I wanted to write about a pretty old Azure feature that apparently approaching General Availability aka GA (as publicly mentioned by different Microsoft PMs) after 4+ years of being in preview – the Azure Elastic Jobs.
The whole idea about the Azure Elastic Jobs is to give you a key missing element from the regular SQL Server experience – the Job scheduling, because as you must know by now – there is no SQL Agent for the Azure SQL Database.
I have no idea why it took so long to port a significant part of the code of the agent (let’s say around 10 years 2006-2016), but as the matter of a fact this feature has been available since at least 2016, but for some obscure reasons nobody wanted to implement it before or advance with a full GA (General Availability) so far.
I remember asking around 3 years ago and the answer that I had received was the kind of – “what the hell do you want to do with THAT … Leave it be …”
Anyway, currently it seems that the market is indeed believing and expecting the GA of the Azure Elastic Jobs and from my personal perspective – these ARE absolutely wonderful news.
Azure Elastic Job Agent
 Right now for creating Azure Elastic Jobs you will need to define your Azure SQL Server & Azure SQL Database where all the necessary Tables, Views, Stored Procedures & Function will be placed. That’s a pretty impressive by easiness setup and I won’t focus on it – there are many blogs around on this matter, and the documentation is quite clear in my opinion.
Right now for creating Azure Elastic Jobs you will need to define your Azure SQL Server & Azure SQL Database where all the necessary Tables, Views, Stored Procedures & Function will be placed. That’s a pretty impressive by easiness setup and I won’t focus on it – there are many blogs around on this matter, and the documentation is quite clear in my opinion.
