Continuation from the previous 55 parts, the whole series can be found at https://www.nikoport.com/columnstore/
Before starting to dive into the specific of all those great-sounding and juicy improvements in SQL Server 2016 for Columnstore Indexes, I wanted to kick off with the “very basics” of the Columnstore Indexes improvements – focusing on the very practical improvements for the monitoring of the Columnstore Indexes.
In SQL Server 2016 CTP2, Microsoft has introduced 3 new Dynamic Management Views and 2 Dynamic Management Functions, which bring an astonishing improvement for Columnstore monitoring.
“Niko, are you insane?” These are just 5 monitoring improvements, that just give a couple of more insights on the Columnstore Indexes structure and it’s usage – you might have thought …
Yeah, but those insights are exactly what was missing from the SQL Server 2012 & 2014 – those insights are exactly the solution that otherwise would be impossible to discover without proper research capabilities and deep Columnstore Indexes knowledge.
Columnstore DMV’s improvements in SQL Server can be split into the following groups:
– Updated DMVs
– New DMVs
– Hekaton DMVs
For the tests I will use a copy of a free ContosoRetailDW database – by restoring it, setting compatibility level to 130 (SQL Server 2016, this is very important for the Batch Mode Improvements), dropping foreign keys and the primary key from the test FactOnlineSales table and creating a clustered columnstore index on it:
USE [master]
RESTORE DATABASE [ContosoRetailDW]
FROM DISK = N'C:\Install\ContosoRetailDW.bak' WITH FILE = 1,
MOVE N'ContosoRetailDW2.0' TO N'C:\Data\ContosoRetailDW.mdf',
MOVE N'ContosoRetailDW2.0_log' TO N'C:\Data\ContosoRetailDW.ldf',
NOUNLOAD, STATS = 1;
GO
ALTER DATABASE [ContosoRetailDW] SET COMPATIBILITY_LEVEL = 130
GO
ALTER DATABASE [ContosoRetailDW] MODIFY FILE ( NAME = N'ContosoRetailDW2.0', SIZE = 2000000KB , FILEGROWTH = 128000KB )
GO
ALTER DATABASE [ContosoRetailDW] MODIFY FILE ( NAME = N'ContosoRetailDW2.0_log', SIZE = 400000KB , FILEGROWTH = 256000KB )
GO
use ContosoRetailDW;
ALTER TABLE dbo.[FactOnlineSales] DROP CONSTRAINT [FK_FactOnlineSales_DimCurrency];
ALTER TABLE dbo.[FactOnlineSales] DROP CONSTRAINT [FK_FactOnlineSales_DimCustomer];
ALTER TABLE dbo.[FactOnlineSales] DROP CONSTRAINT [FK_FactOnlineSales_DimDate];
ALTER TABLE dbo.[FactOnlineSales] DROP CONSTRAINT [FK_FactOnlineSales_DimProduct];
ALTER TABLE dbo.[FactOnlineSales] DROP CONSTRAINT [FK_FactOnlineSales_DimPromotion];
ALTER TABLE dbo.[FactOnlineSales] DROP CONSTRAINT [FK_FactOnlineSales_DimStore];
ALTER TABLE dbo.[FactOnlineSales] DROP CONSTRAINT [PK_FactOnlineSales_SalesKey];
-- Create Clustered Columnstore Index on the fact table
create clustered columnstore Index PK_FactOnlineSales
on dbo.FactOnlineSales;
Updated:
sys.column_store_row_groups
This DMV has received some very important upgrades, mostly related to the Nonclustered Columnstore Indexes, the column row_group_id will contain the value of -1, if there is a “tail” Row Group, belonging to the In-Memory Table, and delta_store_hobt_id will contain NULL if the tail Row Group do belong to an In-Memory Table as well.
This means that the current queries (based on SQL Server 2014), should be update to include the handling of the In-Memory tail Row Groups. Ignoring this would mean filtering out very useful and important information on the Nonclustered Columnstore Indexes.
