This blog post is a part of the whole Batch Mode series, which can be found at the Nikoport Batch Mode page.
With the initial public CTP release of the SQL Server 2019 – the CTP 2.0 we have finally received the feature that I was asking for the last 7 years – the Batch Execution Mode over the Rowstore Indexes. Finally we have a supported tool, that does not require major hacks (*cough*, *cough* – we shall see) and will improve some of the workloads automagically.
The idea here in SQL Server 2019 is that the Batch Execution shall be initiated automatically, based on the internal heuristics. While the core of the idea of making it default is extremely awesome, I am truly wondering if the heuristics will be dynamic enough to interpret some of the cases where the Query Optimiser should have simply backed off, until a more complete implementation will follow – but that’s what the CTPs (Community Technology Previews) are made for – for testing and for the feedback of everyone considering to migrate to the final release of SQL Server 2019.
The Batch Mode for the Columnstore Indexes is enabled in the latest SQL Server editions & Azure SQL Database by default and in the most cases when you are running a compatible query type (not a recursive query, for example) you would get its benefits for your query processing. The same logic seems to be the way to applied for the Batch Mode over the Rowstore. I will state quite clear that after running a couple of workloads – I am not completely convinced that it is an awesome idea, mainly because of the schema building qualities of application designers – where in the wild one could find pretty bizarre data types and inter-table connectivity options. I am definitely jumping ahead here, so let’s get back to the basis and start with how to see how to notice if your query over the Rowstore Indexes is running in the Batch Execution Mode.
For the testing purposes I will be using a 10GB TPCH sample database, that can be easily generated with the help of the free software, such as the HammerDB.
The Basics
The improvement of the Batch Mode for the Rowstore Indexes is hidden behind the compatibility level of 150, as with all previous Query Optimiser in the 2-3 previous versions of SQL Server – and in order to enable it we need to make sure that the compatibility level for our database is set correctly. For this purpose I have issued the following command:
ALTER DATABASE [tpch_10]
SET COMPATIBILITY_LEVEL = 150;
To see and understand how Batch Mode works for the Rowstore Indexes, let’s fire a rather trivial query agains the dbo.lineitem table, calculating the monthly tax and sold quantities:
SELECT MONTH(l.l_shipdate) as [Month], SUM(l.[l_quantity]) as [Total Quantity], SUM(l.l_tax) as [Total Tax] FROM dbo.lineitem l GROUP BY MONTH(l.l_shipdate) ORDER BY MONTH(l.l_shipdate) OPTION (RECOMPILE);
You will find the actual execution plan in the image below:

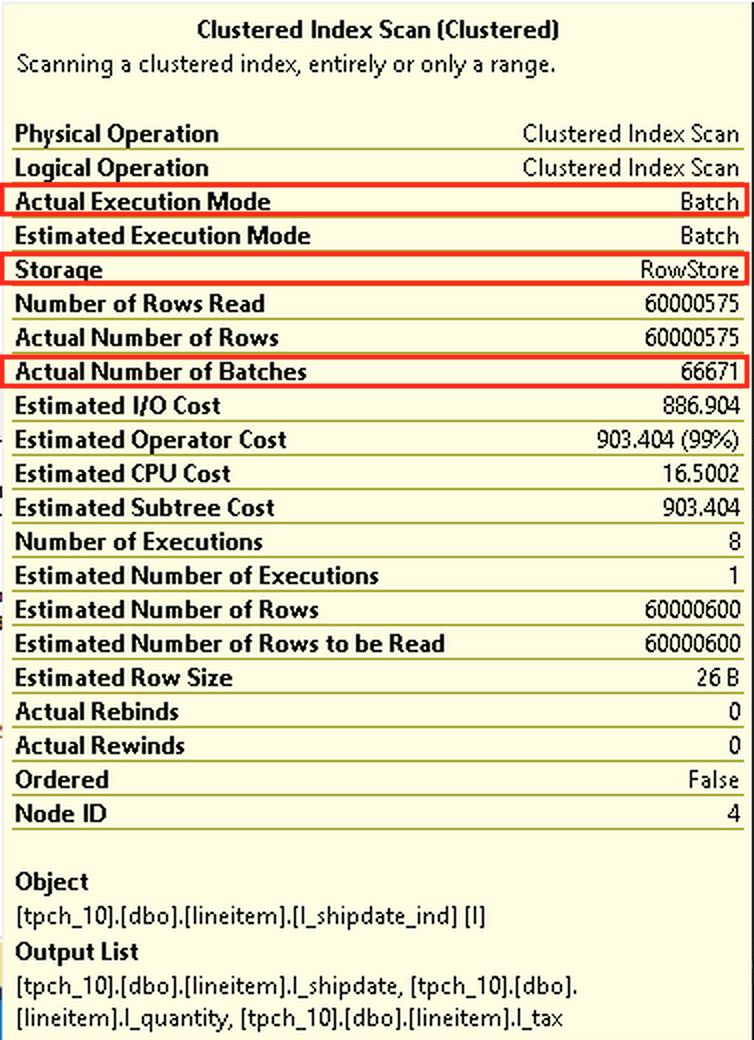 On the left to this text, you can see the properties of the Clustered Index Scan (Notice that there are no Columnstore References and that I am not using any hacks or trace flags), and with a red rectangles the essential properties, such as “Actual Execution Mode” which is Batch Mode, “Actual Number of Batches” which is superior to 0 – meaning the Batch Mode is being executed and for the last I marked the “Storage” property just to make sure that you understand that for the first time in the history it works without any additions or hints for the Rowstore Indexes.
On the left to this text, you can see the properties of the Clustered Index Scan (Notice that there are no Columnstore References and that I am not using any hacks or trace flags), and with a red rectangles the essential properties, such as “Actual Execution Mode” which is Batch Mode, “Actual Number of Batches” which is superior to 0 – meaning the Batch Mode is being executed and for the last I marked the “Storage” property just to make sure that you understand that for the first time in the history it works without any additions or hints for the Rowstore Indexes.
As a matter of a fact, indeed 4 of the 6 iterators in the execution plan are being executed with the Batch Mode, but unfortunately even after years of asking no tool is supporting the visual cue (or some kind of help), which iterators are running in the Batch Execution Mode. I wish SSMS to have a small icon in the top right corner with a Lightning Bolt or something similar – and here is an old connect item with this suggestion, please consider voting it up if you think it will be useful to you.
In order to test the operability of the compatibility level and the respective impact on the performance, lets reset the compatibility level back to 140 – corresponding to the SQL Server 2017:
ALTER DATABASE [tpch_10]
SET COMPATIBILITY_LEVEL = 140;
Let’s execute the same query again
SELECT MONTH(l.l_shipdate) as [Month], SUM(l.[l_quantity]) as [Total Quantity], SUM(l.l_tax) as [Total Tax] FROM dbo.lineitem l GROUP BY MONTH(l.l_shipdate) ORDER BY MONTH(l.l_shipdate) OPTION (RECOMPILE);