After passing through basics of Elastic Job Agent creation in the Azure Portal (or you can do it either in your favorite automation scripting environment Powershell/CLI/Ansible/Terraform/etc), you will be presented with the screen presented below.
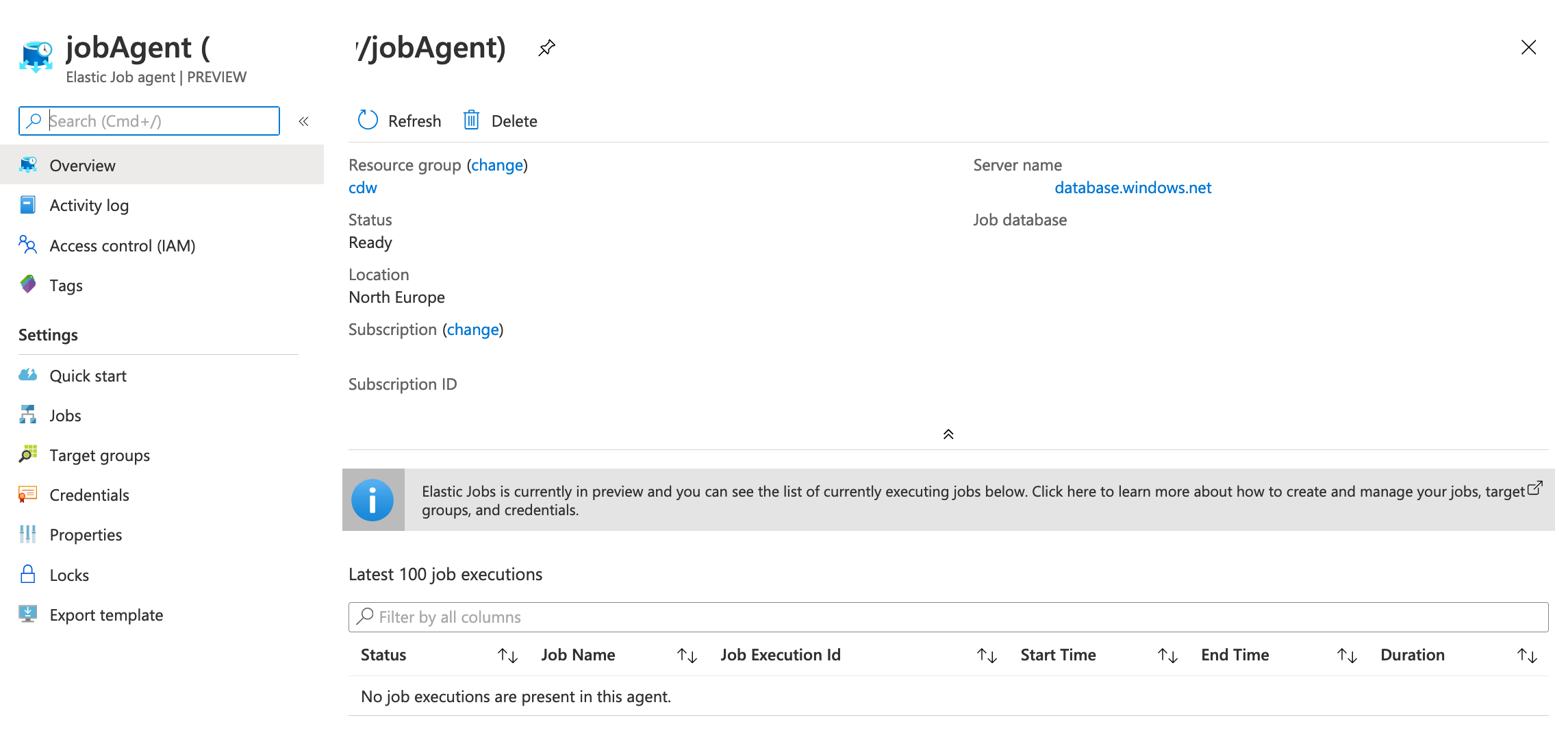 Notice that currently everywhere you look, you will see the warnings about the preview phase of the feature and think about the risks you are facing when using a feature that can be changed in any moment, in any of its parts or being retired completely (I obviously hope that none of this parts will happen). It is not much that you can see on the portal right now, besides listing the output of the last 100 job executions, listing the configured jobs, the Target Groups and the Credentials. You will not be able to execute any job-related actions through the Portal on the Elastic Job Agent blade, and if you want to scale the database or configure something, you will need to deal with good old T-SQL inside the configured repository in Azure SQL Database. Indeed you can use the Powershell for this purpose as well, the documentation provides good information on how to do that.
Notice that currently everywhere you look, you will see the warnings about the preview phase of the feature and think about the risks you are facing when using a feature that can be changed in any moment, in any of its parts or being retired completely (I obviously hope that none of this parts will happen). It is not much that you can see on the portal right now, besides listing the output of the last 100 job executions, listing the configured jobs, the Target Groups and the Credentials. You will not be able to execute any job-related actions through the Portal on the Elastic Job Agent blade, and if you want to scale the database or configure something, you will need to deal with good old T-SQL inside the configured repository in Azure SQL Database. Indeed you can use the Powershell for this purpose as well, the documentation provides good information on how to do that.
