Continuation from the previous 95 parts, the whole series can be found at https://www.nikoport.com/columnstore/.
This blog post is focused on a very important feature in the modern times of the real time operations – the online operations. The first online rebuild operation for indexes in the Microsoft Data Platform world has appeared in SQL Server 2005, when the Clustered & Nonclustered Rowstore Indexes became rebuildable online – meaning that while doing this type of maintenance, your tables are still available to receive data manipulation commands, such as INSERT, DELETE, UPDATE, etc.
Since that time, with every release Microsoft has included more & more support for the online rebuild operations, with recent editions making LOB Columns online rebuild operations available (2012) and partition level online rebuilds available (2014).
For the Columnstore Indexes, the only online operation for the indexes that was available so far, was the Row Group Merging and Removal with ALTER INDEX REORGANIZE (as well as the Tuple Mover operations). With appearance of HTAP scenarios (Hybrid Transactional Analytical Processing aka Operational Analytics) in SQL Server 2016, there was a huge need for the online index maintenance, making sure that the operational part of the HTAP runs smoothly. For any online business, taking their application down for an hour means loosing real money and even worse – loosing credibility from their customers. To my knowledge, Microsoft was very much aware and was working on improving this missing part.
For the SQL Server vNext version (after SQL Server 2016) in CTP 1.2, yesterday, we have finally received the first Online Rebuild operation for the Columnstore Indexes – in this case for the Nonclustered Columnstore Indexes, and this is a huge news for anyone using the HTAP scenarios.
Naturally this feature is Enterprise Edition Only, and like ever before – if you are running a critical workload, you need to step up and use the Enterprise Edition.
The good old free database ContosoRetailDW will be used again for the exploration. Notice that as always in my blog posts, I am using the backup from the C:\Install\ folder:
Notice, that I am already using the 140 compatibility level, which already has some advantages for the execution plans in SQL Server vNext (after SQL Server 2016) as well as the Azure SQL Database:
USE master;
alter database ContosoRetailDW
set SINGLE_USER WITH ROLLBACK IMMEDIATE;
RESTORE DATABASE [ContosoRetailDW]
FROM DISK = N'C:\Install\ContosoRetailDW.bak' WITH FILE = 1,
MOVE N'ContosoRetailDW2.0' TO N'C:\Data\ContosoRetailDW.mdf',
MOVE N'ContosoRetailDW2.0_log' TO N'C:\Data\ContosoRetailDW.ldf',
NOUNLOAD, STATS = 5;
alter database ContosoRetailDW
set MULTI_USER;
GO
Use ContosoRetailDW;
GO
ALTER DATABASE [ContosoRetailDW] SET COMPATIBILITY_LEVEL = 140
GO
ALTER DATABASE [ContosoRetailDW] MODIFY FILE ( NAME = N'ContosoRetailDW2.0', SIZE = 2000000KB , FILEGROWTH = 128000KB )
GO
ALTER DATABASE [ContosoRetailDW] MODIFY FILE ( NAME = N'ContosoRetailDW2.0_log', SIZE = 400000KB , FILEGROWTH = 256000KB )
GO
Now, lets create a Nonclustered Columnstore Index on our SQL Server vNext instance, but to make this operation online, let’s include the HINT – WITH (ONLINE = ON):
CREATE NONCLUSTERED COLUMNSTORE INDEX NCCI_FactOnlineSales ON dbo.FactOnlineSales (OnlineSalesKey, DateKey, StoreKey, ProductKey, PromotionKey, CurrencyKey, CustomerKey, SalesOrderNumber, SalesOrderLineNumber, SalesQuantity, SalesAmount, ReturnQuantity, ReturnAmount, DiscountQuantity, DiscountAmount, TotalCost, UnitCost, UnitPrice, ETLLoadID, LoadDate, UpdateDate) WITH (ONLINE = ON);
This statement executes well, without giving any error message or warning. For example, if you try to do the same against SQL Server 2016 with Service Pack 1, you will receive the following error message:
Msg 35318, Level 15, State 1, Line 3 The statement failed because the ONLINE option is not allowed when creating a columnstore index. Create the columnstore index without specifying the ONLINE option.
Now, the statement has executed successfully, and apparently now we can create Nonclustered Columnstore Indexes online, without affecting the regular workload of our server, but let’s step into this operation and put the operation to the test by running some parallel workload and see what more can we discover of it.
For the first test, let’s re-create the Nonclustered Columnstore Index, with the online operation, while selecting the data out of it:
CREATE NONCLUSTERED COLUMNSTORE INDEX NCCI_FactOnlineSales ON dbo.FactOnlineSales (OnlineSalesKey, DateKey, StoreKey, ProductKey, PromotionKey, CurrencyKey, CustomerKey, SalesOrderNumber, SalesOrderLineNumber, SalesQuantity, SalesAmount, ReturnQuantity, ReturnAmount, DiscountQuantity, DiscountAmount, TotalCost, UnitCost, UnitPrice, ETLLoadID, LoadDate, UpdateDate) WITH (ONLINE = ON, DROP_EXISTING = ON);
It takes around 53 seconds to execute this statement on the SQL Server vNext CTP 1.2, and while this statement is executing on my Azure VM, I will execute the following statement, calculating the total online sales, with clearing the non-modified information from the memory:
dbcc dropcleanbuffers select sum(SalesAmount) from dbo.FactOnlineSales;
While rebuilding is being executed, this query still manages to take advantage of the Nonclustered Columnstore Index, as you can see shown on the actual execution plan below:

Running the same workload (but without ONLINE hint, since it is not supported) on the SQL Server 2016 with Service Pack 1, produces blocking which will prevent the query coming to completion, until the Columnstore Index build is finished.
