Today the topic is something that is totally unexpected – the throttling of the SQL Server Backups. Why unexpected you might ask – well, unless you run workloads on Cloud VMs, you might be totally unaware of the problems that arise regularly on the VMs that are not sized “appropriately”. I have put the word correctly into the quotes, because as I will show you in the next blog posts, this will totally depend on the point of view, and if you put yourself into the customer shoes (and you are, dear reader, a customer – unless you are working for Microsoft) – you might be feeling totally nuts as you will face those problems, which will include sudden Availability Groups Fail-overs, Canceled Jobs and yeah – you got it: Business Transaction Rollbacks.
As I have pointed out in Resouce Governor IOPS_PER_VOLUME is not enough, one major problem that I see around is the impact of the IO on the SQL Server operations and one particularly complex problem are the backups, especially when working with big databases. By Big right now I am defining now databases with Multiple Terabytes, but I am confident that this problem is even more common than a lot of people realize.
If you are doing a full or differential backup on a reasonably busy SQL Server instance, you will face the problem of concurrent workload across different drives that will drive THE SUM of your disks throughput far beyond the Virtual Machine max values.
The Setup
I have chosen a small Azure VM for this purpose — Standard_E4s_v3, containing 4 CPU cores, 32 GB of RAM, 64 MB/second maximum CACHED disk throughput and 96 MB/second maximum UNCACHED disk throughput,
and 3 P30 disks:
– 1 P30 disk to serve as a single volume directly (this volume will give us 200 MB/second of maximum throughput with 5,000 IOPs at maximum): G Drive;
– 2 P30 disks to create a Storage Pool to serve as a 2 TB volume for the data that (this volume will give us 400 MB/second of maximum throughput with 10,000 IOPs at maximum): K Drive;
We need those 3 TB of data/log (let us say we have 2 TB of data), but the potential effect on this situation is very interesting:
Our VM has a maximum throughput (cached, for the sake of the test and because we have followed the best practices and created our disk drives with read cache) of 64 MB/second vs 600 MB/second throughput of just those 3 disks (we are totally ignoring D drive that will suffer the read cache impact, and let’s ignore the System C drive as well, but just for the sake of the test – because in real life you won’t be able to do that, unless you want your transactions to get sudden rollbacks and VM get frozen and your Availability Groups & Failover Cluster to suffer sudden Failovers).
Yes, you are reading this right – we have a VM, which disk throughput limit is almost 10 times slower then of its disks (in real life even more).
I am not touching on the fact that disk D is doing the caching and that it’s impact will be added to the limits we are facing, and that is THE SINGLE REASON THAT MANY CUSTOMERS HAVE STOPPED USING D DRIVE FOR TEMPDB.
That means and this is what you will get from Microsoft Support (yes, I have seen enough cases so far that I can confident that this is a real life response) – upgrade your VM up to Standard_E48s_v3, giving you 768 MB/second of maximum disk throughput (which has 48 CPU cores, just 44 CPU cores more, meaning that you will have to PAY THE LICENSE FOR EVERY SINGLE ONE OF THEM, and LOL @ you if you are using a Standard Edition of SQL Server, which supports the half (24) of them at maximum).
Note: yeah, there are other cheaper VMs that can deliver the necessary throughput, such as Standard_DS15_v2, but the point is that even another 4 CPU cores SQL Server license will be unbearable for the most customers.
