Dear reader, I want to share with you some technical stuff under the name of Froid. Yes, Froid and not Freud, even though I guess one might argue that Froid can potentially be a kind of a Freud for the understanding and improvement of the slow performance of the UDFs (User Defined Functions) – the Scalar T-SQL UDF Inlining.
From the other side we can argue that the changes & improvements can be pretty much arbitrary and some of the “patients” quite contrary to the expectations might be “feeling worse” than before.
There is no panacea, and believing that SQL Server 2019 (or any other version or any other vendor database) will solve all performance problems is immature.
The solution framework is very much awesome and I am thrilled that some of my clients will be delighted once they migrate to Sql Server 2019 & of course Azure SQL Database.
Available for the tests starting with the SQL Server 2019 CTP 2.1 (starting with january 2019, when my original article was written), this function has the promise of correcting the 18-years old “bug” and should be one of the most prominent features of SQL Server 2019 that will drive the adoption of the platform by the traditional application. Especially by those that are written by the developers who do not exactly have a time of learning and understanding how relational databases function and expect them to work as the regular non-set-based programming language.
As we all know – a significant part of the development effort of the commercial databases goes into making not-so-optimised sql development code running as if it was optimised, and the effort of making SQL Server functions working the best possible is more then welcome – it is very much needed.
Just in the past 6 months I was looking at some of the code which besides using the SQL Server Scalar User Defined Functions extensively, would even call other Table-Valued Functions that would call on another 2 depth Scalar User Defined Functions. I am hoping that Froid will bring some benefit to this pretty heavy Premium 6 Azure SQL Database in the nearest future.
Before going any steps further we need to talk about the type of the functions that do exist in SQL Server & Azure SQL Database:
– Multi-Statement Table Valued Functions (Also called MSTVF’s in the popular lingo). In the last 5 years those have Think 2017 improvements)
– Inline Table Valued Functions
– Scalar-Valued Functions
Multi-Statement Table Valued Functions
The definition of the MSTVFs is pretty easy – it is a multi-statement (can have 1 or more statements) function that returns a table as a result. You can simply select stuff directly from it in a statement as if we have had a MSTVF called GetCalcResult we would call it in a code like
SELECT * FROM dbo.GetCalcResult( 'Param 1', 'Another Param' );
You can recognise those functions on a daily basis if you are using some of the system MSTVFs, such as the ones used to obtain the details on the statistics.
The MSTVFs have received some significant attention in past 5 years, with great Joe Sack blogging about them in MSTVF Fixed Cardinality Value in SQL Server 2014 at the SQL Server 2014 timeframe, while he was working for the SQLSkills, and then Introducing Interleaved Execution for Multi-Statement Table Valued Functions as a Microsoft employee already, for the SQL Server 2017.
While 1 as a cardinality estimation value is not an answer and neither is 100 (2014), I know that some code that was heavily optimised for the correct performance gets mixed up and broken with the SQL Server 2017 – which is absolutely awesome for the non-optimised or the new development.
Inline Table Valued Functions
The Inline Table Valued Functions are very similar to a view. Like the MSTVF’s they do return a table, in a single statement. They allow to introduce you parameters that will be served for filtering or calculating the result.
They are pretty much optimised in comparison with MSTVFs or with the Scalar-Valued Functions and here is a random example:
CREATE FUNCTION dbo.itvfCalculateDetails ( @param1 int, @param2 char(2) )
RETURNS TABLE
WITH SCHEMABINDING AS
RETURN (
SELECT rec.masterId,
AVG( masterValue ) * param1 as AverageValuedC,
COUNT(*) AS TotalRecords
FROM dbo.MasterRecord rec
WHERE rec.Country = @param2
GROUP BY rec.masterId
);
which would be invoked with the following code:
SELECT * FROM dbo.itvfCalculateDetails ( 2, 'PT' );
or you can join it with other Inline Table Valued Functions or Views. A lot of time an APPLY (CROSS or OUTER) would be used to access this type of function.
Scalar-Valued Functions
Scalar-Valued Functions or as they are traditionally known – the root of countless performance evils.
These are the User-Defined Functions that will have one or multiple steps and will return a single scalar value as the result, making them unnecessary good candidates to be invoked as a part of the calculations and not as a join part of the query (cause you can’t join a single value to a table, unless it is being used a set/table), but as a single value of the predicate, join (oh evil) or calculation result.
Given that one of the first things a modern (by my own standards) programmer should learn is to encapsulate the repetitive functionalities, the natural will of the unknowing & unsuspecting programmer is to encapsulate such type of procedures:
CREATE FUNCTION dbo.SumAndMultiply( @p1 DECIMAL(16,4), @p2 DECIMAL(16,4) )
RETURNS DECIMAL(38,6) AS
BEGIN
RETURN (@p1 + @p2) + (@p1 * @p2)
END
which pretty much would have been a great optimisation … if only the relational databases would not be using sets and scalar values … :)
What are the evils of the Scalar UDFs ?
