Continuation from the previous 28 parts, starting from https://www.nikoport.com/2013/07/05/clustered-columnstore-indexes-part-1-intro/
One of the key performance factors for Columnstore Indexes is Segment Elimination. I have been presenting on this matter for quite a while, but never actually blogged about it.
Every Columnstore Index in SQL Server is separated into collection of Segments with information about the minimum and maximum values contained inside each of the segments is available in DMV sys.column_store_segments.
Every time we run a query against Columnstore Index, should it possible to avoid reading a Segment which does not contain pretended values – it will be done.
To see this in action, just following the setup:
create table dbo.MaxDataTable( c1 bigint, c2 numeric (36,3), c3 bit, c4 smallint, c5 decimal (18,3), c6 smallmoney, c7 int, c8 tinyint, c9 money, c10 float(24), c11 real, c12 date, c13 datetimeoffset, c14 datetime2 (7), c15 smalldatetime, c16 datetime, c17 time (7), c18 char(100), c19 varchar(100), c20 nchar(100), c21 nvarchar(100), c22 binary(8), c23 varbinary(8), c24 uniqueidentifier, ); GO -- Insert 2.000.000+ rows in order to get a couple Row Groups declare @i as int; declare @max as int; select @max = isnull(max(C1),0) from dbo.MaxDataTable; set @i = 1; begin tran while @i <= 2148576 begin insert into dbo.MaxDataTable default values set @i = @i + 1; end; commit; -- Update our table with some pretty random data with updTable as ( select * , row_number() over(partition by C1 order by C1) as rnk from dbo.MaxDataTable ) update updTable set C1 = rnk, C2 = ABS(CHECKSUM(NewId())) % 142359.0, C3 = 1, C4 = cast(ABS(CHECKSUM(NewId())) % 10000 as smallint), C5 = ABS(CHECKSUM(NewId())) % 242359.0, C6 = rnk / ABS(CHECKSUM(NewId())) % 242359.0, C7 = ABS(CHECKSUM(NewId())) % 2000000, C8 = ABS(CHECKSUM(NewId())) % 255, C9 = rnk / ABS(CHECKSUM(NewId())) % 242359.0, C10 = rnk / ABS(CHECKSUM(NewId())) % 242359.0, C11 = rnk / ABS(CHECKSUM(NewId())) % 242359.0, C12 = getDate(), C14 = DATEADD(day, (ABS(CHECKSUM(NEWID())) % 65530), 0), C15 = DATEADD(day, (ABS(CHECKSUM(NEWID())) % 65530), 0), C16 = DATEADD(day, (ABS(CHECKSUM(NEWID())) % 65530), 0), C17 = getDate(), C18 = cast( ABS(CHECKSUM(NewId())) % 242359.0 as char(25)), C19 = cast( ABS(CHECKSUM(NewId())) % 232659.0 as varchar(25)), C20 = cast( ABS(CHECKSUM(NewId())) % 242359.0 as nchar(25)), C21 = cast( ABS(CHECKSUM(NewId())) % 232659.0 as nvarchar(25)); -- Create a Clustered Columnstore Index create clustered columnstore index cci_MaxDataTable on dbo.MaxDataTable;
Now let's see what data distribution is existing between segments of the first column (c1):
select segment_id, row_count, base_id, min_data_id, max_data_id from sys.column_store_segments where column_id = 1;
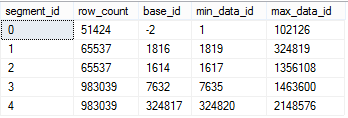 First of all of course we see that data is unsorted (which is as it should be inside Columnstore Indexes where ordering does not exist at all), but then I can clearly see that the number of rows in each of the 5 segments is being very far from being ideal.
First of all of course we see that data is unsorted (which is as it should be inside Columnstore Indexes where ordering does not exist at all), but then I can clearly see that the number of rows in each of the 5 segments is being very far from being ideal.
Now, let us run a query that will read data from every Row Group besides the very first one on the column C1. For this we shall read values superior 1,100,000 by using the following query:
select C4, count(C1) from dbo.MaxDataTable where C1 > 103000 group by C4;
This way we shall eliminate the first Segments of all columnns besides the C4 & C1.
Now comes the interesting question – how can we get to the point of confirming that Segment elimination actually happened?