To see it in more details the locking, you can use the following query, showing what is being currently locked:
-- What's being locked
SELECT dm_tran_locks.request_session_id,
dm_tran_locks.resource_database_id,
DB_NAME(dm_tran_locks.resource_database_id) AS dbname,
CASE
WHEN resource_type = 'object'
THEN OBJECT_NAME(dm_tran_locks.resource_associated_entity_id)
ELSE OBJECT_NAME(partitions.OBJECT_ID)
END AS ObjectName,
partitions.index_id,
indexes.name AS index_name,
dm_tran_locks.resource_type,
dm_tran_locks.resource_description,
dm_tran_locks.resource_associated_entity_id,
dm_tran_locks.request_mode,
dm_tran_locks.request_status
FROM sys.dm_tran_locks
LEFT JOIN sys.partitions ON partitions.hobt_id = dm_tran_locks.resource_associated_entity_id
JOIN sys.indexes ON indexes.OBJECT_ID = partitions.OBJECT_ID AND indexes.index_id = partitions.index_id
WHERE resource_associated_entity_id > 0
AND resource_database_id = DB_ID()
ORDER BY request_session_id, resource_associated_entity_id;

From the picture above, you can see the Pages of the Nonclustered Columnstore Index being locked with the exclusive lock (X), while holding the Schema Modification (Sch-M) & Intent Exclusive (IX) locks as well. In such conditions, on SQL Server 2016 there are no conditions for getting anything out of the Nonclustered Columnstore Indexes.
In the most situations, we do not re-create our indexes, but we rebuild them. For testing this functionality, let us rebuild our Nonclustered Columnstore Index and test if we can still do the reading of the data:
ALTER INDEX NCCI_FactOnlineSales ON dbo.FactOnlineSales REBUILD WITH (ONLINE = ON);
Running in parallel the reading test workload, on SQL Server vNext we can obtain our results very fast with the help of the Nonclustered Columnstore Index and without any blocking:
dbcc dropcleanbuffers select sum(SalesAmount) from dbo.FactOnlineSales;
On SQL Server 2016 with Service Pack 1 you will get the similar type of locking that was shown
the query will have to wait until the end of the rebuild operation before delivering the result.
Additionally, of course on SQL Server 2016 there is no possibility of doing an ONLINE rebuild of the Columnstore Index, and for the test you will need to execute the script without ONLINE hint:
Msg 35328, Level 16, State 1, Line 7 ALTER INDEX REBUILD statement failed because the ONLINE option is not allowed when rebuilding a columnstore index. Rebuild the columnstore index without specifying the ONLINE option.
Those tests were quite interesting and have shown the compatibility with read access to the Nonclusetered Columnstore Index while it is being rebuild, but what about data modification operations, such as INSERT, DELETE & UPDATE operations ?
Let’s kick off with the UPDATE statement, but before advancing, please install the latest CISL version(Columnstore Indexes Script Library), which I will be using for getting the insights on what is going on with the internals of the Columnstore Index.
I decided to show the UPDATE statement functionality, because as you should know for the Columnstore Indexes, it represents the INSERT & DELETE statements by itself.
Before doing any modification or rebuilding the Nonclustered Columnstore Index, let us take a look at the Row Groups of our table:
exec dbo.cstore_GetRowGroupsDetails @tableName = 'FactOnlineSales';
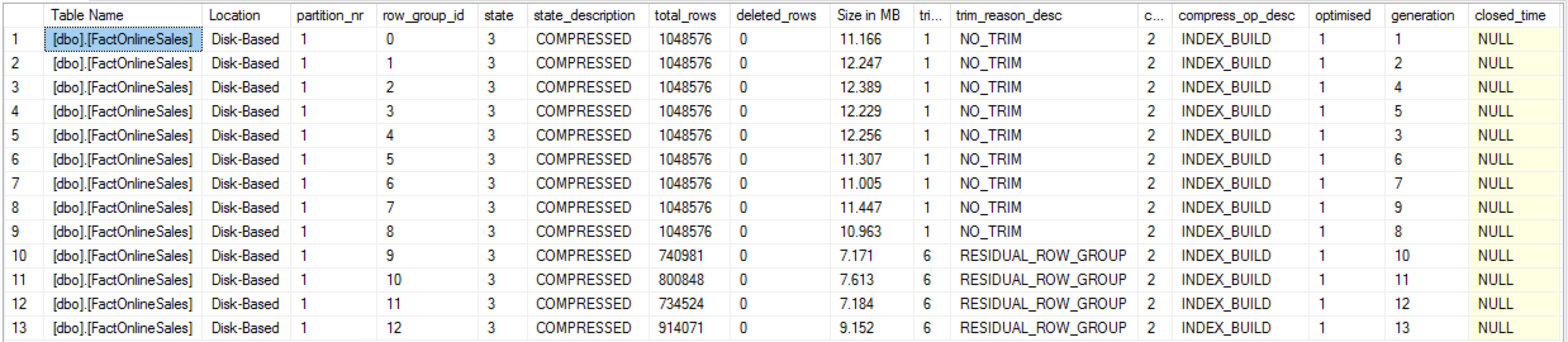
There are 13 Row Groups with engine distributing the data very well between different Row Groups, leaving the final 4 with a similar number of rows, balancing them between the number of the used CPU cores, as it was already happening in SQL Server 2016.
