Continuation from the previous 44 parts, starting from https://www.nikoport.com/2013/07/05/clustered-columnstore-indexes-part-1-intro/
I have blogged a couple times (part 29 – “Data Loading for Better Segment Elimination”, part 34 – “Deleted Segments Elimination” ) about the importance of the Segment Elimination, I have decided to show you something that I personally consider to be beyond awesome feature in Columnstore Indexes – I call this thing, MultiDimensional Clustering(Ordering). I have spent some time delaying the post until the PASSCamp 2014, but now it has officially started I am dedicating it to this amazing event.
Notice, that this technic is valid for Nonclustered Columnstore Indexes as well as the Clustered Columnstore Indexes:
Let us consider the following scenario: we have an instance with SQL Server 2012+ where we have a partitioned table that is being hammered by a number of different queries.
To improve the performance we have identified the most common predicate in our SELECT queries and so decided to implement Segment Clustering to improve our performance.
This has helped us a lot but we need a further improvement, because to be honest, there are almost no such situations when we have just 1 query that needs to be tuned. :)
In this example we have found 2 queries that need to be optimised and surprise – even though they have 1 common predicate (DateKey), they include a second predicate that is different for each of the queries:
select sum(SalesAmount) from dbo.FactOnlineSales where (DateKey>'2008-01-01' and DateKey <'2009-01-01') and StoreKey = 199; select sum(SalesAmount) from dbo.FactOnlineSales where (DateKey>'2009-01-01' and DateKey <'2010-01-01') and SalesAmount > 1000;
But let’s not hurry to much and start with our Segment Clustering implementation:
As so often, I will play with a Contoso Retail DW, my favourite free database.
Right after restoring the database, I will drop the foreign & primary keys on the FactOnlineSales table, on which we shall run our experiments:
USE [master]
alter database ContosoRetailDW
set SINGLE_USER WITH ROLLBACK IMMEDIATE;
RESTORE DATABASE [ContosoRetailDW]
FROM DISK = N'C:\Install\ContosoRetailDW.bak' WITH FILE = 1,
MOVE N'ContosoRetailDW2.0' TO N'C:\Data\ContosoRetailDW.mdf',
MOVE N'ContosoRetailDW2.0_log' TO N'C:\Data\ContosoRetailDW.ldf',
NOUNLOAD, STATS = 5;
alter database ContosoRetailDW
set MULTI_USER;
GO
use ContosoRetailDW;
ALTER TABLE dbo.[FactOnlineSales] DROP CONSTRAINT [FK_FactOnlineSales_DimCurrency]
ALTER TABLE dbo.[FactOnlineSales] DROP CONSTRAINT [FK_FactOnlineSales_DimCustomer]
ALTER TABLE dbo.[FactOnlineSales] DROP CONSTRAINT [FK_FactOnlineSales_DimDate]
ALTER TABLE dbo.[FactOnlineSales] DROP CONSTRAINT [FK_FactOnlineSales_DimProduct]
ALTER TABLE dbo.[FactOnlineSales] DROP CONSTRAINT [FK_FactOnlineSales_DimPromotion]
ALTER TABLE dbo.[FactOnlineSales] DROP CONSTRAINT [FK_FactOnlineSales_DimStore]
ALTER TABLE dbo.[FactOnlineSales] DROP CONSTRAINT [PK_FactOnlineSales_SalesKey]
I have already studied the data inside our table and decided to create the following partitions & filegroups: 1 for Archived Old Data, and 1 partition per each of the Years with data – 2007, 2008, 2009 & 2010:
alter database ContosoRetailDW add filegroup OldColumnstoreData; GO alter database ContosoRetailDW add filegroup Columnstore2007; GO alter database ContosoRetailDW add filegroup Columnstore2008; GO alter database ContosoRetailDW add filegroup Columnstore2009; GO alter database ContosoRetailDW add filegroup Columnstore2010; GO
