UPDATE 25th of June 2019: The item related to this topic on Azure Feedback: Allow Updating Statistics on the Secondary Replicas of the Availability Groups
We all love and use the wonderful features of the Availability Groups on the secondary replicas, such as the Integrity Checks, Backups & co.
Naturally, the inability of persisting this information on the database level on the secondary is a pain in the neck (and think about the things such as CDC to increase the amount of discomfort).
Well, enough for the pains & troubles, here comes the main idea:
Dear Microsoft, allow us to use our secondary replicas to update statistics … well and do much more stuff on the secondary replicas.
There is always a way a kind of a way*
* almost always
Let’s list the basic known details for the possible solution(for the Enterprise Edition of the Sql Server that is):
– We can make the secondary replica readable and read the same data on it. (Not that you should do that by default, but if you really know what you are doing …)
– We can copy our object into the TempDB (yeah, your Multi-TB table is probably not the best candidate for this operation), or maybe into some other writable DB.
– We can write results in the shared folder between the replicas (let’s say in a text file into a File Share)
– We can export the BLOB object of the statistics out of the SQL Server
– We can import the BLOB object of the statistics into the statistics
Let’s do this!
I have a test AG on a couple VMs with Sql Server 2017 (play with any version you feel like it works for you), and I take a rather plain table that I want to update my statistics on.
Here is script for creating a table and inserting one million rows into it:
DROP TABLE IF EXISTS dbo.SampleDataTable;
CREATE TABLE dbo.SampleDataTable (
C1 BIGINT NOT NULL,
C2 BIGINT NOT NULL,
CONSTRAINT PK_SampleDataTable PRIMARY KEY (C1)
);
INSERT INTO dbo.SampleDataTable WITH (TABLOCK)
SELECT t.RN, t.RN
FROM
(
SELECT TOP (1000000) ROW_NUMBER()
OVER (ORDER BY (SELECT NULL)) RN
FROM sys.objects t1
CROSS JOIN sys.objects t2
CROSS JOIN sys.objects t3
CROSS JOIN sys.objects t4
CROSS JOIN sys.objects t5
) t
OPTION (MAXDOP 1);
Additionally let’s create a statistics object ST_SampleDataTable_C2 that will cover column c2:
CREATE STATISTICS ST_SampleDataTable_C2 ON dbo.SampleDataTable(C2);
After that I will insert 1000 rows that will really matter and that I will really want to update my statistics on
set nocount on; INSERT INTO dbo.SampleDataTable WITH (TABLOCK) SELECT 10000000 + t.RN, 999999999 FROM ( SELECT TOP (1000) ROW_NUMBER() OVER (ORDER BY (SELECT NULL)) RN FROM sys.objects t1 CROSS JOIN sys.objects t2 CROSS JOIN sys.objects t3 CROSS JOIN sys.objects t4 CROSS JOIN sys.objects t5 ) t OPTION (MAXDOP 1);
Now I have a case of the value 999999999 that occurs 1000 times for the C2 column and that is definitely meets the ascending key problem and I really want to update my statistics … on secondary, so that I won’t impact the primary with the calculation and can serve my final customers.
Using the good old command DBCC SHOW_STATISTICS let’s take a look into our statistics object:
DBCC SHOW_STATISTICS('dbo.SampleDataTable', 'ST_SampleDataTable_C2')
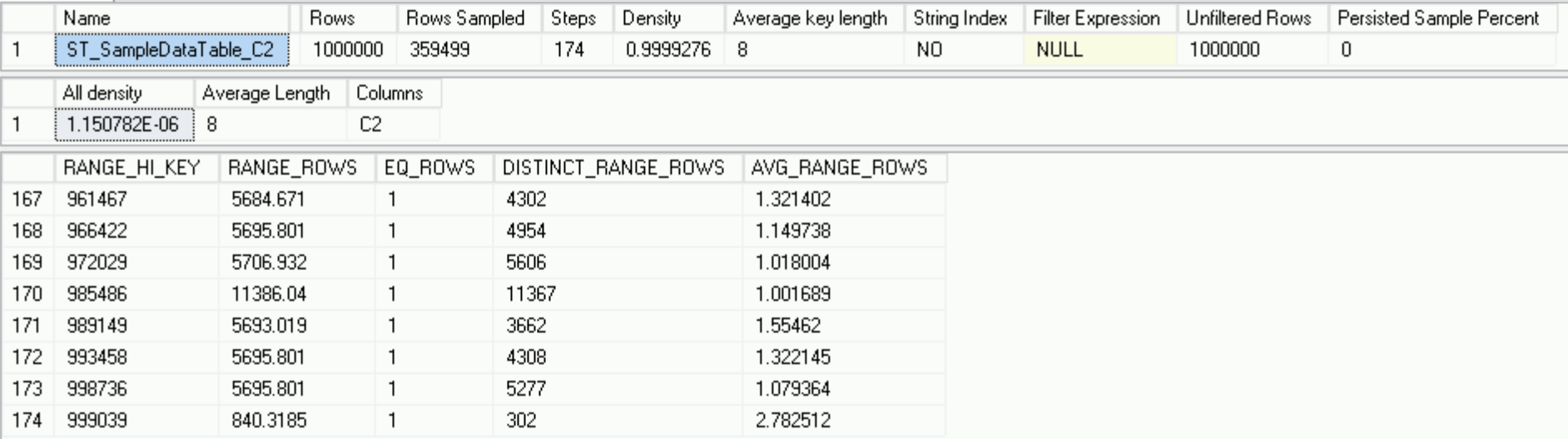 All is fine in the kingdom and our stats are totally fine, with just 1 Million Rows accountable and those perky 1000 rows will eventually make part of the new statistics, calculated on the primary replica.