Let’s update 1 row while doing ONLINE rebuild of our Nonclustered Columnstore Index:
UPDATE TOP (1) dbo.FactOnlineSales SET ETLLoadID = cast(GETDATE() as int) WHERE OnlineSalesKey = 29928943;
The very first thing you will notice (besides that the update was very swiftly succesfull), is that not just 1 row was updated – the messages that will be shown will display that 2 separate rows were updated:
(1 row(s) affected) (1 row(s) affected)
The message is correct, because we have updated 2 rows, but one of them was temporary – was used for the storing the updated information. Let us see the details… :)
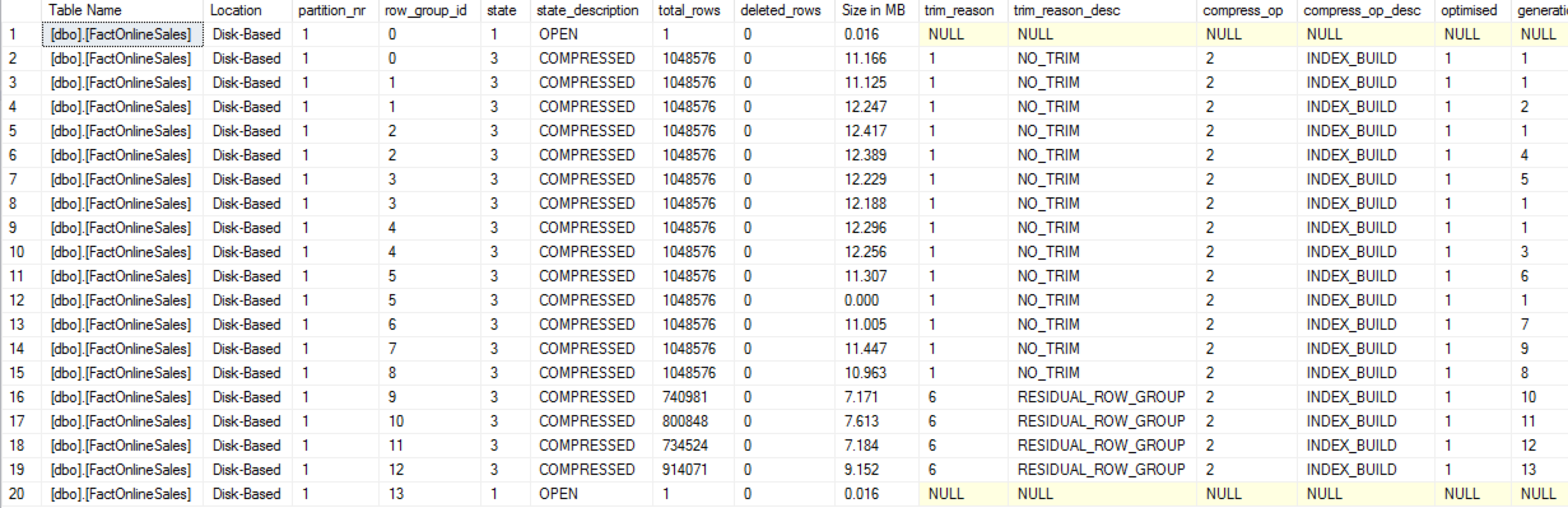
While the rebuild process was being executed, I was also running the cstore_GetRowGroupsDetails function from the CISL, in order to monitor the development and changes of the row groups for our table:
exec dbo.cstore_GetRowGroupsDetails @tableName = 'FactOnlineSales';

On the image above you can see, that besides the original 13 Row Groups, we now have 2 new Delta-Stores and 1 compressed Row Group. The new Delta-Store with the row_group_id equals to 13, contains the original updated data for the original structure of the Nonclustered Columnstore Index. It is being automatically synchronised with the new Delta-Store that belongs to the newly built NCCI – this second Delta-Store has a row_group_id of 0, the only difference here is the internal timestamp of the row group generation that is to be found in the within the sys.dm_db_column_store_row_group_physical_stats DMV, and you can see it on if you scroll the cstore_GetRowGroups results to the right.
