Continuation from the previous 50 parts, the whole series can be found at https://www.nikoport.com/columnstore/
This post is dedicated to usage of one of the most important technologies in ETL space – SQL Server Integration Services and its integration with the Columnstore Indexes.
I have found that some of the aspects of Columnstore Indexes options in SSIS not very clear and thought that a detailed post on this topic might help those who are working with this technology mix.
In my current projects I am working a lot with T-SQL, way too much sometimes. :) It happens that the very first time I have touched on SSIS in combination with Clustered Columnstore Indexes was on my test VM around a week ago. I have struggled with understanding of some of the basic options, and so here are some things that I have learned:
Let’s kick of with a fresh restore of the free ContosoRetailDW database:
USE master; RESTORE DATABASE [ContosoRetailDW] FROM DISK = N'C:\Install\ContosoRetailDW.bak' WITH FILE = 1, MOVE N'ContosoRetailDW2.0' TO N'C:\Data\ContosoRetailDW.mdf', MOVE N'ContosoRetailDW2.0_log' TO N'C:\Data\ContosoRetailDW.ldf', NOUNLOAD, STATS = 5;
I will use the dbo.FactOnlineSales table with ~12.6 Million Rows as a source, creating a Clustered Columnstore Index on it, but before advancing dropping all the Foreign Keys as well as the Primary Key on it:
use ContosoRetailDW; alter table dbo.[FactOnlineSales] DROP CONSTRAINT FK_FactOnlineSales_DimCurrency; alter table dbo.[FactOnlineSales] DROP CONSTRAINT FK_FactOnlineSales_DimCustomer; alter table dbo.[FactOnlineSales] DROP CONSTRAINT FK_FactOnlineSales_DimDate; alter table dbo.[FactOnlineSales] DROP CONSTRAINT FK_FactOnlineSales_DimProduct; alter table dbo.[FactOnlineSales] DROP CONSTRAINT FK_FactOnlineSales_DimPromotion; alter table dbo.[FactOnlineSales] DROP CONSTRAINT FK_FactOnlineSales_DimStore; alter table dbo.[FactOnlineSales] DROP CONSTRAINT PK_FactOnlineSales_SalesKey; create clustered columnstore index PK_FactOnlineSales on dbo.FactOnlineSales;
This table will serve as a source for our DataFlow in SSIS, but as for the destination, I will create a new empty table with a clustered columnstore index, which shall be called FactOnlineSales_SSIS:
CREATE TABLE dbo.FactOnlineSales_SSIS(
[OnlineSalesKey] [int] NOT NULL,
[DateKey] [datetime] NOT NULL,
[StoreKey] [int] NOT NULL,
[ProductKey] [int] NOT NULL,