We cold use the Extended Events, but I will use a couple of trace flags to show it:
-- Turn on trace dbcc traceon(3605, -1) with no_infomsgs; -- Turn on segment elimination information dbcc traceon(646, -1) with no_infomsgs; -- Let us clear Error log dbcc errorlog with no_infomsgs; go -- Let us consult information inside Error Log exec sys.xp_readerrorlog go -- A simple query select C4, count(C1) from dbo.MaxDataTable where C1 > 103000 ---between 1 and 5 group by C4; go -- Turn off segment elimination information dbcc traceoff(3605,646,-1) with no_infomsgs; go -- View Error Log information exec sys.xp_readerrorlog;
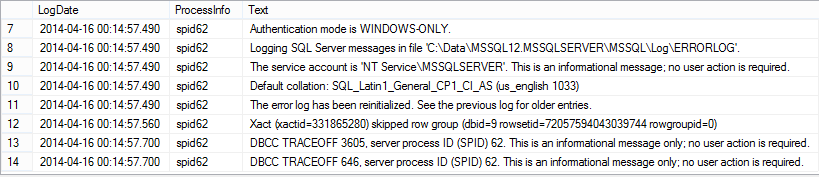 As you can see on the screenshot the only Segment eliminated was with id = 0.
As you can see on the screenshot the only Segment eliminated was with id = 0.
This functionalities are well-known since SQL Server 2012 and Segment has been described for Nonclustered Columnstore Indexes long time ago.
Getting Better Segment Elimination
The tricky part comes now with SQL Server 2014 to get better Segment elimination, which will allow our Columnstore Indexes Performance - because we shall read only data which is matter thus improving IO performance greatly.
How can we can achieve sorted order in our Columnstore table ?
Every time we rebuild our table data is being shifted between Row Groups as I have shown in previous blog posts...
Well, there is a way ;)
Quite limited right now, but I hope that it's limitation should be removed in the upcoming patches. I guess that this limitation does not exist in PDW. :)
To get ordered data we shall experiment with Contoso Retail DW, my favourite database:
My Setup for comfortable working, since I constantly do changes to my version:
USE [master] alter database ContosoRetailDW set single_user with rollback immediate; RESTORE DATABASE [ContosoRetailDW] FROM DISK = N'C:\Install\ContosoRetailDW.bak' WITH FILE = 1, MOVE N'ContosoRetailDW2.0' TO N'C:\DATA\ContosoRetailDW.mdf', MOVE N'ContosoRetailDW2.0_log' TO N'C:\DATA\ContosoRetailDW.ldf', NOUNLOAD, STATS = 5; alter database ContosoRetailDW set multi_user; USE [master] GO ALTER DATABASE [ContosoRetailDW] SET COMPATIBILITY_LEVEL = 120 GO ALTER DATABASE [ContosoRetailDW] MODIFY FILE ( NAME = N'ContosoRetailDW2.0', SIZE = 5120000KB , FILEGROWTH = 512000KB ) GO ALTER DATABASE [ContosoRetailDW] MODIFY FILE ( NAME = N'ContosoRetailDW2.0_log', SIZE = 2560000KB , FILEGROWTH = 512000KB ) GO USE [ContosoRetailDW] GO EXEC dbo.sp_changedbowner @loginame = N'sa', @map = false GO
Now we need to drop all unique constraints (Primary & Foreign Keys) of our FactOnlineSales table:
ALTER TABLE dbo.[FactOnlineSales] DROP CONSTRAINT [FK_FactOnlineSales_DimCurrency]; ALTER TABLE dbo.[FactOnlineSales] DROP CONSTRAINT [FK_FactOnlineSales_DimCustomer]; ALTER TABLE dbo.[FactOnlineSales] DROP CONSTRAINT [FK_FactOnlineSales_DimDate]; ALTER TABLE dbo.[FactOnlineSales] DROP CONSTRAINT [FK_FactOnlineSales_DimProduct]; ALTER TABLE dbo.[FactOnlineSales] DROP CONSTRAINT [FK_FactOnlineSales_DimPromotion]; ALTER TABLE dbo.[FactOnlineSales] DROP CONSTRAINT [FK_FactOnlineSales_DimStore]; ALTER TABLE dbo.[FactOnlineSales] DROP CONSTRAINT [PK_FactOnlineSales_SalesKey];
Now let us create our Clustered Columnstore Index:
create clustered columnstore index [PK_FactOnlineSales_SalesKey] on dbo.FactOnlineSales;
To investigate the situation with the first column Segments, let us execute the following script:
select segment_id, row_count, base_id, min_data_id, max_data_id from sys.column_store_segments where column_id = 1;
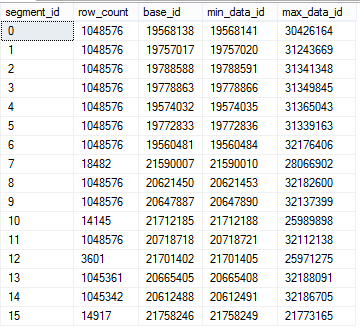 We can see situation when data is completely unordered, as in the first example in this article. Should we run any query using C1 as predicate - potentially there won't be a very effective Segment elimination because the same ranges of data exist in a lot of different Segments, but if we could only get them sorted ...