Any new data that will be updated or inserted here will land in both Delta-Stores, first with the row_group_id equals to 13, belonging to the original NCCI structure, and then it will be synced into the new one, with the row_group_id equals to 0 – becoming the part of the newly rebuilt NCCI.
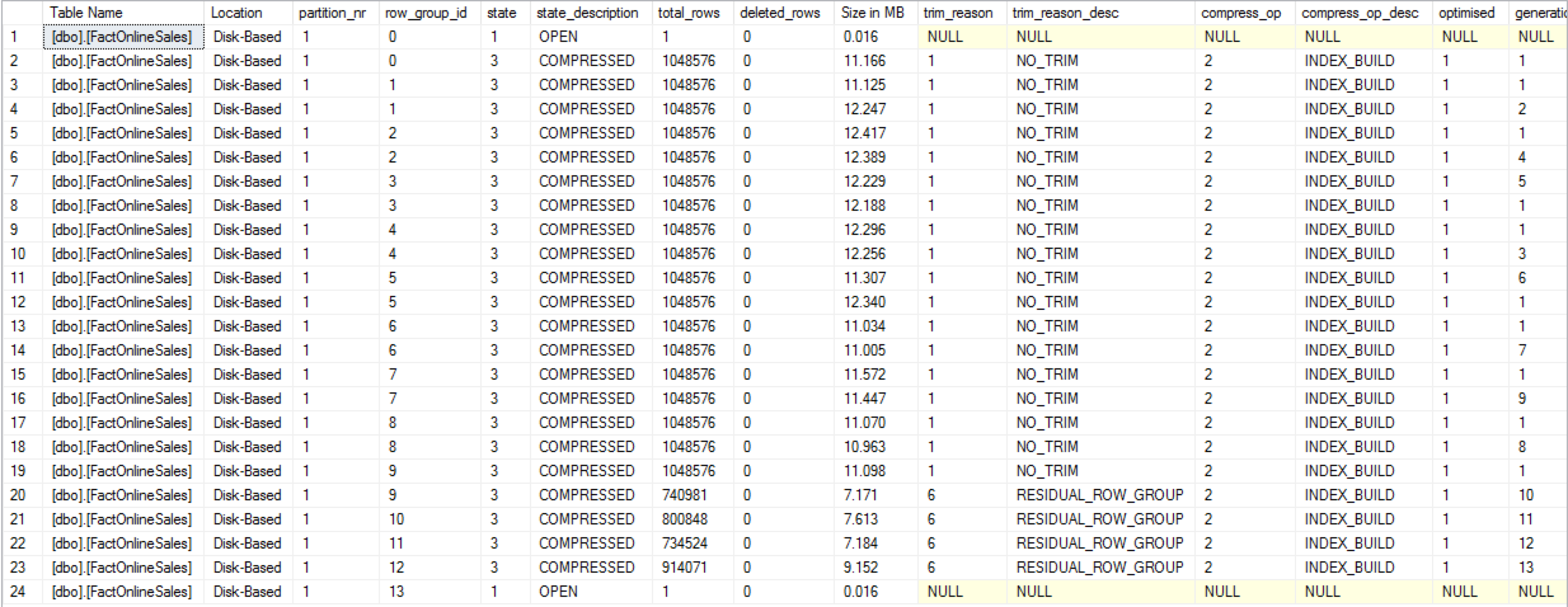
On the image above you can see a number of the Row Groups which are marked with the generation number equals to 1, and that are the newly rebuilt Row Groups of the new NCCI.
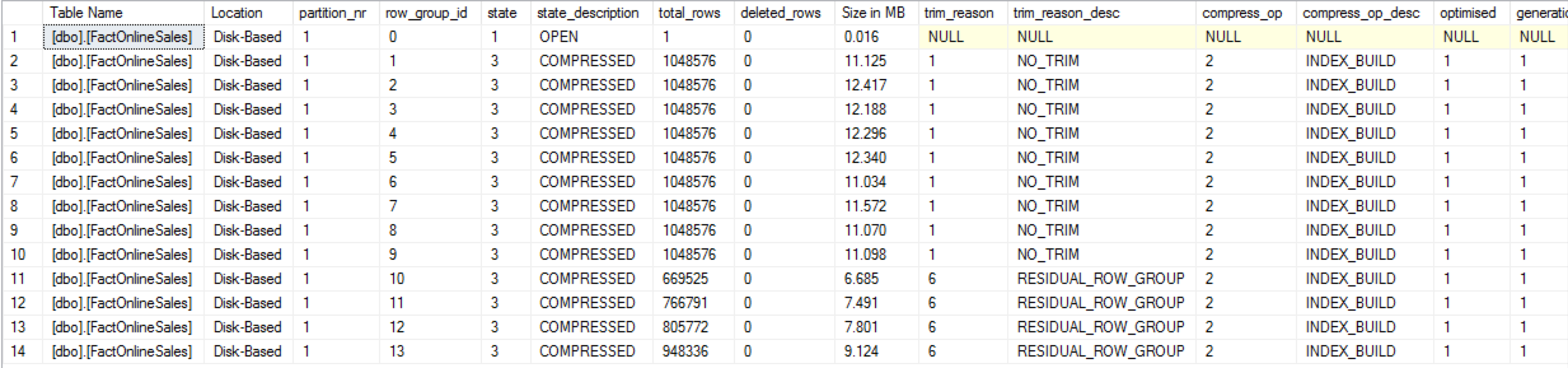
The progress continued until on the next screenshot we shall have the final version of the online rebuilt Nonclustered Columnstore Index, where all of the generation numbers equals to 1, and all of the original Row Groups are gone:
Notice that the Deleted Buffer has received an insert with the information on the key of the row that was updated:
SELECT object_id('FactOnlineSales') as TableName, *
FROM sys.internal_partitions
WHERE object_id = object_id('FactOnlineSales')
AND internal_object_type in (2,4);
![]()
Thus one of the rows within the compressed Row Groups has become obsolete and this information is contained within the Deleted Buffer.