[PromotionKey] [int] NOT NULL,
[CurrencyKey] [int] NOT NULL,
[CustomerKey] [int] NOT NULL,
[SalesOrderNumber] [nvarchar](20) NOT NULL,
[SalesOrderLineNumber] [int] NULL,
[SalesQuantity] [int] NOT NULL,
[SalesAmount] [money] NOT NULL,
[ReturnQuantity] [int] NOT NULL,
[ReturnAmount] [money] NULL,
[DiscountQuantity] [int] NULL,
[DiscountAmount] [money] NULL,
[TotalCost] [money] NOT NULL,
[UnitCost] [money] NULL,
[UnitPrice] [money] NULL,
[ETLLoadID] [int] NULL,
[LoadDate] [datetime] NULL,
[UpdateDate] [datetime] NULL
);
create clustered columnstore index CCI_FactOnlineSales_SSIS
on dbo.FactOnlineSales_SSIS
 For the start I will create a very simple SSIS Package with just 2 simple tasks in the Control Flow – an “Executed TSQL Task” and a “Data Flow Task”. In the first one I shall simply empty the destination table by issuing the truncate table command, for ensuring that for every test that shall be executed in this blogpost, the destination table shall be empty:
For the start I will create a very simple SSIS Package with just 2 simple tasks in the Control Flow – an “Executed TSQL Task” and a “Data Flow Task”. In the first one I shall simply empty the destination table by issuing the truncate table command, for ensuring that for every test that shall be executed in this blogpost, the destination table shall be empty:
truncate table dbo.FactOnlineSales_SSIS;
and inside the Data Flow I will put just 2 elements, OLEDB Source & OLEDB Destination:
 simply reading data from the dbo.FactOnlineSales source table and without any additional operation storing it in the destination table. For the OleDB Source element, I have selected “SQL Command” as a Data Access Mode, reading just 150.000 rows from dbo.FactOnlineSales table:
simply reading data from the dbo.FactOnlineSales source table and without any additional operation storing it in the destination table. For the OleDB Source element, I have selected “SQL Command” as a Data Access Mode, reading just 150.000 rows from dbo.FactOnlineSales table:
select top 150000 *
from dbo.FactOnlineSales;
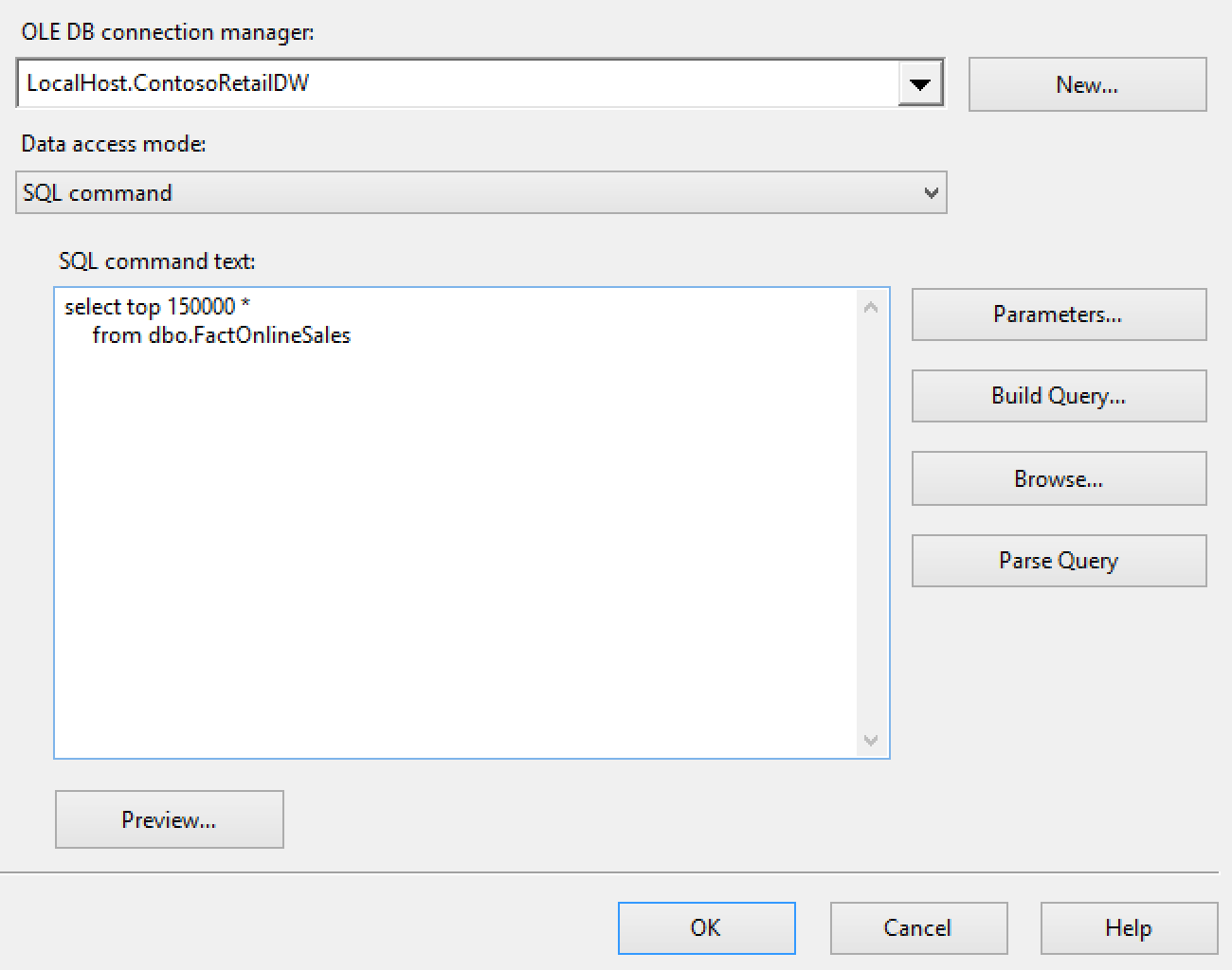 On the right side you can see how exactly my OLEDB Source properties look like. I decided not to use any advanced options, since I just wanted to see how SSIS reacts on the data transfer and if it truly works with BULK Load into Clustered Columnstore Index.
