Continuation from the previous 88 parts, the whole series can be found at https://www.nikoport.com/columnstore/.
I would like to dedicate this blog post to the Memory-Optimised (also known and LOVED as Hekaton) Columnstore Indexes and their limitations in SQL Server 2016.
Disclaimer: the Memory-Optimised Technology is the ground-breaking development, which will be truly appreciated only in the next couple of years, and it has its incredible use cases (and maybe I will be blogging more about this space in the next couple of months), but people needs to understand that mapping InMemory Columnstore Indexes to disk-based Columnstore Indexes 1:1 is a very wrong idea, and that because InMemory technology is significantly younger and less stable than Columnstore Indexes – there are some very significant hidden cornerstones.
I have already blogged twice on the internals (Columnstore Indexes – part 72 (“InMemory Operational Analytics”)) and on the Columnstore Index addition (Columnstore Indexes – part 81 (“Adding Columnstore Index to InMemory Tables”)), but overall I feel that this topic is still very much unexplored, and being new it is a kind of normal – since most people do not want to risk to dive into unknown space.
Construction Limitations
If you have tried or worked with Memory-Optimised tables in SQL Server 2014, you will surely know that once you have created such table, you would not be able to alter it in any way. The same principle applies to the Memory-Opimitsed Stored Procedures in SQL Server 2014, where in order to change one, you have to drop and re-create it again.
In SQL Server 2016 this limitations (and many others) were removed and we can change our Memory-Optimised tables, changing their meta-data such as adding more columns or removing them, adding or removing indexes or changing hash indexes bucket count.
We can also add the Memory-Optimised Clustered Columnstore Indexes to our hekaton tables (within table definition or post-table creation) and everything should be fine and work perfectly.
:)
Let’s take it for a ride, by restoring a copy of my favourite free ContosoRetailDW database, adding memory-optimised file group:
USE master;
alter database ContosoRetailDW
set SINGLE_USER WITH ROLLBACK IMMEDIATE;
RESTORE DATABASE [ContosoRetailDW]
FROM DISK = N'C:\Install\ContosoRetailDW.bak' WITH FILE = 1,
MOVE N'ContosoRetailDW2.0' TO N'C:\Data\ContosoRetailDW.mdf',
MOVE N'ContosoRetailDW2.0_log' TO N'C:\Data\ContosoRetailDW.ldf',
NOUNLOAD, STATS = 5;
alter database ContosoRetailDW
set MULTI_USER;
GO
Use ContosoRetailDW;
GO
ALTER DATABASE [ContosoRetailDW] SET COMPATIBILITY_LEVEL = 130
GO
ALTER DATABASE [ContosoRetailDW] MODIFY FILE ( NAME = N'ContosoRetailDW2.0', SIZE = 2000000KB , FILEGROWTH = 128000KB )
GO
ALTER DATABASE [ContosoRetailDW] MODIFY FILE ( NAME = N'ContosoRetailDW2.0_log', SIZE = 400000KB , FILEGROWTH = 256000KB )
GO
USE master;
ALTER DATABASE [ContosoRetailDW]
ADD FILEGROUP [ContosoRetailDW_Hekaton]
CONTAINS MEMORY_OPTIMIZED_DATA
GO
ALTER DATABASE [ContosoRetailDW]
ADD FILE(NAME = ContosoRetailDW_HekatonDir,
FILENAME = 'C:\Data\Contosoxtp')
TO FILEGROUP [ContosoRetailDW_Hekaton];
GO
Let’s create our test Memory-Optimised table:
DROP TABLE IF EXISTS [dbo].[FactOnlineSales_Hekaton]; CREATE TABLE [dbo].[FactOnlineSales_Hekaton]( [OnlineSalesKey] [int] NOT NULL, [DateKey] [datetime] NOT NULL, [StoreKey] [int] NOT NULL, [ProductKey] [int] NOT NULL, [PromotionKey] [int] NOT NULL, [CurrencyKey] [int] NOT NULL, [CustomerKey] [int] NOT NULL, [SalesOrderNumber] [nvarchar](20) NOT NULL, [SalesOrderLineNumber] [int] NULL, [SalesQuantity] [int] NOT NULL, [SalesAmount] [money] NOT NULL, [ReturnQuantity] [int] NOT NULL, [ReturnAmount] [money] NULL, [DiscountQuantity] [int] NULL, [DiscountAmount] [money] NULL, [TotalCost] [money] NOT NULL, [UnitCost] [money] NULL, [UnitPrice] [money] NULL, [ETLLoadID] [int] NULL, [LoadDate] [datetime] NULL, [UpdateDate] [datetime] NULL, Constraint PK_FactOnlineSales_Hekaton PRIMARY KEY NONCLUSTERED ([OnlineSalesKey]) ) WITH (MEMORY_OPTIMIZED = ON, DURABILITY = SCHEMA_AND_DATA);
Let’s load 2 million rows
-- Load 2 Million Rows insert into dbo.FactOnlineSales_Hekaton select top 2000000 * from dbo.FactOnlineSales;
We can change the meta-data structure by adding another column
alter table [dbo].[FactOnlineSales_Hekaton] add c1 int;
Let’s test if we can drop it, just to make sure we can do that:
alter table [dbo].[FactOnlineSales_Hekaton] drop column c1;
Now, its time to add a Clustered Columnstore Index
-- Add a Columnstore Index alter table dbo.FactOnlineSales_Hekaton add INDEX NCCI_FactOnlineSales_Hekaton CLUSTERED COLUMNSTORE;
Works fine as expected! Lovely stuff!