All is fine in the kingdom and our stats are totally fine, with just 1 Million Rows accountable and those perky 1000 rows will eventually make part of the new statistics, calculated on the primary replica.
We can also check on the Statistics Stream with the help of the STATS_STREAM option of the DBCC SHOW_STATISTICS command:
DBCC SHOW_STATISTICS('dbo.SampleDataTable', 'ST_SampleDataTable_C2') WITH STATS_STREAM;
![]()
This is a rather simple character stream that has been blogged about for ages and even though I am not sure if this a totally documented feature, it has never prevented people from using it.
On the secondary replica
Let’s say we copy the table on the secondary replica into the TempDB (given that we are running synchronous Availability Groups, but we could do the very same with asynchronous AG as well, just the information would be potentially a bit delayed):
use TempDB;
DROP TABLE IF EXISTS dbo.SampleDataTable;
CREATE TABLE dbo.SampleDataTable (
C1 BIGINT NOT NULL,
C2 BIGINT NOT NULL,
CONSTRAINT PK_SampleDataTable PRIMARY KEY (C1)
);
INSERT INTO dbo.SampleDataTable
SELECT C1, C2
FROM AvGroupDb.dbo.SampleDataTable;
We are ready to update the statistics with the fullscan on the secondary replica on TempDB:
use TempDB; UPDATE STATISTICS ST_SampleDataTable_C2 ON dbo.SampleDataTable(C2) WITH FULLSCAN;
Coming back to the DBCC SHOW_STATISTICS let’s take a look into our statistics object:
DBCC SHOW_STATISTICS('dbo.SampleDataTable', 'ST_SampleDataTable_C2')
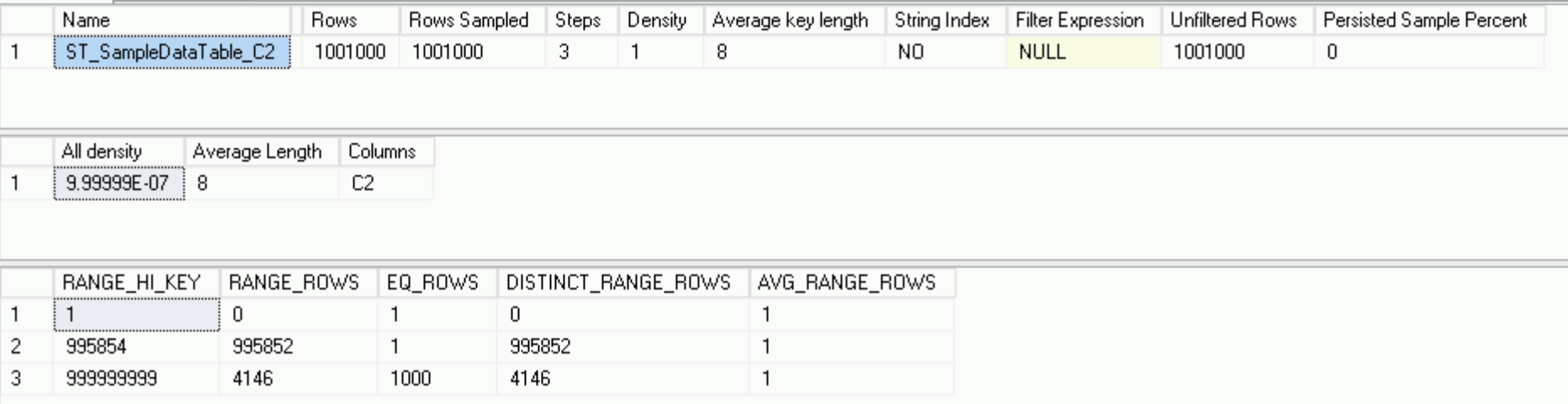 It looks pretty much different from the original one, with just 3 rows instead of 178 as in the original one, but it describes the data distribution perfectly – we have 1 Million distinct rows and 1000 rows with the same value – the histogram is as good as it can be.
