Continuation from the previous 17 parts, starting from https://www.nikoport.com/2013/07/05/clustered-columnstore-indexes-part-1-intro/
This time lets see which improvements were delivered for the Batch Mode processing for the SQL Server 2014 CTP1. Batch Mode query execution was introduced in SQL Server 2012 specifically for the Columnstore Indexes. One of its differences to the traditional Row Mode is that it is processing data joined together in chunks of 1000 units instead of traditional 1 by 1, thus guaranteeing more CPU efficiency for the big amounts of data. Since Columnstore Indexes are being used specifically for the tables with a lot of millions of rows, this is exactly where the Batch Mode is shining.
In the SQL Server 2012 the batch mode implementation was very limited, with just a couple of Query Execution operators being supporting Batch Mode, and in order to get it activated one would have to completely rewrite the query, following the suggestion published by Microsoft.
Well SQL Server 2014 CTP1 is a very different beast. For real. Grab your cup of coffee, jump in – we are going for a very serious ride in the Batch Mode execution country ;)
I downloaded and installed Contoso BI database on both of my Virtual Machines: on SQL Server 2012 and on the SQL Server 2014 CTP1.
Execute the following scripts on both of the Virtual Machines:
alter table dbo.[FactOnlineSales] DROP CONSTRAINT PK_FactOnlineSales_SalesKey alter table dbo.[FactOnlineSales] DROP CONSTRAINT FK_FactOnlineSales_DimCurrency alter table dbo.[FactOnlineSales] DROP CONSTRAINT FK_FactOnlineSales_DimCustomer alter table dbo.[FactOnlineSales] DROP CONSTRAINT FK_FactOnlineSales_DimDate alter table dbo.[FactOnlineSales] DROP CONSTRAINT FK_FactOnlineSales_DimProduct alter table dbo.[FactOnlineSales] DROP CONSTRAINT FK_FactOnlineSales_DimPromotion
For SQL Server 2012, lets create a traditional clustered index, as well as the Nonclustered Columnstore Index:
create clustered Index PK_FactOnlineSales
on dbo.FactOnlineSales (OnlineSalesKey ASC)
WITH ( DATA_COMPRESSION = PAGE);
Create NonClustered Columnstore Index NC_PK_FactOnlineSales
on dbo.FactOnlineSales (OnlineSalesKey, DateKey, StoreKey, ProductKey, PromotionKey, CurrencyKey, CustomerKey, SalesOrderNumber, SalesOrderLineNumber, SalesQuantity, SalesAmount, ReturnQuantity, ReturnAmount, DiscountQuantity, DiscountAmount, TotalCost, UnitCost, UnitPrice, ETLLoadID, LoadDate, UpdateDate)
Now let’s try to see how to we can get hold of a Batch Mode in SQL Server 2012, lets execute the following script, which actually is pretending to get the same results (total sum of the discounts) but in 2 different ways: 1st by writing a traditional query, and then following Microsoft’s suggestion to invoke the Batch Execution Mode by creating a CTE with group by and then summing the totals out of it:
-- Traditional Query: select sum(DiscountAmount) as DiscountAmountSum from dbo.FactOnlineSales; -- CTE Query: with CteAmount as ( select sum(DiscountAmount) as Amount from dbo.FactOnlineSales group by StoreKey-- CustomerKey ) select sum(Amount) as DiscountAmountSum from CteAmount;
Here are the actual execution plans for both of those queries:
 Without looking any further, it is visible that on an environment with MAXDOP > 1, the second query with a CTE is much faster and the reason for it is the Batch Mode Execution which is happening on our “Columnstore Index Scan” and on the “Hash Match” operators in the 2nd execution plan. Here is a screenshot of the properties of the “Columnstore Index Scan” operator:
Without looking any further, it is visible that on an environment with MAXDOP > 1, the second query with a CTE is much faster and the reason for it is the Batch Mode Execution which is happening on our “Columnstore Index Scan” and on the “Hash Match” operators in the 2nd execution plan. Here is a screenshot of the properties of the “Columnstore Index Scan” operator: 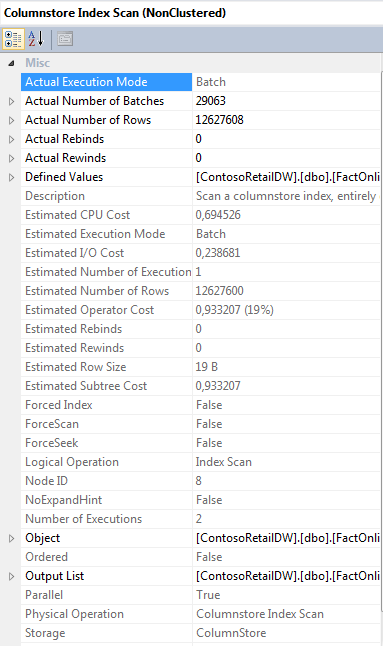
I have decided to discover the behavior of those plans in the terms of the IO, and so I executed the following script before re-executing the previous script:
set statistics IO on
Here are the results that I have received, which show that in the terms of the IO the difference between the both queries is nothing more than 5%:

This all seems to be quite clear, but what about SQL Server CTP1 and the NonClustered Columnstore Indexes and Clustered Columnstore Indexes ?