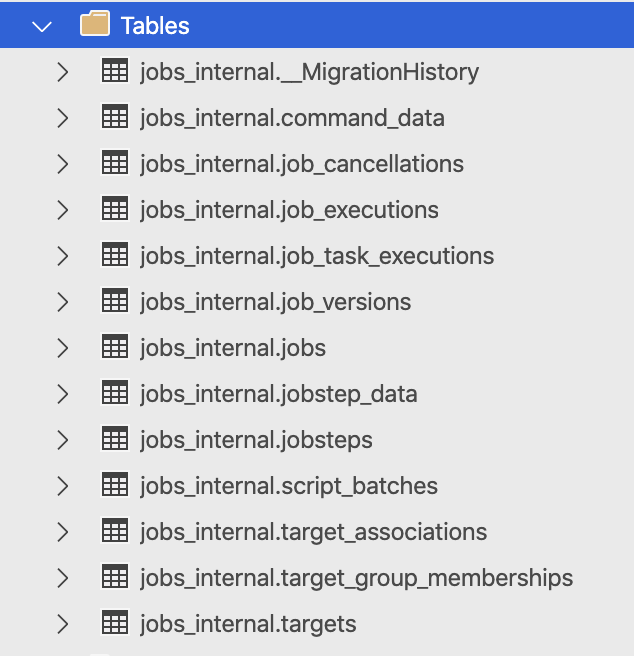
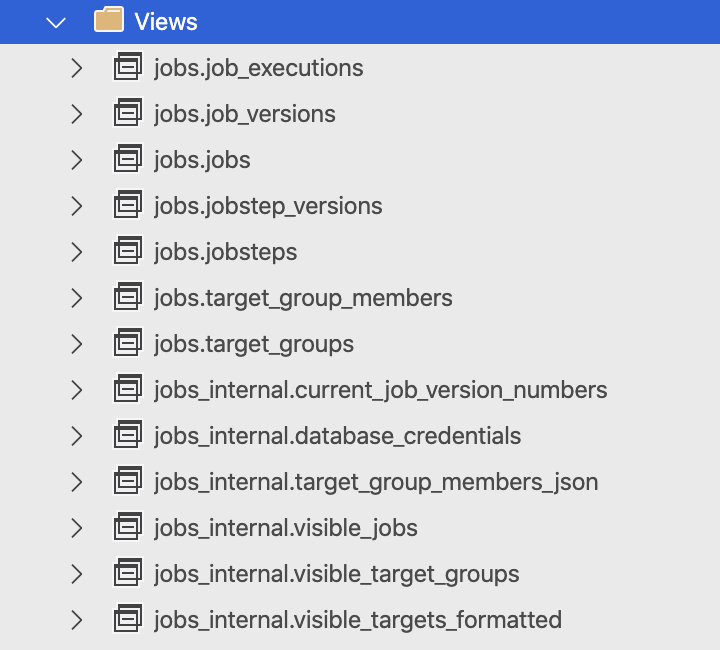
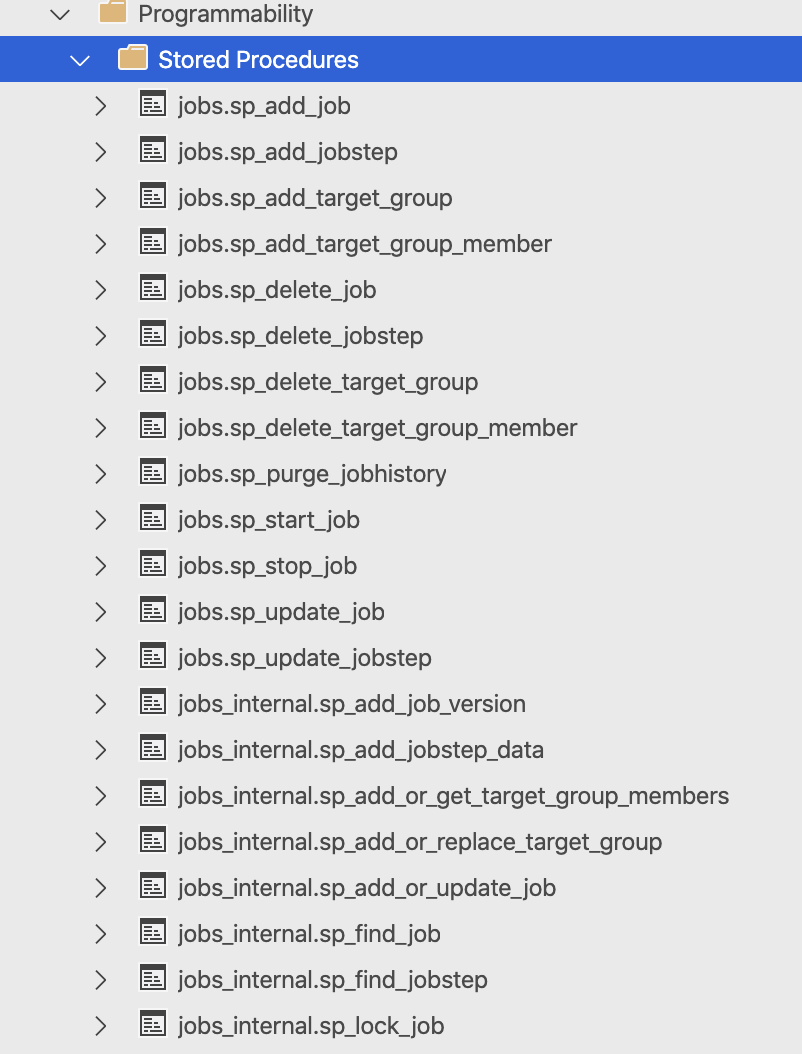 Inside the deployed Azure SQL Database you will be able to find the 13 tables (one of them is kind-of marked as an extra-internal in a special way with 2 underscores :) ), 13 Views and 21 Stored Procedures that will strongly remind you on the similar features available in SQL Server Agent.