The following script shall add 1 physical file to each of the above defined file groups:
-- Add 1 datafile to each of the respective filegroups
alter database ContosoRetailDW
add file
(
NAME = 'old_data',
FILENAME = 'C:\Data\old_data.ndf',
SIZE = 10MB,
FILEGROWTH = 125MB
) to Filegroup [OldColumnstoreData];
GO
alter database ContosoRetailDW
add file
(
NAME = '2007_data',
FILENAME = 'C:\Data\2007_data.ndf',
SIZE = 500MB,
FILEGROWTH = 125MB
) TO Filegroup Columnstore2007;
GO
alter database ContosoRetailDW
add file
(
NAME = '2008_data',
FILENAME = 'C:\Data\2008_data.ndf',
SIZE = 500MB,
FILEGROWTH = 125MB
) to Filegroup Columnstore2008;
GO
alter database ContosoRetailDW
add file
(
NAME = '2009_data',
FILENAME = 'C:\Data\2009_data.ndf',
SIZE = 500MB,
FILEGROWTH = 125MB
) TO Filegroup Columnstore2009;
GO
alter database ContosoRetailDW
add file
(
NAME = '2010_data',
FILENAME = 'C:\Data\2010_data.ndf',
SIZE = 500MB,
FILEGROWTH = 125MB
) TO Filegroup Columnstore2010;
GO
Now that we have our file structure defined, let us create partition function and partition scheme:
-- Create the Partitioning scheme
create partition function pfOnlineSalesDate (datetime)
AS RANGE RIGHT FOR VALUES ('2007-01-01', '2008-01-01', '2009-01-01','2010-01-01');
-- Define the partitioning function for it, which will be mapping data to each of the corresponding filegroups
create partition scheme ColumstorePartitioning
AS PARTITION pfOnlineSalesDate
TO ( OldColumnstoreData, Columnstore2007, Columnstore2008, Columnstore2009, Columnstore2010 );
Now it is the right time to create our Columnstore Index, which will need first a presence of a traditional rowstore Clustered Index, which will physically move data into the right partitions:
Create Clustered Index PK_FactOnlineSales
on dbo.FactOnlineSales (DateKey)