Now, let’s add a Hash Index, that we see that is necessary for our OLTP queries:
alter table dbo.FactOnlineSales_Hekaton add INDEX NCIX_1_FactOnlineSales_Hekaton NONCLUSTERED HASH (OnlineSalesKey, DateKey, StoreKey, ProductKey, PromotionKey, CurrencyKey, CustomerKey, SalesOrderNumber, SalesOrderLineNumber, SalesQuantity, SalesAmount, ReturnQuantity, ReturnAmount, DiscountQuantity, DiscountAmount, TotalCost, UnitCost, UnitPrice, ETLLoadID, LoadDate, UpdateDate) WITH (BUCKET_COUNT = 2000000);
Msg 10794, Level 16, State 15, Line 1
The operation ‘ALTER TABLE’ is not supported with memory optimized tables that have a column store index.
Wait a second! What’s going on ? WHY ?
Can we do any other things, like adding or removing a column:
alter table [dbo].[FactOnlineSales_Hekaton] add c1 int; GO -- Let's try to drop an existing column (should give an error that Clustered Index requires it) alter table [dbo].[FactOnlineSales_Hekaton] drop column ReturnAmount;
Msg 12349, Level 16, State 1, Line 1
Operation not supported for memory optimized tables having columnstore index.
Msg 12349, Level 16, State 1, Line 5
Operation not supported for memory optimized tables having columnstore index.
Bang!
That looks like SQL Server 2014 Memory-Optimised Tables, we can’t change anything after we add a columnstore index (and addition takes a lot of time, just check Columnstore Indexes – part 81 (“Adding Columnstore Index to InMemory Tables”)
That is a very serious bummer and you should be extra-careful when stepping into this kind of adventure, if you expect your schema to change regularly – because every index addition and removal operation for Columnstore Indexes is offline only!