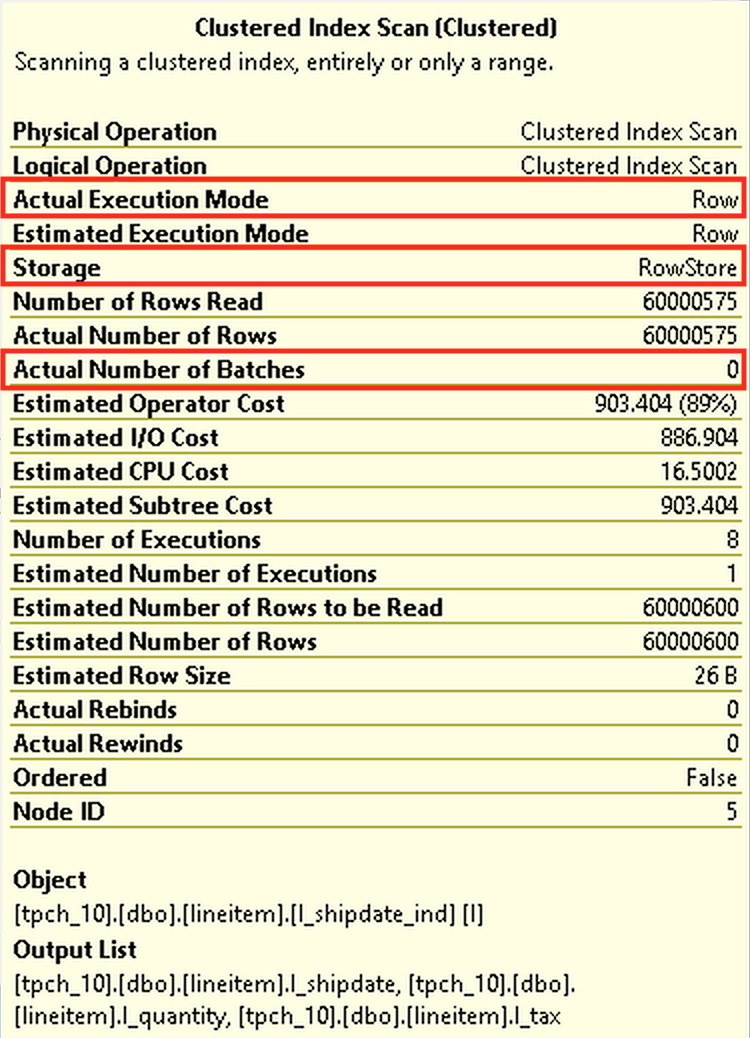 The actual execution plan above shows a different execution plan (ha! expect some more blog posts on this topic in the future) with a sort going into a single-threaded mode which is not bad, since we do not push a lot of data into it, but the 60 Million Rows out of the dbo.lineitem table getting a Compute Scalar and Hash Match operations should have brought a measurable difference to the execution time.
The actual execution plan above shows a different execution plan (ha! expect some more blog posts on this topic in the future) with a sort going into a single-threaded mode which is not bad, since we do not push a lot of data into it, but the 60 Million Rows out of the dbo.lineitem table getting a Compute Scalar and Hash Match operations should have brought a measurable difference to the execution time.
On the picture to the left the relevant properties of the Clustered Index Scan are marked with a red rectangle – “Actual Execution Mode” which is Row Execution Mode, “Actual Number of Batches” is 0 – confirming that the Batch Mode do live here anymore. :)
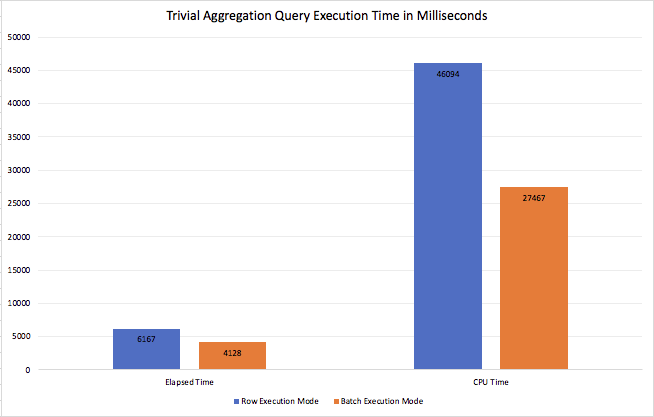
Regarding the execution times, there is a very good difference – with the Batch Mode (2019) over Rowstore getting the job done in 4.2 seconds, while the traditional Row Execution Mode needing over 6.1 seconds to do the very same – around 50% slower!!!
Display Estimated Execution Plan
The estimated execution plan is very supportive in my tests so far, showing the really expected execution plans and respecting the compatibility level settings for the database.
The Options
I could not escape mentioning a couple of the supported options for the Batch Mode over the Rowstore Indexes, especially since I expect a pretty strong need to control them over the database and over the single query execution.
The database scoped configuration for the Batch Mode on the Rowstore can be controlled with the BATCH_MODE_ON_ROWSTORE option – disabling it:
ALTER DATABASE SCOPED CONFIGURATION SET BATCH_MODE_ON_ROWSTORE = OFF;
or enabling it on the database level:
ALTER DATABASE SCOPED CONFIGURATION SET BATCH_MODE_ON_ROWSTORE = ON;
The individual queries are controlled with the help of the ‘ALLOW_BATCH_MODE’ & ‘DISALLOW_BATCH_MODE’ user hints, which are in practice are much more then just simple ON/OFF buttons, because there is absolutely no guarantee that ALLOW_BATCH_MODE user hint will make your query using the Batch Execution Mode – it will allow the Query Optimiser considering it and it eventually might lead to the Batch Execution Mode over the Rowstore or not.
