Continuation from the previous 126 parts, the whole series can be found at https://www.nikoport.com/columnstore/.
With the appearance of the Batch Mode on the Rowstore Indexes (FINALLY!), the big question (aka Elefant) is in the room – DO WE STILL NEED COLUMNSTORE INDEXES ?
The short answer is … NO! Of course, No!
Well, but let us consider the following reasons for keep on pushing the Columnstore Indexes for the Data Warehousing scenarios …
Columnstore & Columnstore Archival Compressions
The typical expected improvement of the PAGE compression will be 2-3 times, and even though there will be exceptions, the overall expectations on the Fact Tables containing a high number of repetitive values is hugely in favour of the Columnstore Indexes. The whole concept of the columnstore compression is about improvement on the table/partition level, while the PAGE compression is limited to the values within a 8KB of data.
Using the TPCH generated 100 GB database, I ran the size check of the dbo.lineitem table with 600 million rows:
use tpch100; EXECUTE sp_spaceused 'dbo.lineitem' use tpch100_rowstore; EXECUTE sp_spaceused 'dbo.lineitem'
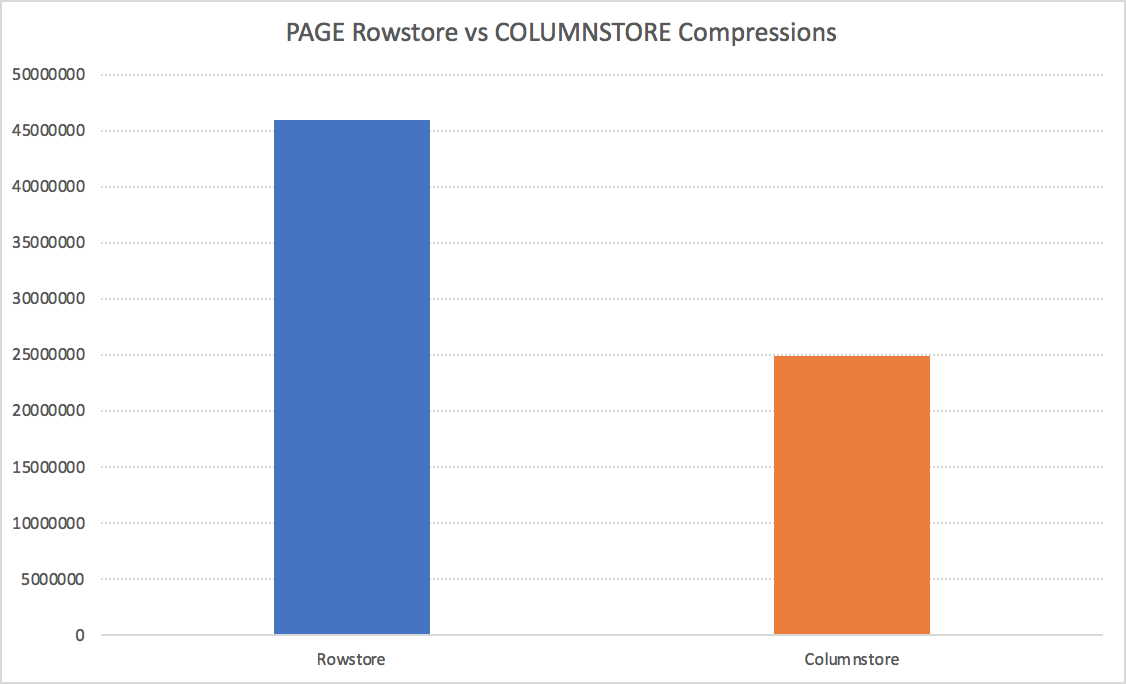 The results for the underlying structure are very clear – 24.855.208 KB for the Columnstore, while the Rowstore table structure takes 45.838.944 KB! We are seeing almost 2 times improvement, which will result in faster disk IO access, as well as the smaller amounts of memory occupied by the compressed tables – resulting in a better performance. While there are enough cases where the Columnstore Object Pool behaviour needs to be corrected (because under pressure it keeps pretty small percentage of the total available memory space), the overall IO will be hugely favourable for the Columnstore Indexes without any shade of the doubt.
The results for the underlying structure are very clear – 24.855.208 KB for the Columnstore, while the Rowstore table structure takes 45.838.944 KB! We are seeing almost 2 times improvement, which will result in faster disk IO access, as well as the smaller amounts of memory occupied by the compressed tables – resulting in a better performance. While there are enough cases where the Columnstore Object Pool behaviour needs to be corrected (because under pressure it keeps pretty small percentage of the total available memory space), the overall IO will be hugely favourable for the Columnstore Indexes without any shade of the doubt.
