Continuation from the previous 76 parts, the whole series can be found at https://www.nikoport.com/columnstore/
I have written previously about SQL Server Integration Services and their interaction with Columnstore Indexes in Columnstore Indexes – part 51 (“SSIS, DataFlow & Max Buffer Memory”), but for a long time I was looking to revisit the chapter of the communication with SSIS because of one important improvement that we have received in SQL Server 2016 – the better possibility to control the amount of of memory available to the DataFlow buffer.
Summarising the biggest problem of SQL Server 2014 in relation to SSIS & Clustered Columnstore Indexes was the fact that we could not allocate more then 100 MB per dataflow buffer, thus potentially limiting the actual size of the row groups, should 1048576 rows need more than 100 MB of RAM.
In SQL Server 2016 we have an option that allows to auto adjust the size of the data flow buffer, and together with the setting for the default dataflow buffer max rows we can control what we need to make columnstore work.
For the test I am picking up the inevitable free test database ContosoRetailDW from Microsoft, which I will restore from the downloaded backup that was copied into C:\Install folder:
USE [master]
alter database ContosoRetailDW
set SINGLE_USER WITH ROLLBACK IMMEDIATE;
RESTORE DATABASE [ContosoRetailDW]
FROM DISK = N'C:\Install\ContosoRetailDW.bak' WITH FILE = 1,
MOVE N'ContosoRetailDW2.0' TO N'C:\Data\ContosoRetailDW.mdf',
MOVE N'ContosoRetailDW2.0_log' TO N'C:\Data\ContosoRetailDW.ldf',
NOUNLOAD, STATS = 5;
alter database ContosoRetailDW
set MULTI_USER;
GO
GO
ALTER DATABASE [ContosoRetailDW] SET COMPATIBILITY_LEVEL = 130
GO
ALTER DATABASE [ContosoRetailDW] MODIFY FILE ( NAME = N'ContosoRetailDW2.0', SIZE = 2000000KB , FILEGROWTH = 128000KB )
GO
ALTER DATABASE [ContosoRetailDW] MODIFY FILE ( NAME = N'ContosoRetailDW2.0_log', SIZE = 400000KB , FILEGROWTH = 256000KB )
GO
Let’s create a Clustered Columnstore Index on the source table FactOnlineSales, while dropping the previous primary key:
use ContosoRetailDW; ALTER TABLE dbo.[FactOnlineSales] DROP CONSTRAINT [PK_FactOnlineSales_SalesKey]; create clustered columnstore Index PK_FactOnlineSales on dbo.FactOnlineSales;
The next step is to create a test table with a Clustered Columnstore Index that resembles the original source table FactOnlineSales, I will call it FactOnlineSales_SSIS:
CREATE TABLE dbo.FactOnlineSales_SSIS(
[OnlineSalesKey] [int] NOT NULL,
[DateKey] [datetime] NOT NULL,
[StoreKey] [int] NOT NULL,
[ProductKey] [int] NOT NULL,
[PromotionKey] [int] NOT NULL,
[CurrencyKey] [int] NOT NULL,
[CustomerKey] [int] NOT NULL,
[SalesOrderNumber] [nvarchar](20) NOT NULL,
[SalesOrderLineNumber] [int] NULL,
[SalesQuantity] [int] NOT NULL,
[SalesAmount] [money] NOT NULL,
[ReturnQuantity] [int] NOT NULL,
[ReturnAmount] [money] NULL,
[DiscountQuantity] [int] NULL,
[DiscountAmount] [money] NULL,
[TotalCost] [money] NOT NULL,
[UnitCost] [money] NULL,
[UnitPrice] [money] NULL,
[ETLLoadID] [int] NULL,
[LoadDate] [datetime] NULL,
[UpdateDate] [datetime] NULL
);
create clustered columnstore index CCI_FactOnlineSales_SSIS
on dbo.FactOnlineSales_SSIS;
For the data loading you will need to have Visual Studio and SSDT installed – I will be using Visual Studio 2015 for the purpose of the test, but to my understanding those settings should function in Visual Studio 2013 as well.