Consider if we would want to try running the same query with the 150 compatibility level on the database and where we would need to disable the Batch Execution Mode because it would be very inefficient – we would use the DISALLOW_BATCH_MODE user hint:
SELECT MONTH(l.l_shipdate) as [Month],
SUM(l.[l_quantity]) as [Total Quantity],
SUM(l.l_tax) as [Total Tax]
FROM dbo.lineitem l
GROUP BY MONTH(l.l_shipdate)
ORDER BY MONTH(l.l_shipdate)
OPTION(RECOMPILE, USE HINT('DISALLOW_BATCH_MODE'));
The very same execution plan as for the 140 compatibility level (SQL Server 2017) for our query with a SQL Server 2019 compatibility level (150) will present itself as a result:
and indeed all the iterators will function in the Row Execution Mode.
As an example of something that won’t work with the single ALLOW_BATCH_MODE hint, consider a very similar query, which will only get an addition of the search predicate for the discounts superior a 1.0 value:
SELECT MONTH(l.l_shipdate) as [Month],
SUM(l.[l_quantity]) as [Total Quantity],
SUM(l.l_tax) as [Total Tax]
FROM dbo.lineitem l
WHERE l.l_discount > 1.0
GROUP BY MONTH(l.l_shipdate)
ORDER BY MONTH(l.l_shipdate)
OPTION(RECOMPILE, USE HINT('ALLOW_BATCH_MODE'));
The original query without the hint will be executed in the Row Execution Mode – because the heuristics of the query do not suggest the Batch Mode involvement (and more info on this in the upcoming blog posts).
Not every query will get faster
Consider the following query:
set statistics time,io on
SELECT SUM(L_EXTENDEDPRICE* (1 - L_DISCOUNT)) AS REVENUE
FROM LINEITEM, PART
WHERE (P_PARTKEY = L_PARTKEY AND P_BRAND = 'Brand#12' AND P_CONTAINER IN ('SM CASE', 'SM BOX', 'SM PACK', 'SM PKG') AND L_QUANTITY >= 1 AND L_QUANTITY <= 1 + 10 AND P_SIZE BETWEEN 1 AND 5
AND L_SHIPMODE IN ('AIR', 'AIR REG') AND L_SHIPINSTRUCT = 'DELIVER IN PERSON')
OR (P_PARTKEY = L_PARTKEY AND P_BRAND ='Brand#23' AND P_CONTAINER IN ('MED BAG', 'MED BOX', 'MED PKG', 'MED PACK') AND L_QUANTITY >=10 AND L_QUANTITY <=10 + 10 AND P_SIZE BETWEEN 1 AND 10
AND L_SHIPMODE IN ('AIR', 'AIR REG') AND L_SHIPINSTRUCT = 'DELIVER IN PERSON')
OR (P_PARTKEY = L_PARTKEY AND P_BRAND = 'Brand#34' AND P_CONTAINER IN ( 'LG CASE', 'LG BOX', 'LG PACK', 'LG PKG') AND L_QUANTITY >=20 AND L_QUANTITY <= 20 + 10 AND P_SIZE BETWEEN 1 AND 15
AND L_SHIPMODE IN ('AIR', 'AIR REG') AND L_SHIPINSTRUCT = 'DELIVER IN PERSON')