Advanced Storage Engine Optimizations
The Columnstore Indexes have a huge performance optimisation of the Advanced Storage Engine features, such as Aggregate Predicate Pushdown or the Local Aggregation as described in Columnstore Indexes – part 59 (“Aggregate Pushdown”) & Columnstore Indexes – part 80 (“Local Aggregation”). These features can deliver incredible performance, delivering results for tables with Billion of Rows within milliseconds!
String predicate pushdown can bring also some advantages on the Columnstore Indexes, especially if we are having very covering Dictionaries, with the columns themselves having very few distinct values. In any case the compression methods, such as bit pack array can give huge advantages to the columnstore, allowing to determine the presence or the absence of the predicate value within milliseconds and without scanning the whole column of values.
If we ran just some basic aggregation functions against the 1GB TPCH table:
SELECT COUNT(*), MAX(l_commitdate) FROM dbo.lineitem_cci; SELECT COUNT(*), MAX(l_commitdate) FROM dbo.lineitem;
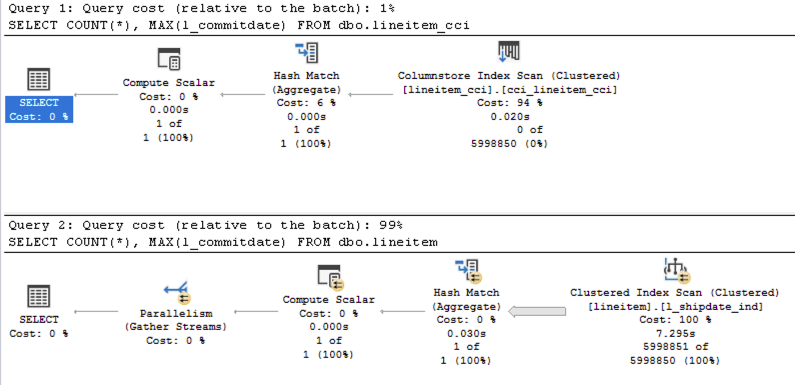
The execution times will be incredible distinct – with 16ms for the Columnstore Indexes vs 612 ms for the Rowstore Indexes. Notice that both queries are running with the Batch Execution Mode and the difference is around 40 times!
Trivial plan optimization
Remember that starting with SQL Server 2017 all plans with the Columnstore Indexes shall get an Full optimisation level, resulting more times in the presence of the Batch Execution Mode. For more detailed information, you can consult the blog post Columnstore Indexes – part 109 (“Trivial Plans in SQL Server 2017”)
The basic example would be this one: after ensuring that your Threshold for Parallelism is set to 50 or higher –
EXEC sys.sp_configure N'cost threshold for parallelism', N'50' GO RECONFIGURE WITH OVERRIDE GO
run the following 2 queries against the 1GB TPCH database
use tpch_1g; SELECT COUNT(*) FROM dbo.lineitem; SELECT COUNT(*) FROM dbo.lineitem_cci;
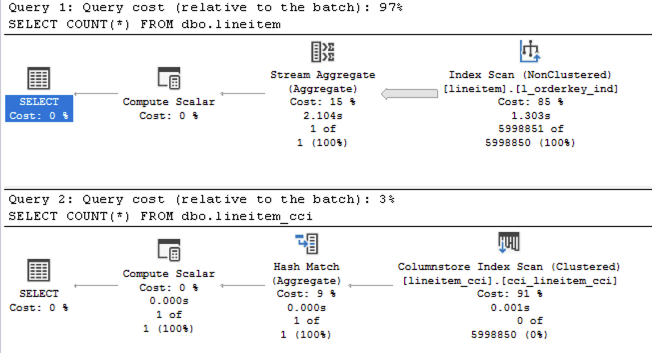
Even after looking at the Execution Plan you should be able to recognise that the presence of the Stream Aggregate is not very supportive, in the way that it does not support the Batch Execution Mode and if you hover over the Rowstore Nonclustered Index Scan, you will notice that it is being executed in the Row Execution Mode, meaning the first query runs really slow vs the second one. The difference of 2ms for the Columnstore Indexes vs 543 ms for the Rowstore Indexes is very much noticeable, and while for the complex queries the trivial plan optimisation might be the less of the problem and you can always improve it by rewriting and making the query being “more complex”, I am talking here about the feature that is running out of the box and that gives incredible advantages in SQL Server 2017 and later versions.
SQL 2019 only (Will it be EE?)