On the right side you can see how exactly my OLEDB Source properties look like. I decided not to use any advanced options, since I just wanted to see how SSIS reacts on the data transfer and if it truly works with BULK Load into Clustered Columnstore Index.
 For the OLEDB Destination properties I decided to leave them at the Defaults, since I am reading over 102.400 rows and OLEDB Destination should take care of the inserting data through BULK API, creating 1 compressed Row Group.
For the OLEDB Destination properties I decided to leave them at the Defaults, since I am reading over 102.400 rows and OLEDB Destination should take care of the inserting data through BULK API, creating 1 compressed Row Group.
Notice that I have not changed any property of the Data Flow as well, leaving all properties at the default.
For measuring the results I will use the following T-SQL query:
SELECT *
FROM sys.column_store_row_groups
WHERE OBJECT_ID = OBJECT_ID('dbo.FactOnlineSales_SSIS');
 After a couple of seconds I could observe a successful result of my package execution, and so all I needed is to verify the status of the Row Groups for the destination table, and here is the result:
After a couple of seconds I could observe a successful result of my package execution, and so all I needed is to verify the status of the Row Groups for the destination table, and here is the result:
![]() Surprise! We have got 1 open Delta-Store like if we would not have used Bulk Load API at all. Sure thing that I have not set the value for the “Rows Per Batch” property at the OLEDB Destination, nor have I changed the default value for the “Maximum Insert Commit Size” property, but I would expect the default values to work correctly for the Bulk Load for the Columnstore Index, because honestly most people using Clustered Columnstore Indexes most probably are not using the trickle inserts.
Surprise! We have got 1 open Delta-Store like if we would not have used Bulk Load API at all. Sure thing that I have not set the value for the “Rows Per Batch” property at the OLEDB Destination, nor have I changed the default value for the “Maximum Insert Commit Size” property, but I would expect the default values to work correctly for the Bulk Load for the Columnstore Index, because honestly most people using Clustered Columnstore Indexes most probably are not using the trickle inserts.
At this point I have decided to update “Maximum Insert Commit Size” property by setting it to 150000, forcing that the batch operation should happen at once at that specific number of rows. The thing is, it did not help at all. Setting “Rows Per Batch” property on any reasonable value above 102.400 rows did not help me at all – there were no changes to the final inserted result – I have always had just a simple Delta Store
At this point I have simply started to believe that there was something wrong with OLEDB Destination.
 There were still a couple of properties left, and so I configured Data Flow “Default Buffer Max Rows” property, changing it from the default value of 10.000 rows to 150.000 rows. The final result has not changed a bit, still delivering one single uncompressed Delta Store. I am confident that in a lot of cases people would simply believe that OLEDB is working in a wrong way for the Columnstore Indexes.
There were still a couple of properties left, and so I configured Data Flow “Default Buffer Max Rows” property, changing it from the default value of 10.000 rows to 150.000 rows. The final result has not changed a bit, still delivering one single uncompressed Delta Store. I am confident that in a lot of cases people would simply believe that OLEDB is working in a wrong way for the Columnstore Indexes.
There was 1 more option that I have not tried – the “Default Buffer Size” for the Data Flow, and thinking about it right now makes one really good argument about In-Memory part of the Columnstore Technology. By default the value for Buffer Size is set to 10 MB, and so I decided to pump it up until the maximum value available – to 100 MB.
![]() This time it has finally worked the way it should have – with “Default Buffer Max Rows” set to 200.000 and “Default Buffer Size” set to 100 MB, I have finally managed to insert the data into a compressed Row Group.
This time it has finally worked the way it should have – with “Default Buffer Max Rows” set to 200.000 and “Default Buffer Size” set to 100 MB, I have finally managed to insert the data into a compressed Row Group.
Great stuff! Not accessible by default for the unexperienced SSIS developers, but great stuff anyway. :) Now let’s scale it to the maximum and create our compressed Row Groups with 1045678 rows – for that all I need is to set the Data Flow property “Default Buffer Max Rows” to 1.1 Million Rows for example and then just execute the rows.