We can see situation when data is completely unordered, as in the first example in this article. Should we run any query using C1 as predicate - potentially there won't be a very effective Segment elimination because the same ranges of data exist in a lot of different Segments, but if we could only get them sorted ...
Let us view from a different angle - let's create a traditional rowstore clustered index, which is sorted and than create a Clustered Columnstore Index:
create unique clustered index [PK_FactOnlineSales_SalesKey] on dbo.FactOnlineSales (OnlineSalesKey) with (DROP_EXISTING = ON, DATA_COMPRESSION = PAGE);
Now all data is being sorted on our first column (OnlineSalesKey), and so we can create Clustered Columnstore Index, which should you have the sorted order :)
create clustered columnstore index [PK_FactOnlineSales_SalesKey] on dbo.FactOnlineSales with (DROP_EXISTING = ON);
To verify the improvement please execute the following script:
select segment_id, row_count, base_id, min_data_id, max_data_id from sys.column_store_segments where column_id = 1;
These are the results that I do observe on my computer:
 Stop! This is not exactly what we were waiting for! This was absolutely not what I have expected! Those maximums and minimums are all going wrong direction! I see some patterns, but ... :(
Stop! This is not exactly what we were waiting for! This was absolutely not what I have expected! Those maximums and minimums are all going wrong direction! I see some patterns, but ... :(

But what if we do the same operation but this time running Clustered Columnstore Indexes creation in MAXDOP 1 mode, using just 1 core thus guaranteeing synchronisation:
create unique clustered index [PK_FactOnlineSales_SalesKey] on dbo.FactOnlineSales (OnlineSalesKey) with (DROP_EXISTING = ON, DATA_COMPRESSION = PAGE); create clustered columnstore index [PK_FactOnlineSales_SalesKey] on dbo.FactOnlineSales with (DROP_EXISTING = ON, MAXDOP = 1);
Here are the results, and yes we have our first column ordered inside the segments.
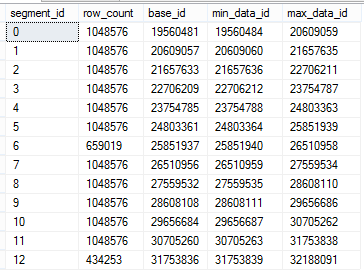
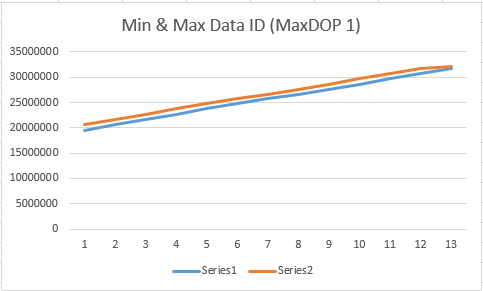
Now I can see a clear way to get a better Segment elimination on a specific column - create a rowstore clustered index and then a clustered columnstore index. Naturally you will have natural disadvantages, such as worse compression (less repeating data), and of course you will be sorting on 1 column only, but it might be secondary to the advantages of the Segment elimination.
I am definitely opening a Connect Item on this one, since there should not be any good reason for such behaviour of the parallel process for Clustered Columnstore Indexes creation - nobody would dream about creating such index on a 20 Billion Rows table in a single thread.
to be continued with Clustered Columnstore Indexes – part 30 (“Bulk Load API Magic Number”)
Thanks for the information, this was very helpful and I observed the same behavior. Did you end up filing the Connect issue to improve this behavior for parallel columnstore index creation? If so, would you mind posting the link so I can up-vote it?