It looks pretty much different from the original one, with just 3 rows instead of 178 as in the original one, but it describes the data distribution perfectly – we have 1 Million distinct rows and 1000 rows with the same value – the histogram is as good as it can be.
Switching to the statistics stream object:
DBCC SHOW_STATISTICS('dbo.SampleDataTable', 'ST_SampleDataTable_C2') WITH STATS_STREAM;
![]() You do not have to be a real genius to notice that the stream looks pretty different as well – we can see the symbols 5689A0C6 in the updated stream, while in the original between all those zeros we have had EDF10EB4.
You do not have to be a real genius to notice that the stream looks pretty different as well – we can see the symbols 5689A0C6 in the updated stream, while in the original between all those zeros we have had EDF10EB4.
Let’s focus now on exporting this data into a text file somewhere outside of the SQL Server, and I will do that with the help of the wonderful BCP command, that requires the CMDSHELL to be enabled (warning: you might not want to do that on your production server):
EXEC xp_cmdshell 'BCP "DBCC SHOW_STATISTICS(''AvGroupDb.dbo.SampleDataTable'', ''ST_SampleDataTable_C2'') WITH STATS_STREAM" queryout \\SharedServer\Tempdb\stats.txt -c -T';
Here is how big this stats.txt file will be on our shared folder:
![]()
Just a couple of KB, nothing else!
Easy to transport, easy to manage!
Back to Primary
On the primary server we shall need to create a temporary table that will store the statistics stream before we shall update our principle table SampleDataTable (or in practice we could expand table for multiple databases/tables/statistics:
CREATE TABLE dbo.TempStats( Stats_Stream VARBINARY(MAX), Rows BIGINT, DataPages BIGINT );
Let’s import that data from the text file into our new shiny temp table and let’s select the result we have imported:
BULK INSERT dbo.TempStats FROM '\\SharedServer\Tempdb\stats.txt' SELECT * FROM dbo.TempStats;
![]() We can see a pretty much similar data of what we have had calculated on our secondary server, but the data is already now on the primary server and all we shall have to do is to update our statistics on our test table. This operation can be done with the help of the UDPATE STATISTICS statement by using the option WITH STATS_STREAM = …
We can see a pretty much similar data of what we have had calculated on our secondary server, but the data is already now on the primary server and all we shall have to do is to update our statistics on our test table. This operation can be done with the help of the UDPATE STATISTICS statement by using the option WITH STATS_STREAM = …
DECLARE @script NVARCHAR(MAX) SELECT @script = 'UPDATE STATISTICS dbo.SampleDataTable(ST_SampleDataTable_C2) WITH STATS_STREAM = ' + CONVERT(nvarchar(max), [Stats_Stream],1) FROM dbo.TempStats PRINT @script; EXECUTE sp_executesql @script;
The following script above reads the imported value (yeah, I am doing one table sample here and do not care multiple statistics, threads, tables, databases, etc), creates the UPDATE STATISTICS statement, prints it out and then finally executes it.
Here is what I have got from the output:
UPDATE STATISTICS dbo.SampleDataTable(ST_SampleDataTable_C2) WITH STATS_STREAM = 0x010000000100000000000000000000005689A0C6000000007D020000000000003D020000000000007F0300007F0000000800130000000000000000000000000007000000C5BB2F0172AA000028460F000000000028460F00000000000000803FB4378635000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000003000000030000000100000018000000000000418062744900000000000000410000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000190400000000000000000000000000006900000000000000B900000000000000C100000000000000C900000000000000180000000000000033000000000000004E00000000000000100018000000803F000000000000803F0100000000000000040000100018000000803FC02073490000803F0E320F00000000000400001000180000007A44009081450000803FFFC99A3B000000000400000100000079DC280172AA00000000000080842E4140420F0000000000AE000000000000A0924EB33E9BD9BB9DFC19B4404449E6ABFE2F84400000000000408F400000000000000000DFE68293BDC8803F28460F00000000000000000000000000
Running the DBCC SHOW_STATISTICS on the primary gives me exactly the result I was hoping for – the same one we have obtained on the secondary replica. The loop is closed
DBCC SHOW_STATISTICS('dbo.SampleDataTable', 'ST_SampleDataTable_C2');
The really awesome part in this story is that the size of the statistics object is truly insignificant and we can transport it really easy/instantly to the primary replica.