Inside the deployed Azure SQL Database you will be able to find the 13 tables (one of them is kind-of marked as an extra-internal in a special way with 2 underscores :) ), 13 Views and 21 Stored Procedures that will strongly remind you on the similar features available in SQL Server Agent.
In my opinion, the names are clear and self-explanatory
According to the information, inside the [jobs_internal].[__MigrationHistory] table, the current version of the Elastic Jobs is a 7.2.1 which was last update in June of 2018, making it well over 2 years since the last update, but the initial release was marked as version 4.0.0 and was launched on the 30th of May of 2016, while the product itself (Elastic Job Agent) at the moment is marked with the version 6.1.3.
One of the key things I love about this incarnation of the Job Management is the versioning – the versions are not only recorded in the system tables, but we can also execute a specific version of the job and for that purpose there is a parameter with a version number for the jobs.sp_start_job Stored Procedure.
Other little gems are forcing the Job deletion with a parameter @force for the jobs.sp_delete_job Stored Procedure – no more canceling each of the steps of the job, stopping it apart and only then removing it & of course the definition of the maximum parallelism of the particular Job Step with the parameter @max_parallelism for the [jobs].[sp_add_jobstep] Stored Procedure.
The Key Element to be understood
They key feature that needs to be well understood and which points to the potential of the Elastic Job Agent is that you are in no way limited by your own Azure SQL Database, nor by the logical Azure SQL Server where this database is located (contrary to the MSDB Database on the SQL Server), nor will you be limted by the Azure Region, Azure Resource Group or even Azure Subscription – you can configure the Elastic Job that will be reaching out to potentially any Azure SQL Database (given the necessary settings & permissions are correctly configured).
