Continuation from the previous 19 parts, starting from https://www.nikoport.com/2013/07/05/clustered-columnstore-indexes-part-1-intro/
This post is dedicated to the situations when available memory to the process ( execution plan ) will not be able to satisfy the context execution environment and one or more operators will have to ‘spill’ the data on the disk. I am trying to investigate if there are any serious improvements in the SQL Server 2014 CTP1.
As in a lot of previous posts, I will keep on working with Contoso BI database, having created a Clustered Columnstore Index on the FactOnlineSales table on SQL Server 2014 CTP1 and having a traditional clustered index + Nonclustered Columnstore Index on SQL Server 2012 SP1.
This type of problems are somehow common in SQL Server as they happen for a good number of reasons. The most common of them is the wrong statistics estimate – and so the request for the necessary memory is simply asking for the wrong values. In this situation for the query to keep on execution, the data is transferred (spilled) to the disk in order for the query not to stop its execution. The current data is moved to TempDB in order to make space available for the new data, and whenever the spilled data is needed again – it will be read from the TempDB disk. This whole process is extremely slow, because we are not dealing with memory and this is the reason why some queries simply execute extremely slowly – they write and read from Disk, without a very concrete mentioning of the process.
Before SQL Server 2012 the query execution plans had no information about this process at all, and in order to be able to catch those situations one would have to use Profiler or Extended Events (2008+). In SQL Server 2012, the query plans have received the necessary warnings in order to advise query developers about the spill process.
I have heard from Igor Stanko (Program Manager for Parallel Datawarehouse at Microsoft) on TechEd 2013 Europe that the new SQL Server 2014 will have some significant improvements in that area, and so I decided to advance with a series of tests that I would like to present in this blog.
One of the common situations in DataWarehousing is when we are joining 2 very big tables and then waiting for our Hash Match operator to complete the joining, and so I have created the following query joining the 12.6 Million row table FactOnlineSales with itself while using a Columnstore Index (Nonclustered for SQL Server 2012 and Clustered for SQL Server 2014 CTP1). Since I have 4 GB of memory given to both of Virtual Machines there must be some interesting results to investigate.
Note: I have made my VM’s suffer with an objective of seeing how different SQL Server handles different situations. The code itself does not make much sense and please don’t run any of such experiments on your production environments.
Note 2: I had to force the usage of the Columnstore Index on SQL Server 2012 SP1, since the traditional clustered index was being used on that queries without additional hints.
set rowcount 100 -- SQL Server 2012 version select sales.OnlineSalesKey, COUNT_BIG(*) from dbo.FactOnlineSales sales with (index(NC_PK_FactOnlineSales)) inner join dbo.FactOnlineSales sales2 with (index(NC_PK_FactOnlineSales)) on sales.OnlineSalesKey = sales2.OnlineSalesKey group by sales.OnlineSalesKey order by sales.OnlineSalesKey -- SQL Server 2014 CTP 1 version select sales.OnlineSalesKey, COUNT_BIG(*) from dbo.FactOnlineSales sales inner join dbo.FactOnlineSales sales2 on sales.OnlineSalesKey = sales2.OnlineSalesKey group by sales.OnlineSalesKey order by sales.OnlineSalesKey
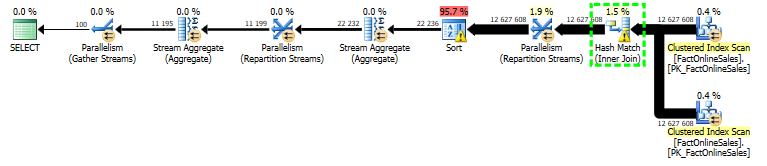
Here comes the execution plan for the SQL Server 2012:
 If you look with attention at the plan, you will notice 2 yellow triangles at the bottom of the Hash Match and Sort operators. This means that we are facing 2 problems in 1 execution plan – we have a TempDB spill on both of those operations.
If you look with attention at the plan, you will notice 2 yellow triangles at the bottom of the Hash Match and Sort operators. This means that we are facing 2 problems in 1 execution plan – we have a TempDB spill on both of those operations.
Now, lets take a look at the SQL Server 2014 CTP 1 execution plan:
It takes 34 seconds with 21124 reads associated to execute this query on my SQL Server 2012 SP 1 Virtual Machine, while on the SQL Server 2014 CTP1 it takes around 5 seconds with 139154 reads. Getting a result almost 7 times better than before is one major improvement.
Both plans look quite similar, with 1 extra Stream Aggregate for the SQL Server 2014 CTP1 version, plus the typical differences between SQL Server 2012 and SQL Server 2014 relating to the batch mode. But wait, let us examine the exact difference in the execution plan.