Let’s drop the index and try to add it with a Columnstore Archival compression (also notice that there is no partition support for the Memory-Optimised tables and you can’t ):
-- Drop the existing columnstore index alter table dbo.FactOnlineSales_Hekaton drop INDEX NCCI_FactOnlineSales_Hekaton; -- Add a columnstore index with Archival compression alter table dbo.FactOnlineSales_Hekaton add INDEX NCCI_FactOnlineSales_Hekaton CLUSTERED COLUMNSTORE WITH (DATA_COMPRESSION = COLUMNSTORE_ARCHIVE);
Msg 10794, Level 16, State 91, Line 2
The index option ‘data_compression’ is not supported with indexes on memory optimized tables.
Yeah, no Archival compression.
Important to think that it’s improvement is not that relevant, since the vast majority of the memory space will be occupied by the memory-optimised table itself (we are talking about some 5% of the overall memory space), but I believe it is important for everyone to know what to expect when migrating to InMemory Columnstore.
In-Memory? :)
:)
As you know, the Memory-Optimised Tables have all their Indexes only in Memory, that’s the reason why they are so fast and so great.
Let’s take it to the test. :)
Let’s re-create our Memory-Optimised Table and observe what happens with the disk space when we add a columnstore index and compare it to the regular hash in-memory index:
DROP TABLE IF EXISTS [dbo].[FactOnlineSales_Hekaton]; CREATE TABLE [dbo].[FactOnlineSales_Hekaton]( [OnlineSalesKey] [int] NOT NULL, [DateKey] [datetime] NOT NULL, [StoreKey] [int] NOT NULL, [ProductKey] [int] NOT NULL, [PromotionKey] [int] NOT NULL, [CurrencyKey] [int] NOT NULL, [CustomerKey] [int] NOT NULL, [SalesOrderNumber] [nvarchar](20) NOT NULL, [SalesOrderLineNumber] [int] NULL, [SalesQuantity] [int] NOT