Offline vs Online Rebuild Transaction Log Impact
As we have seen above, the database impact on the ONLINE rebuild operation of the Nonclustered Columnstore Indexes is quite big – the size of the occupied space doubles, since the original and the newly created Columnstore Structures at the end of operation have to co-exist at the same time.
What about the transaction log – how different/big it gets for the Online Rebuild of the Nonclustered Columnstore Indexes, when compared to the traditional offline rebuild process ?
First, let us measure the SIMPLE recovery model impact:
For measuring the impact, I have executed 5 times the following script, in order to obtain the average numbers of the execution times for the Online Index Rebuild and to measure the transaction log impact:
CHECKPOINT ALTER INDEX NCCI_FactOnlineSales ON dbo.FactOnlineSales REBUILD WITH (ONLINE = ON); SELECT CAST(SUM([log record length]) / 1024. / 1024 as Decimal(9,2)) as LogSizeInMB FROM sys.fn_dblog (NULL, NULL);
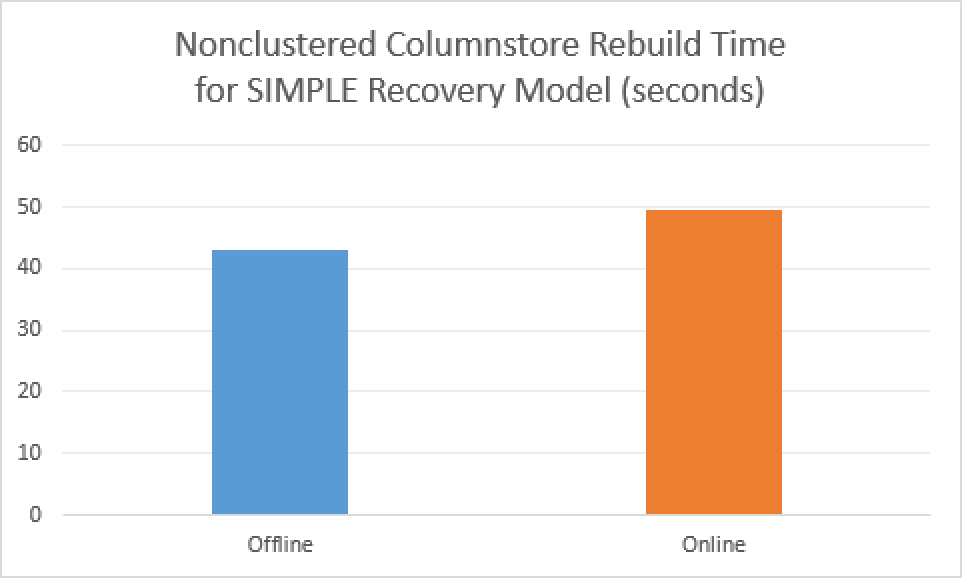
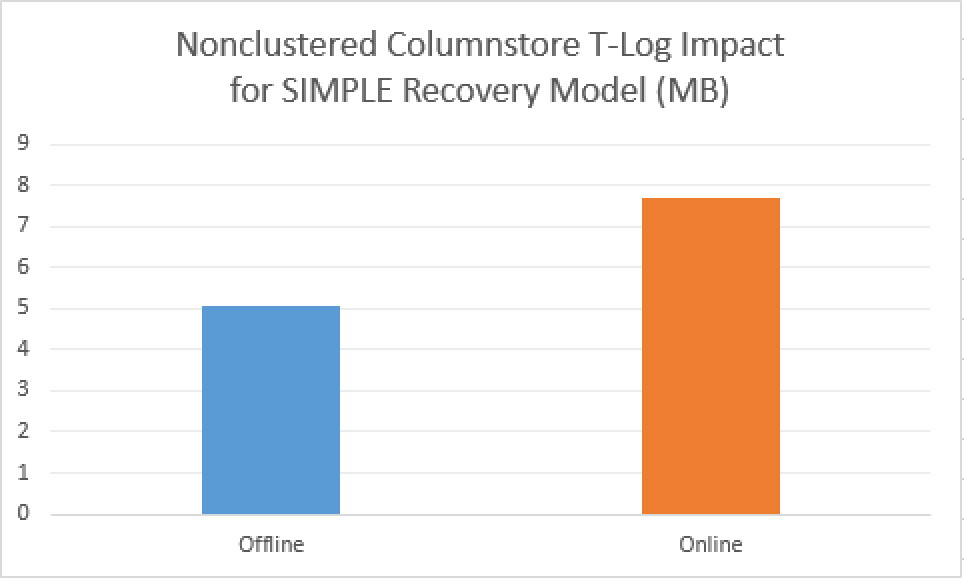
On average, 49.5 seconds was the execution time for the process, with the transaction log impact being around 7.71 MB.
