Continuation from the previous 45 parts, starting from https://www.nikoport.com/2013/07/05/clustered-columnstore-indexes-part-1-intro/
At the last SQLPort event in December 2014, I have listened to a presentation by Alberto Ferrari talking about DAX and giving some tuning advices regarding the Date Dimensions in xVelocity storage engine (PowerPivot, SSAS Tabular).
Since the same base principle & engine is used in the heart of Columnstore indexes, whole thoughts lead me on to doing some research related to the Dates usage in Columnstore Indexes.
For this blog post I decided to experiment with some datetime data – to see what happens with the compression on the storage level and how some of the basic queries will be effected.
To start off with some data, I have restored a fresh copy of my favourite ContosoRetailDW database, upgrading it to 120 Compatibility level and improving data allocation for the data file & log file:
USE [master] alter database ContosoRetailDW set SINGLE_USER WITH ROLLBACK IMMEDIATE; RESTORE DATABASE [ContosoRetailDW] FROM DISK = N'C:\Install\ContosoRetailDW.bak' WITH FILE = 1, MOVE N'ContosoRetailDW2.0' TO N'C:\Data\ContosoRetailDW.mdf', MOVE N'ContosoRetailDW2.0_log' TO N'C:\Data\ContosoRetailDW.ldf', NOUNLOAD, STATS = 5; alter database ContosoRetailDW set MULTI_USER; GO ALTER DATABASE [ContosoRetailDW] SET COMPATIBILITY_LEVEL = 120 GO ALTER DATABASE [ContosoRetailDW] MODIFY FILE ( NAME = N'ContosoRetailDW2.0', SIZE = 2048000KB , FILEGROWTH = 512000KB ) GO ALTER DATABASE [ContosoRetailDW] MODIFY FILE ( NAME = N'ContosoRetailDW2.0_log', SIZE = 1124000KB , FILEGROWTH = 512000KB ) GO use ContosoRetailDW;
I have choosen to create 4 different tables with different way of storing DateTime data: DateTime column(1), Date column & Time column(2), Character column(3), Integer column(4).
Setup
Because there is no hours & minutes information in the dates stored in FactOnlineTable, I have decided to generate a random times (Hours:Minutes:Seconds) into a support table, which I called dbo.Times:
create table dbo.Times
( id int identity(1,1) primary key clustered,
randomTime Time not null );
alter table dbo.Times
rebuild WITH (DATA_COMPRESSION = PAGE);
With E00(N) AS (SELECT 1 UNION ALL SELECT 1),
E02(N) AS (SELECT 1 FROM E00 a, E00 b),
E04(N) AS (SELECT 1 FROM E02 a, E02 b),
E08(N) AS (SELECT 1 FROM E04 a, E04 b),
E16(N) AS (SELECT 1 FROM E08 a, E08 b),
E32(N) AS (SELECT 1 FROM E16 a, E16 b)
Insert into dbo.Times (randomTime)
Select top 12627608 cast(DateAdd(Second,abs(CheckSum(newId()))%86400,'00:00') as Time)
from E32;
alter table dbo.Times
rebuild WITH (DATA_COMPRESSION = PAGE)
DateTime
For the principle test table I have used the dates from dbo.FactOnlineSales table, joining them together with the random times generated in the previous step for dbo.Times table.
create table dbo.DatesSimple (DateKey Datetime not null ); create clustered columnstore index PK_DatesSimple on dbo.DatesSimple; WITH OrderedDates AS ( Select DateKey, ROW_NUMBER() over (ORDER BY DateKey) AS RowNumber from dbo.FactOnlineSales ) insert into DatesSimple (DateKey) select DateKey + cast(t.randomTime as DateTime) from OrderedDates od inner join dbo.Times t on od.RowNumber = t.id;
Date & Time separated into 2 columns
The second test case that I created was all about splitting Date & Time into different separated column, especially since SQL Server 2008 we have specific data types for Date & Time:
create table dbo.DatesSplitted (DateKey Date not null, TimeKey time not null ); create clustered columnstore index PK_DatesSplitted on dbo.DatesSplitted; insert into dbo.DatesSplitted (DateKey,TimeKey) select convert(date, DateKey) as [Date], convert(varchar(8), convert(time, DateKey)) as [Time] from dbo.DatesSimple;
Character column table
This will be quite controversial, I know :)
I decided to put DateTime data into a string column, to see how it will compress compared to the DateTime and how it will perform with my test queries.