NULL, [SalesAmount] [money] NOT NULL, [ReturnQuantity] [int] NOT NULL, [ReturnAmount] [money] NULL, [DiscountQuantity] [int] NULL, [DiscountAmount] [money] NULL, [TotalCost] [money] NOT NULL, [UnitCost] [money] NULL, [UnitPrice] [money] NULL, [ETLLoadID] [int] NULL, [LoadDate] [datetime] NULL, [UpdateDate] [datetime] NULL, Constraint PK_FactOnlineSales_Hekaton PRIMARY KEY NONCLUSTERED ([OnlineSalesKey]) ) WITH (MEMORY_OPTIMIZED = ON, DURABILITY = SCHEMA_AND_DATA); -- Load data into it: 2 Million Rows insert into dbo.FactOnlineSales_Hekaton select top 2000000 * from dbo.FactOnlineSales; -- CHECKPOINT Checkpoint
Using the upcoming version of the MOSL, let’s take a look at the checkpoint files and their sizes while also observing the C:\Data\Contosoxtp\$HKv2 folder, which we have configured for storing the data:
Here are the results that I can see with my WorkInProgress version for SQL Server 2016:
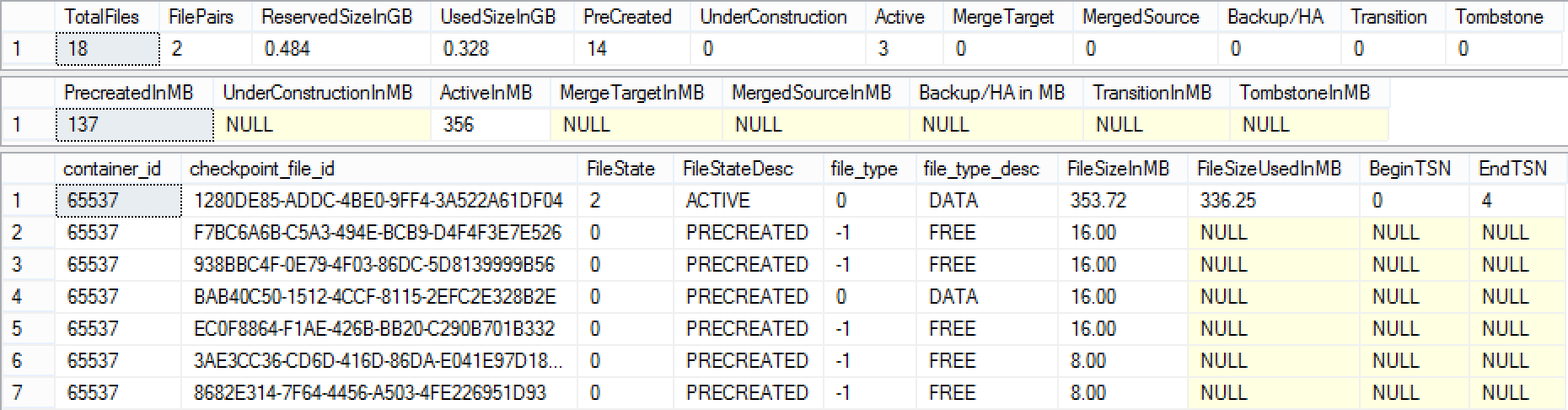
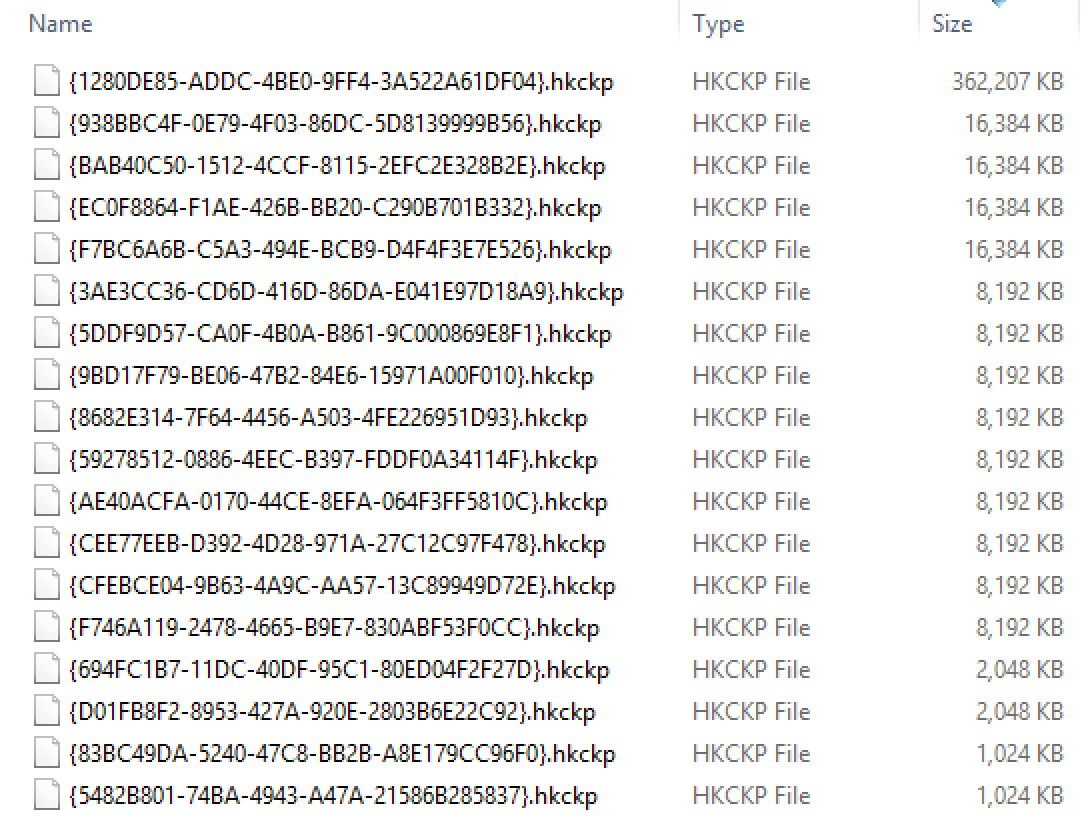
The FileSystem looks the following way:
Let’s add the Clustered Columnstore Index and issue a checkpoint:
-- Add a Columnstore Index alter table dbo.FactOnlineSales_Hekaton add INDEX NCCI_FactOnlineSales_Hekaton CLUSTERED COLUMNSTORE; -- CHECKPOINT Checkpoint
After good 9 seconds :) on my VM, I have the following results Checkpoint File Pairs and for the file system:
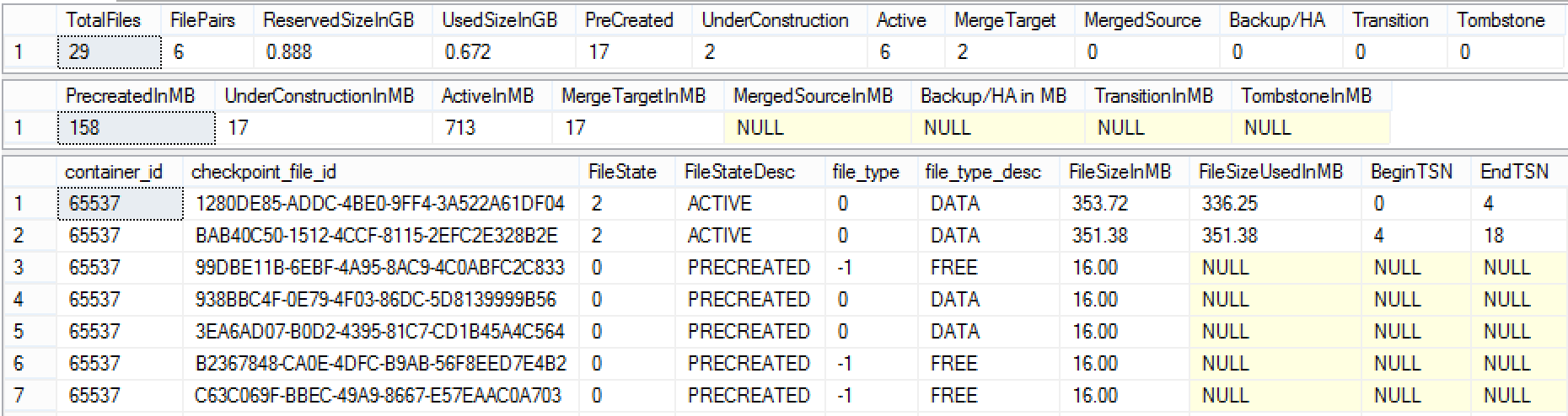
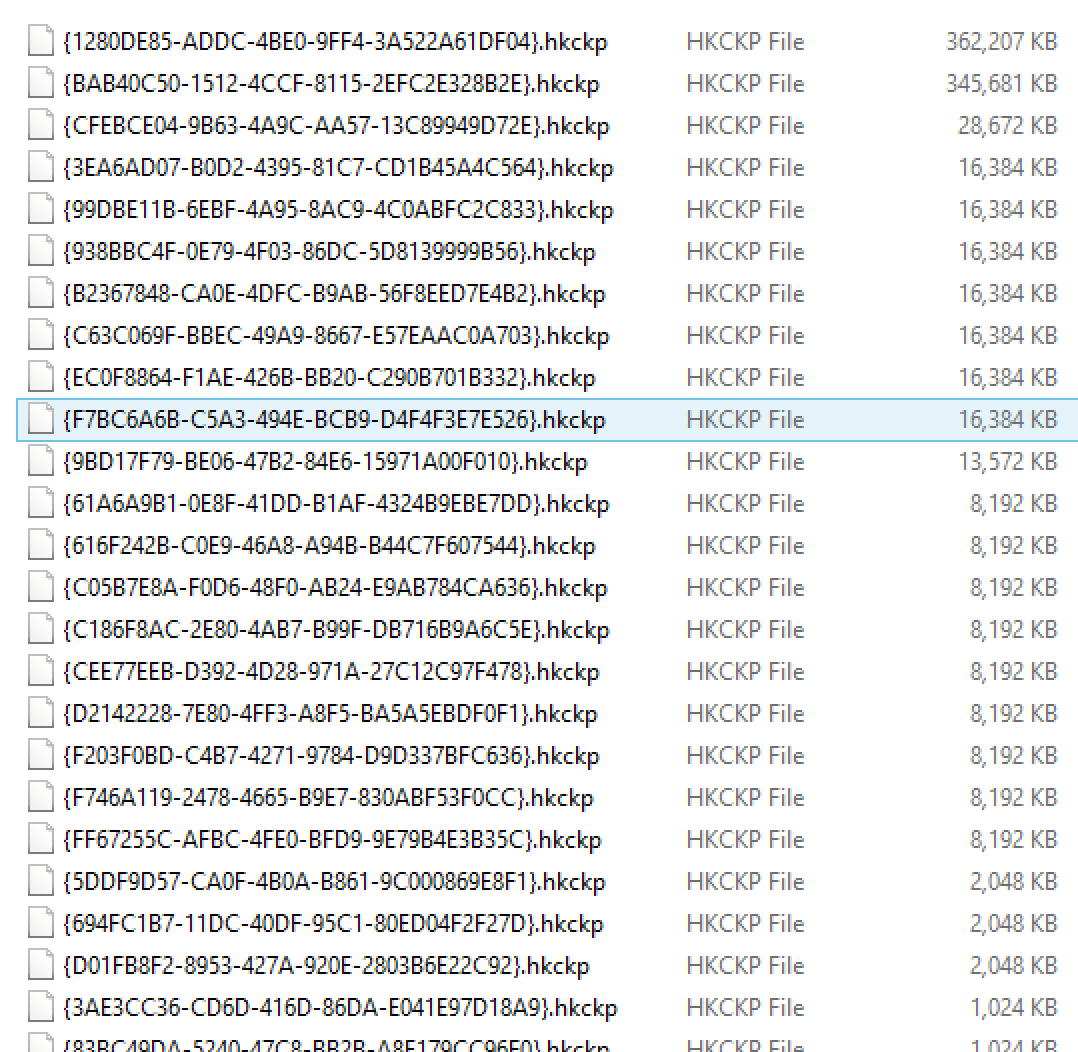 What happened on the file system is that the occupied space has been simply doubled – it has went from 0.328 GB to 0.672 GB ! So what the effectiveness of the Columnstore compression? Why do we have any File System imprint at all ?