Full Speculaiton Mode: I believe that the initial release might be bringing Batch Mode on the Rowstore Indexes only to the Enterprise Edition. This is a performance feature, and not a development feature like the Columnstore Indexes – meaning that most probably Microsoft will put it in the Enterprise Edition only. And I honestly believe that IF it will make down to the Standard & Express editions one day, this day is years away, meaning that the most of us will not be able to use this feature in production at all.
Bad location for the Bitmap Filters for Batch Mode on Rowstore now (to be updated once it is solved)
Right now, in CTP 2.0 the location of the Bitmap Filters and their execution prevents the Batch Execution Mode on the Rowstore Indexes to be even distantly comparable with the Batch Mode over the Columnstore Indexes and when you are testing 100GB TPCH Database or even bigger ones, the performance of the Batch Execution Mode on the Rowstore Indexes is actually slower when compared to traditional Row Execution Mode on the Rowstore Indexes. I expect this to be solved before the RTM of the SQL Server 2019, but there will be definitely scenarios for the initial release where things will go wrong for the Batch Execution Mode over the Rowstore and where it won’t perform any faster than in previous SQL Server versions.
By the contrast, Columnstore Indexes will be already in their 5th release by the RTM of the SQL Server 2019 with a lot of performance troubles have been already addressed in the previous 8 years.
Hekaton disables Batch Mode Scan, LOBs presence (even as a predicate) disables Batch Mode completely
As described in Batch Mode – part 4 (“Some of the limitations”), the limitations for the Hekaton (In-Memory OLTP) and the LOBs are dreading – we won’t be getting those fixed until a couple of the future releases and many people complaining about them, which I do not honestly expect.
Meaning that the Batch Mode on Rowstore will be “loosing its name” in some of such situations, giving a full green light to the Columnstore Indexes.
There will be more limitations and edge situations found, but that is already enough for me to look at the Batch Execution Mode on the Rowstore Indexes as a huge improvement for the edge scenarios on the Rowstore Indexes, but still not up to the game vs the Columnstore Indexes for the DataWarehousing scenarios.
HTAP
What about HTAP – Hybrid Transactional Analytical Processing ?
Here is where I believe that the Batch Mode over the Rowstore Indexes shall succeed, and in some scenarios shall bring better performance – especially because of winning on the Writable operations (INSERT, DELETE & UPDATE), while of course the compression of the Columnstore Indexes shall gain some advantages back in the typical scenario.
Basic Decision Workflow
Here is the basic decision workflow that might help you with a decision of advancing with the Batch Mode on the Rowstore Indexes:
If you are indeed running Analytical Queries with aggregations,
If you are using some of the features that are not supported by the Columnstore Indexes (there are less & less of them with every release),