I know that it is not suited for this purpose, and obviously every data type is created and optimised for its own usage … or is it ? :)
I know enough people and I have seen way too many times people choosing the wrong data types and understanding some of the implications is extremely important, because granting that this might bring some advantages does not mean that there are no clear disadvantages of selecting a “wrong” data type.
Notice that with VarChar would simply get worse, especially with the Memory Grants for the queries, which are attributed calculated that Varchar fields are half-full, which a lot of times leads into the problems of TempDB Spilling.
create table dbo.DatesChar (DateKey CHAR(20) not null ); create clustered columnstore index PK_DatesChar on dbo.DatesChar; insert into dbo.DatesChar (DateKey) select convert(char,DateKey,20) from dbo.DatesSimple
Big Integer column table
To get a better view I have decided to include a BigInt data into the test, converting the DateTime data into a big integer value (I would be able to use a simple Integer if my data would not have seconds involved).
create table dbo.DatesBigInteger (DateKey bigint not null ); create clustered columnstore index PK_DatesBigInteger on dbo.DatesBigInteger; insert into dbo.DatesBigInteger (DateKey) select replace(replace(replace(Datekey,'-',''),' ',''),':','') from dbo.DatesChar;
The sizes
To finalize the load process I have decided to rebuild all of my tables to make sure that all Delta-Stores are converted into compressed Segments:
alter table [dbo].[DatesSimple] rebuild; alter table [dbo].[DatesSplitted] rebuild; alter table [dbo].[DatesChar] rebuild; alter table [dbo].[DatesBigInteger] rebuild;
For measuring my generated table sizes I executed the following query, which is calculating the sum of the compressed Segments for each Columnstore Index found in my DB:
select object_name(object_id) as TableName, cast(sum(size_in_bytes)/1024./1024. as Decimal(9,2)) as SizeMB from sys.column_store_row_groups group by object_name(object_id) order by cast(sum(size_in_bytes)/1024./1024. as Decimal(9,2)) desc;
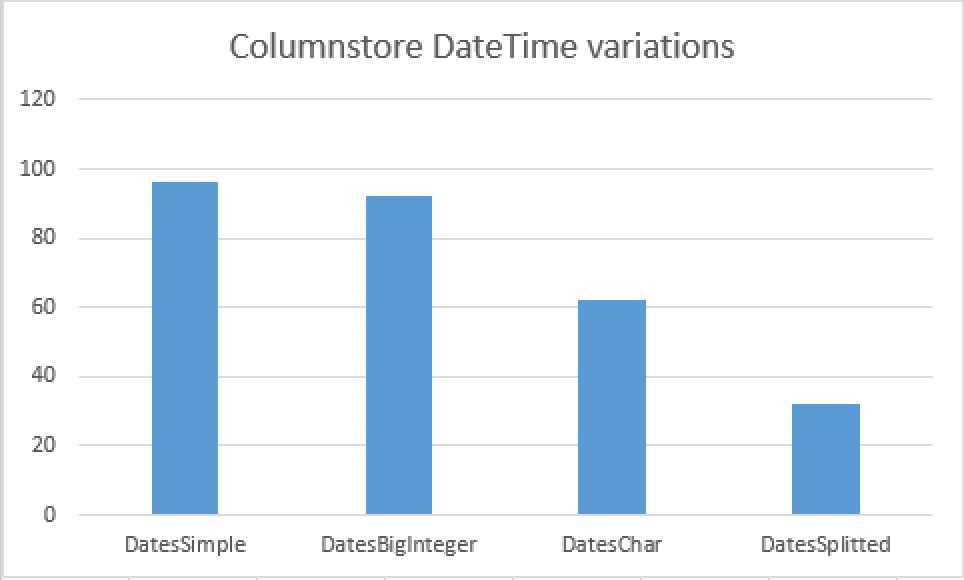 You can see the difference in the sizes with DateSplitted occupying 1/3 of the size from the original DatesSimple table. Depending on the data, I have actually seen it going as low as being 5 times smaller, it all depends on the actual information. Separating date from time guarantees that we can compress the Dates much better in the cases when they have the same values stored. The same applies to the Times column, where having equal values means much greater level of compression.