Once again I have created a simple package with 2 elements in the Control Flow: an Execute SQL Task that will truncate the destination table and a DataFlow Task that has 2 elements – and OleDB Source and a OleDB Destination for transferring data from the original source to the test table:

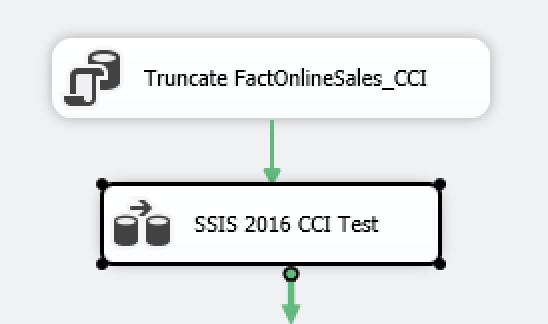
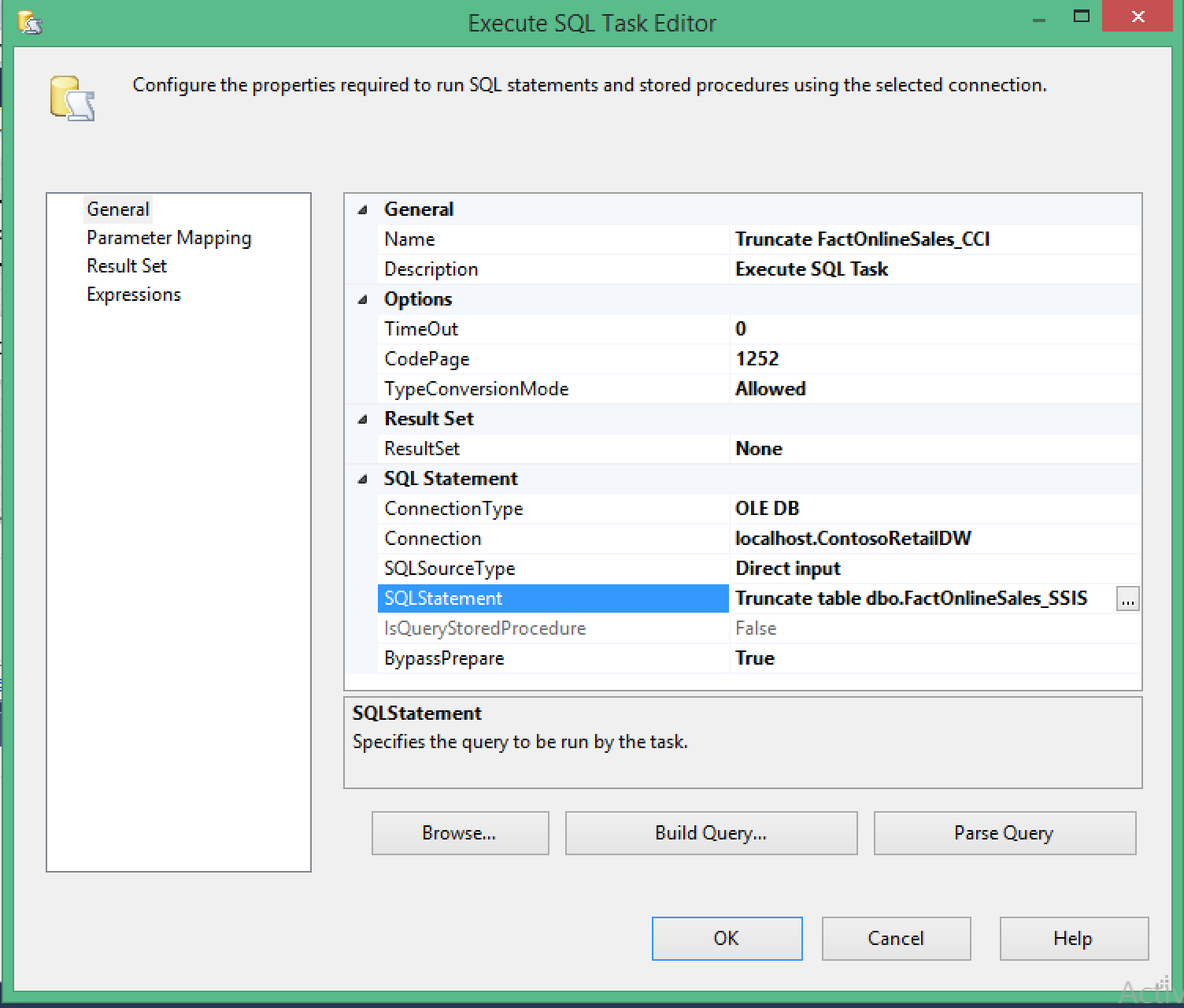
I have configured the OleDB Connection to point at my freshly restored ContosoRetailDW database and I have added a truncation command for the destination table:

The first test was of course the one with all default settings (coughing carefully … DefaultBufferMaxRows is set to 10000 rows in SSIS 2016)
The default settings execution took nothing less then 5 minutes and 34 seconds on my test VM. For ~12.6 Million Rows that’s a recipe for a total disaster.