The Setup
There are countless blog posts written in the 4 years since the initial preview offering and I won’t be re-inventing the wheel here, so let’s log into the created database and create a master key with 2 database scoped credentials, so the Azure Elastic Agent service can function without any freaction:
CREATE MASTER KEY
ENCRYPTION BY PASSWORD='6MICubW9FM1Ao^ZDKmSeuFvzmNV8#81';
GO
CREATE DATABASE SCOPED CREDENTIAL dbJob WITH IDENTITY = 'dbJob',
SECRET = 'VGEM29J?2(j]MNJa';
GO
CREATE DATABASE SCOPED CREDENTIAL dbmaster WITH IDENTITY = 'dbmaster',
SECRET = 'nA7x&rZngdD&?4@243gd';
GO
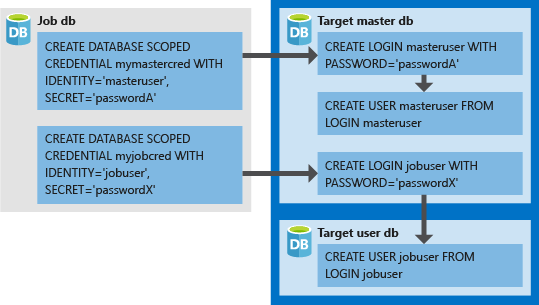 The reason for creation of the 2 credentials is presented on the picture on the left, those will serve for accessing the MASTER and USER database on the target server(s). The next step would be the creation of the respective logins on the master database of the target server (Serverless/Hyperscale/Elastic Pools as the alternatives)
The reason for creation of the 2 credentials is presented on the picture on the left, those will serve for accessing the MASTER and USER database on the target server(s). The next step would be the creation of the respective logins on the master database of the target server (Serverless/Hyperscale/Elastic Pools as the alternatives)
CREATE LOGIN [dbmaster]
WITH
PASSWORD = N'nA7x&rZngdD&?4@243gd';
GO
CREATE USER [dbmaster]
FOR LOGIN [dbmaster];
GO
CREATE LOGIN [dbJob]
WITH
PASSWORD = N'VGEM29J?2(j]MNJa';
GO
And in each target user database we need to create a respective user for the [dbJob] login, assigning it respective necessary privileges (note: I am using here db_owner, but if you are just reading some data, assign db_reader or go more granular with just a specific table/stored procedure/function:
CREATE USER [dbJob] FOR LOGIN [dbJob]; GO ALTER ROLE db_owner ADD MEMBER dbJob;
Well, that’s about it for the most of the part – now we can start with configuring the more interesting parts – Target Groups, Jobs & Job Steps.
Let us add a new Target Group, which will serve as a logical grouping of the conjunction of the servers/databases to be targeted by the Job Steps. I will call my group S1, but you should do something meaningful, such as Maintenance Group or Client X:
EXEC jobs.sp_add_target_group N'S1';
Let’s add a first target member, which can either be a SQL Database or a full logical Azure SQL Server including all the databases (do not forget to create the users with respective permissions for each of them) or an Elastic Pool.
In this case I will add a random test database called ‘whatevernikotests’ and the server is ‘supersecretazuresrvr’
EXEC jobs.sp_add_target_group_member @target_group_name = N'S1',
@target_type = 'SqlDatabase',
@database_name = 'whatevernikotests',
@server_name='supersecretazuresrvr.database.windows.net'
cool
For this function we can also refresh the list of the databases with the help of the respective parameter @refresh_credential_name=’dbinsights’ if we are target a logical Azure SQL Server.
In any case we can always consult what Target Groups and Group Members are configured through 2 respective Views, jobs.target_groups and jobs.target_group_members:
SELECT *
FROM jobs.target_groups tg
INNER JOIN jobs.target_group_members mb
ON tg.target_group_id = mb.target_group_id
ORDER BY tg.target_group_name, mb.server_name, mb.database_name;
Time to create our first Job, which will be called ResultsJob, because as you know, everybody wants the results :)
EXEC jobs.sp_add_job @job_name ='ResultsJob',
@description='Because everyone wants the results',
@schedule_interval_type='once',
@enabled = 1
In that stored procedure jobs.sp_add_job we can also specify the repeating job or the schedule start and end time with the parameters indicated below:
[ , [ @schedule_interval_type = ] schedule_interval_type ] [ , [ @schedule_interval_count = ] schedule_interval_count ] [ , [ @schedule_start_time = ] schedule_start_time ] [ , [ @schedule_end_time = ] schedule_end_time ]
In the granularity @schedule_interval_type, we can choose from “once” to “minutes” or even “months”, the @schedule_interval_count can go from NULL (non-repetitive) to 1 or bigger integer numbers.