What happened on the file system is that the occupied space has been simply doubled – it has went from 0.328 GB to 0.672 GB ! So what the effectiveness of the Columnstore compression? Why do we have any File System imprint at all ?
Why don’t SQL Server keep all the data In-Memory like it supposed to do ?
…
Let’s step back and see what happens when we add a regular index to our table (include here running all the restore part and table creation :
alter table dbo.FactOnlineSales_Hekaton add INDEX NCIX_1_FactOnlineSales_Hekaton NONCLUSTERED HASH (OnlineSalesKey, DateKey, StoreKey, ProductKey, PromotionKey, CurrencyKey, CustomerKey, SalesOrderNumber, SalesOrderLineNumber, SalesQuantity, SalesAmount, ReturnQuantity, ReturnAmount, DiscountQuantity, DiscountAmount, TotalCost, UnitCost, UnitPrice, ETLLoadID, LoadDate, UpdateDate) WITH (BUCKET_COUNT = 2000000); CHECKPOINT
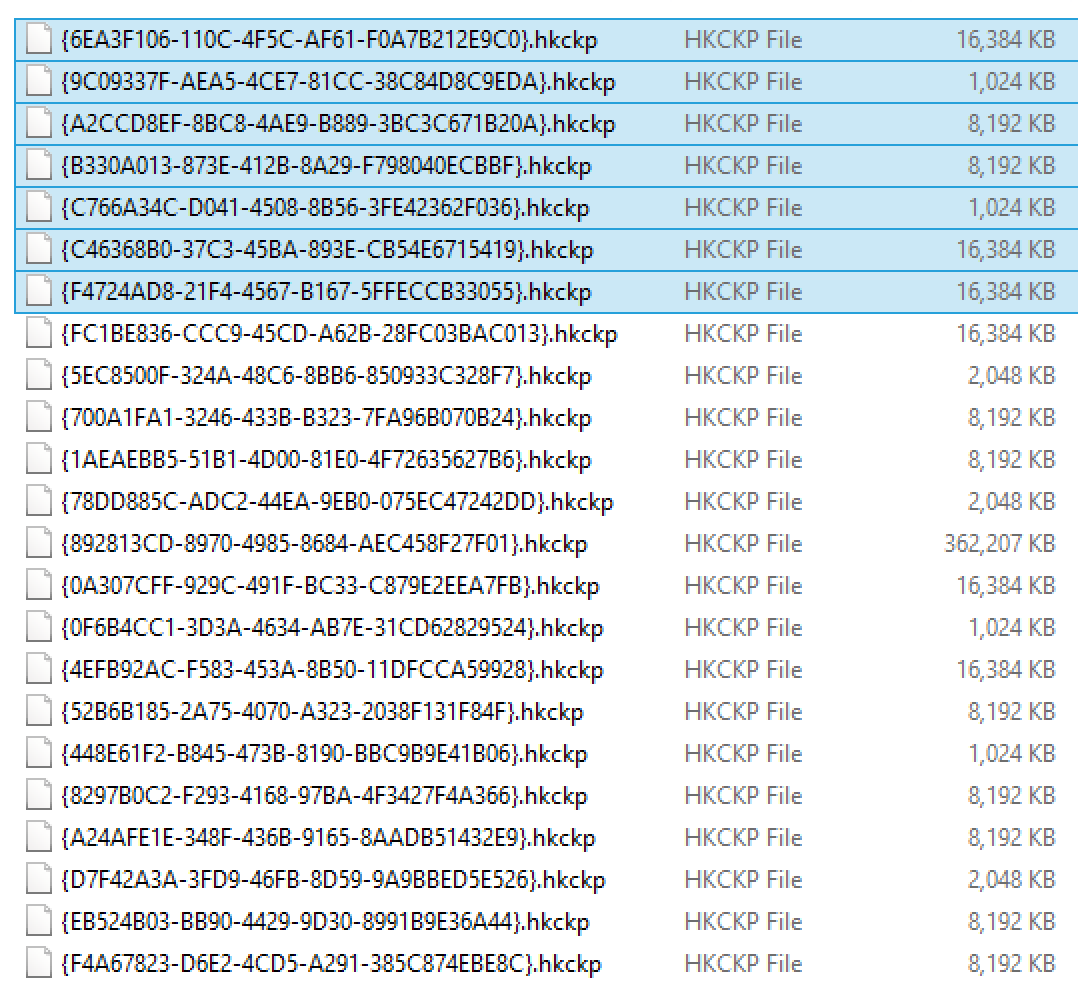 On the picture on the right side, you can see the complete list of the checkpoint files that were added to the file system after executing the addition of a new Hash Index, the new files that were added are highlighted and their sum is around 68 MB.