with (DATA_COMPRESSION = PAGE)
ON ColumstorePartitioning (DateKey);
-- Create Partitioned Clustered Columnstore Index
Create Clustered Columnstore Index PK_FactOnlineSales on dbo.FactOnlineSales
with (DROP_EXISTING = ON, maxdop = 1)
ON ColumstorePartitioning (DateKey)
At this point we should check the situation with the Segment Clustering on the DateKey column (id = 2) that we have partitioned our table on:
select partition_number, segment_id, row_count, base_id, min_data_id, max_data_id
from sys.column_store_segments seg
inner join sys.partitions part
on seg.partition_id = part.partition_id
where column_id = 2
and part.object_id = object_id('FactOnlineSales')
order by partition_number, segment_id;
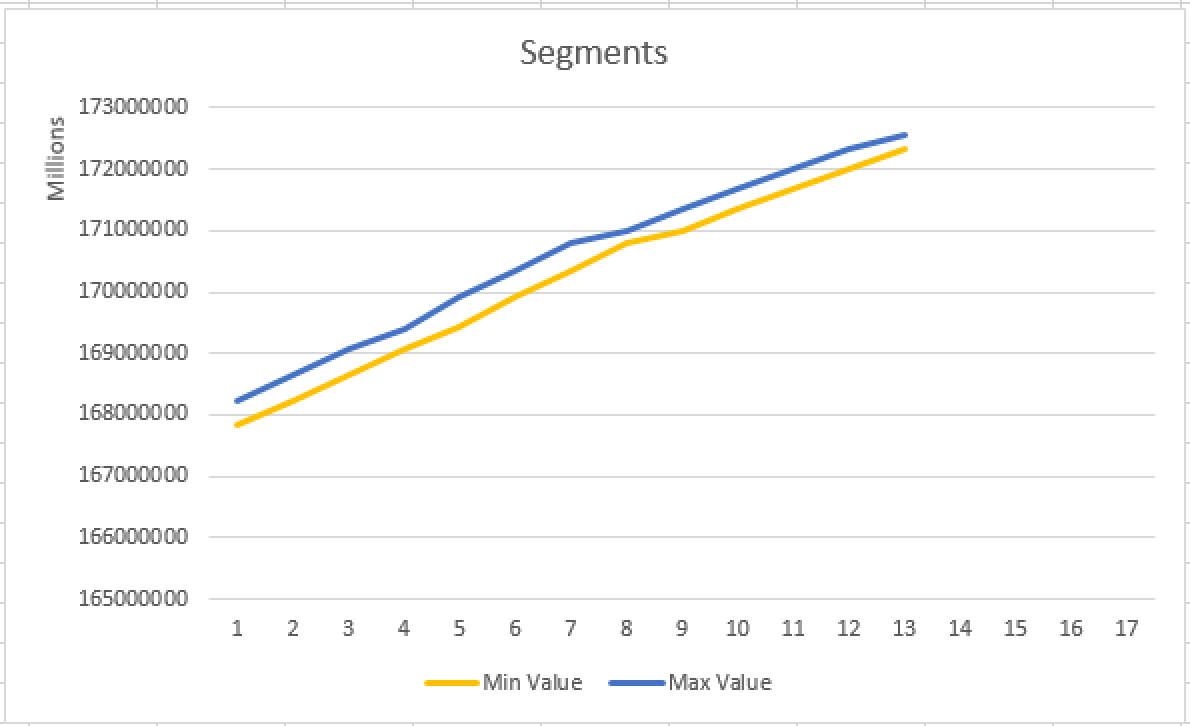
It looks quite fine and we have done an optimisation to our system at this point.
It is perfectly aligned for the Column Number 2 (DateKey) on which we have partitioned our Clustered Columnstore Index, but what about the 2 other columns (StoreKey (Column 3) & SalesAmount(Column 11)):
select partition_number, segment_id, row_count, base_id, min_data_id, max_data_id
from sys.column_store_segments seg
inner join sys.partitions part
on seg.partition_id = part.partition_id
where column_id = 3
and part.object_id = object_id('FactOnlineSales');
select partition_number, segment_id, row_count, base_id, min_data_id, max_data_id
from sys.column_store_segments seg
inner join sys.partitions part
on seg.partition_id = part.partition_id
where column_id = 11
and part.object_id = object_id('FactOnlineSales');
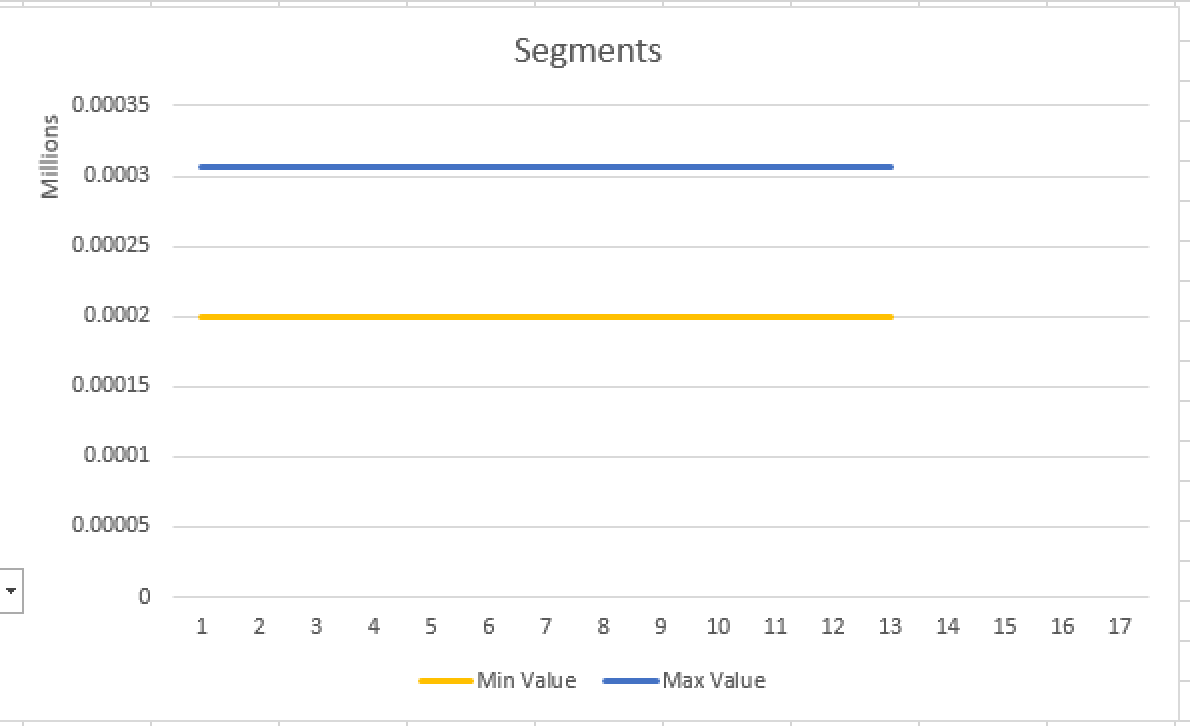
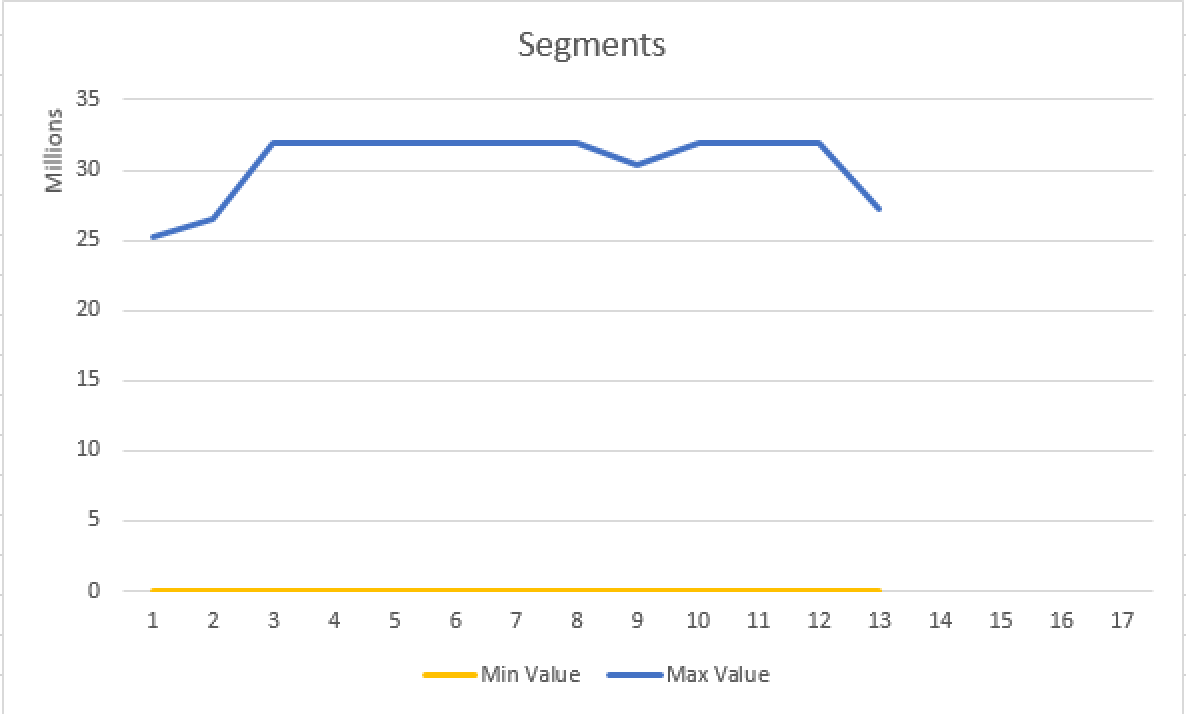
It is very clear that there is no alignment whatsoever involved, because we have partitioned our table on the different column (DateKey).