New:
sys.dm_column_store_object_pool
I am extremely glad that this DMV is being included into the SQL Server 2016, this improves the analysis of the Columnstore Object Pool greatly, since all the relevant information is available inside this DMV, ready for consumption. I have described my struggles in the previous posts Columnstore Indexes – part 38 (“Memory Structures”) & Columnstore Indexes – part 39 (“Memory in Action”)
Besides some pretty obvious fields in this DMV, such as database_id(id of the used database), object_id(table id), index_id(id of the Columnstore index),
partition_number(partition number), column_id(id of the used Columnstore column),
row_group_id(id of the Row Group), there are a couple of the columns that demand a proper explanation.
object_type – type of the object, that is being included into the Columnstore Object Pool, there are a number of them in the current version:
1 = COLUMN_SEGMENT – this is a normal Columnstore Segment, corresponding to the Row Group within given column.
2 = COLUMN_SEGMENT_PRIMARY_DICTIONARY – Primary Dictionary for a given column.
3 = COLUMN_SEGMENT_SECONDARY_DICTIONARY – Secondary Dictionary for a specific Segment of a given column.
4 = COLUMN_SEGMENT_BULKINSERT_DICTIONARY – Structure used to map segments to the primary Dictionary. Can be found after BULK load API usage or after index build/rebuild process, or after tuple mover has been invoked.
5 = COLUMN_SEGMENT_DELETE_BITMAP – good old Deleted Bitmap. :)
Additional thoughts: there are 2 new elements that are missing from the documented states and I am not sure that they will make it to this list, but it would make a lot of sense to me:
– Mapping Index – a connection element for Clustered Columnstore and Rowstore BTree Indexes;
– Deleted Buffer – a connection element between the Rowstore BTree structure and a updatable Nonclustered Columnstore Index (aka Operational Analytics);
Notice that I am not including the Deleted Rows Table, since it belongs to a pure InMemory Structure and at this point I am not sure how it is handled by the Columnstore Object Pool or wether it belongs to it at all
object_type_desc – Contains textual description for the object_type column. The possible values are: COLUMN_SEGMENT, COLUMN_SEGMENT_PRIMARY_DICTIONARY, COLUMN_SEGMENT_SECONDARY_DICTIONARY, COLUMN_SEGMENT_BULKINSERT_DICTIONARY & COLUMN_SEGMENT_DELETE_BITMAP.
access_count – number of times that the structure was accessed by reading or writing operations.
memory_used_in_bytes – amount of memory in bytes that is being used to store this structure.
timestamp – the moment when the structure was loaded into Columnstore Object Pool
Here is the query that I have been using for observing the basics of the Columnstore Object Pool, right after Clustered Columnstore Indexes creation (Corrected on 17.04.2016 after Marios Philippopoulos help):
select db_name(p.database_id) as DBname, p.database_id, object_name(p.object_id) as TableName, p.object_id, ind.name as IndexName, p.index_id, p.partition_number, COL_NAME(col.object_id,col.column_id) as name, p.column_id, p.row_group_id, p.object_type, p.object_type_desc, p.access_count, p.memory_used_in_bytes, p.object_load_time from sys.dm_column_store_object_pool p inner join sys.index_columns col on p.object_id = col.object_id and p.column_id = col.index_column_id inner join sys.indexes ind on p.object_id = ind.object_id and p.index_id = ind.index_id order by p.object_id, partition_number, p.column_id, row_group_id;
 On the left you can see the output of my query, which is giving back the relevant information on my columnstore table, which is already located inside Columnstore Object Pool right after the initial Index creation. After I start executing my queries agains the table with Columnstore Indexes, an updated information on the number of access for each of the respective structures will be updated inside this dmv.
On the left you can see the output of my query, which is giving back the relevant information on my columnstore table, which is already located inside Columnstore Object Pool right after the initial Index creation. After I start executing my queries agains the table with Columnstore Indexes, an updated information on the number of access for each of the respective structures will be updated inside this dmv.
Notice that whenever DBCC DropCleanBuffers is invoked, all structures that are marked as “Clean” will be removed from the Columnstore Object Pool and hence from the results of this DMV.
The sys.dm_column_store_object_pool DMV will not be useful for everyone in every situation, but it will provide a vastly valuable insight on the memory internals off the Columnstore Indexes, and sampling information from it will enable a better understanding of the Columnstore queries performance.
sys.dm_db_column_store_row_group_physical_stats
This DMV represents an extended version of the good old sys.column_store_row_groups DMV.
This DMV sys.dm_db_column_store_row_group_physical_stats represents the information on the physical structure of the Columnstore Row Groups, and even more importantly – it gives a detailed explanation on why each of the particular Row Groups has the current size. This method represents a radical change from the strategies in SQL Server 2014, where only with the help of Extended Events we could have established the reasons for the Row Group trims, and should we have had no Extended Events running – then establishing the reason was simply impossible.