On the picture on the right side, you can see the complete list of the checkpoint files that were added to the file system after executing the addition of a new Hash Index, the new files that were added are highlighted and their sum is around 68 MB.
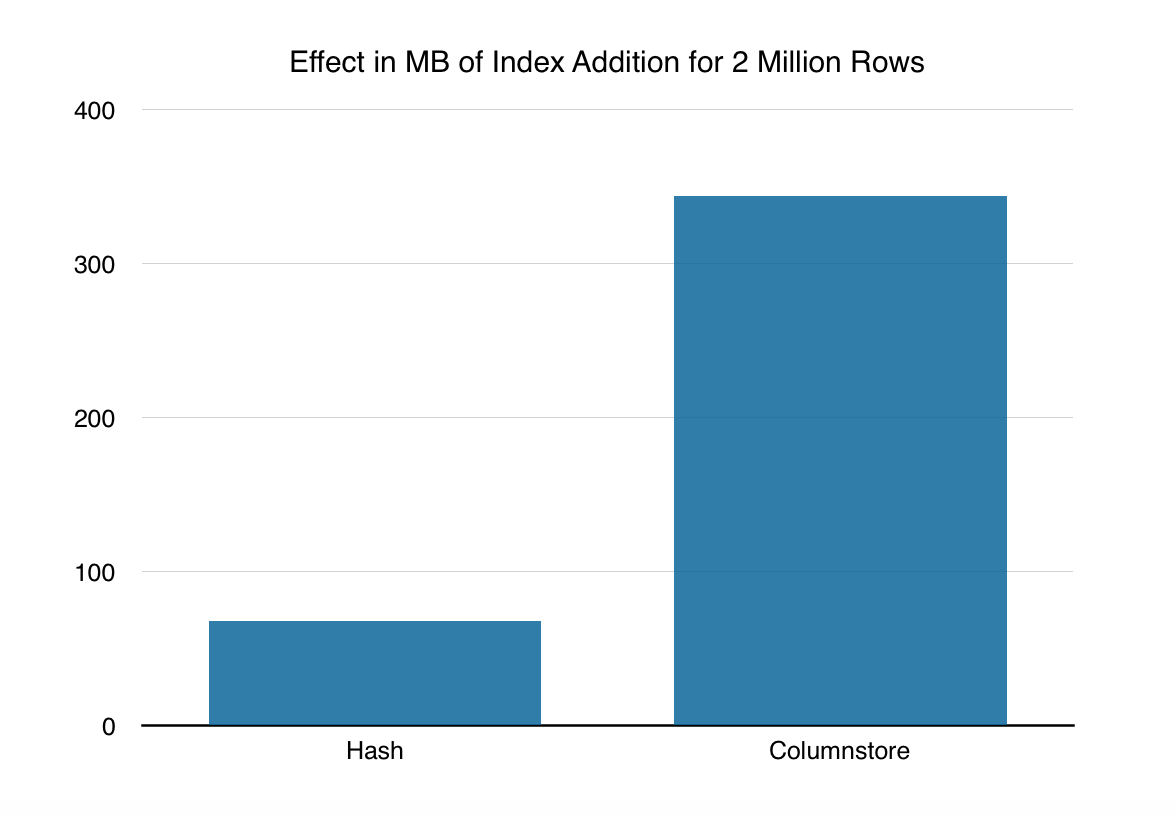
Below this text, you can see the relative impact that the addition brings, but keep in mind that while the columnstore indexes addition will grow proportionally to the number of rows added, the nonclustered hash indexes will keep their size pretty much at the same level.