Let us establish a baseline for the IO performance of our queries:
set statistics io on select sum(SalesAmount) from dbo.FactOnlineSales where (DateKey>'2008-01-01' and DateKey <'2009-01-01') and StoreKey = 199; select sum(SalesAmount) from dbo.FactOnlineSales where (DateKey>'2009-01-01' and DateKey <'2010-01-01') and SalesAmount > 1000;
Table 'FactOnlineSales'. Scan count 1, logical reads 1209, physical reads 0, read-ahead reads 0, lob logical reads 0, lob physical reads 0, lob read-ahead reads 0. Table 'FactOnlineSales'. Scan count 1, logical reads 1325, physical reads 0, read-ahead reads 0, lob logical reads 0, lob physical reads 0, lob read-ahead reads 0.
This means we have 1209 logical reads & 1325 logical reads respectively. Is this the best that we can do?
Partitioning information:
Let’s see how the data is spread around the different partitions:
-- Partitioning Information SELECT $PARTITION.pfOnlineSalesDate(DateKey) AS Partition, COUNT(*) AS [Rows Count] , Min(Year(DateKey)) as [Min], Max(Year(DateKey)) as [Max] FROM dbo.FactOnlineSales GROUP BY $PARTITION.pfOnlineSalesDate(DateKey) ORDER BY Partition ;
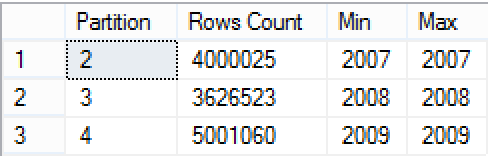 It’s clear now that we actually will be concentrating our job on the partitions 3 & 4 respectively, since they include the data that interest us for those 2 queries optimization.
It’s clear now that we actually will be concentrating our job on the partitions 3 & 4 respectively, since they include the data that interest us for those 2 queries optimization.
Query 1 (Partition 3):
We should concentrate on the first query, looking at the data between in the year 2008 and thus let’s try to optimize it first (in practice the order of optimization does not matter as long as different partitions are being involved):
Actually, what happens if at this point we reload our partition?
Clustered Columnstore Indexes should allow us to do that without any problem:
-- Load Data from the year 2008 SELECT * into dbo.FactOnlineSales2008 FROM dbo.FactOnlineSales WHERE $PARTITION.pfOnlineSalesDate(DateKey) = 3;
And what if we build a traditional row store clustered index on that table before building a Clustered Columnstore Index and switching it in:
-- Creation of a traditional Clustered Index
Create Clustered Index PK_FactOnlineSales2008
on dbo.FactOnlineSales2008 (StoreKey)
WITH (DATA_COMPRESSION = PAGE)
on Columnstore2008;
-- Create Partitioned Clustered Columnstore Index
Create Clustered Columnstore Index PK_FactOnlineSales2008 on dbo.FactOnlineSales2008
with (DROP_EXISTING = ON, MAXDOP = 1);
Notice that we are building Clustered Columnstore right after the rowstore clustered index that have sorted that data on the disk, and that MAXDOP = 1 is extremely important as long Microsoft has not fixed bug with the Segment Clustering.