In SQL Server 2016, in this DMV – sys.dm_db_column_store_row_group_physical_stats we have 2 columns that will provide the exact information on the trim reasons for each of the Row Groups.
Lets check out the properties available through this DMV:
object_id(table id), index_id(id of the Columnstore index),
partition_number(partition number), row_group_id(id of the Row Group),
delta_store_hobt_id(the hot_id for the Row Group, NULL if this is a Delta-Store or a Tail Row Group.
state – current status of the Row Group: 0 = INVISIBLE, 1 = OPEN, 2 = CLOSED, 3 = COMPRESSED, 4 = TOMBSTONE. For more information on the Tombstone, check out Azure Columnstore, part 1 – The initial preview offering)
state_desc – current descriptive status of the Row Group
total_rows – total number of rows inside this Row Group
deleted_rows – number of rows inside this Row Group that are marked as deleted (see Deleted Bitmap)
size_in_bytes – the total size in bytes of the Row Group. Notice that this size does not include the metadata and dictionaries.
trim_reason – the reason behind the current size of the Row Group. Possible documented values are:
0 – UNKNOWN_UPGRADED_FROM_PREVIOUS_VERSION – upgrade from the elder version of engine or unknown.
1 – NORMAL – the current available maximum value of the rows – 1048576 was reached successfully.
2 – BULKLOAD – the data was loaded through Bulk Load API operation containing more than 102.400 rows
3 – REORG – the ALTER INDEX REORGANIZE operation was invoked. This is a merge operation.
4 – DICTIONARY_SIZE – the dictionary pressure has occurred (I have seen it ranging from 7.5MB to 16MB(the true maximum size for a given dictionary))
5 – MEMORY_LIMITAION – not enough available memory
6 – RESIDUAL_ROW_GROUP – not enough row to reach the maximum number of rows, this state is typically reached for the last Row Groups in the Columnstore Tables.
Undocumented, but discovered values:
8 – SPILLOVER – happens whenever Tuple Mover compresses In-Memory Columnstore table and it becomes part of the last Row Group. This looks to me to be extremely similar to the RESIDUAL_ROW_GROUP state, but applies only to the automatic compression process (Manual compression will get REORG state).
trim_reason_desc – the reason behind the current size of the Row Group. The textual description can contain one of the following values: UNKNOWN_UPGRADED_FROM_PREVIOUS_VERSION, NORMAL, BULKLOAD, REORG, DICTIONARY_SIZE, MEMORY_LIMITATION, RESIDUAL_ROW_GROUP, SPILLOVER.
generation – undocumented, but looks like an exact order sequence that was used for Row Group creation.
Interestingly, in the current documentation I have found a couple more described columns that are not available in the current build (SQL Server 2016 CTP 2.0), containing the information that would be extremely useful, such as:
transition_to_compressed_state, transition_to_compressed_state_desc –
Shows how this rowgroup got moved from the deltastore to a compressed state in the columnstore.
0 – NOT_APPLICABLE – the operation does not apply to the deltastore. Or, the rowgroup was compressed prior to upgrading to SQL Server 2016 Community Technology Preview 2 (CTP2) in which case the history is not preserved.
1 – INDEX_BUILD – An index create or index rebuild compressed the rowgroup.
2 – TUPLE_MOVER – The tuple mover running in the background compressed the rowgroup. This happens after the rowgroup changes state from OPEN to CLOSED.
3 – REORG_NORMAL – The reorganization operation, ALTER INDEX … REORG, moved the CLOSED rowgroup from the deltastore to the columnstore. This occurred before the tuple-mover had time to move the rowgroup.
4 – REORG_FORCED – This rowgroup was open in the deltastore and was forced into the columnstore before it had a full number of rows.
5 – BULKLOAD – A bulk load operation compressed the rowgroup directly without using the deltastore.
6 – MERGE – A merge operation consolidated one or more rowgroups into this rowgroup and then performed the columnstore compression.
This looks like a part that is dedicated to the Delta-Stores, and trim_reason existence makes part of this information obsolete, though I would not mind having a column that provides information what kind of Tuple Mover (automatic or manual) was used in order to compress a given Delta-Store.
has_vertipaq_optimization
Vertipaq optimization improves columnstore compression by rearranging the order of the rows in the rowgroup to achieve higher compression. This optimization occurs automatically in most cases. An exception, SQL Server skips Vertipaq optimization when a delta rowgroup moves into the columnstore and there are one or more nonclustered indexes on the columnstore index. In this case Vertipaq optimization is skipped to minimizes changes to the mapping index.
