I love Azure Blob Storage. It is a great source for the Data Disks for the Azure VMs (IaaS), Data Files for Azure SQL Database Managed Instance and of course for the key things that guarantees the business running – the backups.
With SQL Server 2012 SP1 CU2 we had received an opportunity to do backup to a URL. Requiring pretty high privileges and the storage account key inside of SQL Server (2012 or 2014) you could have a direct backup to Page Blob on the Azure Blob Storage. For those who faced it at those times or facing it now you should be aware of pretty important limitations, such as
- 1TB Backup at Maximum
- No Striping, just 1 file
- Page Blobs are the only supported destination (Slower & More Expensive than the Block Blobs)
- No Logical Device Name
- Many usual parameters are not supported (BLOCKSIZE, MAXTRANSFERSIZE, …)
It would work, but it would not fly – as they say …
With SQL Server 2016 the mechanism of the BackupToURL.exe (yeah, that’s the name of the file and I had situations where the backup would not advance for hours and the solution was to find it out and to kill that process) was pretty much rewritten and included things such as:
- SAS support (Shared Access Signature), which can give more granular permission on the Container/Folder/Blob and can include an expiration date, which is a great security measure
- Striping to multiple files, yahoo! Big Databases love striping for good backup & restores performance.
- Choice of the Access types (Premium, Hot, Cool or Archive)
- Block Blobs are cheaper (0.0380€ per GB for Page Blobs vs 0.00844€ per GB for the Cool Storage in Western Europe region for Blob Storage)
- Up to 4.5TB in total
If you have a really big Database (Multiple TB) – a Page Blob without any striping would either not allow you to finish or take way too much time to finish the backup. Striping backups into multiple files is the key to get a good performance out of the backup process (well, besides tuning the block size & the buffer count obviously).
The Bad part
If you have ever dealt with a Backup of a really big Databases to the Block Blobs, you might be also be aware that once a single Block reaches the “magical” number of 195 GB per stripe (file), you will start getting errors from the Storage, preventing you to finish the operation. :(
Well, you might start thinking – I need to make sure that I am striping quite well in order not to hit this limitation. Yes, you better do. You better configure your backups right with the right tool.
You might think that the Block Blobs are very limited – but they are definitely not the case, they can span very well beyond 195 GB up to 4.5 TB, and it has been this way for almost 4 years (since 2016).
This problem we are all facing has to do with the REST API version the SQL Server is using to write to Azure Blob Storage. I can only guess that it relates to some of the year 2015 version, chosen and tuned during the times of SQL Server pre-release (CTPs).
What is really sad is that in SQL Server 2017 & SQL Server 2019, Microsoft has not found resources to upgrade the API to a newer version. Looking at all the previous version of the Storage REST API that were released after SQL Server 2016 – I see a huge potential for improvement.
Specifically take a look at the 2016-05-31 version, which was released right before the RTM of the SQL Server 2016. It states in a very clear way on the very first line the following:
The maximum size of blocks has been increased to 100 MB. This means that the maximum size of a block blob is now 5,000,000 MB, or about 4.75 TB.
Yes, 100 MB per block instead of the previous 4 MB – making it a 25 times improvement! And that just right when the development team was probably already working on the first Cumulative Update for SQL Server 2016 !
Wonder
How do people manage the backups to URL ?
– If you are on SQL Server 2012 or SQL Server 2014 – you need to upgrade.
– Backing up directly to the Locally Attached Drives and then copying them up to Blob Storage (that’s really expensive)
– Constantly increasing the number of stripes… :(
What are the problems with constantly increasing the number of stripes ?
There are multiples:
– It might affect Restore testing processes or QA-environment seedings (you need to make sure that you script will adjust the number of sources)
– It might not be enough if your database suffers a sudden growth and you will discover it in the worst way possible.
– You should be doing more important/interesting things.
One can always choose a very high number of Backup Files in order not to hit this limitation, but this does not sound like a fascinating plan to me. If you have a number of 10 GB and 10 TB Databases on the same server – either you have separate jobs for one/group or you will end up with 128 Files delivering you solid 80 MB per file … Boo!
While Microsoft hopefully considers fixing this situation, you can start taking control into your own hands and create maybe even a dynamic invocation of the Backups based on the need and for that purpose I decided to share a little script that I have developed.