Funny, isn’t it ? (Tip: it is not, if you are a paying customer)
Well, let’s take a look at how we can tackle it with SQL Server, so that our operations won’t get canceled:
Resource Governor Setup
Let us set up Resource Governor with a new Resource Pool and a Workload Group, right now specifying all the regular default values:
CREATE RESOURCE POOL [backupPool] WITH(min_cpu_percent=0, max_cpu_percent=100, min_memory_percent=0, max_memory_percent=100, cap_cpu_percent=100, AFFINITY SCHEDULER = AUTO, min_iops_per_volume=0, max_iops_per_volume=0); CREATE WORKLOAD GROUP [gBackup] WITH(group_max_requests=0, importance=Medium, request_max_cpu_time_sec=0, request_max_memory_grant_percent=25, request_memory_grant_timeout_sec=0, max_dop=0) USING [backupPool];
Now, it is time to define a Resource Governor Classifier function in the master database, which will serve to map our User “BackupUser” (that I have created for this purpose) with the Workload Group “gBackup“, that we have defined in the previous step:
CREATE OR ALTER FUNCTION [dbo].[fnUserClassifier]()
RETURNS sysname WITH SCHEMABINDING
AS
BEGIN
DECLARE @WorkloadGroup AS SYSNAME;
IF(SUSER_NAME() = 'BackupUser')
SET @WorkloadGroup = 'gBackup'
ELSE
SET @WorkloadGroup = 'default'
RETURN @WorkloadGroup;
END
ALTER RESOURCE GOVERNOR
WITH (CLASSIFIER_FUNCTION = fnUserClassifier);
And in the end, we shall need to reconfigure the Resource Governor in order to have all those actions in effect:
ALTER RESOURCE GOVERNOR RECONFIGURE;
Limiting IOPS
As already mentioned in the other posts, the only parameter that is controllable in the terms of IO control are the MIN_IOPS_PER_VOLUME & the MAX_IOPS_PER_VOLUME, giving us pretty exciting (*cough*) control of the disk. Of course we do consider that all our operations occupy the same size and I mean, come on! All backups will be the same, right ?
For the backup part I will use Ola Hallengren’s solution installed in the master database, because for me it is a good de-facto standard for working with databases.
Let’s run the backup of the TPCH 10GB database that is located on our K drive (2 P30 Disks with a potential of reaching 400 MB/second):
EXECUTE [dbo].[DatabaseBackup] @Databases = 'TPCH_10', @BackupType = 'FULL', @URL = 'https://xxxxxx.blob.core.windows.net/backups', @NumberOfFiles = 8, @CheckSum = 'Y', @LogToTable = 'Y', @Compress = 'Y', @MaxTransferSize = 4194304, @BlockSize = 65536
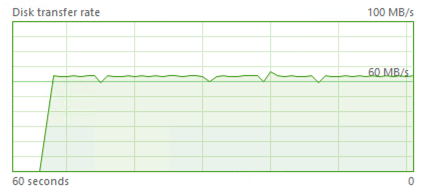 Yeah, those wonderful
Yeah, those wonderful 400 64 MB/second that our VM type Standard_E4s_v3 will give us at max. Of course, in the real world, if we would have an Availability Group and would be running a reading workload on the other drive (G), we would be probably already facing a Failover, but hey – life is good.
Let’s throttle the IOPs to just 10, to see what kind of throughput we shall get out of our system. Let us hope that it will help by lowering the capacity significantly, after all the disk is capable of giving 5000 IOPs and thus we are limiting by 50 times, maybe we should get 4 MB/second (200 MB/second divide by 50) (WARNING: this is definitely a wrong thought on so many levels).
ALTER RESOURCE POOL backupPool WITH (MAX_IOPS_PER_VOLUME = 10); ALTER RESOURCE GOVERNOR RECONFIGURE;
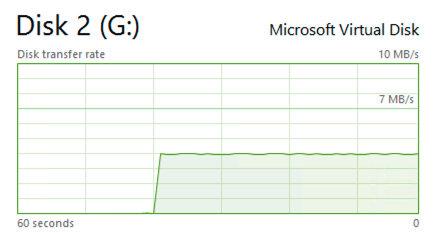 After trying again with our Login “BackupUser” – we have got around 4 MB/second, just like we have expected, isn’t it wonderful ?
After trying again with our Login “BackupUser” – we have got around 4 MB/second, just like we have expected, isn’t it wonderful ?
But what about some other database on the very same drive – the one that takes just a couple of GB and it is nonetheless but my good old friend ContosoRetailDW free database from Microsoft that has been abandoned a couple of years ago already:
EXECUTE [dbo].[DatabaseBackup] @Databases = 'ContosoRetailDW', @BackupType = 'FULL', @URL = 'https://xxxxxx.blob.core.windows.net/backups', @NumberOfFiles = 8, @CheckSum = 'Y', @LogToTable = 'Y', @Compress = 'Y', @MaxTransferSize = 4194304, @BlockSize = 65536
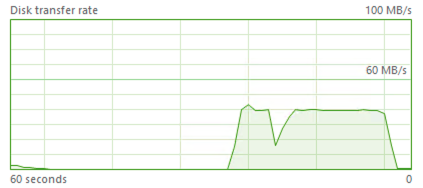 Wow, this time we have got a little bit over 40 MB/second without changing any parameter on the server. Without diving into any reasons behind it, here goes the primary argument – You will not be able to control all your disks throughput with the current IOPS parameter.