You can see the difference in the sizes with DateSplitted occupying 1/3 of the size from the original DatesSimple table. Depending on the data, I have actually seen it going as low as being 5 times smaller, it all depends on the actual information. Separating date from time guarantees that we can compress the Dates much better in the cases when they have the same values stored. The same applies to the Times column, where having equal values means much greater level of compression.
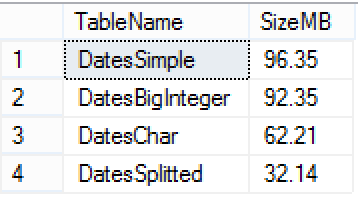 From the other side BigInteger seems to compress data quite similarly to DateTime, which makes enough sense since both data types occupy 8 bytes of space. The difference for the dbo.DatesChar table is clearly provoked by better compression technics applied to the character fields within Columnstore engine.
From the other side BigInteger seems to compress data quite similarly to DateTime, which makes enough sense since both data types occupy 8 bytes of space. The difference for the dbo.DatesChar table is clearly provoked by better compression technics applied to the character fields within Columnstore engine.
The real strength of the date & time separation & compression lies within the similarity of the data, which is very visible when consulting existing dictionaries – the only table with dictionaries is the dbo.DatesSplitted table:
select object_name(object_id) as TableName, * from sys.column_store_dictionaries dict inner join sys.partitions part on dict.partition_id = part.partition_id

The result from the storage perspective is very clear – splitting date & time into 2 columns pays off greatly, and storing data in character form in the current (SQL Server 2014) gives a number of advantages relative to the compression.
But be aware – storage space is not the whole story :)
Querying DateTime Tables
We have seen data storage variation depending on the method, but now let’s see how it behaves whenever we are extracting and processing data.
For the first test I have run a simple scan of the complete table trying to find the maximum and the minimum dates from all of the tables:
set statistics time on set statistics io on select max(DateKey), min(DateKey) from dbo.DatesSimple; select max(cast(DateKey as DateTime) + cast(TimeKey as datetime)) , min(cast(DateKey as DateTime) + cast(TimeKey as datetime)) from dbo.DatesSplitted; select max(DateKey), min(DateKey) from dbo.DatesChar; select max(DateKey), min(DateKey) from dbo.DatesBigInteger;
I have executed those queries a number of times in order to see average times and on my VM (4 i7 2.8GHz cores with SSD) and here are my results:
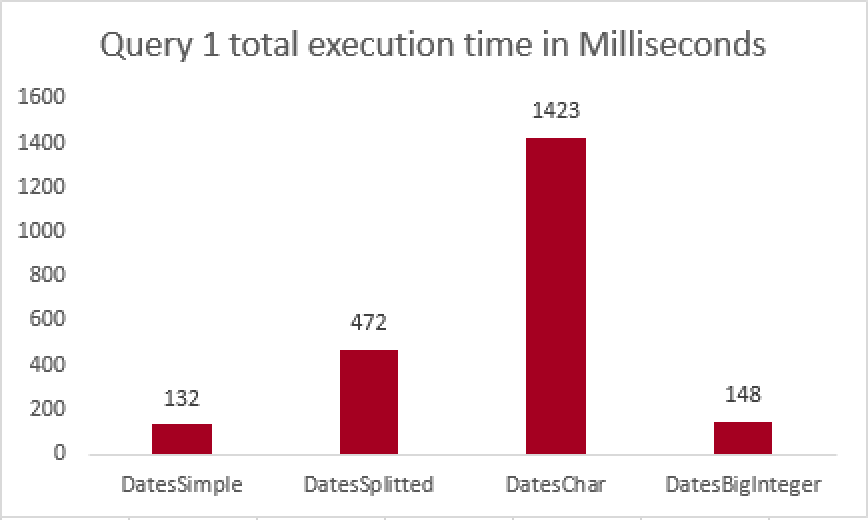 The clear winner here is the default storage engine (DateTime), performing the best without any tweeks, with BigInteger following by a minor delay and than with huge gap of ~3.5 times slower the table with Date & Times separated into 2 different columns (dbo.DatesSplitted), finished by the slowest by far dbo.DatesChar table is using Character data type for DateTime storage.
