect that there will at least a couple of scenarios where the caching won’t bring the expected benefits (very IO intensive workload where the same data is not queried all over again), where the default caching on the Azure disk drives won’t bring you any benefit, but will slower your overall performance.
Of course, I want to explicit mention that even restores will have a significant impact over the Log file and it’s performance might reveal the necessary to tune the Log Storage Pools/Disks performance, but the main point here is about caching and not caching for certain workloads.
No matter if you are adding a new replica, or directly restoring a database, the potential impact on the overall performance can be huge!
And by the way: do not take it for granted – test your workloads and operations before deciding anything
it is just ridiculous that people believe caching must be good without understanding circumstances. See the 2004 paper and code by Peter Kukol https://www.microsoft.com/en-us/research/wp-content/uploads/2004/12/tr-2004-136.pdf
https://www.microsoft.com/en-us/download/details.aspx?id=52334
on the price of caching (buffering) versus straight through
Hi Niko, interesting post thanks for sharing, and it is great to run into another one of your posts after a long time… I have read many of your columnstore posts years ago from which I have learned a lot.
Thought you may find these 2 related posts of mine interesting as they also talk about the disk caching aspect in Azure and point out some differences
https://www.linkedin.com/pulse/azure-vm-disk-stress-tests-comparison-different-premium-yaniv-etrogi/
https://www.linkedin.com/pulse/azure-vm-disk-stress-tests-p30-premium-ssd-drive-yaniv-etrogi/
IT would be much more informative if you will try the same comparison on machines using AMD EPUC cpus, like D16as_v4, etc. The results could be much better than here.
Hi Przemysław,
thank you for the tip – I will consider this, once writing a new article in the future.
Best regards,
Niko
I have also discovered some very strange anomalies when using uncached workloads (SQLite exactly) on virtual machines that are using cached disks in my article about Azure VM performance: https://www.linkedin.com/pulse/azure-virtual-machines-performance-behavior-costs-you-%C5%82ukawski/
In a nutshell: on Intel based machines when cached disks are used in VM, when you degrade the disk from premium SSD to Standard SSD and then revert back the change. You will get uncached performance to degrade significantly.
Hi Przemysław,
thank you – it looks interesting. Did you reported it as a bug ?
Best regards,
Niko