0 = No
1 = Yes
This is very interesting property, which helps us to understand some of the architectural solutions that SQL Server had received for the integration of Nonclustered Columnstore Index. :)
creation_time – Clock time for when this rowgroup was created.
NULL – for a columnstore index on an in-memory table.
Here is the query that I have executed on my database to see how my Clustered Columnstore Index behaved:
select object_name(phst.object_id) as TableName, phst.object_id, ind.name as IndexName, phst.index_id, partition_number, delta_store_hobt_id, state, state_desc, total_rows, deleted_rows, size_in_bytes, trim_reason, trim_reason_desc, generation from sys.dm_db_column_store_row_group_physical_stats phst inner join sys.indexes ind on phst.object_id = ind.object_id and phst.index_id = ind.index_id order by phst.object_id, phst.partition_number, phst.row_group_id;
 As you can see, just 2 of my Row Groups did not manage to reach the maximum number of rows, naturally because FactOnlineSales table does not have exact number of rows to fit perfectly into a Columnstore Index without a non-full Row Group, like it happens in a real life. More importantly I have a clear overview of what happened to which Row Group and why.
As you can see, just 2 of my Row Groups did not manage to reach the maximum number of rows, naturally because FactOnlineSales table does not have exact number of rows to fit perfectly into a Columnstore Index without a non-full Row Group, like it happens in a real life. More importantly I have a clear overview of what happened to which Row Group and why.
sys.dm_db_column_store_row_group_operational_stats
The newest DMV sys.dm_db_column_store_row_group_operational_stats (which was already exposed in Azure SQLDatabase since December 2014), provides information on the IO and Locking for the Columnstore Indexes. We have never had such information before, and only by aggregating the results of certain Extended Events could we have reached a similar understanding and how close it would be to real-time is definitely another question.
Lets check out the properties available through this DMV:
object_id(table id), index_id(id of the Columnstore index),
partition_number(partition number), row_group_id(id of the Row Group),
index_scan_count – number of times the Columnstore Index for the current partition was scanned.
scan_count – number of times that this RowGroup was scanned, as opposed and compared to the index_scan_count which should contain equal or superior value.
delete_buffer_scan_count – number of times that the Deleted Buffer (Connection between Rowstore Btree table & updatable Nonclustered Columnstore Index) was used in order to filter the Deleted Rows out of the result from the current Row Group.
I also interpret, this property as the number of times that the Deleted Rows Table was accessed.
row_group_lock_count – number of Row Group locks requested by the engine. This property will provide a better insight on the type of the operations that are happening on the Columnstore structure.
row_group_lock_wait_count – the total number of times that the engine was made to wait on the acquisition of the Row Group lock. This property provides a good explanation for the delays in execution times for the queries.
row_group_lock_wait_in_ms – the total time spent on waiting to acquire the Row Group lock. This property provides a good explanation for the delays in execution times for the queries.
