Continuation from the previous 110 parts, the whole series can be found at https://www.nikoport.com/columnstore/.
The topic of the Segment Elimination (aka Row Group Elimination) is something that I keep on blogging on through all the years, but given that Joe Obbish has written an incredibly valuable blog post on this matter lately, I decided to touch only on the points that I feel that need some expansion – and right now, I can think of 2 of them – the OR condition and the Inter-column Search, that are true pain in the neck in the world of the Columnstore Indexes Row Group Elimination.
The Setup
Once again the test database shall be the free test database from Microsoft – ContosoRetailDW, which I shall restore from the C:\Install location:
USE [master]
alter database ContosoRetailDW
set SINGLE_USER WITH ROLLBACK IMMEDIATE;
RESTORE DATABASE [ContosoRetailDW]
FROM DISK = N'C:\Install\ContosoRetailDW.bak' WITH FILE = 1,
MOVE N'ContosoRetailDW2.0' TO N'C:\Data\SQL16\ContosoRetailDW.mdf',
MOVE N'ContosoRetailDW2.0_log' TO N'C:\Data\SQL16\ContosoRetailDW.ldf',
NOUNLOAD, STATS = 1;
alter database ContosoRetailDW
set MULTI_USER;
GO
GO
ALTER DATABASE [ContosoRetailDW] SET COMPATIBILITY_LEVEL = 130
GO
Using my favourite table FactOnlineSales, this time I shall create a limited copy of it, calling it FactOnlineSales_CCI, creating a Clustered Columnstore Index on it and optimising the Row Group Elimination for the column number 4 – the [ProductKey]:
CREATE TABLE [dbo].[FactOnlineSales_CCI](
[OnlineSalesKey] [int] NOT NULL,
[DateKey] [datetime] NOT NULL,
[StoreKey] [int] NOT NULL,
[ProductKey] [int] NOT NULL,
[PromotionKey] [int] NOT NULL,
[CurrencyKey] [int] NOT NULL,
[CustomerKey] [int] NOT NULL,
[SalesOrderNumber] [nvarchar](20) NOT NULL,
[SalesOrderLineNumber] [int] NULL,
[SalesQuantity] [int] NOT NULL,
[SalesAmount] [money] NOT NULL,
[ReturnQuantity] [int] NOT NULL,
[ReturnAmount] [money] NULL,
[DiscountQuantity] [int] NULL,
[DiscountAmount] [money] NULL,
[TotalCost] [money] NOT NULL,
[UnitCost] [money] NULL,
[UnitPrice] [money] NULL,
[ETLLoadID] [int] NULL,
[LoadDate] [datetime] NULL,
[UpdateDate] [datetime] NULL
) ON [PRIMARY]
insert into [dbo].[FactOnlineSales_CCI] with (tablock)
(OnlineSalesKey, DateKey, StoreKey, ProductKey, PromotionKey, CurrencyKey, CustomerKey, SalesOrderNumber, SalesOrderLineNumber, SalesQuantity, SalesAmount, ReturnQuantity, ReturnAmount, DiscountQuantity, DiscountAmount, TotalCost, UnitCost, UnitPrice, ETLLoadID, LoadDate, UpdateDate)
select OnlineSalesKey, DateKey, StoreKey, ProductKey, PromotionKey, CurrencyKey, CustomerKey, SalesOrderNumber, SalesOrderLineNumber, SalesQuantity, SalesAmount, ReturnQuantity, ReturnAmount, DiscountQuantity, DiscountAmount, TotalCost, UnitCost, UnitPrice, ETLLoadID, LoadDate, UpdateDate
from dbo.FactOnlineSales
WHERE OnlineSalesKey <= 32188091;
create clustered index PK_FactOnlineSales_CCI
on dbo.FactOnlineSales_CCI (ProductKey)
with (data_compression = page, maxdop = 1);
create clustered columnstore index PK_FactOnlineSales_CCI
on dbo.FactOnlineSales_CCI
with (drop_existing = on, maxdop = 1);
To verify all the details of all Segments for this column, let's issue the following query against the sys.column_store_segments DMV:
select column_id, segment_id, min_data_id, max_data_id
from sys.column_store_segments seg
inner join sys.partitions part
on seg.hobt_id = part.hobt_id and part.partition_id = seg.partition_id
where part.object_id = object_id('FactOnlineSales_CCI')
and column_id = 4;
 On the picture on the right side, you can see the distribution of the values between different Segments between 1 and 2517 for the [ProductId], between my 9 different Segments. You can also determine that there are no overlaps with the some certain values being located on the interconnections between the Segments.
On the picture on the right side, you can see the distribution of the values between different Segments between 1 and 2517 for the [ProductId], between my 9 different Segments. You can also determine that there are no overlaps with the some certain values being located on the interconnections between the Segments.
We are ready to advance now and start looking at the most serious Segment Elimination Problems for the Columnstore Indexes.
The Painful OR condition
At the moment of the writing of this article, I do not remember of any more painful limitation for the Row Group elimination, other than the usage of the OR condition.