Wow, this time we have got a little bit over 40 MB/second without changing any parameter on the server. Without diving into any reasons behind it, here goes the primary argument – You will not be able to control all your disks throughput with the current IOPS parameter.
Period.
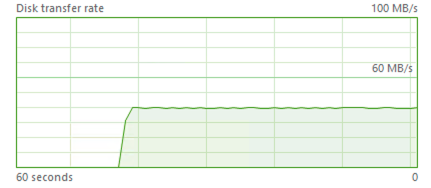 Consider that taking backup of the same Database (detach, copy & attach) from the disk K gave us a bit over 42 MB/second throughput as you can see on the picture on the right side of this text.
Consider that taking backup of the same Database (detach, copy & attach) from the disk K gave us a bit over 42 MB/second throughput as you can see on the picture on the right side of this text.
Limiting CPU
Tackling this problem from a different angle will require to focus … on the CPU. Every operation requires some CPU and by throttling it very rigorously, we might be able to control the impact of the maximum disk throughput speed, and for that purpose let’s reset the MAX_IOPS_PER_VOLUME parameter to the default and define the CAP_CPU_PERCENT parameter to cap the CPU by 10%:
ALTER RESOURCE POOL backupPool WITH (MAX_IOPS_PER_VOLUME = 0); ALTER RESOURCE POOL backupPool WITH (CAP_CPU_PERCENT = 10); ALTER RESOURCE GOVERNOR RECONFIGURE;
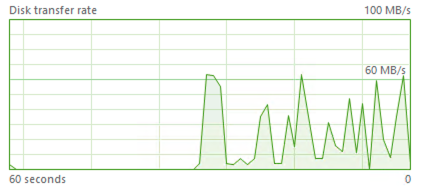
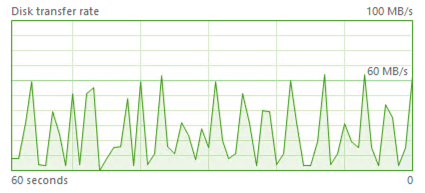 The average :) impact of the throttling can be clearly seen through the spikes of the IO operations on the graphic on the left side of this text, but this is the one that really works and that is closer to the real world throttle, then the max_memory_percent parameter we have been using before, even though the IOPs one is guaranteeing smoother performance as per these tests.
The average :) impact of the throttling can be clearly seen through the spikes of the IO operations on the graphic on the left side of this text, but this is the one that really works and that is closer to the real world throttle, then the max_memory_percent parameter we have been using before, even though the IOPs one is guaranteeing smoother performance as per these tests.
You might ask and wonder if the combination of 2 would not be a better all-together solution and the answer is – try it out yourself. :).
The most important thing I can share is that in my experience those temporary IO spikes will not provoke those VM freezes and Availability Group Failovers, but maybe your experience will be different.
The Agent, The SQL Agent
If you have never battled with SQL Server and Resource Governor for the controlling the behaviour of the jobs, you might think and declare that the mission is completed, but wait a second – there is one more thing.
Most people I know who are running SQL Server in IaaS are using good old (almost obsolete as in “where are my granular permissions for job editing”) SQL Server Agent.