To check on the results I have used the CISL function dbo.cstore_GetRowGroups:
exec dbo.cstore_GetRowGroups;
![]()
This result shows that we have not received small Row Groups, which would require us to rebuild the table/partition – and these are definitely good news, but the speed is of the operation is something that leaves the desire for further improvements.
I decided not to give up and activated the promised setting of AutoAdjustBufferSize which should automatically adjust the size of the DataFlow up to 2 GB – 1 byte:
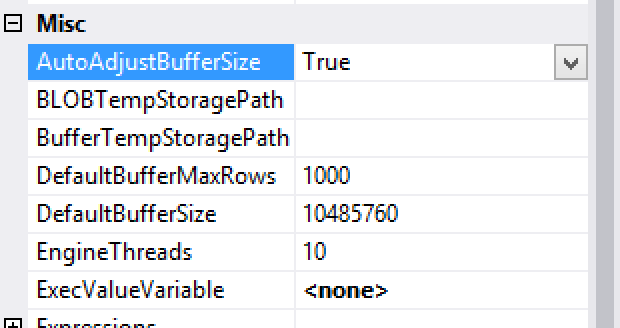
With 4:35 Minutes this result was a rather small improvement. Of course you will need to add at least 15 seconds per each of the Row Groups, so the efficiency of this method is very questionable.
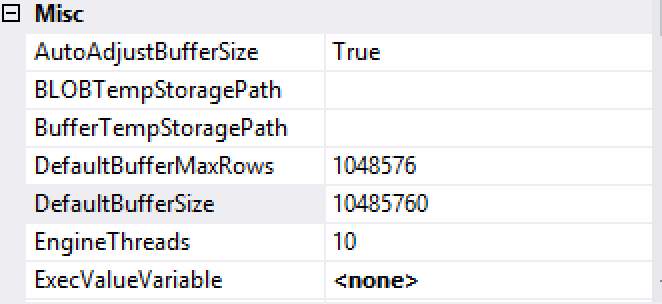 To solve the performance problem I went straight to the DefaultBufferMaxRows setting and set it to be equal of the maximum number of rows in a Row Group – 1048576. Together with the AutoAdjustBufferSize setting it helps the actual current size of the DataFlow Buffer that will be used for transferring the data from the source to the destination table.
To solve the performance problem I went straight to the DefaultBufferMaxRows setting and set it to be equal of the maximum number of rows in a Row Group – 1048576. Together with the AutoAdjustBufferSize setting it helps the actual current size of the DataFlow Buffer that will be used for transferring the data from the source to the destination table.
What should I say – it worked like magic:
I guess that with 2:09 Minutes the clear winner of this test is the configuration with AutoAdjustBufferSize set to True and the DefaultBufferMaxRows to 1048576. It took less then a half of the time with just AutoAdjustBufferSize activated and the insertion process was executed with the help of the Bulk Load API – meaning that we did not have to wait for the Tuple Mover or to execute it manually.