The clear winner here is the default storage engine (DateTime), performing the best without any tweeks, with BigInteger following by a minor delay and than with huge gap of ~3.5 times slower the table with Date & Times separated into 2 different columns (dbo.DatesSplitted), finished by the slowest by far dbo.DatesChar table is using Character data type for DateTime storage.
In the case where the major number of queries are scanning whole FactTable on the fast storage, there is no doubt that splitting DateTime into 2 columns does not make a lot of sense.
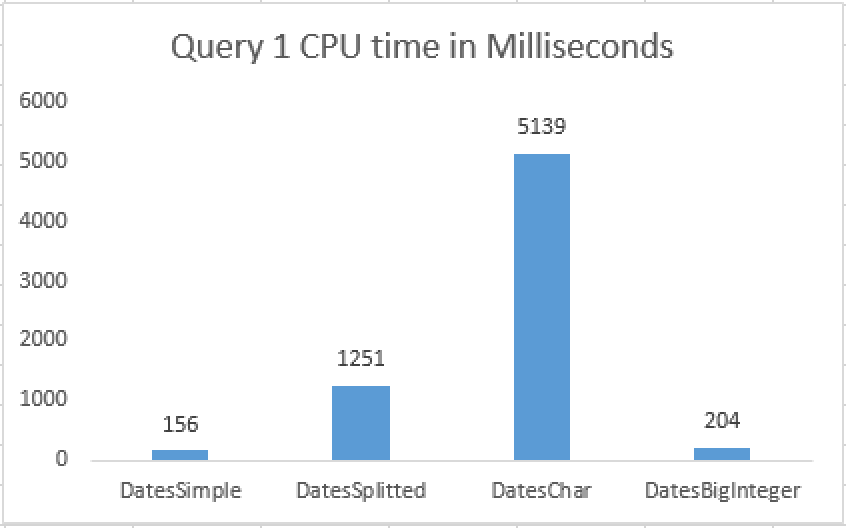 This picture would not be complete without spent CPU times – here you can clearly see that the pattern of the total time behaves in correspondence to the CPU times – which in this case means that we are simply spending our CPU power on processing data.
This picture would not be complete without spent CPU times – here you can clearly see that the pattern of the total time behaves in correspondence to the CPU times – which in this case means that we are simply spending our CPU power on processing data.
Notice that those results will be very different depending on the storage, if we would be scanning large TB of data on a storage that is slow, than our resources spending pattern would definitely change.