To see what is happening with the system right now, I will execute the following query:
select object_name(st.object_id) as TableName, st.object_id, ind.name as IndexName, st.index_id, st.partition_number, st.row_group_id, st.index_scan_count, st.scan_count, st.delete_buffer_scan_count, st.row_group_lock_count, st.row_group_lock_wait_count, st.row_group_lock_wait_in_ms from sys.dm_db_column_store_row_group_operational_stats st inner join sys.indexes ind on st.object_id = ind.object_id and st.index_id = ind.index_id order by st.object_id, st.partition_number, st.row_group_id
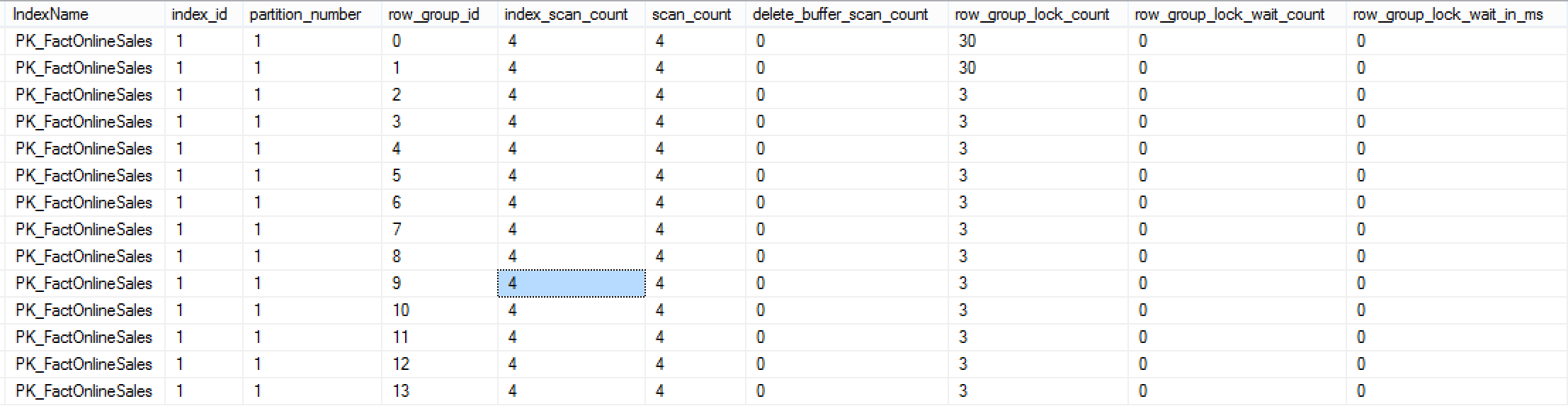 The image clearly shows detailed information on the scanning operations and the Row Group locking that my tables has faced so far (almost none). In a real production environment I would be able to determine if my queries are stuck because of the locking problem and how good often each of the Row Groups is getting eliminated by the query predicates.
The image clearly shows detailed information on the scanning operations and the Row Group locking that my tables has faced so far (almost none). In a real production environment I would be able to determine if my queries are stuck because of the locking problem and how good often each of the Row Groups is getting eliminated by the query predicates.
sys.internal_partitions
This new DMV provides an insight on the internal data for Columnstore Indexes for traditional row-store tables, that are disk-based, tracking Delta-Stores, Deleted Bitmap, Deleted Buffer (a new structure that takes care of the updatable Nonclustered Indexes maintenance) & Mapping Index (a new structure used to synchronise secondary Rowstore Btree nonclustered Indexes and a Clustered Columnstore Index) & Deleted Rows Table (InMemory OLTP connection to the InMemory Columnstore), based on the partition. This view gives a valuable information on the internals of the supporting structures for Columnstore Indexes, allowing to understand the way they function.
Since some of these structures are new to SQL Server, there is nothing to compare this DMV to – and hence its usability will be proven with time. The one thing that is undeniable is that this view gives us an incredible insight on what is going with the system and this a very fresh way for the Columnstore structures – and so I definitely “blame” Sunil Agarwal for giving us more tools to work with :)
As with other Columnstore DMVs we have a number of traditional properties as well as specific ones that provide practical valuable information :
object_id(table id), index_id(id of the Columnstore index),
partition_number(partition number), row_group_id(id of the Row Group),
hobt_id(the hot_id for the Row Group).
internal_object_type – type of the internal Columnstore object that is being tracked (yes, the public documentation has wrong values at the moment)
2 = COLUMN_STORE_DELETE_BITMAP – our good old friend Deleted Bitmap from SQL Server 2014
3 = COLUMN_STORE_DELTA_STORE – Delta-Stores, they are still the same structures from SQL Server 2014 :)
4 = COLUMN_STORE_DELETE_BUFFER – this new structure is used to synchronise the deletes from the RowStore table to the Nonclustered Columnstore Index.
5 = COLUMN_STORE_MAPPING_INDEX – this new structure will be used for mapping secondary nonclustered indexes to Clustered Columnstore Index)
Additional thoughts: Undocumented is the Deleted Rows Table here, will it be present there or will it continue to be exposed as a Deleted Bitmap as it seems at the moment?