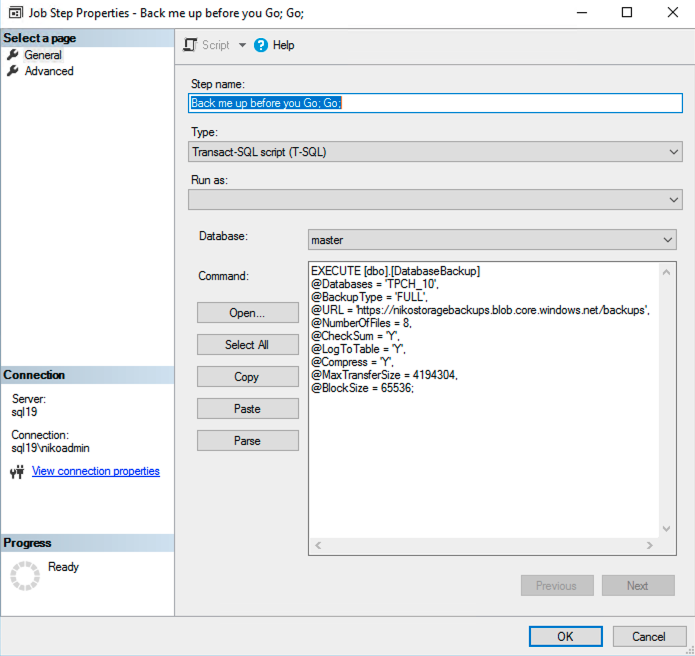 Setting up a regular SQLAgent Job is a regular task for anyone working with SQL Server, right ? So the question that needs to be asked is – Where do you specify the credentials of the login that will be used for executing the job. This is one of the most painful elements in all this SQL Server Backup Throttle, in my opinion – because we are facing very, very old problems which have not been addressed in many years before and reasonably thinking about Microsoft’s motto “Cloud First” there is not even a remote chance of Microsoft starting to fix the SQL Server Agent deficiencies. Being a very big optimist in general, I am not even trying to hold my breath on this one.
Setting up a regular SQLAgent Job is a regular task for anyone working with SQL Server, right ? So the question that needs to be asked is – Where do you specify the credentials of the login that will be used for executing the job. This is one of the most painful elements in all this SQL Server Backup Throttle, in my opinion – because we are facing very, very old problems which have not been addressed in many years before and reasonably thinking about Microsoft’s motto “Cloud First” there is not even a remote chance of Microsoft starting to fix the SQL Server Agent deficiencies. Being a very big optimist in general, I am not even trying to hold my breath on this one.
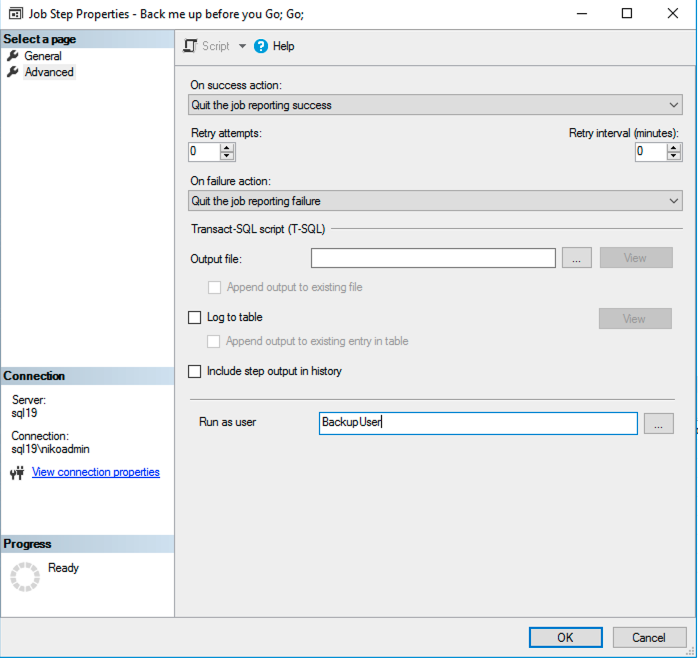 Here is the wrong solution on the right side of this text – it is definitely not the place where you want to specify your user, since there is no actual login procedure taking place, Resource Governor will happily ignore this option and you will end up with our default SQLAgent User. :(
Here is the wrong solution on the right side of this text – it is definitely not the place where you want to specify your user, since there is no actual login procedure taking place, Resource Governor will happily ignore this option and you will end up with our default SQLAgent User. :(
Unfortunately, setting up a Proxy will not help you either – there is no login operation in the execution and thus Resouce Governor will not help us out.
The solution
Use the Powershell, Luke!