Let’s see what happens when we execute a different query, that is using a predicates, allowing to eliminate a number of Segments – I am filtering on the year 2008, but in order to do a fair setup for Segment elimination, ordering data with a Segment Clustering:
create clustered index PK_DatesSimple on dbo.DatesSimple (DateKey) with (DROP_EXISTING = ON, DATA_COMPRESSION = PAGE); create clustered columnstore index PK_DatesSimple on dbo.DatesSimple with (DROP_EXISTING = ON, MAXDOP = 1); create clustered index PK_DatesSplitted on dbo.DatesSplitted (DateKey) with (DROP_EXISTING = ON, DATA_COMPRESSION = PAGE); create clustered columnstore index PK_DatesSplitted on dbo.DatesSplitted with (DROP_EXISTING = ON, MAXDOP = 1); create clustered index PK_DatesChar on dbo.DatesChar (DateKey) with (DROP_EXISTING = ON, DATA_COMPRESSION = PAGE); create clustered columnstore index PK_DatesChar on dbo.DatesChar with (DROP_EXISTING = ON, MAXDOP = 1); create clustered index PK_DatesBigInteger on dbo.DatesBigInteger (DateKey) with (DROP_EXISTING = ON, DATA_COMPRESSION = PAGE); create clustered columnstore index PK_DatesBigInteger on dbo.DatesBigInteger with (DROP_EXISTING = ON, MAXDOP = 1);
Now we are ready to run our queries:
set statistics time on set statistics io on select max(DateKey), min(DateKey) from dbo.DatesSimple where DateKey >= '2008-01-01' and DateKey < '2009-01-01'; select max(cast(DateKey as DateTime) + cast(TimeKey as datetime)) , min(cast(DateKey as DateTime) + cast(TimeKey as datetime)) from dbo.DatesSplitted where DateKey >= '2008-01-01' and DateKey < '2009-01-01'; select max(DateKey), min(DateKey) from dbo.DatesChar where DateKey >= '2008-01-01' and DateKey < '2009-01-01'; select max(DateKey), min(DateKey) from dbo.DatesBigInteger where DateKey >= 20080101000000 and DateKey < 20090101000000;
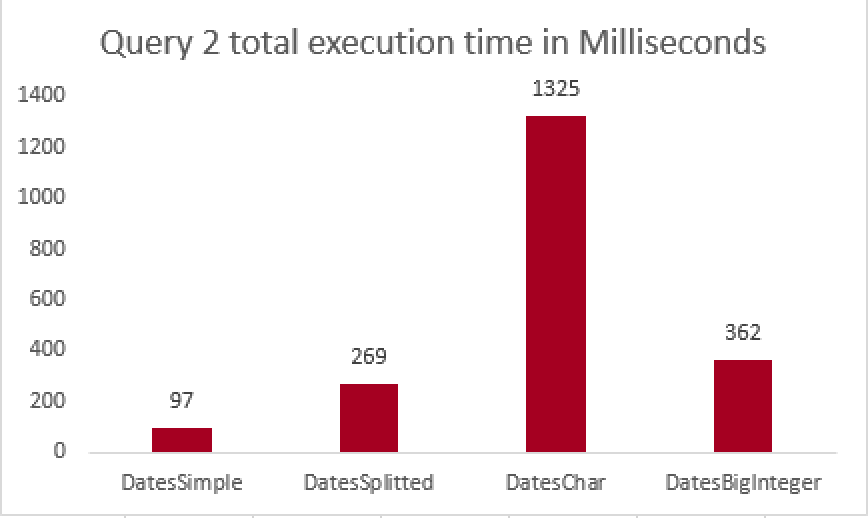 The results follow the pattern of the 1st query results, with quite notable difference of BigInteger performing extremely slow compared to the previous results. In all this looks more like a bug and I am definitely submitting a Connect Item on it. The amount of data read in the query for DatesBigInteger is smaller and so it should be running at least as fast as the full table scan.
The results follow the pattern of the 1st query results, with quite notable difference of BigInteger performing extremely slow compared to the previous results. In all this looks more like a bug and I am definitely submitting a Connect Item on it. The amount of data read in the query for DatesBigInteger is smaller and so it should be running at least as fast as the full table scan.
Updated on 18th of January: After comments by Vassilis Papadimos, I have finally understood that while inputting a very long number as a BigInteger, it is indeed being converted to a numeric(14,0) value and following the precedence rules, the conversion needs to be done on the left side of the predicate, thus disabling the effective Segment Elimination. Declaring the value as a BigInt variable will allow to achieve the expected performance - with the following execution times registered:
CPU time = 78 ms, elapsed time = 105 ms.
then dictate that the comparison needs to happen between numerics, and the conversion of the bigint column data to numeric is what’s killing the performance. Explicitly casting the constants to bigint (or assigning them to bigint variables and then using the variables in the query) will get you the expected performance
The difference between using 1 DateTime column or 2 columns separated into Date & Time, is getting smaller - most probably because of more efficient Segment elimination.