Now we are ready to switch the data in, but before that we shall remove all the copied data from the year 2008:
delete FROM dbo.FactOnlineSales WHERE $PARTITION.pfOnlineSalesDate(DateKey) = 3;
Before switching the data from the table dbo.FactOnlineSales2008 into the main one, we need to add a constraint that will guarantee the boundaries of the data contained inside the table:
alter table dbo.FactOnlineSales2008 add Constraint CK_FactOnlineSales2008_Year CHECK (DateKey>='2008-01-01' and DateKey <'2009-01-01');
Time to switch in the data:
ALTER TABLE FactOnlineSales2008 SWITCH TO FactOnlineSales PARTITION 3;
Surprise, it worked! :)
Let’s check our structure, which should show us Segment Clustering, based on the 3rd partition (we have data only in the partitions 2,3,4):
-- Check out the structure
select partition_number, segment_id, row_count, base_id, min_data_id, max_data_id
from sys.column_store_segments seg
inner join sys.partitions part
on seg.partition_id = part.partition_id
where column_id = 3
and part.object_id = object_id('FactOnlineSales')
order by partition_number, segment_id;
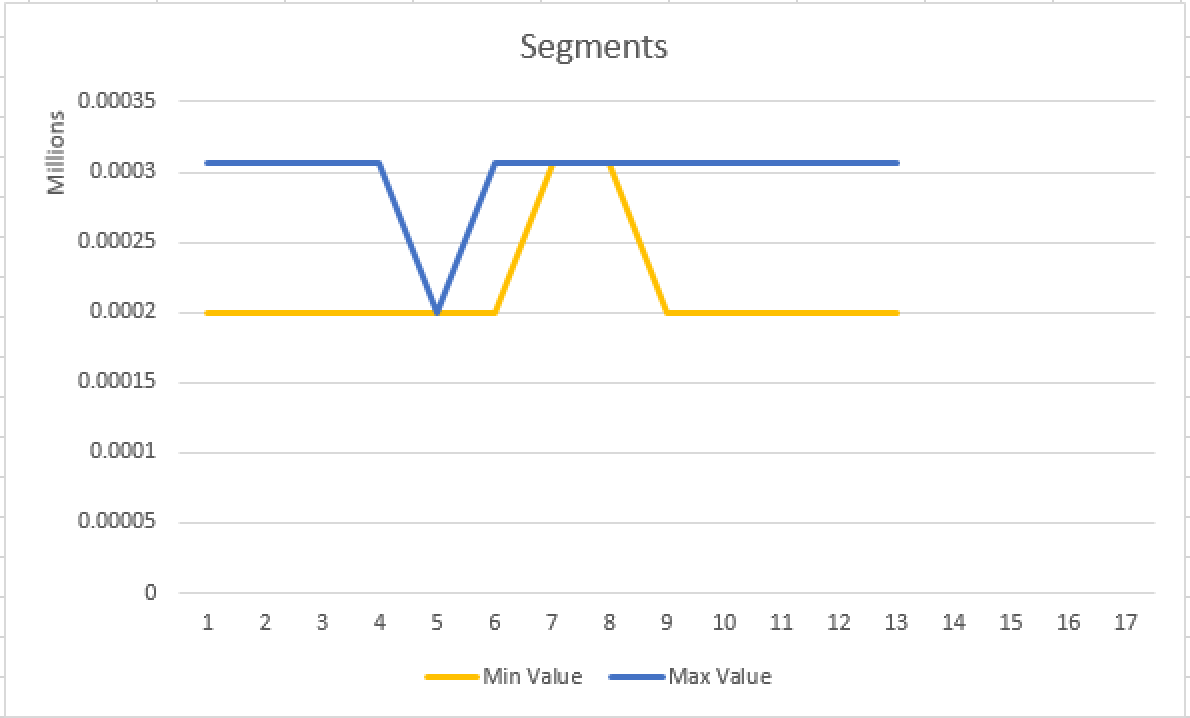 Yeap, without any denial we have our Segment Clustering working for the column StoreKey which just have 3 distinct values for the specified partition, but still works perfectly!
Yeap, without any denial we have our Segment Clustering working for the column StoreKey which just have 3 distinct values for the specified partition, but still works perfectly!