which looks pretty much old (pre-92 style table join) with just 2 tables being joined (60 Million Rows and 2 Millions for dbo.lineitem and dbo.part respectively) and a couple pretty much real life predicates. In fact, this is a Query 19 from the TPCH standard test. :)
Let's run it a couple of times agains the 10 GB TPCH database while measuring the execution time, and let's run it again, but this time with a OPTION (USE HINT('DISALLOW_BATCH_MODE')) user hint which will effectively disalow any possibility of the Batch Execution for our query:
set statistics time,io on
SELECT SUM(L_EXTENDEDPRICE* (1 - L_DISCOUNT)) AS REVENUE
FROM LINEITEM, PART
WHERE (P_PARTKEY = L_PARTKEY AND P_BRAND = 'Brand#12' AND P_CONTAINER IN ('SM CASE', 'SM BOX', 'SM PACK', 'SM PKG') AND L_QUANTITY >= 1 AND L_QUANTITY <= 1 + 10 AND P_SIZE BETWEEN 1 AND 5
AND L_SHIPMODE IN ('AIR', 'AIR REG') AND L_SHIPINSTRUCT = 'DELIVER IN PERSON')
OR (P_PARTKEY = L_PARTKEY AND P_BRAND ='Brand#23' AND P_CONTAINER IN ('MED BAG', 'MED BOX', 'MED PKG', 'MED PACK') AND L_QUANTITY >=10 AND L_QUANTITY <=10 + 10 AND P_SIZE BETWEEN 1 AND 10
AND L_SHIPMODE IN ('AIR', 'AIR REG') AND L_SHIPINSTRUCT = 'DELIVER IN PERSON')
OR (P_PARTKEY = L_PARTKEY AND P_BRAND = 'Brand#34' AND P_CONTAINER IN ( 'LG CASE', 'LG BOX', 'LG PACK', 'LG PKG') AND L_QUANTITY >=20 AND L_QUANTITY <= 20 + 10 AND P_SIZE BETWEEN 1 AND 15
AND L_SHIPMODE IN ('AIR', 'AIR REG') AND L_SHIPINSTRUCT = 'DELIVER IN PERSON')
OPTION (USE HINT('DISALLOW_BATCH_MODE'));
Both of the execution plans are presented below (first is the one with the Batch Execution Mode by default, the second one is for the disallowed Batch Mode):
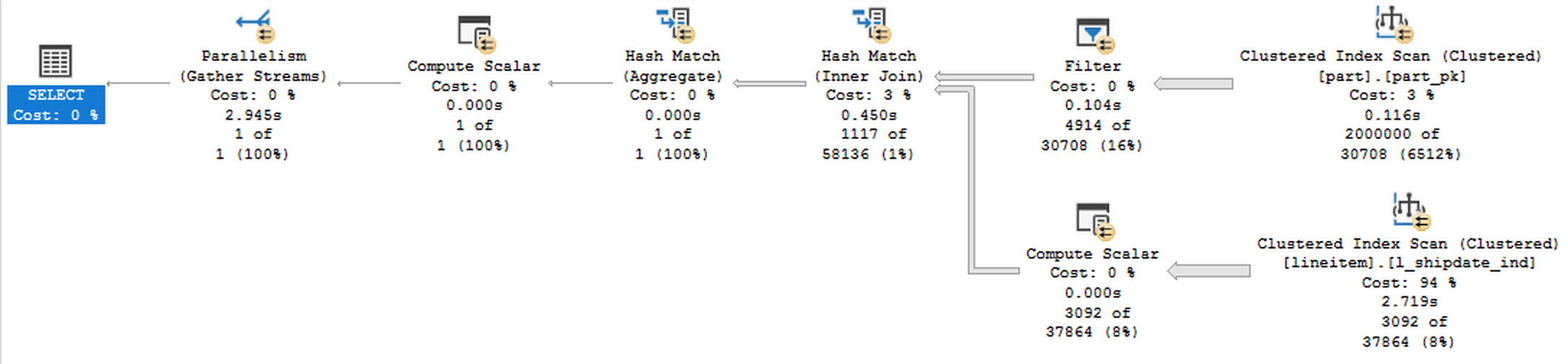

and while the first one looks much prettier & much smaller, the execution times tell us quite a different story - the Batch Mode needs 2.9 seconds to finish its execution, while the good old Row Execution Mode needs just 1.3 seconds - which means that Batch Mode by default will make your query run 2 times slower !!!
Going through the documentation and other communication, I feel that the program management team is extremely clear on the expectations that not every query will become automagically faster, but I guess nobody expects situations like this - where server might function significantly slower BECAUSE of the Batch Execution Mode.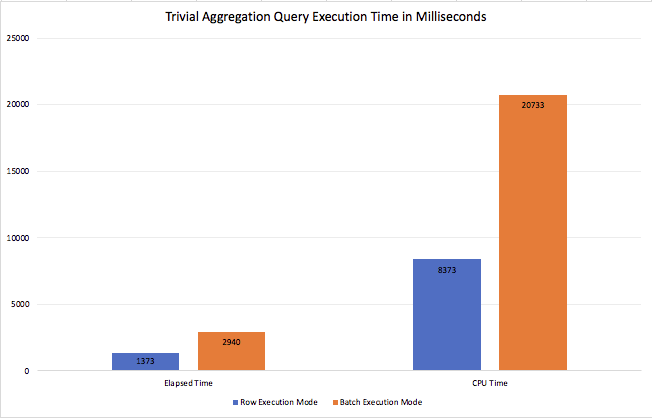
I have a feeling that the presence of the string filter here provokes the difference in the results, especially since historically Batch Mode & the Columnstore Indexes were no friends of the Strings at all.