To consult the configured job, consult the view jobs.jobs and for its respective versioning use the following statement:
SELECT [job_name]
,[job_id]
,[job_version]
FROM [jobs].[job_versions]
ORDER BY job_name, job_version;
Time to add a Job Step, which will allow us to specify the details of the execution, such as the command type, the command itself, the Target Group and even more :)
Let’s add a hypothetical statistics update to all our tables in the user databases, forcing no retries, should it fail
EXEC jobs.sp_add_jobstep
@job_name ='ResultsJob',
@command = N'EXECUTE sp_updatestats',
@credential_name = 'dbJob',
@target_group_name= 'S1',
@retry_attempts = 0;
Notice that we are specifying the Target Group name and through this level of abstraction we can easily add more or remove some of the servers that will receive this treatment.
In reality this function (as well as the one that allows to update the Job Steps job.sp_update_jobstep) allows to specify so many details, such as if we are using T-SQL at all (the alternatives are not documented), command source (not documented, but maybe Stored Procedures or are there hopes for packages inside the SSISDB :)), many retry details (delay, number of attempts, back off multiplier) Step Timeout and even significantly more.
All we need to do is to execute the job with the help of the Stored Procedure jobs.sp_start_job:
EXEC jobs.sp_start_job 'ResultsJob'
If we are having different jobs, we might want to filter on the job name and/or execution start times, but here is a plain script to get you started – the key for me have always been the last_message column:
SELECT last_message, [job_execution_id]
,[job_name]
,[job_id]
,[job_version]
,[step_name]
,[step_id]
,[is_active]
,[lifecycle]
,[create_time]
,[start_time]
,[end_time]
,[current_attempts]
,[current_attempt_start_time]
,[next_attempt_start_time]
,[target_type]
,[target_id]
,[target_subscription_id]
,[target_resource_group_name]
,[target_server_name]
,[target_database_name]
,[target_elastic_pool_name]
FROM jobs.job_executions
WHERE job_name = 'ResultsJob'
ORDER BY start_time DESC;
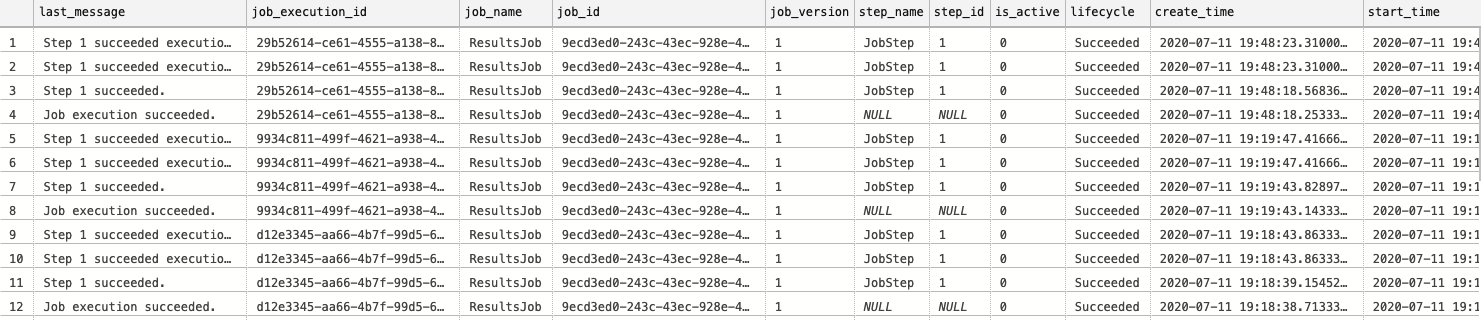
You can see at the SELECT list that we have a lot of important details on the servers against which this script was executed as well as the retry attempts and more.
Please also notice the [job_execution_id] column – it is absolutely essential and later in this post you will understand why.