Comparing to the offline rebuild process for the Nonclustered Columnstore Index, we are talking about 43 seconds and 5.08 MB impact on the transaction log. On the pictures that accompany this paragraph you can clearly see the differences that these operations bring while doing essentially the same data movements, but providing different type of the availability.
As the next step, let’s see what changes when we switch our recovery model from SIMPLE to FULL and I am quite sure that everyone reading this blog is using FULL recovery model for their operational databases… :)
USE [master] GO ALTER DATABASE [ContosoRetailDW] SET RECOVERY FULL WITH NO_WAIT GO USE [ContosoRetailDW] GO EXEC dbo.sp_changedbowner @loginame = N'sa', @map = false GO
We need to execute the Backup, in order to start the log chain – I will backup our database to the C:\Install\ContosoRetailDW-new.bak:
BACKUP DATABASE [ContosoRetailDW] TO DISK = N'C:\Install\ContosoRetailDW-new.bak' WITH NOFORMAT, INIT, NAME = N'ContosoRetailDW-Full Database Backup', SKIP, NOREWIND, NOUNLOAD, COMPRESSION, STATS = 1, CHECKSUM;
Our next step after the setup is running the test multiple times for the Online and the Offline Nonclustered Columnstore Indexes with the help of the following statement (change it to offline when testing it by yourself):
ALTER INDEX NCCI_FactOnlineSales ON dbo.FactOnlineSales REBUILD WITH (ONLINE = ON);
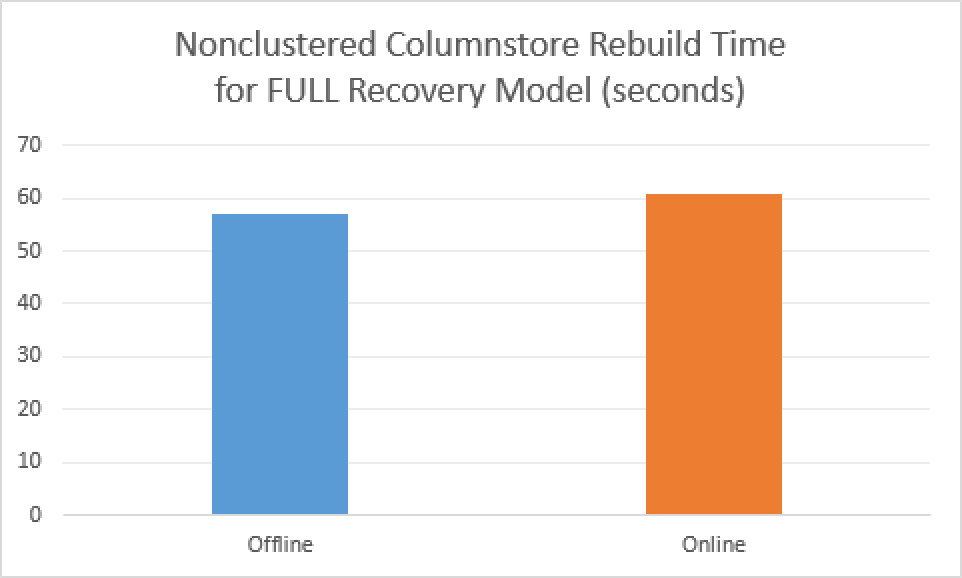
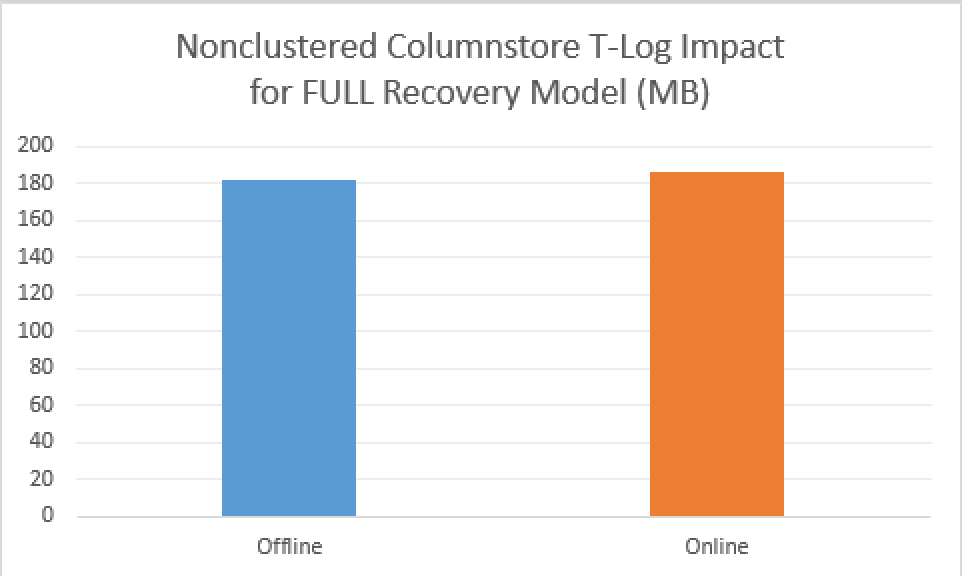 With a FULL Recovery Model, on average, it took around 61 seconds to complete while taking 185.71 MB of transaction log space for the Online Rebuild operation. For the offline rebuild operation, the average execution time was on the average around 57 seconds with the transaction log impact rounding on the 181.83MB. The difference between online and offline operations in this sense was absolutely minimal and definitely insignificant – not even 5% difference. I guess that this has to do with a number of optimisations that were implemented by the developers.