Alternatively this can be some kind of a bug, because while looking at the execution plan, I can't find any good reasons for this functionality, but I guess no matter how hard every software developer shall try & fix such situations - there will be enough cases where nobody can guarantee that it won't affect your server. That is the reason why I am thinking that maybe a default option should be a disabled Batch Execution Mode - at least for the SQL Server 2019 and after that release when enough metrics are picked up, a decision to make it enabled by default can be made.
Why does it took so long? Isn't it just an adaptation of the Batch Mode Injection?
This is a different thing. This is a very different game with the different rules!
While in the original hacks, the adaptation/conversion of the rows to the batches is taking place pretty much invisible to us, the end users - in the Batch Mode over the Rowstore the processing of the Rowstore is delivering the Batches, thus doing a very significant CPU optimisation over the original hacks. How significant could it be ?
Well, the more rows you have, the bigger the difference will be, because after all the more CPU work is being done, the bigger impact on the conversions will be.
For the example, let's create an empty table with a Clustered Columnstore Index:
DROP TABLE IF EXISTS dbo.CCIDummy; CREATE TABLE dbo.CCIDummy( c1 INT, INDEX CCI_CCIDummy CLUSTERED COLUMNSTORE );
Now let's run the comparison of the 2 queries, the first one will be Batch Mode over the Rowstore and the second will use the LEFT JOIN dbo.CCIDummy ON 1=0 condition, which is a hack available since SQL Server 2014 for enabling Batch Execution Mode over the Rowstore Structures.
For the Batch Mode over the Rowstore (SQL Server 2019 news) let's ensure that the Batch Mode on the Rowstore is enabled by setting the Database Scoped Configuration,
and for the Batch Mode Injection (SQL Server 2014+) let's set it off, making sure that we are running old style as much as possible:
SET STATISTICS TIME, IO ON
ALTER DATABASE SCOPED CONFIGURATION SET BATCH_MODE_ON_ROWSTORE = ON;
-- 2019 Batch Mode over the Rowstore
SELECT MONTH(l.l_shipdate) as [Month],
SUM(l.[l_quantity]) as [Total Quantity],
SUM(l.l_tax) as [Total Tax]
FROM dbo.lineitem l
INNER JOIN dbo.part p
ON l.l_partkey = p.p_partkey
WHERE p.p_name like 'N%'
GROUP BY MONTH(l.l_shipdate)
ORDER BY MONTH(l.l_shipdate)
OPTION (RECOMPILE, USE HINT('ALLOW_BATCH_MODE'));
ALTER DATABASE SCOPED CONFIGURATION SET BATCH_MODE_ON_ROWSTORE = OFF;