I executed the very same scripts on the Virtual Machine SQL Server 2014 CTP1 and this what I have found:
 Yes, you are looking at the correct plan – a simple & direct query is using Batch Mode even with the Nonclustered Columnstore Index ! The difference between execution plans in SQL Server 2012 & in SQL Server 2014 is that Steam Aggregate from 2012 became Hash Match (Partial Aggregate) in 2014 and that both operations (Index Scan & Steam Aggregate) are running fully in Batch Mode. Here you have the screenshot of the “Statistics IO”:
Yes, you are looking at the correct plan – a simple & direct query is using Batch Mode even with the Nonclustered Columnstore Index ! The difference between execution plans in SQL Server 2012 & in SQL Server 2014 is that Steam Aggregate from 2012 became Hash Match (Partial Aggregate) in 2014 and that both operations (Index Scan & Steam Aggregate) are running fully in Batch Mode. Here you have the screenshot of the “Statistics IO”: I do not know why the number of reads is so significantly higher, since the difference between the sizes of the Columnstore Indexes were around 15 MB and it does not represent even 10% of the total space occupied by the Nonclustered Columnstore Index in that case.
I do not know why the number of reads is so significantly higher, since the difference between the sizes of the Columnstore Indexes were around 15 MB and it does not represent even 10% of the total space occupied by the Nonclustered Columnstore Index in that case.
It seems that the implementation of the Batch Mode in SQL Server 2014 was taken on a whole new level – on the level of what people like me are expecting from a good 1.0 version. :)
Goodbye query-rewritings – hello operational execution of “normal” queries. I am sure that there are thousands of bugs, and that there will be posts all over internet crying and blaming everyone, but for the moment let us celebrate that even query like this are running in a batch mode finally:
select count(*) from dbo.FactOnlineSales
Take it from here – such improvements right in the CTP1 version of SQL Server: this is amazing! :)
The last thing I was looking to measure is if this queries were really supported for the Clustered Columnstore Indexes and so I ran the following script:
drop Index PK_FactOnlineSales
on dbo.FactOnlineSales;
drop Index NC_PK_FactOnlineSales
on dbo.FactOnlineSales;
Create Clustered Columnstore Index PK_FactOnlineSales
on dbo.FactOnlineSales;
Then I ran the SELECT queries again and the execution plan was pretty much the same as for the NonClustered Columnstore Indexes, though the difference in performance were more visible – the first query got better results than the CTE one, though they are definitely not in orders of magnitude, but around 5-8% on my VMs’.
Wait, but then I took a more detailed look at the results and decided to hold my horses a little bit, take a look at the execution plan:
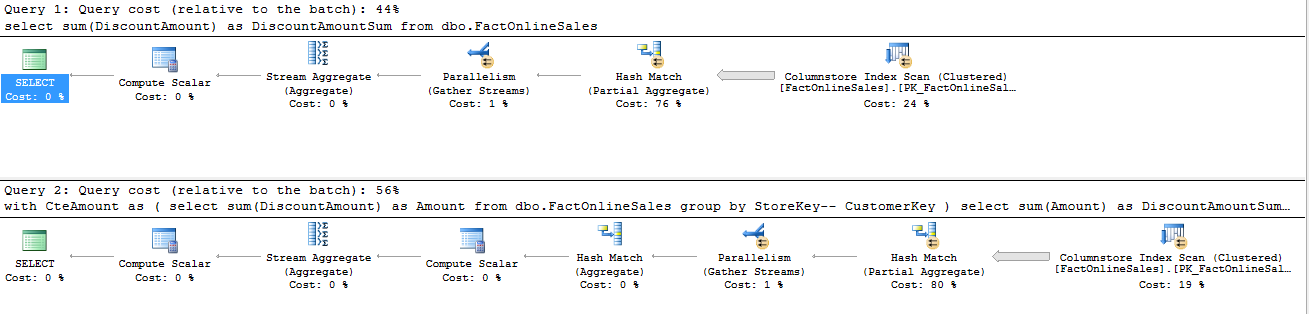
and now at the “Statistics IO”:
Did you notice “Table ‘Workfile’. Scan count 0, logical reads 0, physical reads 0, read-ahead reads 0, lob logical reads 0, lob physical reads 0, lob read-ahead reads 0.” on both of the execution statistics outputs…
I will make a guess, that this is exactly the Workfiles serving for the Hash Indexes & Hash Aggregates described at the respective MSDN article, but it is very interesting that CTP1 is making mention of them.
to be continued with Clustered Columnstore Indexes – part 19 (“Batch Mode 2012 Limitations … Updated!”)