Continuation from the previous 18 parts, starting from https://www.nikoport.com/2013/07/05/clustered-columnstore-indexes-part-1-intro/
This post is dedicated to the limitations of the Batch Mode of the Columnstore Indexes in SQL Server 2012 and the improvements which are already present in SQL Server 2014 CTP1.
I am continuing using the VMs and the Contoso BI database with the alterations that I have done in the previous post of the series on Clustered Columnstore Indexes.
If you have seen some of the presentations or read some documents or blog posts on the NonClustered Columnstore Indexes in SQL Server 2012, you have definitely heard a good list of the limitations of the Batch Mode implementation. Basically, in SQL Server 2012 should you go just a couple of steps away from the instructions on how you should write queries, then you are back into the Row Mode, which will be painfully slow since we are working with the tables containing at least a couple of million of rows.
Well, lets kick off and check on them, if SQL Server 2014 and the Clustered Columnstore Indexes in it are fit and able to be called the next generation of the DataWarehousing solutions:
The following limitations are being considered and tested in this blog post (more on them can be found on the respective page at MSDN:
- OUTER JOIN
- IN & EXISTS
- NOT IN
- UNION ALL
- Scalar Aggregates
- One or more DISTINCT Aggregates
Lets consider a simple query which has a right OUTER JOIN:
select prod.ProductName, sum(sales.SalesAmount) from dbo.DimProduct prod right outer join dbo.FactOnlineSales sales on sales.ProductKey = prod.ProductKey group by prod.ProductName order by prod.ProductName
Here are the execution plans of both of the queries – on SQL Server 2012 and on SQL Server 2014 CTP1:
SQL Server 2012:
SQL Server 2014 CTP1:
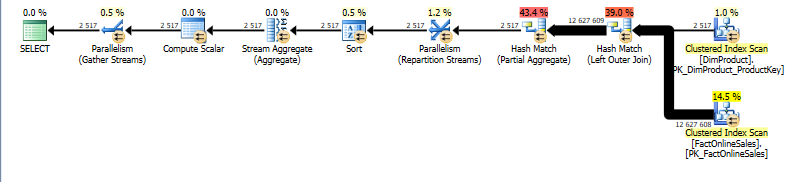
Unfortunately no tool so far I have seen shows the Batch Mode of the operators (Not even the SQL Sentry Plan Explorer that I am using), but if you look carefully on the execution plan difference, you will notice that there are 4 Parallelism operators in SQL Server 2012 plan, and that there are just 2 of them for SQL Server 2014 CTP1 execution plan. The presence of the Hash Match (Left Outer Join) is another indication of the SQL Server 2014 CTP1 plan being using Batch mode extensively. On my VM’s the execution time difference was extremely big ~10 seconds vs < 1 second.
This sounds exciting, but lets not stop and see other limitations and so the next one in the queue - IN & EXISTS:
Lets execute the following query:
-- In select (select store.StoreName from dbo.DimStore store where store.StoreKey = sales.StoreKey) as 'Store', sum(sales.SalesAmount) as 'Store Sales' from dbo.FactOnlineSales sales where sales.ProductKey in ( select prod.ProductKey from dbo.DimProduct prod ) group by sales.StoreKey order by sales.StoreKey -- Exists select (select store.StoreName from dbo.DimStore store where store.StoreKey = sales.StoreKey) as 'Store', sum(sales.SalesAmount) as 'Store Sales' from dbo.FactOnlineSales sales where EXISTS ( select prod.ProductKey from dbo.DimProduct prod where sales.ProductKey = prod.ProductKey ) group by sales.StoreKey order by sales.StoreKey
Here are the execution plans of both of the queries since they are really equal for the SQL Server Query Optimizer:
SQL Server 2012:
SQL Server 2014 CTP1: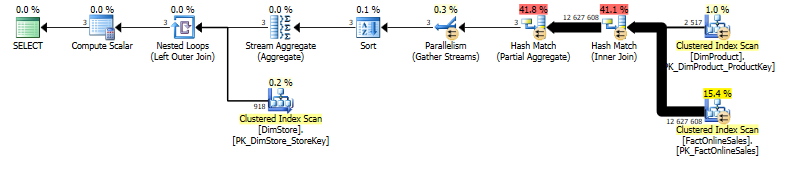
It is quite clear where Batch Mode lives, since on SQL Server 2012 those queries take around 7.3 seconds on my laptop, and on a similar VM with SQL Server 2014 CTP1 it takes around 0.25 seconds. This is one more great improvement, since a lot of people are keep on using IN & EXISTS ignoring the possibilities of re-writing the queries using inner joins.
Actually a good indicator of a Batch Mode from the plan that I am seeing is the presence and the position of the Parallelism operator – should it happen before the Hash Match operator, then most probably the execution mode is a Row, if otherwise we see just a few of the Parallism operators which are located after any join operators, then we are more probably running the relevant operations in Batch Mode.