Here are the details for the both operators at SQL Server 2012: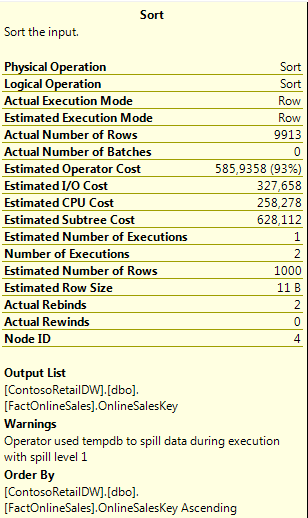
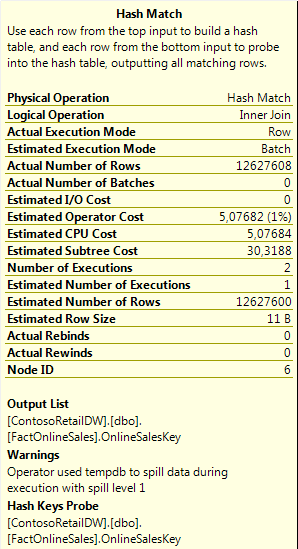 One of the first things to notice is that both operations are running in Row Mode, but remember that we are actually reading data only from the Columnstore Index, which means that theoretically there is a possibility of both of those operations running in the Batch Mode. Life is not a fairy tale, and for the first version of the Columnstore Indexes no reasonable person should have expected to have everything functioning right, so lets check out if there are any improvements SQL Server 2014 CTP1:
One of the first things to notice is that both operations are running in Row Mode, but remember that we are actually reading data only from the Columnstore Index, which means that theoretically there is a possibility of both of those operations running in the Batch Mode. Life is not a fairy tale, and for the first version of the Columnstore Indexes no reasonable person should have expected to have everything functioning right, so lets check out if there are any improvements SQL Server 2014 CTP1:
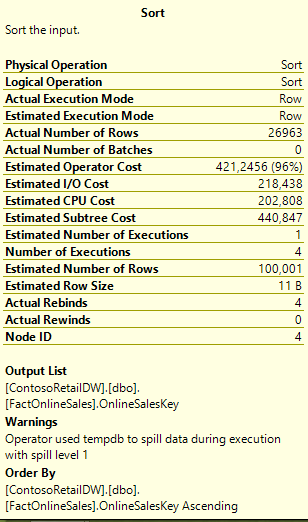
 Now there are some quite visible changes with the Hash Match operator – it functions completely in Batch Mode even though we are doing TempDB spill, and according to Microsoft the spill itself functions completely in Batch Mode, which is a very nice improvement if you ask me.
Now there are some quite visible changes with the Hash Match operator – it functions completely in Batch Mode even though we are doing TempDB spill, and according to Microsoft the spill itself functions completely in Batch Mode, which is a very nice improvement if you ask me.
This is really fine, but what about the Sort operation ? It works completely in Row Mode, and especially since we have a Parallelism operator in our plan – I don’t even have to check its mode.
I am extremely glad to have Batch Mode implemented for the Hash Match operator but I am definitively looking forward to see Sort operator functioning in the Batch Mode. There is no doubt in my mind that this can be done especially in the situations when we are dealing only with the data from the Columnstore Indexes. I mean that ideally we would do almost everything (besides some small operations when we have just a few rows to work with, but I see the progress and I really expect a couple more operators to have Batch Mode implemented in the final release of the SQL Server 2014.
I really applaud to Microsoft for advancing further with Columnstore Indexes and especially with the Batch Mode, but I am pretty much hungry for more.
to be continued with Clustered Columnstore Indexes – part 21 (“DBCC CSIndex”)
Hi Niko,
Thanks for this article. Indeed, Sql 2014 can bring new tech achievements that are very important but in a real structure (as you well know), all the horizontal tech structure are also very important, like SAN’s and I can say that HP and EMC are taking large steps to improve even better the IO “issue”.
Regard’s and “grande abraço de Angola”. Ivo Moura
Hey Ivo,
thanks for the comment :)
Actually Columnstore Indexes appeared in SQL Server 2012 as a Nonclustered version. :) Columnstore technology is not a minor improvement, it is a brand new world with a brand new way of doing things. They are already being used in different installations, and Clustered Columnstore is already being used inside of the SQL Server Parallel Datawarehous product (appliance which price starts at 1 million $).
Eric Hanson (Principal Program Manager at Microsoft) has once described them as a ‘revolutionary change which happens once in a lifetime’ and I have to agree with it.
Batch Mode makes things function in a remarkably different way and the speed of the storage might become secondary in a lot of cases. Hold on for the next blog post – you will see how an external USB 2.0 drive can be blazingly faster then a Vertex 3 SSD. ;)
Quando estiveres em Lisboa, apita para gente combinar um almoço ;) Um abraço!
Hi Niko,
Is there no way to trick SQL Server into ‘thinking’ that it will require more memory to avoid the tempdb spills in the first place? (Instead of having SQL Server underestimate the amount of memory the query will require and then spill to disk/tempdb.)
I’m particularly interested in this problem as I’ve got an enourmous daily-partitioned fact table with a nonclustered columnstore index (4+ billion rows, ~80 GB data, ~30 GB indexes; and growing at a rate of ~10 millions rows/day). Up until some point around 2B rows, we could query the columnstore index extremely quickly, but now we can rarely get any rows returned even when restricted to a single day’s partition. Regardless of what we try (using/not using the columnstore, limiting madop, etc.), the queries inevitably start spilling to tempdb. We even experience the tempdb spills on an inactive server with 256 GB of RAM dedicated to SQL Server.
I wish I could just tell SQL, “You can use all 256 GB; Don’t use tempdb please!”
-Aaron
Hi Aaron,
Did you check your resource governor settings ? Did you set up proper Resource Groups and assigned the respective amounts of memory?
Controlling memory grants on a query basis will require SQL Server 2016 – there are new hints that will allow you to do so. (hope to write on it soon)
Taking it from another angle – do you use any char columns in the fact table? Did you consider using Nonclustered Columnstore in order to avoid the character columns and thus lowering the required memory grants?
Best regards,
Niko Neugebauer
Microsoft actually fixed this issue in the hotfix SQL Server 2014 SP1+CU8. Although we need to enable traceflag 9410 for the optimizer to avoid tempdb spillage.
Hi Suren,
the fix you are mentioning is only partial, since there are always situations when there is simply not enough memory. For Batch Sorting in SQL Server Microsoft has implemented a dynamic memory grant which is super-exciting and let’s see how it will perform in the real world.
Best regards,
Niko Neugebauer