If you are interested in seeing the active jobs which are running right now just add the following predicate to the query – active = 1:
SELECT last_message, [job_execution_id]
,[job_name]
,[job_id]
,[job_version]
,[step_name]
,[step_id]
,[is_active]
,[lifecycle]
,[create_time]
,[start_time]
,[end_time]
,[current_attempts]
,[current_attempt_start_time]
,[next_attempt_start_time]
,[target_type]
,[target_id]
,[target_subscription_id]
,[target_resource_group_name]
,[target_server_name]
,[target_database_name]
,[target_elastic_pool_name]
FROM jobs.job_executions
WHERE active = 1
ORDER BY start_time DESC, step_id;
In the junior DBA imagination the job output will be very easy, but the reality of the Elastic Agent Jobs is a little bit different and for that purpose let us focus on a particular execution:
SELECT last_message, * FROM jobs.job_executions WHERE job_name = 'ResultsJob' AND job_execution_id = '29b52614-ce61-4555-a138-8ded6298c6b0' ORDER BY start_time DESC
![]()
If you have ever included the results of each of the Job step in the output – you will realize that you are looking at the similar information, but notice that if you would add more databases/servers to your Target Group, you will have an additional line with the output for each of them.
Job Ownership & Execution
Unless you are new to SQL Server or you have been living under the rock – one can’t manage SQL Agent Jobs between users reasonably, and if you want to give a reasonable permission for it – the “reasonable” choice of no alternative is a SYSADMIN.
And so here is a BIG QUESTION – Can we give permission, maybe the 8th version will bring it to us ?
Right now there is a new role jobs_reader that allows to SELECT the data from the [jobs] schema tables. Yeah, that’s it as for the security…
No, I am not holding my breath, but hey, this is a cloud and so we can at least hope (Cloud First, you know…) that someone capable can make this basic security feature work one day.
A bit beyond basics
The thing I do not see a lot of people blogging about is that you can actually output the result of the job into a table.
The function jobs.sp_add_jobstep supports multiple parameters for specifying the destination of the output – which of course will have to be Azure SQL Database.
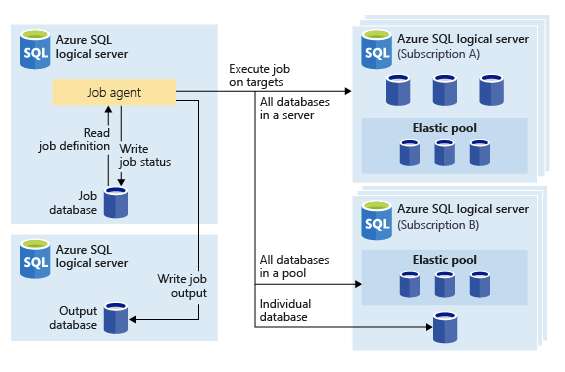
This functionality allows us to store the results obtained from the Target Groups and seamlessly integrate our data where we need it.
I recommend to use a different database for landing the output data, in order to keep from the potential conflicts with hopefully new developments of the Azure Elastic Jobs, and of course because you might want to separate your Scheduling activities from security AND performance perspectives from your real data.
Let’s collect the sizes of the tables in our target databases with the following statement:
SELECT @@SERVERNAME + '.database.windows.net' as ServerName, DB_NAME() DatabaseName, schema_name(schema_id) as SchemaName, obj.name as TableName, SUM(reserved_page_count) * 8.0 / 1024 as SizeInMB
FROM sys.dm_db_partition_stats dmdb
INNER JOIN sys.objects obj
ON dmdb.object_id = obj.object_id
GROUP BY obj.name
ORDER BY SUM(reserved_page_count) * 8.0 / 1024 DESC;
and for storing the data on our new Azure SQL Database “destination” (which I have called ‘superdata’) let’s create a new table:
CREATE TABLE [dbo].[TableSizes]( [ServerName] [nvarchar](149) NULL, [DatabaseName] [nvarchar](128) NULL, [SchemaName] [nvarchar](128) NULL, [TableName] [sysname] NOT NULL, [SizeInMB] [numeric](27, 6) NULL ) ;
Let’s update the created Step 1 with the new T-SQL statement
EXEC jobs.sp_update_jobstep
@job_name='ResultsJob',
@step_id = 1,
@command= N'SELECT @@SERVERNAME + ''database.windows.net'' as ServerName, DB_NAME() DatabaseName, schema_name(obj.schema_id) as SchemaName, obj.name as TableName, SUM(reserved_page_count) * 8.0 / 1024 as SizeInMB