First of all let's take for the test the overall usage of the OR criteria with a simple query, but even before that let's execute the simplest search query with one equality predicate:
set statistics io on SELECT SUM([SalesAmount]), MAX(StoreKey) FROM dbo.FactOnlineSales_CCI sales WHERE (ProductKey = 2000);
Table 'FactOnlineSales_CCI'. Scan count 1, logical reads 0, physical reads 0, read-ahead reads 0, lob logical reads 253, lob physical reads 0, lob read-ahead reads 0. Table 'FactOnlineSales_CCI'. Segment reads 1, segment skipped 8.
As expected for a simple predicate that we have specified, the Query Optimiser processed just 1 Segment, because other Segments do not contain comparable results. Everything is fine here, right? :)
Now, let's use 2 equality searches and see what happens - the expectation here is that only 2 Row Groups will be processed, since we have aligned all segments and that Segment with ID = 3 is the one that will correspond to this equality search.
set statistics io on SELECT SUM([SalesAmount]), MAX(StoreKey) FROM dbo.FactOnlineSales_CCI sales WHERE (ProductKey = 2000 OR ProductKey = 1000)
This query produces the following IO results: we read 3 Row Groups, while skipping 6 - the Row Group Elimination works in a ... unexpected way!
Table 'FactOnlineSales_CCI'. Scan count 1, logical reads 0, physical reads 0, read-ahead reads 0, lob logical reads 1307, lob physical reads 0, lob read-ahead reads 0. Table 'FactOnlineSales_CCI'. Segment reads 3, segment skipped 6.
Do dive deeper, lets install and start the Extended Events session from the CISL library - cstore_XE_RowGroupElimination:
Watching the elimination results will give you the confirmation that as a matter of a fact, 3 Segments with IDs 3,4,5 were processed, but this raises a big question - what did this happen ?
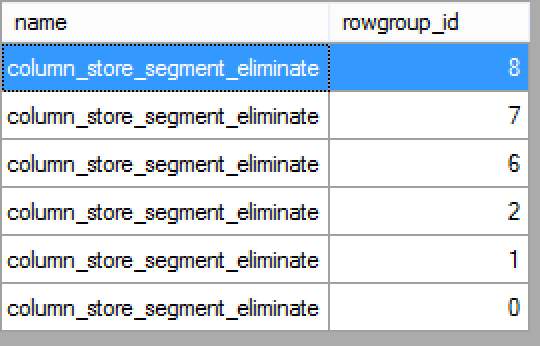
Let me share with you my guess: "The Segment Elimination in this case works as a range scan between the minimum (1000) and the maximum values (2000)", because the Segments 3, 4 & 5 are the ones which are overlapping with this scale of values.
Following this theory I will execute a simple variation of the query, but this time setting the second parameter search equals to the 0 - thus expecting that it will scan the Segments between 0 and 5:
set statistics io on SELECT SUM([SalesAmount]), MAX(StoreKey) FROM dbo.FactOnlineSales_CCI sales WHERE (ProductKey = 2000 OR ProductKey = 0);
and (drumroll) - voilá!:
Table 'FactOnlineSales_CCI'. Scan count 1, logical reads 0, physical reads 0, read-ahead reads 0, lob logical reads 2669, lob physical reads 0, lob read-ahead reads 0. Table 'FactOnlineSales_CCI'. Segment reads 6, segment skipped 3.
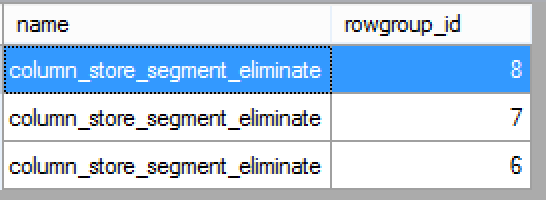
As expected, unfortunately, it seems that the OR will scan all possible values in the range, instead of doing an intelligent comparison (Insert a very big frown here - :().
To solve this, you can re-write your OR condition into something similar, where every single search functions separately (yes, there will be few cases where it will be doable):
set statistics io on SELECT SUM([SalesAmount]), MAX(StoreKey) FROM ( SELECT SUM([SalesAmount]) as [SalesAmount], MAX(StoreKey) as StoreKey FROM dbo.FactOnlineSales_CCI sales WHERE (ProductKey = 2000) UNION ALL SELECT SUM([SalesAmount]) as [SalesAmount], MAX(StoreKey) as StoreKey FROM dbo.FactOnlineSales_CCI sales WHERE ( ProductKey = 0) ) res
The somewhat risky results are presented below. They are risky, because if other conditions will require a full scan, this way will instantly become a very unproductive:
Table 'FactOnlineSales_CCI'. Scan count 2, logical reads 0, physical reads 0, read-ahead reads 0, lob logical reads 253, lob physical reads 0, lob read-ahead reads 0. Table 'FactOnlineSales_CCI'. Segment reads 1, segment skipped 17.
Still this gives us processing of just 1 Segment with 253 lob logical reads vs 6 Segments and 2669 lob logical reads in the original query.
But wait, that's not all! It can get significantly worse!