and especially, if your workload is CPU-bound, because after all the Batch Execution Mode is an improvement for the CPU-intensive operations, then you should consider Batch Execution Mode on the Rowstore Indexes:
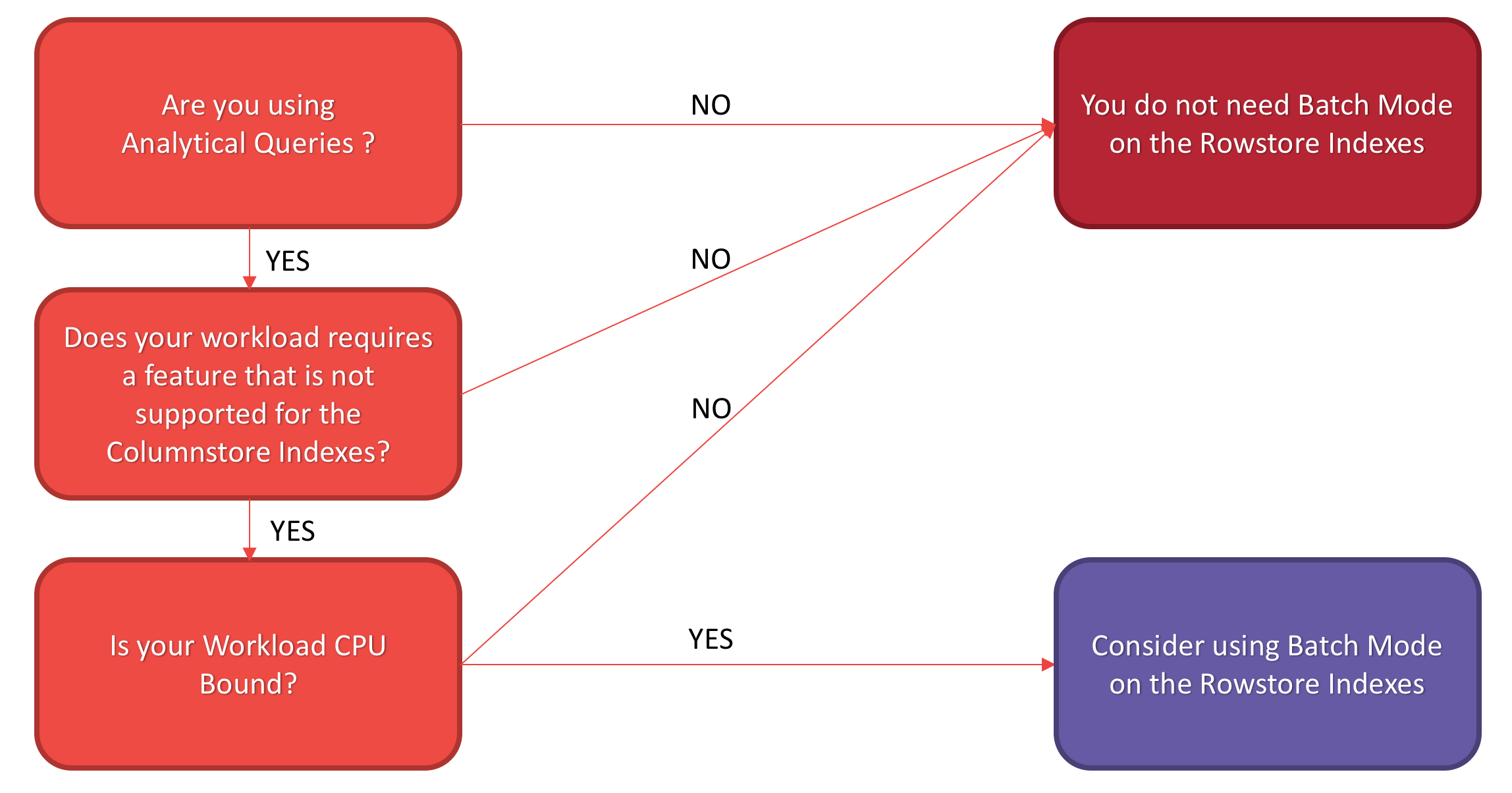
The workflow for this graph was developed by the incredible Joe Sack & Vassilis Papadimos.
Should you be able to prefer Columnstore Indexes – then you definitely should keep using them.
to be continued with Columnstore Indexes – part 128 (“Ordering Columnstore Indexes in Azure SQL Datawarehouse”)
batch mode in row store is not meant to displace column store, simple to make large aggregate queries in traditional row-store better. Columnstore is really fast because the sequential/streaming memory access can make full use of modern processors,
whereas as traditional row store is essentially an exercise in pointer-chasing code: access memory to determine the next memory address to access, which does not make good use of a CPU core in which 2.5GHz – 0.4ns cycle time, versus round-trip memory between 75-140ns (187-350 CPU-cycles).
In any case, preliminary: TPC-H queries to row-store data appears to be 10-30% faster in SQL Server 2019 CTP 2.1 versus 2017
Hi Joe,
thank you for the comment! I agree with you, that it is not mean to displace the columnstore. There are enough scenarios when it is needed and where Columnstore simply is not welcome, but my worry is that people are already starting to talk about Batch Mode on Rowstore as it was the solution (while the product is in the CTP phase, haha).
The memory access for the Rowstore, I would expect to be optimised in the Batch Building phase and after it passes to the consecutive iterators (Aggregations, Joins, Sorts) – it should deliver a comparable performance when comparing to Columnstore, while the initial Index Scan will generally stay on the loosing side (with notable exceptions of not supported predicate pushdowns for Columnstore).
Regarding TPCH I have to say that I have very mixed results so far (some queries do perform significantly worse) and that’s why I am waiting to see some of the limitations getting fixed (bitmap filter location) to make my judgement about how much faster in general it can be.
Best regards,
Niko
Columnstore Object Pool behaviour needs to be corrected (because under pressure it keeps pretty small percentage of the total available memory space)
Could you please elaborate
Hi Manish,
on a completely working system with Columnstore Indexes, the User Cache where the Columnstore Segments/Dictionaries/Deleted Bitmaps/etc are located is called Columnstore Object Pool – and this user cache is located outside of the Buffer Pool. On a production system when monitoring the Columnstore Object Pool size, you will notice that its size typically won’t grow over 10-15% of the Max Memory size. If you are running a Data Warehouse with the most tables using Columnstore Indexes – you will not be able to work with the full size of your memory objects, your system will work with Disk IO much more than it is actually needed.
Best regards,
Niko