I also made a note on the relevant MSFT page (which does not mention the MAXDOP 1 requirement observed here). It seems they moderate comments, so I’m not sure if it will have shown up yet, but here is the page:
http://social.technet.microsoft.com/wiki/contents/articles/5823.multi-dimensional-clustering-to-maximize-the-benefit-of-segment-elimination.aspx
Hi Geoff,
thank you for the comment.
Here is the Connect to be upvoted: https://connect.microsoft.com/SQLServer/feedback/details/912452/multi-threaded-rebuilds-of-clustered-columnstore-indexes-break-the-sequence-of-pre-sorted-segment-ordering-order-clustering
Sunil Agarwal has already publicly admitted (during 24 Hours of PASS 2014) that Microsoft has got enough requests on this item and that they are potentially evaluating this improvement.
Let us hope. :)
Thanks for the link; I voted it up and added a comment. I think my ideal behavior would be to have an optional “order by” clause to control the ordering of initial columnstore creation, which would allow us to bypass the original clustered index entirely and would control the ordering of row groups within each partition. But simply preserving clustered index order with parallel columnstore creation would be very valuable even without that additional option.
I’m liking the new columnstore functionality overall. It was too limited in 2012 to be usable for our workloads, especially in being frequently unable to take advantage of batch mode. However, my initial testing shows 2014 to be far superior in this regard.
I think that perhaps the next on my wish list is the ability to support clustered columnstore indexes for tables with computed columns. We frequently do things like compute cost as “sales – margin” in order to reduce the footprint on our fact tables; while these things could be done via a view, it would be nice to have the computed column option!
Thanks again for the detailed series on columnstores.
Hi Geoff,
thank you for your vote and for the kind words – I really appreciate them.
A very interesting idea on the Order By. :)
It would be a very practical, but of course there would be enough people posting scripts with it’s usage, without any understanding what it really does. I guess Microsoft would prefer us to do CL + CCI combination, since it gives them less features to support and worry about. :)
I am asking myself if Microsoft will join Nonclustered & Clustered Columnstore into TheColumnstore in the next version of SQL Server. When they implement the lookups, there will be an opportunity to join both implementation (ignoring the words Nonclustered & Clustered in T-SQL), and then eventually implement some kind of extra ordering. ;)
Regarding Columnstore & Computed Columns – I keep hearing people requesting it and I personally guess that it is just a question of time, which means next version of SQL Server. They did awesome job improving Data Type support in SQL Server 2014, but it is still far from being complete.
Afternoon Niko,
Unless I am missing something I was wondering how you managed to build a unique clustered index followed by a Clustered ColumnStore Index without dropping the former clustered index.
I assumed a drop was in order therefore I did, but found that the data is not actually physically sorted, i.e.
Select 1000 * from with cluster index are in order, dropping the index reverts back to a random order.
Subsequent segment analysis shows overlapping of min_data_id max_data_ids.
Paul,
The combination of (DROP_EXISTING = ON, MAXDOP = 1) may provide the functionality you are looking for. DROP_EXISTING allows you to build a clustered columnstore index directly from a clustered rowstore index of the same name, without dropping that index. Doing so in a single-threaded manner retains the order of the original clustered rowstore index.
Morning Geoff, appreciate the quick response.
Yes, that has done the trick, but isn’t this functionality a little naughty, allowing the replacing of a Clustered Index with a Clustered Columnstore Index, and without any warning. The index naming may also become unclear as I tend to prefix a Clustered Columnstore with CCI. I suppose the Clustered Index is only temporary.
My immediate concern now is how this affects our plan to justify moving to 2016, i.e. if we implement this workaround on 2014, how does 2016 behave with this scenario, will it for instance be tighter and not allow different index types to override each other. Are we just building technical debt. I hope the sorting issue is resolved in 2016.
We are still in the early stages of looking at benefits, I am particularly interested in the performance boost on windows and analytical aggregation functions (detailed by some of the later articles on this site).