Columnstore: Disk vs In-Memory
Let’s compare the size of the Row Groups between the Disk-Based Clustered Columnstore Indexes and the In-memory Clustered Columnstore. Yeah, I know – the algorithms should be absolutely the same or similar and one would not expect to have any significant differences, but you know, just in case ;)
Let’s use CISL for discovering the sizes of the Row Groups:
exec dbo.cstore_getRowGroupsDetails;

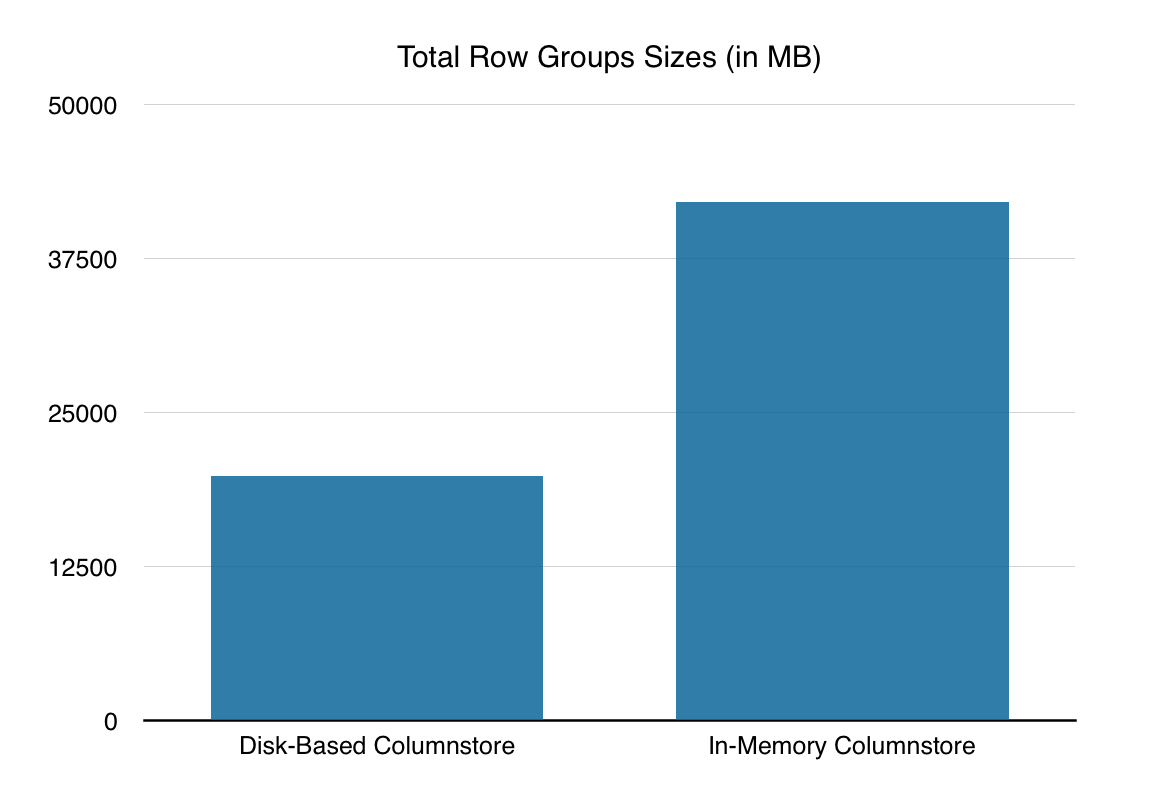 One can very clearly notice the huge difference (almost double the size) between the sizes of the disk-based columnstore indexes and the in-memory ones. As the size of the table increases, so will the occupied space and keep in mind, that for the disk-based columnstore you can always cut the disk space even further by using Columnstore Archival compression.
One can very clearly notice the huge difference (almost double the size) between the sizes of the disk-based columnstore indexes and the in-memory ones. As the size of the table increases, so will the occupied space and keep in mind, that for the disk-based columnstore you can always cut the disk space even further by using Columnstore Archival compression.
Let’s consider if the are some serious differences in the dictionaries and for verifying that, lets run the dbo.cstore_getDictionaries function from the CISL:
exec dbo.cstore_getDictionaries;
![]()
Its really interesting that though the sizes of the dictionaries are very similar, the total number and their distribution are definitely not. I will be looking into the whole dictionary and the compression story and differences of the columnstore indexes in the upcoming months, but in the mean time let’s leave it for here.
The reason for this significant difference is that the disk-based columnstore are optimised on the compression while the Memory-Optimised ones are not, and to see that information you can easily use the CISL function “dbo.cstore_getRowGroupsDetails”:
exec dbo.cstore_getRowGroupsDetails;
You can see the results marked in red on the right side of the image below:

Natively Compiled Stored Procedures
The message that has been delivered over and over again over all type of media and live presentations and blogs is that the natively compiled stored procedures are much better and that everyone should be using them when working with Memory-Optimised tables.
…
Let’s take it to the test :)
Let’s run the very same query as a interpreted one and compare it’s performance with a query written in the natively compiled stored procedure:
create procedure dbo.Test with native_compilation, schemabinding as begin atomic with (transaction isolation level = snapshot, language = N'English') select StoreKey, sum(sales.SalesAmount) from dbo.FactOnlineSales_Hekaton sales group by StoreKey end
Let’s run the test:
set statistics time, io on exec dbo.Test; select StoreKey, sum(sales.SalesAmount) from dbo.FactOnlineSales_Hekaton sales group by StoreKey;
Since the natively compiled stored procedure with Columnstore indexes, does not show:
– logical reads for the columnstore index
– execution plan,
the only thing we can easily measure are the execution times, and they look like this:
317 ms vs 174 ms (Native Compiled Stored Procs vs Interpreted Query). Visually this looks like this:
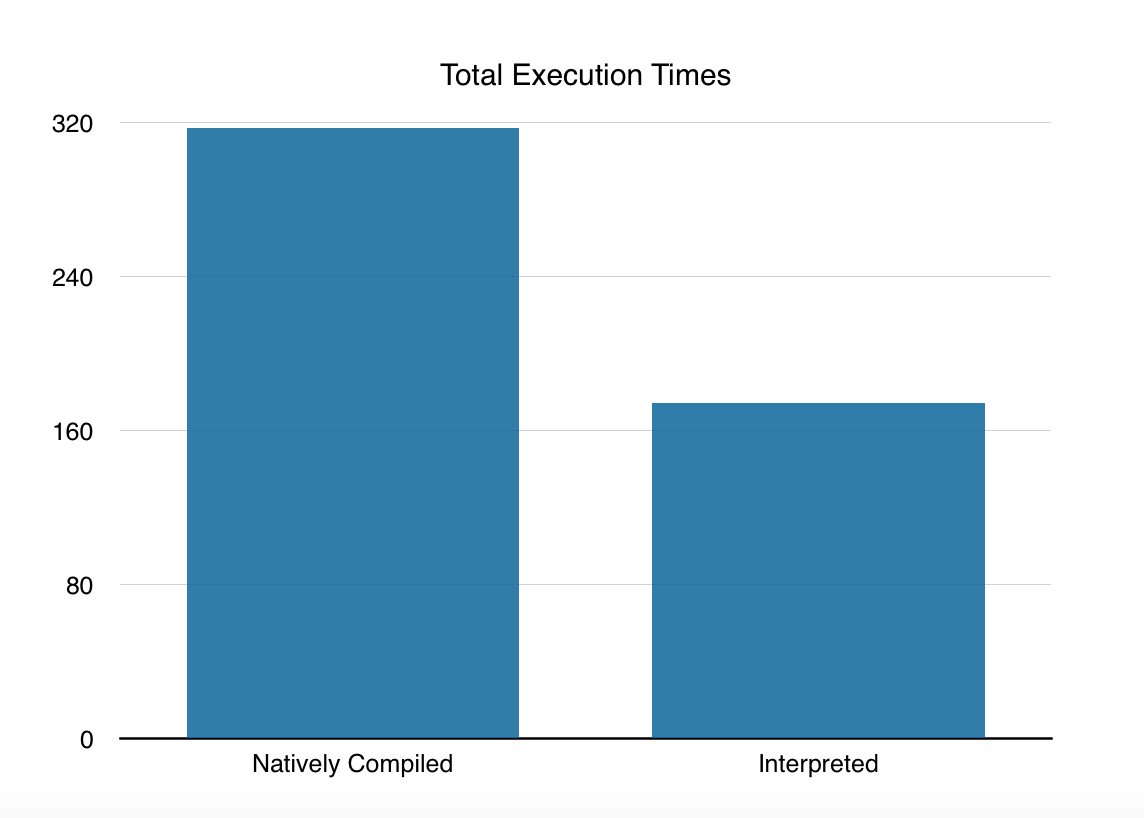 That’s because the first query, the one that runs with the Natively Compiled Stored Procedure runs with a single core and it will not use the Columnstore Indexes, while the interpreted query is not limited to just 1 core! Meaning that you have got to be very careful when going all in on the natively compiled stored procedures, because when your analytical query requires more power than just 1 core, you will not be able to get it from SQL Server 2016.