Not so basic scenario:
– If you have multiple Availability Groups between the same replicas, where one replica leads one AG, while the other leads the second AG -> you can insert the BLOB data into the flow of the AGs and replicate an additional tiny database with the transported data.
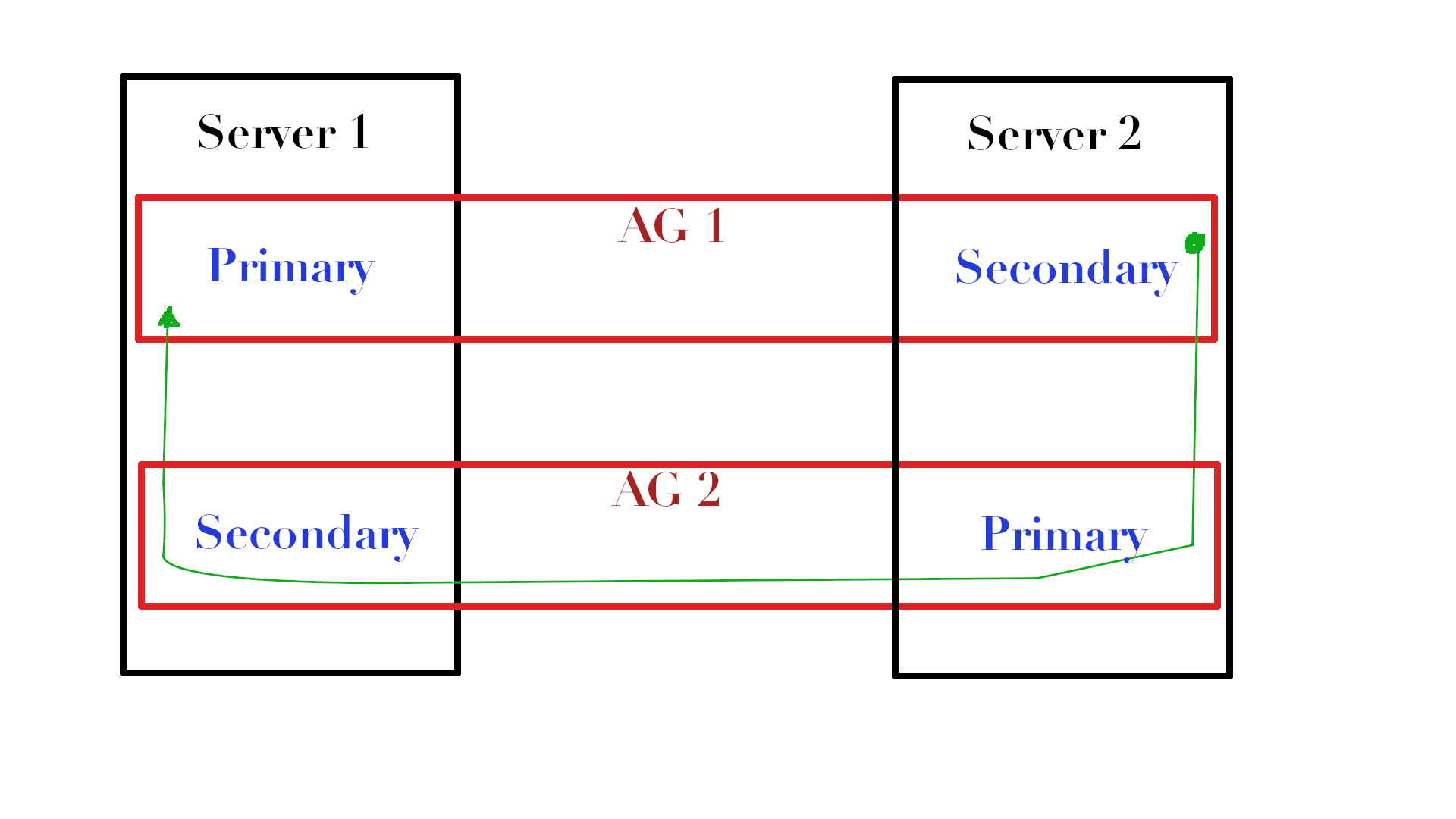 As on the picture on the left, if we have 2 Availability Groups (AG1 & AG2) that are located and forced to be on the distinct servers – and we have a certain table on the Server 1 in the Availability Group 1 that we want to update statistics on, then we could extract a copy of the table (let’s call it dbo.MyTable) on the Server 2 in the TempDB and use the Channel for the Availability Group 2 to deliver the statistics stream object back to the server 1, where we would simply re-import the data back into our primary table dbo.Mytable. Y
As on the picture on the left, if we have 2 Availability Groups (AG1 & AG2) that are located and forced to be on the distinct servers – and we have a certain table on the Server 1 in the Availability Group 1 that we want to update statistics on, then we could extract a copy of the table (let’s call it dbo.MyTable) on the Server 2 in the TempDB and use the Channel for the Availability Group 2 to deliver the statistics stream object back to the server 1, where we would simply re-import the data back into our primary table dbo.Mytable. YYes, I know it sounds quite confusing, but simply think about the AG 2 as the feedback channel to deliver results back instead of pushing them through the file share or Azure Blob Storage.
Complains area
You might have an objection or two, such as:
– why would I do this on the secondary, when I could do the same perfectly on the primary without further delays …
(Well, the idea here is to offload the primary)
– aren’t we potentially kicking a serious workload on the secondary (if it is stalled – then yeah, and that’s why we should try to use it’s powers)
– can’t we simply affect the primary with it ? (nope, we are reading the data and potentially writing back a couple of KB, where in the age of GB & TB this sounds like “say whaaaaaat?”)
– what if in the middle time the primary will start updating statistics by itself? In this case it can either cancel the secondary process, or will re-execute with the updated data (and limit such tentatives by number of 3)
but I do not buy it. :)
Availability Groups Feedback Channel Option