Let's use the inequality search with the OR condition, to see what happens - should be safe, right ?
set statistics io on SELECT SUM([SalesAmount]), MAX(StoreKey) FROM dbo.FactOnlineSales_CCI sales WHERE (ProductKey > 2000 OR ProductKey < 0)
Table 'FactOnlineSales_CCI'. Scan count 1, logical reads 0, physical reads 0, read-ahead reads 0, lob logical reads 3206, lob physical reads 0, lob read-ahead reads 0. Table 'FactOnlineSales_CCI'. Segment reads 9, segment skipped 0.
Yes, you have seen it right, instead of reading just 4 Segments, according to the value distribution, this query will scan all of the segments without a need.
This is a really bad situation, as far as I am concerned, and I am filing this bug to the Connect during this week.
The one positive thing to add is of course if we have a better AND predicate, it will be helping to eliminate Row Groups, for example the following query will deliver no results while reading no Row Groups, because there are no such rows with SalesAmount > 10000.:
set statistics io on SELECT SUM([SalesAmount]), MAX(StoreKey) FROM dbo.FactOnlineSales_CCI sales WHERE (ProductKey = 2000 OR ProductKey = 0) AND (SalesAmount > 10000.);
Inter-column Search
The comparison/search between the columns of the same table is something where Columnstore Indexes have a serious problem, because it seems to me being not implemented.
Let us run a simple query with 3 aggregates against our FactOnlineSales_CCI table, comparing the [StoreKey] (integer) with [ProductKey] columns.
SELECT SUM(SalesAmount), MAX(sales.ProductKey), MIN(sales.ProductKey) FROM dbo.FactOnlineSales_CCI sales WHERE sales.StoreKey = sales.ProductKey

The execution plan above is very self-explainatory, the Filter iterator does all the job of doing the search, and the Columnstore Index Scan gets no Predicate Pushdown, nor can it do Row Group elimination.
For the RowStore tables, this part functions pretty simple with a predicate being pushed down to the Storage Engine:
SELECT SUM(SalesAmount), MAX(sales.ProductKey), MIN(sales.ProductKey) FROM dbo.FactOnlineSales sales WHERE sales.StoreKey = sales.ProductKey

While naturally we have a different execution plan here with a Stream Aggregate, the story does not need further study, the number of rows coming out of our 12.6 Million Rows table is very small, because it is being filtered within the scan operation.
We can execute here not only the equality search (=), but also the non-equality one (< or >, for example), but the result will stay the same - the Columnstore Index Scan will not push the predicate into the engine and hence the Row Group elimination will not function.
Thoughts
There are a lot of limitations in every technology or solution, but those 2 are the biggest ones that I know off and I hope that I was able to share them with the reader.
to be continued with Columnstore Indexes – part 112 (“Linked Servers”)
Creating Column store index with maxdop option as 1 and the index will created after the clustered index with drop existing on will not be completed in environments that holds 6 billions rows. Mean while when ever any solution provided to the audience, we need to consider the volume of data, storage, execution time. I tries your approaches it wont fit for us.
Hi Kannan,
agreed!
I do not use this approach everywhere. First of all if you are running a table with 6 Billion Rows you must be using partitioning and for that case you might be able to execute this operation on a partition level.
I wish that Microsoft would finish implementing the internal option of allowing us to do that on SQL Database & Sql Server. My connect item is pretty old …
Best regards,
Niko
Dear Niko, Thanks for your response. you are Correct, we already partitioning our data based on the date column and the volume of the single partition contains a maximum of 450 million rows and our table size would be 1.2 TB of size. We are the one who is consuming largest volume of data because ours is a healthcare database.At non clustered column store index i noticed the segment skipped similar to the column store index but the number of skipped is more in clustered column store. Even though few of the stored procedure took a hour delay in execution for clustered column store index when compared to non clustered column store, In non clustered column store few SP took 100% cpu and never completed its execution even 3 or 4 days. I noticed the root cause, we used >= and <= conditions in date columns(partitioned columns) with additional 'in' conditions as well, these works well in clustered column store when compared to non clustered column store. Few stored procedures took same amount of duration for its execution. We also faced Legacy carnality estimation problem in 2016 version of SQL server, but this clustered column store can fill the gap but Microsoft should improve their partition strategy similar to Oracle for supporting composite partitioning fixing LCE issues without making code changes.
Hi Kannan,
I totally agree on the need of the partitioning improvement need for the SQL Server.
Besides the automated (range) partitioning, the better partition-elimination, read-only partition support, and finally the partition-based statistics are incredibly needed.
I can only hope that post – SQL Server 2019 development will start bringing the partition improvements / features for bigger scenarios.
Best regards,
Niko
Thank you for this post, Niko! It’s very informative.
What I’m wondering, though, is whether this use case serves as a reason to NOT align your columnstore segments, as suggested by Emanuele Meazzo?
Hi Eitan,
I blogged my view on this in the Columnstore Indexes – part 110 (“The best column for sorting Columnstore Index on”) in 2017 and CISL contains a function cstore_getAlignment that will allow to determine the best function for this purpose.
I do not see a lot of downsides, besides the work necessary to rebuild the Columnnstore Indexes. Naturally, if you are ordering on the column that does not support it or does not use this ordering – well … :)
Best regards,
Niko