One observation – I assume segment elimination is only going to be available on the first column due to left to right column inclusion/scanning. We filter heavily on 3 separate columns – just a date or just time and demographic with a wide date range. I have now seen segment elim on Date as the first column and using Batch mode, time and/or demographic on the other hand (with a wide date range) reverts back to row execution mode (though adding a group by invokes the Batch performance boost)
BTW – forgot to add to my original post – excellent site.
Yes, it’s a little bit awkward that the CI is replaced by a CCI. The Books Online documentation for DROP_EXISTING explicitly says that you cannot go from CCI => CI, so I guess in order to go back you would need to drop the index.
Precise control of the clustered columnstore build sort order is not resolved yet in SQL 2016, at least to my knowledge. Perhaps in a future update, we’ll see. However, I would expect your issue of seeing row mode used unexpectedly is likely addressed in 2016 as batch mode has been a big focus of development.
In terms of multi-dimensional segment elimination, I’m not sure there are any perfect options. But here are a few ideas:
* If the data set is quite large, you can potentially partition by date and then sort your data by a different column in order to have partition elimination on date and segment elimination (within each partition) on a secondary column. Just make sure that the partitions are wide enough that each partition has millions of rows (enough for multiple segments within the partition).
* Alternatively, if read performance is absolutely crucial and the data is mostly read-only, you could build multiple copies of the table and sort each one for different segment elimination. You queries would then need to know which one to target, which might be a pain.
* You could also experiment with b-tree non-clustered indexes on one or two of the dimensions that are not optimized for segment elimination. It seems that tables that mix a CCI and additional non-clustered indexes are well supported in SQL 2016. How successful this would be probably depends on how selective your queries are on those additional dimensions.
Thanks, I really appreciate your time. Will have to look at building additional indexes once we have a 2016 environment to play with.
Hi Geoff,
thank you for the very competent replies!
Best regards,
Niko Neugebauer
Hi Paul,
the DROP_EXISTING hint works correctly, as I interpret it – replacing a Clustered Rowstore Index with another type of a Clustered Index.
The naming convention can be one big pain, but you can easily correct it with the sp_rename function.
The functionality you are asking (sorted rebuilds) is definitely coming and there are already error messages to be found within the core of SQL Server 2016, but at the RTM it is not enabled yet. Let us hope that it will be released very, very soon.
In the mean time, consider doing this trick manually or with the help of the maintenance solution within CISL (open source Columnstore Library – https://github.com/NikoNeugebauer/CISL).
Regarding the multiple segment elimination – it works out of the box. You can do sorting on 2 columns, with the help of the technic, described here : http://www.nikoport.com/2014/12/02/clustered-columnstore-indexes-part-45-multi-dimensional-clustering/
Best regards,
Niko Neugebauer
Hi Niko,
In your examples you create the clustered index for sorted data with DATA_COMPRESSION=PAGE. I guess we can get rid of that compression, right? since we are anyways going to recompress using CS?
Thanks,
Avinash
create unique clustered index [PK_FactOnlineSales_SalesKey] on dbo.FactOnlineSales (OnlineSalesKey)
with (DROP_EXISTING = ON, DATA_COMPRESSION = PAGE);
Avinash,
Yes, you can use any of the rowstore compression options (NONE, ROW, PAGE) for your intermediate clustered b-tree index.
One thing to keep in mind: If your table is large and is already compressed (e.g., is columnstore, or already has page compression), replacing the existing index with an uncompressed index will significantly expand the size of the table and you’ll need to be careful that you don’t run out of disk space.
However, using NONE or ROW does avoid the need for expensive single-threaded decompression of the intermediate clustered b-tree index if you’re using the (MAXDOP 1) hint to create your “ordered” clustered columnstore. You’d have to test and judge for yourself which option works best for your data and hardware.
Hi Geoff,
Thanks for your response. The disk space consideration is indeed interesting and could be helpful in many cases. Please look at my follow up questions below and let me know your opinion.
Thanks,
Avinash
Hi Avinash,
yeap, you can use any/none compression on the Rowstore Index before creating Clustered Columnstore Index.
I find it faster to use compression than not. Since 2016 SP1 every edition supports it.
Best regards,
Niko
Hi Niko,
I have two follow up questions:
1. Why is it faster with the compression (even though there is an overhead of decompression)?
2. What would be a good strategy to follow if there are other Non Clustered Indexes (NCI) on the table? Is it better to create the NCI after creating the CCI (without the MAXDOP option). Assume if there were already other NCIs present then will replacing the clustered index with CCI trigger the recreation of the NCI (since the actual data is getting rearranged). In this case will the NCI also gets created with MAXDOP 1, thus making it’s creating unnecessarily slow?