That’s because the first query, the one that runs with the Natively Compiled Stored Procedure runs with a single core and it will not use the Columnstore Indexes, while the interpreted query is not limited to just 1 core! Meaning that you have got to be very careful when going all in on the natively compiled stored procedures, because when your analytical query requires more power than just 1 core, you will not be able to get it from SQL Server 2016.
OLAP vs HTAP (Hybrid Transactional/Analytical Processing)
Whenever you are comparing the real data warehousing solution (star schema or whatever design you are using), you should clearly understand the dangers of going into the Operational Analytics kind of the design (or now more known as HTAP – Hybrid Transactional/Analytical Processing).
Even though we have Clustered Columnstore Indexes on disk-based and on memory-optimised tables, they are very different solutions that are not that much comparable in the terms of the design, optimisations and naturally performance.
Final Thoughts
This post is not intended to be used as a bashing tool of Microsoft, but rather as a warning for those who run for the newest solutions, without understanding their true limits.
to be continued with Columnstore Indexes – part 90 (“In-Memory Columnstore Improvements in Service Pack 1 of SQL Server 2016 “)
Hi great article.But I have specific question -we have a table with 90 million records and a server with 8 GB memory allocated.
when we use xVelocity in-memory analytics engine on SSAS 2016 there is no problem and it just took 400 MB of memory but when we want to use it with in-memory optimized ColumnStore index 2016 (create an in-memory table with clustered columnstore index) we encounter an error like this:
There is insufficient system memory in resource pool ‘default’ to run this query.
I thought memory optimized ColumnStore index must use less memory than the xVelocity in-memory analytics engine and this two technologies are just the same! what is it so?
thanks in advance.
Hi Mohsen,
In-Memory Clustered Columnstore does not use Vertipaq Compression and compresses less in comparison to the disk-based Clustered Columnstore (Logical reason is that currently In-Memory Columnstore is targeting HTAP aka Operational Analytics, where insertion speed is the key). I have mentioned that difference in the following blog post http://www.nikoport.com/2016/10/25/columnstore-indexes-part-89-memory-optimised-columnstore-limitations-2016/
Did you try working with Resource Governor, configuring a different amount of RAM for the memory grants as a solution ?
Best regards,
Niko
Hi Niko,
I read your blogs regarding operational analytics using memory optimized table + clustered columnstore (CCI). I am running test on similar workload.
The workload is as follow:
– 50 million rows on the table initially (size is about 50 GB)
Run simultaneously:
– 300 user insertion process –> 3000 TPS
– 500 user query (simple, medium, complex)
Use Azure VM (32 cores, 448 GB RAM)
resource pool is set to 90% max_memory, 90% max CPU. memory grant is 25% for each user
Issue: we got error for some queries. some is complete successfully.
There is insufficient system memory in resource pool ‘default’ to run this query.
When we run on 10 insert users x 30 query users, there is no error.
Do you have any advice regarding this error? what should I try to setting and test again?
Thank you