You can see on the picture below the difference that the right settings can make – and in this case we are considering less then 13 Million Rows
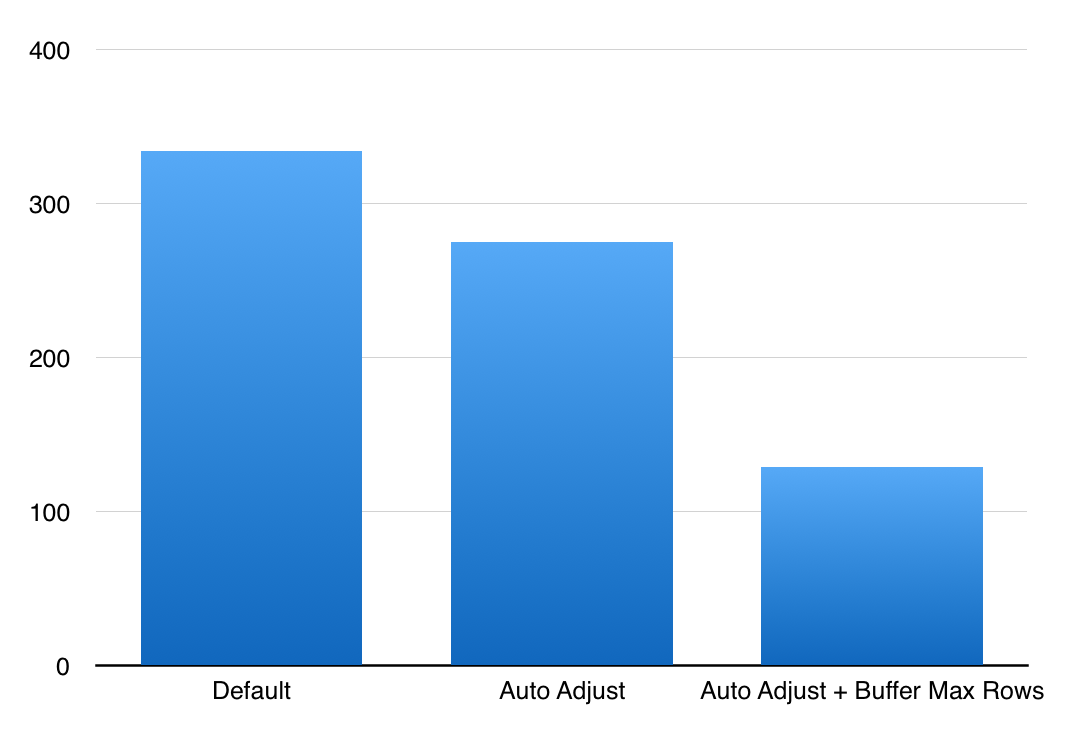
Keep in my mind that any internal pressures such as memory (when you do not have enough to process a Row Group) or the dictionary pressure (this is what you see if you put a lot of very wide strings into your fact table) are something that takes place on the engine level and can’t be controlled from SSIS or T-SQL.
to be continued with Columnstore Indexes – part 78 (“Temporary Objects”)
Hi Niko,
First off great writeup of clustered columnstores. This is something I’ve been waiting on for a long time, especially the referential integrity! Can’t wait to try it out
About the SSIS loads, do you have a comparison vs a ‘known’ minimally logged/bulk api load of the same data? eg bulk insert or BCP?
Out of interest, what did you set the max insert commit size to? And does turning on minimally logged inserts (TF610) have any effect?
How are inserts into a clustered columnstore logged?
According to the OleDb Destination page on TechNet (http://msdn.microsoft.com/en-us/library/ms188439.aspx) we have the following two settings:
Rows per batch
Specify the number of rows in a batch. The default value of this property is –1, which indicates that no value has been assigned.
Clear the text box in the OLE DB Destination Editor to indicate that you do not want to assign a custom value for this property.
Maximum insert commit size
Specify the batch size that the OLE DB destination tries to commit during fast load operations. The value of 0 indicates that all data is committed in a single batch after all rows have been processed.
A value of 0 might cause the running package to stop responding if the OLE DB destination and another data flow component are updating the same source table. To prevent the package from stopping, set the Maximum insert commit size option to 2147483647.
If you provide a value for this property, the destination commits rows in batches that are the smaller of (a) the Maximum insert commit size, or (b) the remaining rows in the buffer that is currently being processed.
^^^^^ that ‘remaining rows’ is the smallest of ‘rows per batch’, and the defaultbuffermaxrows/defaultbuffersize settings.
This is the thing that trips a lot of people up, especially with that warning about not setting it to the most performant setting – 0 (and the warning only matters if you’re running multiple bulk loads into the same table at the same time..)
I did some research on this and how it affected minimally logged inserts into b-trees a while back – http://jakubka.blogspot.com.au/2014/06/ssis-and-minimally-logged-inserts.html some might be relevant to clustered columnstores if the same architecture is used for logging
Hi, check out these 2 posts:
Clustered Columnstore Indexes – part 43 (“Transaction Log Basics”)
Clustered Columnstore Indexes – part 51 (“SSIS, DataFlow & Max Buffer Memory”)
Best regards,
Niko Neugebauer