Well – they are running in single-threaded mode, with the help of the Inner Loops (Even if there are Gazillions of rows to be processed) and contributing with a whole lot of 0 (zero) cost to the query cost estimation.
Sounds bad enough, eh ? I am just starting :)
For the Azure SQL Database & SQL Server 2019, Microsoft has introduced the Froid framework, which allows to inline some of the Scalar-Valued Functions.
Here are some of the quotations from the paper:
It is a known fact amongst practitioners that UDFs are “evil” when it comes to performance considerations.
In fact, users are advised by experts to avoid UDFs for performance reasons. The inter- net is replete with articles and discussions that call out the performance overheads of UDFs. This is true for all popular RDBMSs, commercial and open source.
IThe root cause of poor performance of UDFs can be attributed to what is known as the ‘impedance mismatch’ between two distinct programming paradigms at play – the declarative paradigm of SQL, and the imperative paradigm of procedural code.
In practice this would mean something like this:
– Using the transformation of the APPLY operator, Froid manages to transform the imperative language into the relational expressions.
– Even though it is applied on the T-SQL, the same technic is expected to work against any other language, with the appropriate operator support.
Using the following technics:
- Dead Code elimination
- Dynamic Slicing
- Constant Propagation
- Folding
Froid framework will try to convert the existing Scalar UDF code into a table-valued function code that can be joined/applied/used in a query where the cost for the calculation is estimated, the traditional Query Optimisation technics are applied and potentially a parallelism can be achieved. Potentially I say, the miracles are in the different department – for that purpose look at the Marketing :)
UDF Phases
The UDF is following the phases during the preparation and execution:
- Parsing, Binding and Normalization (Object Identification, Schema Verification, etc):
- Cost Based Optimisation
- Execution
These are true even for the inlined UDFs – which is nothing too much different from the traditional UDF functions, with the exception with the inlining itself and the Cost-Based Optimisation because as I already mentioned before – the previously estimated cost for the UDF execution was 0, meaning that the query optimiser would simply not weight the execution at all.
UDF Inlining details
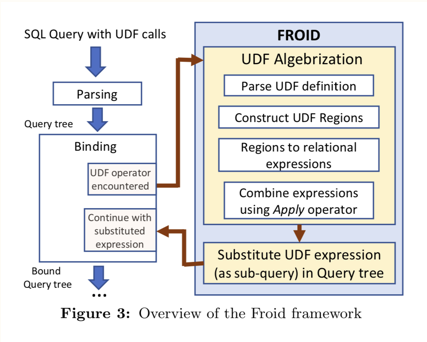 On the left side of this text, you will find an image of the Froid internal functioning where the parsing and the construction & combination of the UDF Regions are the most significant point in the whole framework for me – because the magic is exactly is happening there. The conversion of the UDF logic into a set-based solution is the key to get a optimised result.
On the left side of this text, you will find an image of the Froid internal functioning where the parsing and the construction & combination of the UDF Regions are the most significant point in the whole framework for me – because the magic is exactly is happening there. The conversion of the UDF logic into a set-based solution is the key to get a optimised result.
I will leave you with an example of a function and how it is getting optimised – it was taken from the Research Paper that I mentioned: https://www.microsoft.com/en-us/research/project/froid/, I really recommend you to spend a couple of minutes and read it through – it is totally worth it!
 On the picture above you can see the determination of the regions and its/their conversion into an optimised code and finally its execution.
On the picture above you can see the determination of the regions and its/their conversion into an optimised code and finally its execution.
Inlineable Scalar UDFs requirements
Without going into all of the requirements and limitations of the inlined UDFs, I would love to point to some of the more significant ones, that hopefully will get solved at some point:
The UDF does not invoke any intrinsic function that is either time-dependent (such as GETDATE()) or has side effects (such as NEWSEQUENTIALID()). – This is huge. Huge not in the best of the ways, because way too many solutions will really depend on the GETDATE() functionally – I have seen this year at a real client a scalar UDF that would call another scalar UDF just in order to calculate the current time in the different timezone and this limitation will totally kill this optimisation.
Think about this issue as in the question – will the invocation of the inlined scalar UDF bring the very same (as in exactly the same) result as the non-inlined UDF ? If we are invoking a function with just 1 result – that’s one situation, but traditionally the UDFs are being invoked in the sequential fashion, meaning that if we are processing a huge amount of information and the query will take a couple of seconds.
Views that reference inline scalar UDFs cannot be indexed. If you need to create an index on such views, disable inlining for the referenced UDFs.
This is really unfortunate. The indexed views have been such a pool of the solutions for a lot of my clients and I am disappointed by the lack of their support by the Froid.
The ones that I want to be aware of, but I am totally understanding:
Inlining will result in a different query hash for the same query text.
This is not a limitation and while I totally understand that it is needed, because as a matter of a fact the Query Optimiser will get a Froid-remade query when it starts its execution. Given all the details of the Query Store and the forced execution plans ids, I am not even raising this as a significant item. Need to keep it in the head though.