With a FULL Recovery Model, on average, it took around 61 seconds to complete while taking 185.71 MB of transaction log space for the Online Rebuild operation. For the offline rebuild operation, the average execution time was on the average around 57 seconds with the transaction log impact rounding on the 181.83MB. The difference between online and offline operations in this sense was absolutely minimal and definitely insignificant – not even 5% difference. I guess that this has to do with a number of optimisations that were implemented by the developers.
Ultimately the change from running in a SIMPLE recovery model to FULL recovery model is huge, we are talking here about change from ~8 MB of transaction log to over 180MB making it over 22 times bigger, and this is relatively small table.
I have also executed some tests to see if the transaction log changes significantly with the updates running against the rebuilt table, and to my experience there were just additional data in the Delta-Stores marked in the Transaction log, meaning nothing special after all. Of course, in the real world of operational database, your table might suffer huge changes, but they will be simply doubled (copying from the original Delta-Store in the newly built one), which is rather an acceptable change for having your workload being available 100% of the time.
Clustered Columnstore Indexes ?
HTAP (Operational Analytics) scenarios are very important, but let us not forget the roots of the Columnstore Indexes – the Data Warehousing, Data Marts, Business Intelligence & Reporting scenarios. Let us see if the announced change of allowing the ONLINE rebuilds is really limiting to the Nonclustered Columnstore Indexes.
For that, I will restore the database from the original backup:
USE master;
alter database ContosoRetailDW
set SINGLE_USER WITH ROLLBACK IMMEDIATE;
RESTORE DATABASE [ContosoRetailDW]
FROM DISK = N'C:\Install\ContosoRetailDW.bak' WITH FILE = 1,
MOVE N'ContosoRetailDW2.0' TO N'C:\Data\ContosoRetailDW.mdf',
MOVE N'ContosoRetailDW2.0_log' TO N'C:\Data\ContosoRetailDW.ldf',
NOUNLOAD, STATS = 5;
alter database ContosoRetailDW
set MULTI_USER;
GO
Use ContosoRetailDW;
GO
ALTER DATABASE [ContosoRetailDW] SET COMPATIBILITY_LEVEL = 140
GO
ALTER DATABASE [ContosoRetailDW] MODIFY FILE ( NAME = N'ContosoRetailDW2.0', SIZE = 2000000KB , FILEGROWTH = 128000KB )
GO
ALTER DATABASE [ContosoRetailDW] MODIFY FILE ( NAME = N'ContosoRetailDW2.0_log', SIZE = 400000KB , FILEGROWTH = 256000KB )
GO
and after successful restore process, let us drop the Primary Key which is also serving as a Clustered Index, and create a new Clustered Columnstore Index as an ONLINE operation:
ALTER TABLE dbo.[FactOnlineSales] DROP CONSTRAINT [PK_FactOnlineSales_SalesKey]; create clustered columnstore Index PK_FactOnlineSales on dbo.FactOnlineSales WITH (ONLINE = ON);
The error message is quite clear and it is the same one, as in SQL Server 2016 or even SQL Server 2014 – the online rebuild for the Clustered Columnstore Indexes is not allowed:
Msg 35318, Level 16, State 2, Line 1 The statement failed because the ONLINE option is not allowed when creating a columnstore index. Create the columnstore index without specifying the ONLINE option.
I know that Microsoft is well aware of the need to allow ONLINE operations on the Clustered Columnstore Indexes, and while the first Columnstore Index to receive this type of enterprise support were the HTAP scenario supporting Nonclsutered Columnstore Indexes, but I have no doubt that very soon we shall see the support for the Clustered Columnstore Indexes as well.
The Clustered Columnstore Indexes are more complex to handle for the ONLINE operations, because their internal structure involves more complex objects, such as Mapping Index – serving for the connection between the CCI and the secondary indexes, and since it is the real table structure and not a secondary index (like in the case with the Nonclustered Columnstore Index), an additional care must be taken, in order to keep this process function all the time correctly.