Invoke-Sqlcmd -ServerInstance LocalHost -Query "EXECUTE [dbo].[DatabaseBackup] @Databases = 'TPCH_10',@BackupType = 'FULL',@URL = 'https://nikostoragebackups.blob.core.windows.net/backups',@NumberOfFiles = 8,@CheckSum = 'Y',@LogToTable = 'Y',@Compress = 'Y',@MaxTransferSize = 4194304, @BlockSize = 65536;" -Username BackupUser -Password '1234567890'
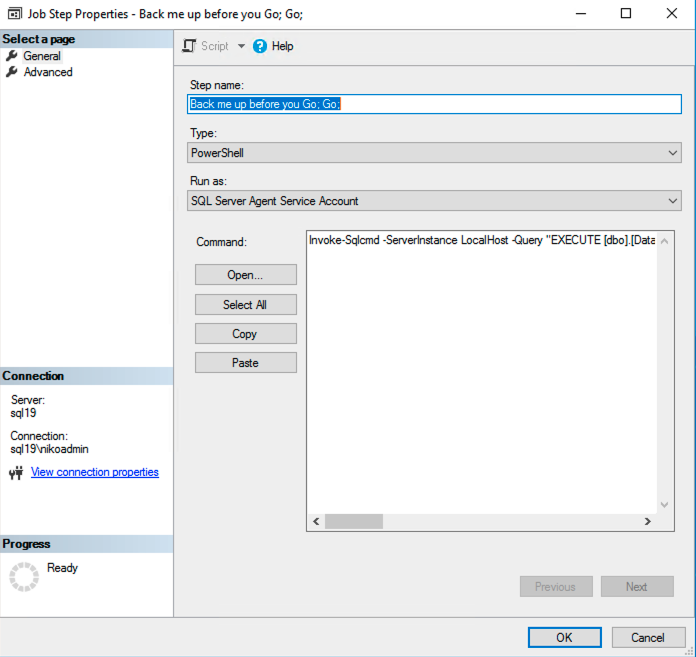 By using the good old Invoke-SQLCMD Powershell function we can establish the connection (while I am doing here in clear text, you definitely should be using a more secure way, unless you pretend to use your SYSADMIN credentials in clear text (yes, Ola Hallengren’s backup requires SYSADMIN, as a according to documentation)). Consider using whatever suits you to make sure it works, use the Azure Vault if you need – but do not use simple password or plain text authentications.
By using the good old Invoke-SQLCMD Powershell function we can establish the connection (while I am doing here in clear text, you definitely should be using a more secure way, unless you pretend to use your SYSADMIN credentials in clear text (yes, Ola Hallengren’s backup requires SYSADMIN, as a according to documentation)). Consider using whatever suits you to make sure it works, use the Azure Vault if you need – but do not use simple password or plain text authentications.
Final Thoughts
Besides above listed techniques, if you are doing Backup To URL (Azure Blob Storage), consider using less stripes (backup files) as it will affect the reading and the writing speed, block size (it will affect the maximum size of a single stripe, so you better watch out and use the script described in Striping Backups to Azure Blob Storage and adjust it accordingly to your maximum available size of a stripe) and …
VOTE UP on the suggestion to Allow Resource Governor to control the CAP of the TOTAL IO in MB/s.
Thanks for sharing, Niko!
There are two glaring issues that you’re overlooking, though:
1. Resource governor is an Enterprise only feature. It won’t help with standard edition servers.
2. You don’t have to complicate things with powershell in order to identify your backup jobs in the classifier function. Instead of checking the username, you can simply check the PROGRAM_NAME which is used by SQL agent to identify the job ID being executed.
Hi Eitan,
Thank you for the valuable feedback.
1. Yeap, agree. Standard Edition gives us a lot of limitation and almost no knobs to control.
2. Never thought of this, Great idea! I am wondering though if it throttle then all the jobs, which is definitely not the goal.
Adding a check if a particular job is running would definitely help to solve this …
Thank you again for the tip – I will definitely need to look deeper into this.
Best regards,
Niko
Niko
Big fan of this article, answered a load of questions we were having in an Azure deploy.
Quick question – with backup compression is the compression outside of the control of the resource governor? It appears to be so and at weekends we see CPU peak to 95% + and backup times cut in half. I’m just twitchy, on previous VMs using Std Edition when the backups saturated the disk paths we saw failovers and that seemed nicely under control with RG & cap_cpu_percent and max_iops_per_volume = 20 (~160MBPS) for the Recovery Service Vault process. However it seems backup compression will flat-line CPU.
Any experience with this?
Regards
Gareth
PS Godaddy isn’t serving the right certificate for this site so you have to bypass the security
Hi Gareth,
to my understanding – yes, RG can not control Backup Compression.
Regarding the certificate – yeah … I will be migrating away, I am tired of the problems with Media Temple.
Best regards,
Niko