Only a certain level of nested/recursive invocations are supported
We certainly do not want the Query Optimiser to spend 5 minutes looking through the nested realities, looking for some kind of a plan :)
Solution Idea: why not add a hint to the function definition where we can take the responsibility of saying – it is OK to deliver the same results or not, thus allowing ? :)
The UDF uses the EXECUTE AS CALLER clause (the default behavior if the EXECUTE AS clause is not specified).
The vast majority of the uses cases which I see won’t need this, though given SQL Server focus on the security, eventually in the future this item will need to get fixed.
The UDF does not reference table variables or table-valued parameters.
Hopefully in V2. Well, or maybe V3. :)
The query invoking a scalar UDF does not reference a scalar UDF call in its GROUP BY clause.
Totally understand the lack of investment to fix the more complex scenarios.
The query invoking a scalar UDF in its select list with DISTINCT clause does not reference a scalar UDF call in its ORDER BY clause.
The UDF is not natively compiled (interop is supported).
Who is surprised by the lack of the love to the Hekaton?
The UDF is not used in a computed column or a check constraint definition.
Computed columns … Still not getting enough love from SQL Server team … Think that it took 4 releases to get the computed columns finally support the Columnstore Indexes (as long as they are not persisted and not in Nonclustered Columnstore Index)
The UDF does not reference user-defined types.
User-Defined Type is the path of loosing support of the features since day 1.
The UDF is not a partition function.
I want to see someone complaining on this item … Like really!
Scalar-Valued Functions Configurations
Microsoft did a great job of giving us the necessary knobs to control the Scalar UDFs Inlining, where we can exercise precision control on the database level by:
– setting the database compatibility level to 150 (corresponding to SQL Server 2019) as in
ALTER DATABASE [ContosoRetailDw] SET COMPATIBILITY_LEVEL = 150;
– controlling the feature by enabling or disabling the database scoped configurations:
ALTER DATABASE SCOPED CONFIGURATION SET TSQL_SCALAR_UDF_INLINING = ON/OFF;
– controlling on the function level if it should be inlined or not, by using the new syntax WITH INLINE = ON / OFF:
CREATE OR ALTER FUNCTION dbo.discount_price(@price DECIMAL(12,2) ) RETURNS DECIMAL (12,2) WITH INLINE = ON /* OFF */ AS BEGIN SELECT 1 END
An important note to add here is If the INLINE=ON option is specified but the UDF is found ineligible for inlining, an error will be thrown.
– and finally we can exercise the control on the statement level by using the following user hint DISABLE_TSQL_SCALAR_UDF_INLINING, as in :
OPTION (USE HINT('DISABLE_TSQL_SCALAR_UDF_INLINING'));
Is My UDF Inlineable?
To check if the UDF is inlinable the DMV sys.sql_modules was expanded with 2 new columns – inline_type and is_inlineable,
which will show if the function can be inlined (the inlining is allowed through the configuration and for that see the previous item) [inline_type]
and if the function does not hit limitations and can be potentially inlined, if it’s cost considered by the Query Optimiser to be inalienable – then the column [is_inlineable] will get the value of 1.
The most interesting implication/speculation is that one day we can more functions types or even procedures to support inlining … :)
Froid pain points
Since we know that UDF Inlining is heavily based on the application of the APPLY statement (wow, such an interesting phrase this sentence has become!), anywhere near the problematic choices of the APPLY statement are the very same situations where we might hit the pain points of the Froid frameworks.
I have seen some of such example in the early CTPs, but starting with CTP 3.0 those examples were solved by the optimiser choosing the better/smarter path and switching to the Hash Match and pushing the Clustered Index Scan to the left side (top side) of the Hash Match iterator.
I still believe that there will be such examples as nothing is perfect, but I am rather happy to report seeing great progress even between the CTPs.
Final Thoughts
I love the feature and I think that for a huge number of Programmers this feature will seem to be something of a triviality. For a lot of applications, especially the older ones, the move to SQL Server 2019 and Azure SQL Database might bring huge performance improvements, becoming one of the key upgrade drivers to SQL Server 2019.
Additionally CROSS APPLY will definitely become much more accessible and that would hopefully drive more optimisation and fixes for this functionality within Query Optimiser. :)
to be continued … (yes, definitely!)
Nice article, thx for the time you spent for this!
Hi LucX,
thank you for the kind words.
Best regards,
Niko Neugebauer
Thank you, this was quite timely for me. One of our databases had been getting slower for a while but last week suddenly became un-useable. It ended up being a function in a WHERE clause. As the DBA I look for that and weed them out, but apparently missed that one. Went from 10 people in my cubicle wondering what we were going to do this weekend to oh … its fixed … hooray !! :)
Hi Kyle,
yeah – UDF’s have been a regular punishment for the performance of the Sql Server for way too many years and hopefully starting with the Sql Server 2019 the situation will start to improve.
Best regards,
Niko Neugebauer