internal_object_type_desc – textual description of the internal Columnstore Object (the value will be one of the following ones: COLUMN_STORE_DELETE_BITMAP, COLUMN_STORE_DELTA_STORE, COLUMN_STORE_DELETE_BUFFER, COLUMN_STORE_MAPPING_INDEX)
rows – the number of rows that the Columnstore structure contains
data_compression – describes the data compression algorithm used for this structure:
0 = NONE
1 = ROW
2 = PAGE
data_compression_desc – textual description of the compression algorithm used for this structure – NONE, ROW or PAGE
To check the current status of your Columnstore internal structures, you can use the following query, for example:
select object_name(part.object_id) as TableName, part.object_id, part.partition_id, ind.name as IndexName, part.index_id, part.hobt_id, part.internal_object_type, part.internal_object_type_desc, part.row_group_id, part.rows, part.data_compression, part.data_compression_desc from sys.internal_partitions part inner join sys.indexes ind on part.object_id = ind.object_id and part.index_id = ind.index_id
![]() On this picture you can see the output for a couple of Columnstore Structures that are visible for some tests that I was creating.
On this picture you can see the output for a couple of Columnstore Structures that are visible for some tests that I was creating.
As for my personal experience, I confess that while studying the new Columnstore structures, this was the DMV that I was constantly using – it gave me exactly the understanding of what was going on inside the system, but it will probably won’t be the first DMV that one will be using when troubleshooting some basic Columnstore issues :)
In-Memory OLTP:
As of the moment, the current changes to the 6 DMV’s (sys.dm_db_xtp_hash_index_stats, sys.dm_db_xtp_index_stats, sys.dm_db_xtp_memory_consumers, sys.dm_db_xtp_nonclustered_index_stats, sys.dm_db_xtp_object_stats, sys.dm_db_xtp_table_memory_stats) that serves for In-Memory OLTP monitoring, I have only noticed 1 new column in most of them – xtp_object_id. I am expecting this situation to change in the next CTP versions of SQL Server 2016, so stay tuned! :)
to be continued …
Hi Niko,
Thank you for this series of blogs on columnstore indexes – I have been reading it a lot lately, trying to catch up on the evolution of columnstores from SQL 2012 to SQL 2016.
I have just one observation on the above query for sys.dm_column_store_object_pool.
This DMV actually returns the index_column_id, not the column_id. So you need to join it to sys.index_columns, not sys.columns.
Again, I have found this series very beneficial for my understanding of columnstores; pls keep up the good work.
Thank you,
Marios Philippopoulos
Hi Marios,
thank you for the kind words.
Thank you so much for pointing the error – it has been now corrected.
Best regards,
Niko
Hi Niko,
Thanks for all of your knowledge sharing related to columnstore indexes – much appreciated! I have a fact table with a clustered columnstore index that is partitioned. Within each partition, I am seeing multiple trimmed row-groups after a fresh columnstore build. After looking at the dm_db_column_store_row_group_physical_stats dmv, I see that the trim reason is always “RESIDUAL_ROW_GROUP”. How are there multiple trimmed row groups within the same partition, all with that reason? I would only expect a max of 1 per partition. As an example, this is what 1 of my partitions looks like:
– partition_number 22, row_group_id 0, total_rows 1048576
– partition_number 22, row_group_id 1, total_rows 1048576
– partition_number 22, row_group_id 2, total_rows 1024, trim_reason_desc RESIDUAL_ROW_GROUP
– partition_number 22, row_group_id 3, total_rows 148143, trim_reason_desc RESIDUAL_ROW_GROUP
– partition_number 22, row_group_id 4, total_rows 1048576
– partition_number 22, row_group_id 5, total_rows 1024, trim_reason_desc RESIDUAL_ROW_GROUP
Thanks!
Chris
Hi Chris,
The Residual Row Groups (RESIDUAL_ROW_GROUP) happen when you load the data, which is not exactly divisible through the maximum number of rows in a Row Group (1.048576).
For example if you load with Bulk Load API and no pressures 1.5 million rows, you will have a full row group and a residual row group with 452.424 rows. This is totally normal.
Rebuilding this partition with multiple cores will allow you to re-balance the rows sometimes, making more groups similar-sized, and thus helping processing performance.
Best regards,
Niko
Hello Niko,
Please, could you explain MEMORY_LIMITATION ? – I have a lot of RGs with this trim_reson and total_rows = 524289. What could be done in this case?
Hi Alexander,
This happens when your build/rebuild process does not receive enough working memory and the Row Group can not fit into available working memory space, so the Engine has to trim(or cut) it off.
Consider increasing the overall amount of memory or working with Resource Governor and giving greater amount than the default 25% to you Index build/rebuild query.
Best regards,
Niko