Let’s run our first query again:
set statistics io on select sum(SalesAmount) from dbo.FactOnlineSales where (DateKey>'2008-01-01' and DateKey <'2009-01-01') and StoreKey = 199;
Table 'FactOnlineSales'. Scan count 1, logical reads 696, physical reads 0, read-ahead reads 0, lob logical reads 0, lob physical reads 0, lob read-ahead reads 0.
We are down from 1209 logical reads to 696 logical reads.
This means that without changing a bit of the data on the partition level we have managed to improve the IO in almost 2 times!
Do not forget that IO in Columnstore Indexes has a strong relationship to the Memory Bandwidth as well as the number of rows processed in a Batch at once, concepts explained in Clustered Columnstore Indexes – part 42 (“Materialisation”).
Query 2 (Partition 4):
Our first query is optimised, and so we can turn our attention to our to the tuning of the second query, which has a predicate on SalesAmount column:
-- Load Data from the year 2009
SELECT *
into dbo.FactOnlineSales2009
FROM dbo.FactOnlineSales
WHERE $PARTITION.pfOnlineSalesDate(DateKey) = 4;
-- Create Rowstore Clustered Index
Create Clustered Index PK_FactOnlineSales2009
on dbo.FactOnlineSales2009 (SalesAmount)
WITH (DATA_COMPRESSION = PAGE)
on Columnstore2009;
-- Create Partitioned Clustered Columnstore Index
Create Clustered Columnstore Index PK_FactOnlineSales2009 on dbo.FactOnlineSales2009
with (DROP_EXISTING = ON, MAXDOP = 1);
-- Remove all data from the year 2009 from the original table
delete FROM dbo.FactOnlineSales
WHERE $PARTITION.pfOnlineSalesDate(DateKey) = 4;
-- Add a necessary constraint for ensuring that the table is correctly guaranteeing that the data belongs to the correct period of time
alter table dbo.FactOnlineSales2009
add Constraint CK_FactOnlineSales2009_Year CHECK (DateKey>='2009-01-01' and DateKey <'2010-01-01')
-- Switch In
ALTER TABLE FactOnlineSales2009
SWITCH TO FactOnlineSales PARTITION 4;
What about the internal structure – let's check on it:
-- Check out the structure
select partition_number, segment_id, row_count, base_id, min_data_id, max_data_id
from sys.column_store_segments seg
inner join sys.partitions part
on seg.partition_id = part.partition_id
where column_id = 11
and part.object_id = object_id('FactOnlineSales')
order by partition_number, segment_id;
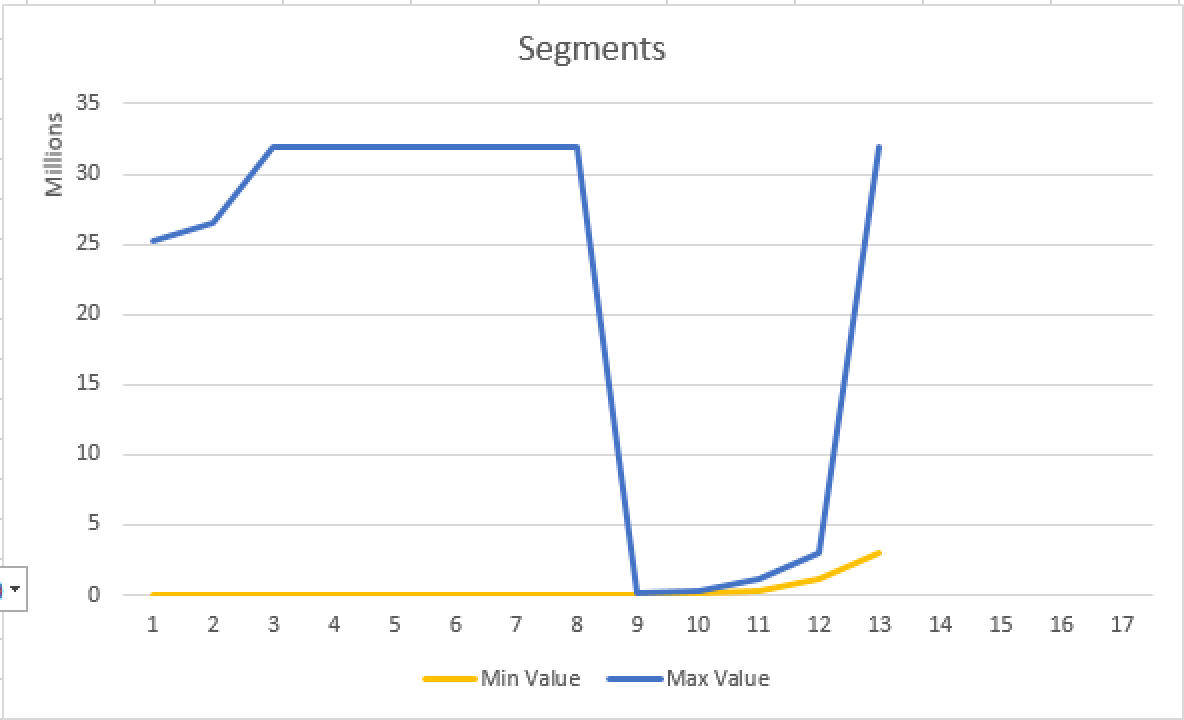 You can clearly see that starting from the 9th Segment the alignment is perfect – we have got a different Segment Clustering for the 4th partition here. Notice that since we did not touched the data at the other partitions, that data is still perfectly aligned on the StoreKey column for the 1st query.