There is a feedback channel for the communication from the secondary replica to the primary – once we are logging a transaction on the synchronous replica, the primary will wait for the confirmation which is sent by the secondary replica – and I am thinking that this channel can be potentially used for the implementation of this improvement.  Take a look at the image on the left, which was taken from the original blog post by Simon Su –
Take a look at the image on the left, which was taken from the original blog post by Simon Su –
https://blogs.msdn.microsoft.com/psssql/2018/04/05/troubleshooting-data-movement-latency-between-synchronous-commit-always-on-availability-groups/, where the exact mechanism of the feedback channel is explained. The secondary replica using the step 12 and posterior ones confirms to the primary replica that the information has been persisted. The very same channel should be used to sent the statistics stream object after being recalculated on the secondary replica. Of course, we should not use the TempDB for this purpose, but creating an in-memory object within a database that is not persisted (looking at you In-Memory OLTP Schema-Only tables, or think about NOLOGGING tables in Oracle) that will be destroyed at the operation end – this would be really awesome.
General Thoughts
It does not really matter if the replica is synchronous or asynchronous – most of the time the statistics update do not take place every couple of seconds, and this brings us to the second part of the idea:
make statistics update an invokable possibility from the Primary Replica, with a parameter such as
UPDATE STATISTICS dbo.MyAwesomeTable(HugeImportantStatOnC17) WITH FULLSCAN, SECONDARY
where the indication of where the command should be executed is set with the command SECONDARY.
And as exactly as in the case of the Backups, we could have a configuration for the Statistics Update preference, choosing the replica that should be preferred for processing the Statistics Update (or any other command in the future).
I am confident that such feature would be something that would definitely motivate a lot of Enterprise Edition users to migrate to a new Sql Server version that could spread the heavy commands between the secondary replicas.
Oh, and imagine tuning this kind of stuff for the Azure SQL Database on the 2 of the secondary replicas behind the scene – could be pretty much a killer feature :)
In the mean time – oh yeah, I totally see how this solution can be automated with the help of Powershell :)
Microsoft, your turn! :)
Over & Out.
Ingenious! Now do it for multi-TB tables and without tempdb :) Is there a User Voice item to upvote?
Hi Alex,
indeed and here it is – https://feedback.azure.com/forums/908035-sql-server/suggestions/37972738-allow-updating-statistics-on-the-secondary-replica
Best regards,
Niko Neugebauer
Upvoted!