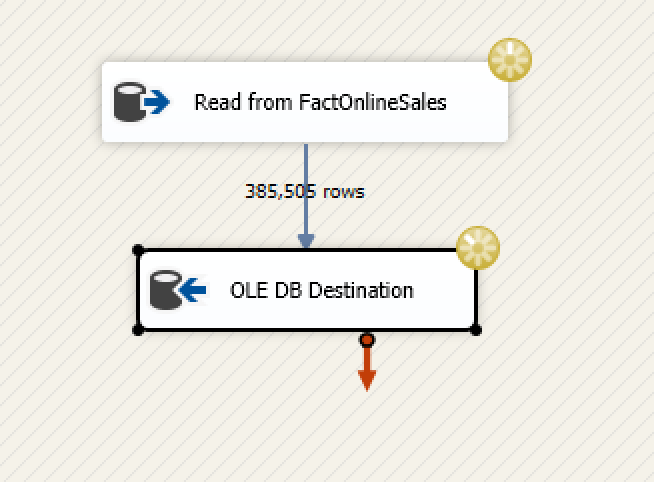 The screenshot on the left of this text shows the progress while executing inserting the data. Yes, your eyes are not lying – there are 385.505 rows per batch at a time. But – WHAT THE HECK IS GOING ON ? We have 2 million rows as the max number of rows per DataFlow, 100MB (max allowed value) of memory per DataFlow Buffer and just 385.505 rows ???
The screenshot on the left of this text shows the progress while executing inserting the data. Yes, your eyes are not lying – there are 385.505 rows per batch at a time. But – WHAT THE HECK IS GOING ON ? We have 2 million rows as the max number of rows per DataFlow, 100MB (max allowed value) of memory per DataFlow Buffer and just 385.505 rows ???
Yes. :)
Check out the final result from the Row Groups perspective:
![]() Going with the speed ~1/3 of the maximum Row Group size – this does not look good … At all !
Going with the speed ~1/3 of the maximum Row Group size – this does not look good … At all !
Updated on 24th of April 2015:
 Well, thanks to the help of David Peter Hansen, I have learned and understood better how to use SSIS.
Well, thanks to the help of David Peter Hansen, I have learned and understood better how to use SSIS.
The solution for the insertion problem lies within “Maximum Insert Commit Size” option of the OLE DB Destination component in Data Flow. Setting it to be equal to 0 (zero), will make the insertion into the destination table to be delivered in a Single Batch, allowing to reach the maximum allowed number of rows per Row Group.

This information made me rediscover the famous Data Loading Performance Guide and re-read it again.
Take this, modern In-Memory technology aligned with an amazing Tech that has not had an update for the last 3 years. The issue in this very case is the width of the row and the 100 MB Buffer size limit. There is no dictionary pressure, if you look at the previous blog posts you will see that I have created maximum sized Row Groups on this very FactOnlineSales table countless times. The Row Length at SQL Server is 158 bytes divided between 21 columns, this is absolutely nothing special for the modern fact tables, and yet you can’t reach for the maximum allowed size for a Row Group if you are using DataFlow inside SSIS, loading directly into a table with Clustered Columnstore Index.
In the modern times of In-Memory Technologies and current hardware prices and developments, it is below reasonable to maintain the limit of 100MB per Data Flow Buffer.
This is the best argument that I have against loading data directly a table with Clustered Columnstore Index with SSIS, something that does not happen, if you are using T-SQL, like for situations when transferring data from Staging into DataWareHousing tables.
Please do not ignore this issue just because at the moment your Fact table is actually smaller and you are getting the perfect Row Groups, once you add an extra column, you are risking to change this situation in the middle of development cycle where any architectural change is too late.
ODBC Source
 If you are brave enough to use ODBC source or destination, then there are more limitations for you: if you are choosing ODBC Source and select direct Table Name access then you shall face the following error message that will explain you that Cursors are not supported on a table with a Clustered Columnstore Index:
If you are brave enough to use ODBC source or destination, then there are more limitations for you: if you are choosing ODBC Source and select direct Table Name access then you shall face the following error message that will explain you that Cursors are not supported on a table with a Clustered Columnstore Index:
[ODBC Source [80]] Error: Open Database Connectivity (ODBC) error occurred. state: '42000'. Native Error Code: 35370. [Microsoft][ODBC Driver 11 for SQL Server][SQL Server]Cursors are not supported on a table which has a clustered columnstore index.
The same problem shall occur if you will opt to go for a SQL Command, which is basically like saying – No, you can’t use ODBC for tables with Clustered Columnstore Indexes. How nice is it, since Microsoft is recommending to use ODBC instead of OLEDB for any future projects.