-- Old SQL Server 2014 Batch Mode Injection
SELECT MONTH(l.l_shipdate) as [Month],
SUM(l.[l_quantity]) as [Total Quantity],
SUM(l.l_tax) as [Total Tax]
FROM dbo.lineitem l
LEFT JOIN dbo.CCIDummy
ON 1 = 0
INNER JOIN dbo.part p
ON l.l_partkey = p.p_partkey
WHERE p.p_name like 'N%'
GROUP BY MONTH(l.l_shipdate)
ORDER BY MONTH(l.l_shipdate)
OPTION (RECOMPILE)
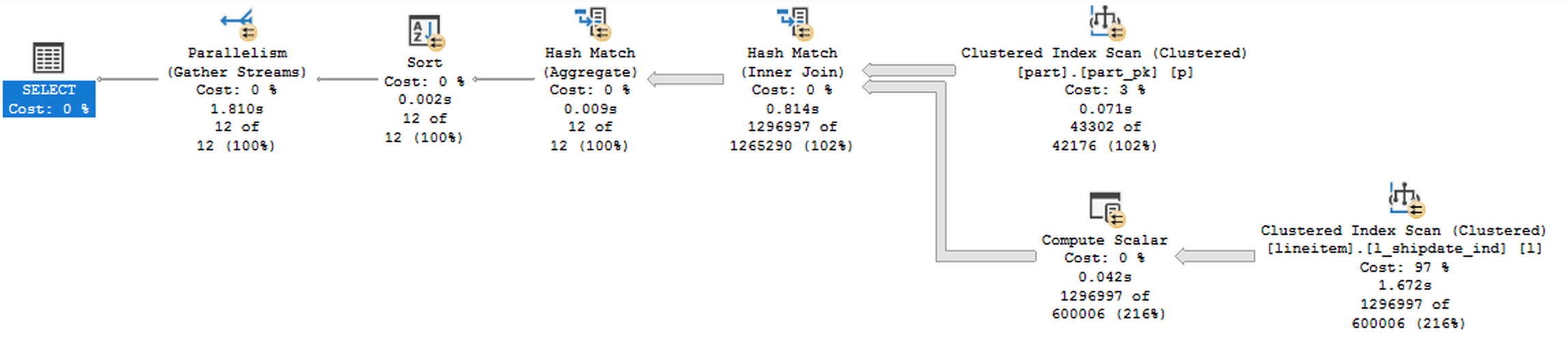

Looking at the execution plans above, one could easily incline to favour the first plan, because it has iterators while being basically a moral equivalent for the second one, with just one (ha-ha-ha) perky iterator being different - the second execution plan has that itchy Filter iterator, and by now you should know that so many times this is exactly where the things go slow & wrong.
The other thing is when you hover the mouse cursor over the iterators, you will notice that the Clustered Index Scan over the lineitem table as well as the Filter iterator are both running in the Row Execution Mode, where the Batch Mode kicks in only at the Compute Scalar iterator, making the largest row processing part of the execution plan to work with the slow Row Execution Mode.
What would be the result of those changes and the adaptors?
Oh here it is in the textual form:
SQL Server Execution Times: CPU time = 11499 ms, elapsed time = 1822 ms. SQL Server Execution Times: CPU time = 22751 ms, elapsed time = 3204 ms.
Here is a visual information, which will show that we get almost double of the performance:
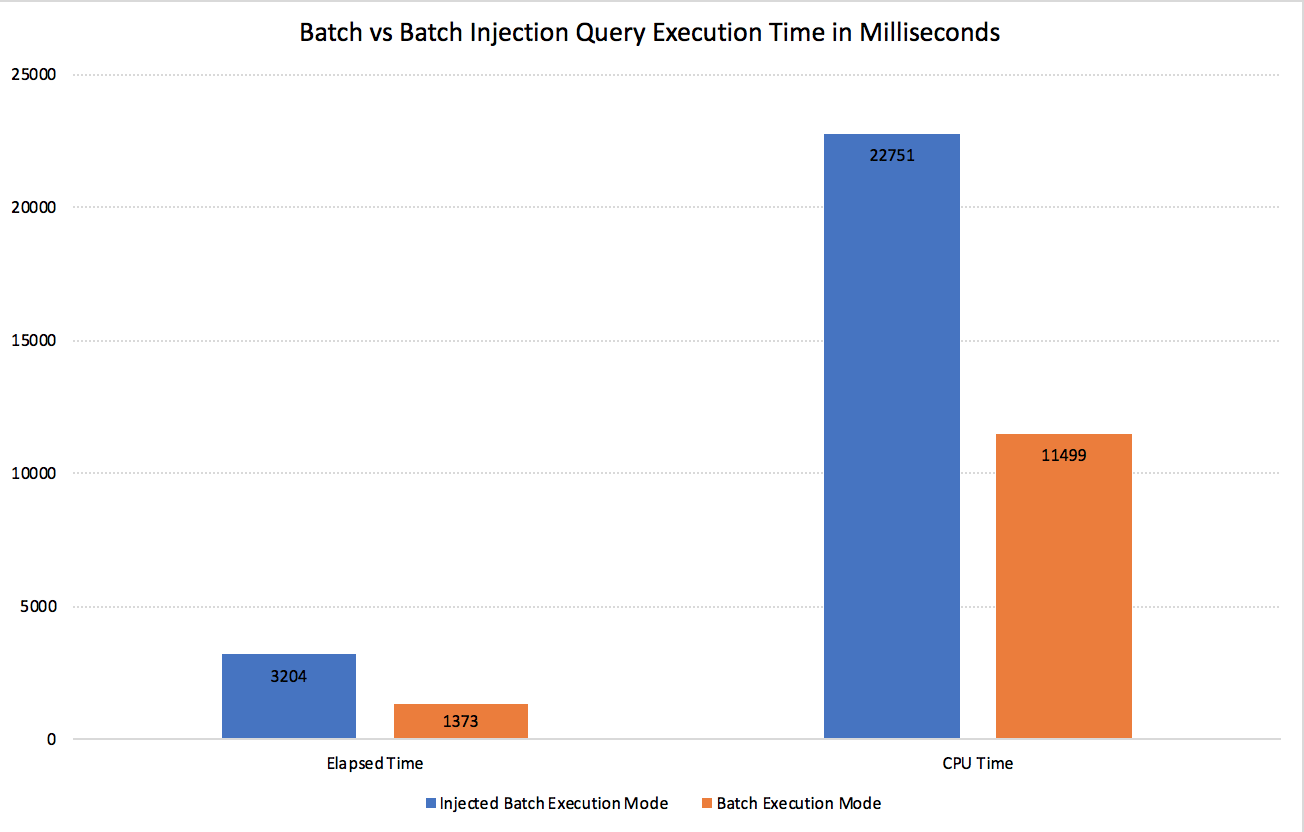 This should be enough reason to start testing all those injected Batch Modes and see if on SQL Server 2019 they can much better results by default.
This should be enough reason to start testing all those injected Batch Modes and see if on SQL Server 2019 they can much better results by default.
If you have any doubts, try running the same queries over 100GB TPCH database :) Scaling is a huge advantage for the CPU-intensive workloads and in my test the difference between 22 seconds (Batch Mode over Rowstore) vs 41 seconds (Batch Mode Injection), meaning that it scales pretty much linear in those sizes, but the number of seconds of difference is a smashing one and if your Data Warehouse is in the TB size, please consider checking out the default Batch Mode over Rowstore - it might be hugely worth it!
First Thoughts
I am beyond ecstatic to see this item finally being implemented for the SQL Server - this might provide itself as a real game changer for a number of scenarios, such as (and not limited):