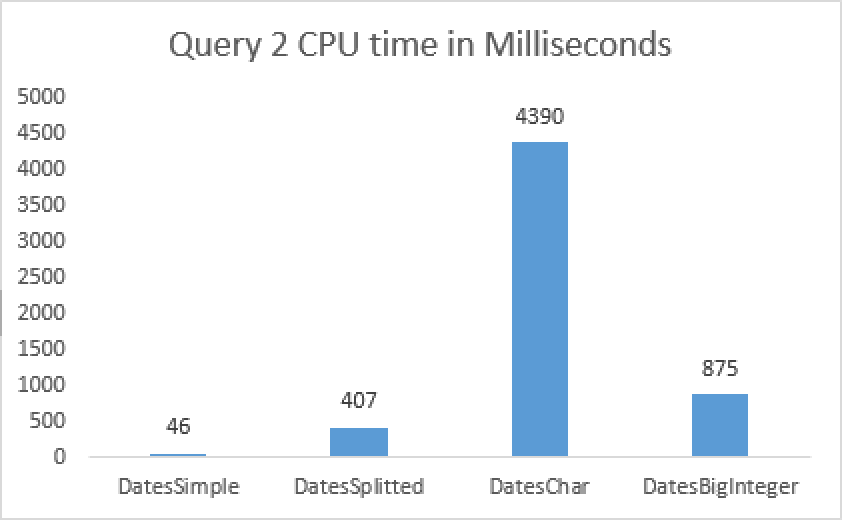 Once again, the CPU time is actually setting the pattern for the total execution time. The Character processing is extremely slow on the CPU side and I do not really even a slow storage to compensate it easily. Naturally everything needs to be proven and tested, but for the current set of data I can clearly see that sticking to the default DateTime configuration is still the best option.
Once again, the CPU time is actually setting the pattern for the total execution time. The Character processing is extremely slow on the CPU side and I do not really even a slow storage to compensate it easily. Naturally everything needs to be proven and tested, but for the current set of data I can clearly see that sticking to the default DateTime configuration is still the best option.
At this point lets take a more detailed look at the execution plans:




Looking at the execution plans things are getting more clear:
1. The performance problems of the DatesSplitted table are related to Compute Scalar iterator - we are doing max over casting of 2 different columns, and should remove those complex calculations (which are needed for the logic in this case) than our query times would easily drop to 19 ms of total duration and 32 ms CPU time respectively.
If there is a logic involving complex calculations of date & time conjunction, than there might be no win in splitting the column, but should we just use Date & Time as a predicate - it might be very interesting.
2. In the case of DatesCharacter performance - we are simply not filtering the data on the storage level - the predicate is not being pushed down, as you can judge on the presence of Filter iterator and the number of rows being transferred from the Clustered Columnstore Index scan.
This is a known limitation for SQL Server 2012 & 2014 and I can only hope that in the future it will get updated & improved.