Hi Avinash,
1. The disk is almost always (99.9% in my experience) the slowest element in the system. Getting 2-3 X improvement on the disk space imprint will improve the overall performance of the process, just because you will access less times your slowest element.
2. Drop/Disable your Rowstore NCCIs and rebuild them after the CCI build. Every Data Warehouse developer will tell you that this is the basic practice. You can rebuild NCCIs with more cores (MAXDOP) than just 1, it will have less impact than on CCI.
Overall, use partitioning – it will lower the impact and you won’t have to rebuild your whole table every time your load some data.
Best regards,
Niko
Niko,
Thanks for blogging this. I have now implemented this in my production system and we achieved 5x-10x performance gain. We have more than 30 billion rows. Query which used to take 8 minutes now takes under 20 seconds! We already had our tables partitioned which made the conversion easy.
Thanks,
Avinash
Hi Avniash,
it is great to hear that you were successful !
Best regards,
Niko
Hi Niko
From docs of MS, its not very evident, which SQL version (onwards) has Segment Elimination feature available. Is this available in 2014?
I have 2 segments with respective min and max limits for a particular column B, whereas the table is partitioned on column A. I gave a query with both A and B in the WHERE clause whose result-set is limited to only one of the two segments within the candidate partition, expecting Statistics IO to confirm one segment is skipped. However, this was not the case. I don’t see SEGMENT SKIPPED message in Statistics. Is there something wrong or is it that 2014 does not have Segment Skipped feature?
thanks
Hi,
the Segment Elimination exists since the very first version (Sql Server 2012), but until Sql Server 2016, only by using the Extended Events could one determine if it took place or not. Starting with Sql Server 2016, the support for SET STATISTICS IO command was expanded to include this information in the output of that command.
Best regards,
Niko Neugebauer
Hi
I noticed a strange thing I can’t explain on SQL 2016 Enterprise. I have a dbo.Event table with clustered columnstore index that is sorted on [Date] column (I used approach described in this blog post to sort the data). When I query for some rows with [Date] > xxx then segment elimination is applied:
SELECT * FROM dbo.Event AS E WHERE E.[Date] > ‘20191014’ — gives “Table ‘Event’. Segment reads 1, segment skipped 3.”
But when I ask SQL for the MAX([Date]) then it reads all segments:
SELECT MAX([Date]) FROM dbo.Event — gives “Table ‘Event’. Segment reads 4, segment skipped 0.”
I thought that the latter query would be very simple and effective as SQL should just read the last segment. Am I missing something here?
Piotr
Hi Piotr,
since Columnstore Indexes are not sorted and are not guaranteed to be sorted – there is no way QP can simply select one single Segment will be to satisfy the query.
If you have any Delta-Stores, they will have to be processed as well.
Best regards,
Niko Neugebauer
Hi Niko,
thanks for the answer. Yup, I forgot about the Delta-Store but apart from it I thought that the QP would just read max_data_id for every Segment and then scan data only from the one with the highest max_data_id as it is the Segment that has the max value (not including Delta-Store). What’s the point of reading other Segments?
For example, let’s assume there are 4 Segments with the following min_data_id and max_data_id (let’s assume that they are ints):
Segment 1; 1 – 100;
Segment 2: 34 – 89;
Segment 3: 23 – 111;
Segment 4: 58 – 134;
So looking and max_data_id I would indicate Segment 3 to scan (plus Delta-Store) to find the max value. Or maybe min_data_id and max_data_id might not be accurate, e.g. after deletes?
Best regards,
Piotr
Hi Piotr,
Precisely that – the deleted rows might make your Segment 4 to contain the real maximum of 58, while the segment 1 will have 100.
Plus do not forget that the distancing of the Query Optimizer from the internal structure of the Columnstore can cause other unverified assumptions that are really internal down to the implementation.
Current Azure Synapse Analytics implementation of the sorted Columnstore Indexes with some potential additional improvements for the processing like after executing the sort operation that was uninterrupted and had no overlapping spills – might provide some kind of a guarantee of the non-overlapping segments and a true maximum & minimum.
Let’s hope it will make into vNext …
Best regards,
Niko