- when one can not use the Columnstore Indexes (think Replication from your Data Warehouse which is not supported for the Clustered Columnstore, the same as Change Data Capture (CDC) or Change Tracking (CT), etc)
- when the Columnstore Compression & Architecture are not allowing you to apply them on the particular table (high frequency, irregular updates), and I have had a fair share of those for the DWH in the past years.
- your workload is CPU bound, but someone in your organisation still does not like or fears the change to the Columnstore Indexes
- other edge cases
I am anxious for SQL Server 2019 to get RTM and to show what can simply get faster without big additional work and help the clients to achieve their goals faster.
I do feel that the lack of FORCING the Batch Execution Mode is a lost potential - there will be some edge cases where the heuristics will simply won't comply, and there must be some hidden Trace Flag - well, in any case I am confident that an appropriate hack (oops, solution) will be found.
In the next blog post I will play with a couple of the heuristics challenges and show can we understand the behaviour of the Batch Execution Mode with a little bit more precision.
to be continued with Batch Mode – part 3 ("Basic Heuristics and Analysis")
Batch mode over row store can provide staggering performance gains as you have shown. This is a game changer for DW style queries. When was the last time a SQL Server release brought 50% or more query time reduction for a huge class of queries?! Amazing.
Hi tobi,
Agreed, and the most amazing thing is like with the most ground-breaking changes – most of the people look at it and just say – meh …
I am anxiously waiting for SQL Server 2019 RTM when people will suddenly see performance increases and will wonder, what the heck is going on … Or they will simply attribute it to the newer hardware / bigger VMs … Hahaha
Best regards,
Niko
Hi
I installed SQL Server 2019 Dev edition and CU8
I changed Db compatibility mode 150
I check in query execution plan only showing Row mode
Unable to change Batch mode.
I also tried change BATCH_MODE_ON_ROWSTORE scoped configuration enable\disable
Still not shwoing Batch
Wat was the issue ?
Hi Vipul,
I suggest checking out the article that explains how to detect the reasons of how QO chooses or choses not to use Batch Mode – Batch Mode – part 3 (“Basic Heuristics and Analysis”)
Best regards,
Niko