To prove the point let's take a look at the 10-12th Segments (i just selected those 3, but feel free to select any other) of all Clustered Columnstore tables:
select object_name(object_id) as TableName, partition_number, segment_id, row_count, base_id, min_data_id, max_data_id from sys.column_store_segments seg inner join sys.partitions part on seg.partition_id = part.partition_id where column_id = 1 and segment_id in (10,11,12) order by object_name(object_id), partition_number, segment_id;
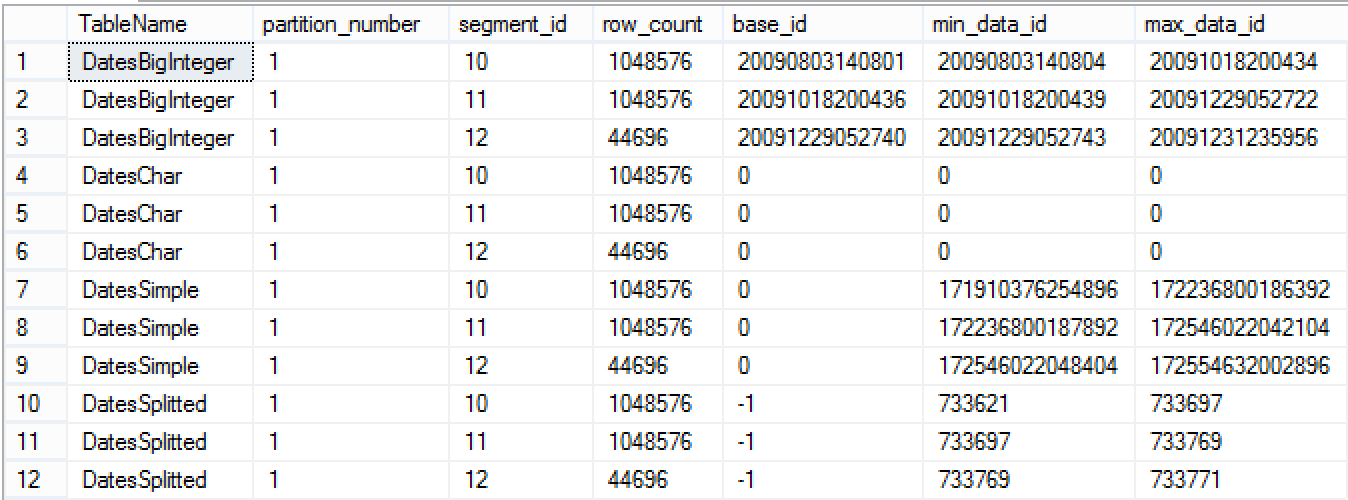 Since the information about min & max data stored inside segment is not exposed for the Character columns, there is no reason to push down the predicate.
Since the information about min & max data stored inside segment is not exposed for the Character columns, there is no reason to push down the predicate.
Ok, but let's run a different test query, this time focusing on filtering data on Time, between 9AM and 6PM:
set statistics time on set statistics io on select max(DateKey), min(DateKey) from dbo.DatesSimple where CONVERT(VARCHAR, DateKey, 108) >= '09:00:00' and CONVERT(VARCHAR, DateKey, 108) < '18:00:00'; select max(cast(DateKey as DateTime) + cast(TimeKey as datetime)) , min(cast(DateKey as DateTime) + cast(TimeKey as datetime)) from dbo.DatesSplitted where TimeKey >= '09:00:00' and TimeKey < '18:00:00'; select max(DateKey), min(DateKey) from dbo.DatesChar where cast(right(DateKey,10) as datetime) >= '09:00:00' and cast(right(DateKey,10) as datetime) < '18:00:00'; select max(DateKey), min(DateKey) from dbo.DatesBigInteger where DateKey % 1000000 >= 90000 and DateKey % 1000000 < 180000;
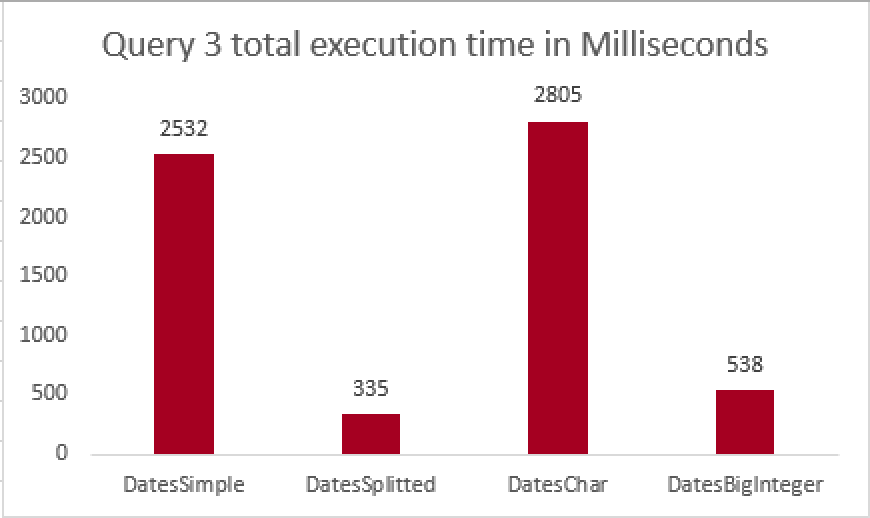
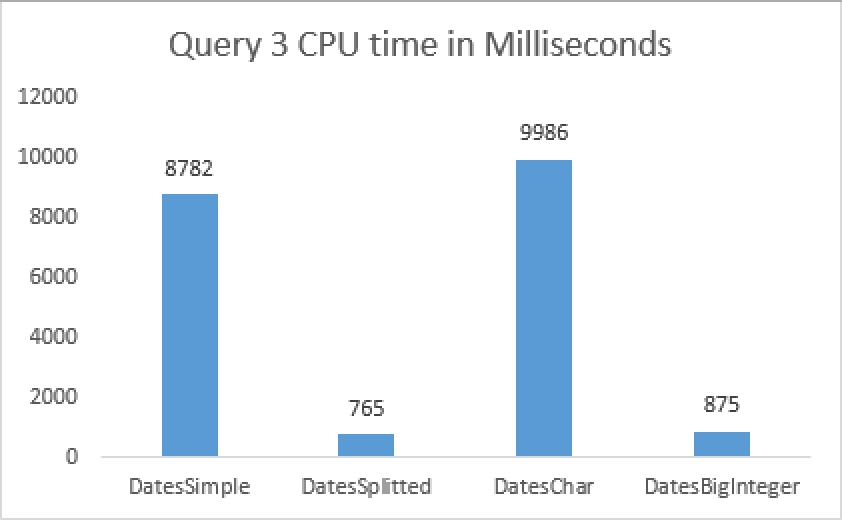
As you can see the results are very clear with Date & Time splitted into 2 columns are leading the way together with BigInteger table, while DateTime & Character based column tables are trailing with a performance almost 10 times slower.
The Conclusion