FROM sys.dm_db_partition_stats dmdb
INNER JOIN sys.objects obj
ON dmdb.object_id = obj.object_id
GROUP BY obj.name, schema_name(obj.schema_id)
ORDER BY SUM(reserved_page_count) * 8.0 / 1024 DESC;',
@credential_name='dbJob',
@target_group_name='S1',
@output_type='SqlDatabase',
@output_credential_name='dbJob',
@output_server_name='supersecretazuresrvr.database.windows.net',
@output_database_name='superdata',
@output_schema_name = 'dbo',
@output_table_name='TableSizes',
@retry_attempts = 0;
Executing the update job has never been easier (with t-sql that is):
EXEC jobs.sp_start_job 'ResultsJob';
and viewing the result gives a little (A LITTLE) bit of surprise:
SELECT last_message, * FROM jobs.job_executions WHERE job_name = 'ResultsJob' ORDER BY start_time DESC;

delivering us the bad news that we are missing some strange column named ‘internal_execution_id’:
Writing result set failed (server 'supersecretazuresrvr.database.windows.net', database 'superdata table '[dbo].[TableSizes]'): Column name 'internal_execution_id' does not exist in the target table or view. (Msg 1911, Level 16, State 1, Line 3)
Remember when in the text above I said that it was important to notice the [job_execution_id] column ?
That’s the one that is called here with the name [internal_execution_id].
For correcting the situation, on our destination database, let’s recreate the table TableSizes with the new code, adding internal_execution_id UNIQUEIDENTIFIER column:
DROP TABLE [dbo].[TableSizes];
CREATE TABLE [dbo].[TableSizes](
[internal_execution_id] UNIQUEIDENTIFIER NULL,
[ServerName] [nvarchar](149) NULL,
[DatabaseName] [nvarchar](128) NULL,
[SchemaName] [nvarchar](128) NULL,
[TableName] [sysname] NOT NULL,
[SizeInMB] [numeric](27, 6) NULL
) ON [PRIMARY]
GO
This time we have a full success!

And so remember, you will need to create your tables accordingly … or you can simply specify a non-existing table and it will be created by the Azure Elastic Job Agent! :)
I love the idea of including the reference to the Job Step Execution Id, thus creating a basic lineage for the output of the Elastic Job Agent.
DID NOT WE ALL WAITED FOR AN AZURE-BASED SCHEDULER for everything related with SQL Server ?
The one that can access potentially any Azure SQL Database, far beyond your own subscription ?
…
What should be next ?
What are the missing things about the Elastic Jobs as they are approaching the General Availability (GA)?
– Support for the Azure SQL Database Managed Instance.
– Support for the regular SQL Server, at least in Azure VMs (IaaS – Infrastructure as a Service). Given that for the customers running Azure 100% one of the main topics is the consolidation, it will give a better opportunity of delivering universal way of running
– Better Error Messaging & Troubleshooting as some scenarios are still not really complete. I have had a couple of situation where the job would declare to be executed successfully, while in reality no data was found in the output table at all. (A good example of a missing detail is the lack of the output details inside the jobs.job_executions View)
– Improved Portal Management. There will always a lot of junior Cloud Engineers or DBAs who would need to cancel, stop, delete or reschedule jobs without diving into the T-SQL and giving an interface for those operations would increase not only the exposure but also helps the final users.
– Job Permissions … Job Groups … You know … Multiple People managing multiple projects …
Final Thoughts
If you are working with PaaS SQL Databases and had to deal with Azure Automation … You have my understanding.
Let us all hope that Elastic Agent Jobs will go into GA as soon as possible and that they will have so much needed further investment and development.
The best article!!!!! My jobs finally worked!
Glad to hear that, Luciana.
Best regards,
Niko