You can clearly see that starting from the 9th Segment the alignment is perfect – we have got a different Segment Clustering for the 4th partition here. Notice that since we did not touched the data at the other partitions, that data is still perfectly aligned on the StoreKey column for the 1st query.
That’s enough of speaking, let’s run our first query again:
set statistics io on select sum(SalesAmount) from dbo.FactOnlineSales where (DateKey>'2009-01-01' and DateKey <'2010-01-01') and SalesAmount > 1000;
Our results here are :
Table 'FactOnlineSales'. Scan count 1, logical reads 344, physical reads 0, read-ahead reads 0, lob logical reads 0, lob physical reads 0, lob read-ahead reads 0.
We are down from 1325 logical reads to 344 logical reads.
In the case of the 2nd query we have received a 4 times improvement!!!
Final Thoughts
I just have shown you how to do multi-dimensional clustering (ordering) of a table with Columnstore Index, in which you can practically control the degree of the first clustering dimension, in the sense of controlling the size of the partition - not always and of course until the maximum supported 15.000 partitions.
The technic implies a need to switch out a partition, order it by applying Row store compression with an index and then creation of a Columnstore Index.
Your results will naturally vary, depending on the data distribution and you might not get any improvements if your predicate inside the partition has no variation whatsoever.
to be continued with Clustered Columnstore Indexes – part 46 (“DateTime compression and performance”)
Multidimensional clustering is all nice – but it is so hard to control. For example rebuilding the table will likely “smear” adjacent segments into each other.
What do you think about the following? Create a composite partitioning key (e.g. “DateKey=2014-12-XX;StoreKey=8XX”, or make this an integer). That way we can reliably shove data into partitions, each of which will have uniform segments. This works for arbitrary dimensionality.
Hi Tobi,
thank you for sharing your thoughts :)
I agree that it is hard to control, but there will be enough environments where composite partitioning key will not be an allowed option.
Also, notice that I have sorted different partitions based on the different columns – which allows me to adapt a partition to the most common predicates existing on them, and this can’t be done alone by a composite partitioning key.
As the time goes by so can the queries extracting the data – and in order to get the best performance you do not have to change your data – just adapt maintenance processes.
Best regards,
Niko