While it is still largely depends on the concrete situation, if achieving the best compression and great balanced performance are extremely important points, and if you can apply changes to your queries without any big problems (maybe creating a view) - then you should consider splitting DateTime columns into 2 columns with Date & Time datatypes.
As long as Character columns do not support Segment elimination on the storage level, there are no reasons to use them, unless you are intending to scan the whole table - then its better compression might be something to consider.
to be continued with Clustered Columnstore Indexes – part 47 (“Practical Monitoring with Extended Events”)
The surprisingly bad performance for the BigInteger variation in Query 2 is due to the not quite intuitive rules for literal typing. 20080101000000 may fit in a bigint, but its default type is numeric(14, 0). Precedence rules then dictate that the comparison needs to happen between numerics, and the conversion of the bigint column data to numeric is what’s killing the performance. Explicitly casting the constants to bigint (or assigning them to bigint variables and then using the variables in the query) will get you the expected performance. A warning in the graphical showplan might be useful here… (P. S. I work for Microsoft.)
Hi Vassilis,
thank you for the comment and explanations – it makes total sense.
I just tested your suggestion and it works as described.
Really appreciate your input!
Best regards,
Niko Neugebauer
when filtering for times between 9:00 and 18:00 you should use DATEPART(HOUR, DateKey) BETWEEN 9 AND 18 on the dbo.DatesSimple (native DateTime columns). This would reduce the CPU time by 40 – 50 %.
Drawback: works only for full hours. On the other side even a DATEPART(HOUR, DateKey) * 100 + DATEPART(MINUTE, DateKey) BETWEEN 915 AND 1830 would reduce the CPU by ~25 %.
Using CONVERT(VARCHAR, tww.geaendert_am, 108) BETWEEN ’09:00:00′ AND ’18:00:00′ would have only a minimal benefit.