Memory-Optimised Columnstore Indexes ?
Another HTAP type of the scenario, and for me personally, the scenario of the future is when we are using Clustered Columnstore Index on the Memory-Optimised Tables.
Even though they were not part of the announcement for the CTP 1.2 of the SQL Server vNext (after SQL Server 2016), I really expect this feature to be a part of the engine and if not in vNext, then right after.
For trying out, we need to add the memory-optimised FileGroup, as always:
USE master; ALTER DATABASE [ContosoRetailDW] ADD FILEGROUP [ContosoRetailDW_Hekaton] CONTAINS MEMORY_OPTIMIZED_DATA GO ALTER DATABASE [ContosoRetailDW] ADD FILE(NAME = ContosoRetailDW_HekatonDir, FILENAME = 'C:\Data\Contosoxtp') TO FILEGROUP [ContosoRetailDW_Hekaton]; GO
Let us create a Memory-Optimised Table that will be a copy of the FactOnlineSales table:
use ContosoRetailDW; drop table IF EXISTS [dbo].[FactOnlineSales_Hekaton]; CREATE TABLE [dbo].[FactOnlineSales_Hekaton]( [OnlineSalesKey] [int] NOT NULL, [DateKey] [datetime] NOT NULL, [StoreKey] [int] NOT NULL, [ProductKey] [int] NOT NULL, [PromotionKey] [int] NOT NULL, [CurrencyKey] [int] NOT NULL, [CustomerKey] [int] NOT NULL, [SalesOrderNumber] [nvarchar](20) NOT NULL, [SalesOrderLineNumber] [int] NULL, [SalesQuantity] [int] NOT NULL, [SalesAmount] [money] NOT NULL, [ReturnQuantity] [int] NOT NULL, [ReturnAmount] [money] NULL, [DiscountQuantity] [int] NULL, [DiscountAmount] [money] NULL, [TotalCost] [money] NOT NULL, [UnitCost] [money] NULL, [UnitPrice] [money] NULL, [ETLLoadID] [int] NULL, [LoadDate] [datetime] NULL, [UpdateDate] [datetime] NULL, Constraint PK_FactOnlineSales_Hekaton PRIMARY KEY NONCLUSTERED ([OnlineSalesKey]) ) WITH (MEMORY_OPTIMIZED = ON, DURABILITY = SCHEMA_AND_DATA);
Now let us add a Clustered Columnstore Index, with the help of the ONLINE hint (notice the different syntax that is necessary for the Index addition to the memory-optimised tables:
ALTER TABLE dbo.FactOnlineSales_Hekaton ADD INDEX NCCI_FactOnlineSales_Hekaton CLUSTERED COLUMNSTORE WITH (ONLINE = ON);
The message to be received is very clear and leaves no doubt:
Msg 10794, Level 16, State 91, Line 49 The index option 'online' is not supported with indexes on memory optimized tables.
The Columnstore Indexes on the memory-optimised tables right now do not support ONLINE operations right now, but make no mistake – this is the scenario of the future and Microsoft should invest their resources in the nearest future to make this scenario work equally or even much better than the disk-based one with the Nonclustered Columnstore Indexes.
Final Thoughts
The new possibility of doing rebuilds and creating the Nonclustered Columnstore Indexes is really fantastic, bringing the HTAP scenarios to the online and 24×7 shops attention. I love the speed with which the changes are done. They give a hope that the adoption of the ONLINE rebuild will quite wide between Enterprise Edition users.
The missing support for the online operations for the disk-based Clustered Columnstore Indexes as well as the lack of the online operations for the memory-optimised tables with Columnstore indexes is sad, but with the speed of the rebuild process on the memory-optimised tables (Columnstore Indexes – part 90 (“In-Memory Columnstore Improvements in Service Pack 1 of SQL Server 2016 “)) this might be a little bit less painful as one thinks.
SQL Server vNext is showing signs of bringing truly enterprise features (Columnstore Indexes – part 93 (“Batch Mode Adaptive Memory Grant Feedback”), for example) to the Columnstore Indexes and that leaves me very excited about the SQL Serve vNext release.
to be continued …
Please when there’s already reorganize doing the same thing with online, why we do need rebuild Online.
Thank you
Hi Manish,
ALTER INDEX REORGANIZE will not do the same thing as the ALTER INDEX REBUILD.
Alter Index Reorganize will kick off IF the Row Groups are logically fragmented under the specified thresholds, suffering no pressures (see http://www.nikoport.com/2017/09/24/columnstore-indexes-part-113-row-groups-merging-limitations/ for SQL 2016) and within current max capability of the Row Groups.
It does not matter which version of SQL Server or Azure SQL DB you are running.
Besides, ALTER INDEX REORGANIZE can grab a Memory Grant of default 25% that you are not expecting on a Multi-TB VM … Think about 500GB or RAM spent on this operation and the Resource Semaphore implications when you are running a 2 TB RAM Data Warehouse …
Take a look at this video, where I show some of the examples – https://www.youtube.com/watch?v=aBQ985N3SPI&t=206s
Best regards,
Niko