Dear Microsoft SQL Server Integration Team – FIX those things as soon as possible and fix them not only for the future releases but for SQL Server 2014.
to be continued with Clustered Columnstore Indexes – part 52 (“What’s new for Columnstore XE in SQL Server 2014 SP1”)
To answer your question about what is going on:
The buffer manager in the data flow engine can only fit 385,505 rows into a single 100 MB buffer for your execution tree. It lowers the number of rows from default buffer max rows from 1.1 million rows to that number, to make sure the in-row data can fit into the buffer.
What I believe you are experiencing is that the OLE DB destination is committing after each buffer (not batch, as you write). This is because when maximum insert commit size is set to >0 and larger than the number of rows in the buffer profile for that particular execution tree, it will do a commit after each of the buffers (and not after each maximum insert commit size). If the maximum insert commit size is set to >0 and less than the number of rows in the buffer profile for that particular execution tree, then it will do a commit after each maximum insert commit size and after each buffer.
However, if you set the maximum insert commit size to 0, then it will do a single commit. While I have not tested it with column store indexes, I believe this might solve your problem.
I do not understand your argument against having the maximum value of DefaultBufferSize set to 100MB. The data flow engine uses multiple buffers (maximum 5 per execution tree, due to the basic back pressure mechanism (which is a good thing) – but a typical data flow have multiple execution trees). I assume you don’t want first all of your data to be read from the source into a single buffer, before it will start writing that to the destination?
Let me know if setting the maximum insert commit size to 0 doesn’t work, then I will try test it.
Hi David,
thank you for the comment. :)
>However, if you set the maximum insert commit size to 0, then it will do a single commit. While I have not tested it with column store indexes, I believe this might solve your problem.
That’s cool! This is one of the things that I did not try out, and indeed it has solved the issue!
I have only tried to set MICS to controllable commit size values, such as 1.000.000 rows for example, but this value is ignored then, since the buffer is capping number of rows to an inferior value.
>I do not understand your argument against having the maximum value of DefaultBufferSize set to 100MB.
I thought that Columnstore Indexes insert operation was limited by the size of Buffer from the execution tree where the insert takes place. Yes, I thought that per se this situation would be ridiculous.
Thank you once again for the comment, I will be updating this article later tonight. :)
Best regards,
Niko Neugebauer
is there a work-around for ODBC limitation.
I am getting following error from reporting side (for a jTDS connection)
java.sql.SQLException: Cursors are not supported on a table which has a clustered columnstore index.
Greetings marees,
at the moment the workaround is not known to me.
I guess the best way is to open a Connect Item.
Best regards,
Niko Neugebauer
SQL SERVER 2014 does support creation of CCI even if there is a PK present right ? I did not drop it before creating and was able to successfully create a CCI. Am I missing on some part ?
Figured out the missing part :)
Hi Jilna,
glad to hear that you got it solved!
Hi Niko,
Have you tried using the BDD (Balanced Data Distributor) transformation? https://docs.microsoft.com/en-us/sql/integration-services/data-flow/transformations/balanced-data-distributor-transformation
It can work wonders for massive data flows.
Hi Blaž,
yes, surely!
I am still badly disappointed that for so many years it is not provided as a standard part of the SSIS.
The SQL Server Feature Pack still requires extra approvals in a lot of places. :(
Best regards,
Niko
Have you tested using BDD in combination with various source component settings (buffer size, buffer max rows, commit size)?
How does BDD relate to the buffers and the columnstore index – does it split the buffer to equal parts, or is it sending entire buffers to different destinations? In the first case we would then have to modify buffer size accordingly, and in the second, no additional tuning is required?
How does BDD’s “parallelism” work on deltastore?
Hello Niko!
I just wanted to drop a comment in here to note that as of SQL Server 2016, the maximum buffer size is now just one byte shy of 2 GB.
“The default buffer size is 10 megabytes, with a maximum buffer size of 2^31-1 bytes.”
https://docs.microsoft.com/en-us/sql/integration-services/data-flow/data-flow-performance-features
Denzil Ribeiro mentions this here as well.
https://blogs.msdn.microsoft.com/sqlcat/2016/02/29/sql-server-2016-ssis-data-flow-buffer-auto-sizing-capability-benefits-data-loading-on-clustered-columnstore-tables/
Tchau!
Lonny
Hi Lonny,
thank you, I have been mentioning this on my presentations this fact. I will update the article http://www.nikoport.com/2016/02/23/columnstore-indexes-part-77-ssis-2016-columnstore/ which is focusing on this feature, to be more clear.
Best regards,
Niko