Now let’s go and consider a case with a NOT IN:
From our previous Sales Analysis query, let’s try to adapt it to see the global sales of only non-luxury products:
-- Sales without Luxury Products select (select store.StoreName from dbo.DimStore store where store.StoreKey = sales.StoreKey) as 'Store', sum(sales.SalesAmount) as 'Non-Luxury Store Sales' from dbo.FactOnlineSales sales where sales.ProductKey not in ( select prod.ProductKey from dbo.DimProduct prod where prod.ClassID = 3 ) group by sales.StoreKey order by sales.StoreKey
Lets check the execution plans:
SQL Server 2012: 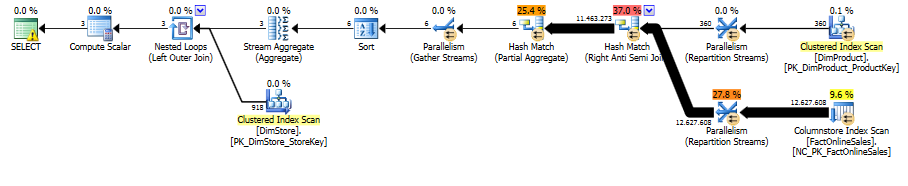
SQL Server 2014 CTP1:
Once again the difference is as described for the previous case, Row Mode for SQL Server 2012 and 7.6 seconds execution time vs a Batch Mode execution in SQL Server 2014 CTP1 with 0.5 seconds of execution time.
Next one in line is UNION ALL:
-- Let us create a view on the totality of the purchases create view dbo.vPurchases as select [SalesQuantity], [TotalCost] from dbo.FactOnlineSales union all select [SalesQuantity], [TotalCost] from dbo.FactSales -- Lets get the totals out of this view select sum([SalesQuantity]) as TotalSales, sum([TotalCost]) as TotalCosts from dbo.vPurchases
The execution plan for SQL Server 2012: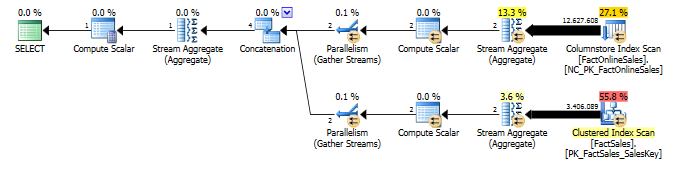
Here comes the execution plan for SQL Server 2014 CTP1:
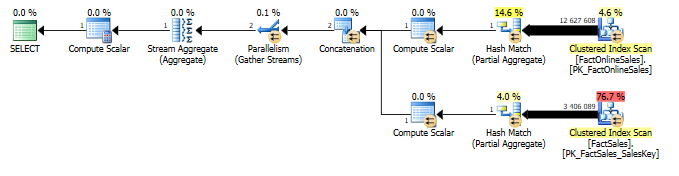
It is clear that one of the slowest points of the query is the scanning of the totality of the clustered index (Non-Columnstore) on the FactSales table, but the difference in the execution plans is quite clear – once again we have 3 operators in Batch Mode for the SQL Server 2014 CTP1, while everything is in Row Mode for SQL Server 2012. One more improvement, especially if you compare it to writing 3 CTEs + 1 SELECT instead :)
Scalar Aggregates
This one is very easy, it was already referred to in the previous post on the matter of the Batch Mode improvements:
-- Total count of the sales select count(*) from dbo.FactOnlineSales
Here are the execution plans, I will just mention that the execution times were 1469 ms for SQL Server 2012 and 31 ms for SQL Server 2014 CTP1:
SQL Server 2012 execution plan:
SQL Server 2014 CTP1 execution plan:

This all looks quite clear.
Lets check then on queries with 1+ Scalar Aggregates:
For the not faint of a heart and with good Hardware, here comes a simple query to test the performance:
select count( distinct StoreKey ) as 'Distinct Stores' , count( distinct CustomerKey ) as 'Distinct Customers' , count( distinct CurrencyKey ) as 'Distinct Currencies' from dbo.FactOnlineSales sales inner join dbo.DimPromotion prom on sales.PromotionKey = prom.PromotionKey where prom.DiscountPercent = 0 group by sales.LoadDate
On my SQL Server 2012 VM it took around 18 seconds to run this one. :)
Here comes a little monster of the execution plan:
Well, but here comes the rain – the situation for this query is pretty much the same on SQL Server 2014 CTP1:
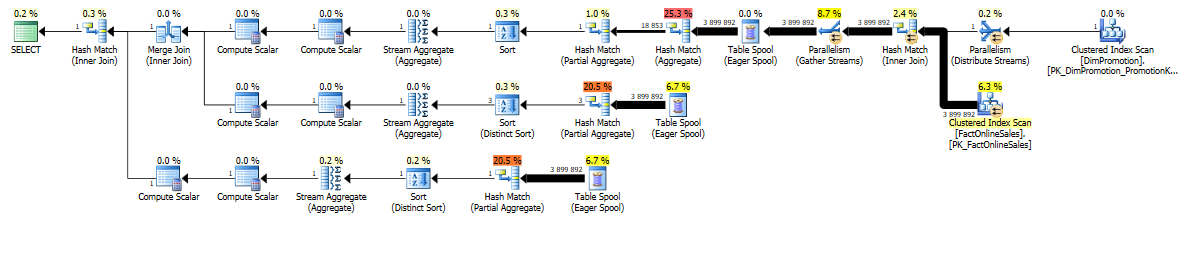
With very similar execution times (17 seconds) and just small insignificant cosmetic changes within the execution plans, this is one of the situations Microsoft needs to keep on pushing to make this plan working fine in a Batch Mode.
This is a very real scenarios for a lot of reporting queries but I do remember some of the similar queries performance problems for a Row Mode in all available SQL Server version. Lets hope that something will change for the RTM, but in this case I am definitely not holding my breath.
All in all I am very excited about the changes in the upcoming version of SQL Server, I am eagerly waiting for CTP2 to see if the last one of the situations described above will suffer any changes.
to be continued with Clustered Columnstore Indexes – part 20 (“TempDB Spills – when memory is not enough”)
Niko,
Do you happen to have a definitive list of the things which inhibit batch mode in SQL Server 2014, I know that the list is much smaller than it was for 2012.
Chris
Chris, its coming :)
Niko