First of all I have defined some parameters, such as
– All Stripes numbers are defined with the power of 2 as in 1, 2, 4, 8, 16, 32, 64, 128, …
– Once a backup hits 80% of the used size of the 195 GB per Stripe, the number of Stripes should be increased
– Once the next expected linear growth of the Backup Size hits the 195 GB per Stripe, the number of Stripes should be increased
– The backups in the considerations are only FULL Backups to URL (starts with https://)
Here is the script that will provide you information on the specific Database (for that you will need to define the @dbName parameter)
DECLARE @dbName SYSNAME = 'master'; SELECT database_name as dbName, backup_start_date as StartTime, backup_finish_date as FinishTime, DatabaseSizeGB, TotalBackupSizeGB, TotalBackupSizeGB - LAG(TotalBackupSizeGB,1) OVER (PARTITION BY Database_name ORDER BY backup_start_date) as FullBackupGrowthInGB, PercentageOfStripesUsed, UsedNumberOfFiles, CASE WHEN PercentageOfStripesUsed > 80 OR (TotalBackupSizeGB + TotalBackupSizeGB - LAG(TotalBackupSizeGB,1) OVER (PARTITION BY Database_name ORDER BY backup_start_date) ) / UsedNumberOfFiles > 195. THEN FLOOR(POWER(2,CEILING(LOG(UsedNumberOfFiles*2))+1)) ELSE FLOOR(POWER(2,CEILING(LOG(CAST(TotalBackupSizeGB / 195. * 1.30 AS INT)))+1)) END as MinRecommendedNumberOfFiles, IsCopyOnly FROM ( SELECT bs.database_name, bs.backup_start_date, bs.backup_finish_date, MAX(CAST(bs.backup_size/1024.0/1024/1024 AS DECIMAL(9, 3))) AS DatabaseSizeGB, MAX(CAST(bs.compressed_backup_size/1024.0/1024/1024 AS DECIMAL(9, 3))) AS TotalBackupSizeGB, COUNT(*) as UsedNumberOfFiles, CAST(MAX(bs.compressed_backup_size/1024.0/1024/1024 ) / COUNT(*) / 195. * 100. AS DECIMAL(9,3)) as PercentageOfStripesUsed, FROM msdb.dbo.backupmediafamily bm INNER JOIN msdb.dbo.backupset bs ON bm.media_set_id = bs.media_set_id WHERE database_name = @dbName and bs.Type = 'D' AND bm.physical_device_name LIKE 'https://%' GROUP BY backup_start_date, backup_finish_date, bs.database_name ) src ORDER BY backup_start_date DESC;
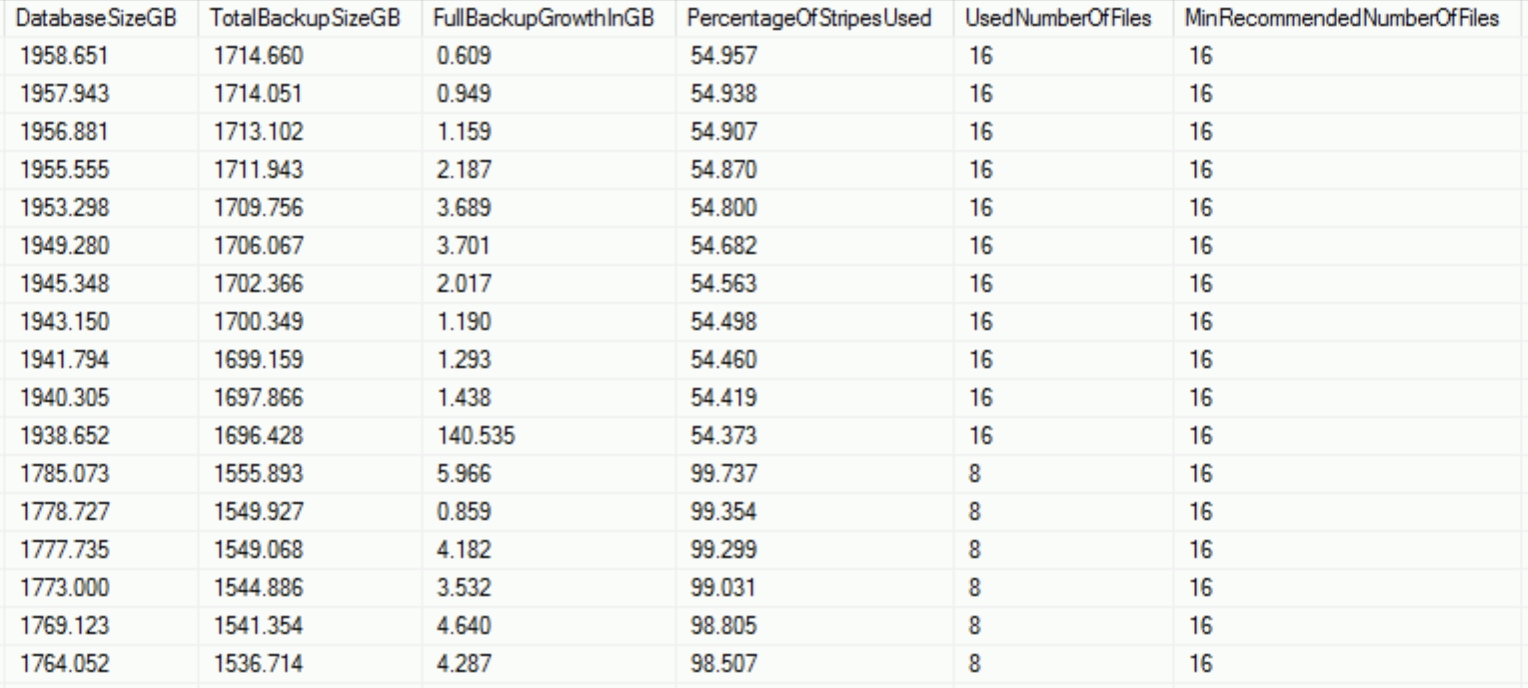 On the picture on the left you will see some edited output (database name, StartTime & Finish Time are not shown) from some certain instance where the growth has essential caused problems, which we are fixing with the new script.
On the picture on the left you will see some edited output (database name, StartTime & Finish Time are not shown) from some certain instance where the growth has essential caused problems, which we are fixing with the new script.
The idea behind the automation process (aka AIP, yeah pun intended) is to simply re-generate the backup command for the Ola Hallengren’s script that is being used in the SQLAgent Job with the help of the sp_update_jobstep system stored procedure in order to generate an adaptable command with the adequate number of Stripes.
You might want to include additional filters into the logic:
– ensuring that if you are running an Availability Group, you won’t base your decision on the older or non-existing information.
– generate a .sql file that will be called by the SQLAgent Job and not mess with the SQL Server Agent
– use a non-linear regression algorithm for the decision making process (hey, anything more advanced is better)
Have fun!