If you remember yourself being a new kid on the block to the databases and the concept of the transaction and rollback, or if you have ever worked or working with the people who are new to the principles and concepts of transactions, then you must have experienced in one way or another the feeling of “When does this transaction, if ever, finishes committing/recovering”. If you are a DBA (voluntary or involuntary one), then surely you are facing the most typical question from someone doing a big transaction against a database and wanting to know when it finishes and if it is safe to cancel it without paying 2-3 times the price/time. Another item is the database recovery time – being it a simple instance start/restart or an Availability Groups failover, the impact of the operation can be very, very significant and if you are playing in the 24×7 league, this is something that definitely won’t bring you any significant joy with impatient questions coming from all stakeholders – “How Much Longer?”
As recently as a couple of weeks ago, someone ran a rather furious task of updating a lot of information on the database I help to manage and where we all together decided to cancel the task after a couple of hours. You want to know what was the result of the cancelation ? Almost a 6 hours of waiting for transaction to finish. And topping of this cake was of course the fact, that the Database was in Availability Group. :)
Introducing ADR – Accelerated Database Recovery
Accelerated Database Recovery is new mechanism that is being developed for Azure SQL Databases and SQL Server 2019, that potentially will allow to cut the time to recovery from the canceled/rolled-back transactions and the time we spent on database recovery.
Building on the impeccable paper of ARIES with Write-Ahead Logging – Panagiotis with Christian, Hanuma and several others have built Constant Time Recovery in Azure SQL Database which with the help from the marketing because Accelerated Database Recovery as ADR instead of long-time expected original CTR :) The whole idea behind the Accelerated Database Recovery is to help to greatly improve the time spent on the recovery by paying dues ahead of time, with the help of the Persistent Version Store, which will store the intermediate versions of the modified rows within the same database where ADR is enabled.
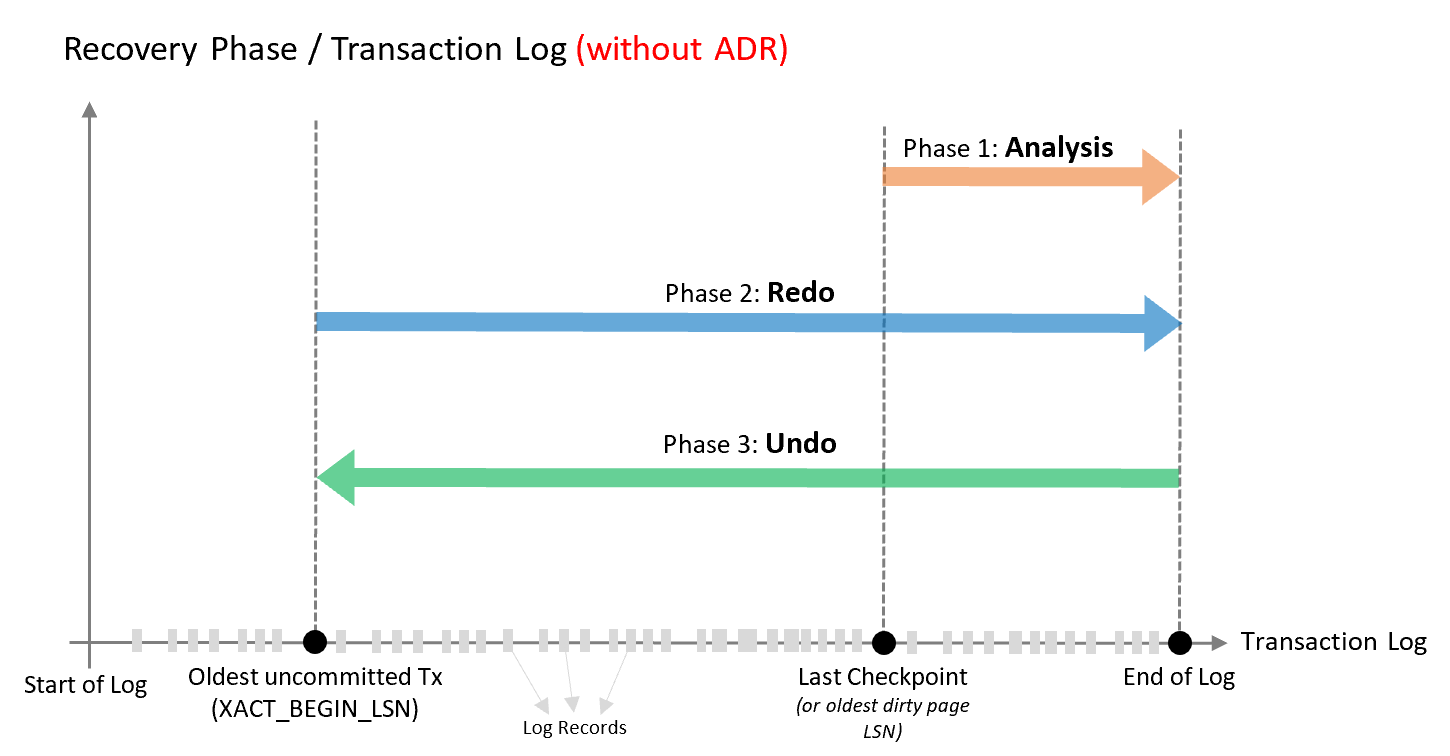 On the left side, I have included an image from the Original Microsoft Article on Accelerated Database Recovery, describing the principle phases of the Rollback process, that contains the following major phases:
On the left side, I have included an image from the Original Microsoft Article on Accelerated Database Recovery, describing the principle phases of the Rollback process, that contains the following major phases:
– Analysis
– Redo Lock Acquisition
– Physical Redo
– Undo
Analysis
The very first recovery phase identifies the transactions to be rolled back and the LSN of the oldest modified page. This process will scan the log starting from the last completed checkpoint with the Oldest Modified Page LSN to recovery the needed transactional information.
Redo
The Accelerated Database Recovery Redo Phase consist of the 2 phases. The first one is the Redo Lock Acquisition and the second is the real Physical Redo operation. Once we have the Oldest Modified Page LSN from the Analysis phase, we should process the log forward looking for the required version of the data page, but in the reality and in order to guarantee a better consistency, the Redo process will start working even from the earlier phase, which potentially can slower it’s performance significantly.
In SQL Server 2017 the Redo process has been already improved to be run in parallel, but the fact that the focus of the processing starts on the LSN of the oldest active transaction, meaning that a huge amount of potentially unnecessary work & recovery time will be spent on comparison between the Page LSN with the LSN of the processed log record.
The Redo phase is responsible to recover the data right to point in time when the failure took place.
Undo
The Undo phase will deliver the full rollback to any active non-completed transactions at the time of the Cancelation/Failure. The Undo can be executed while database is already available for user queries and it will eventually block them in cases if they are trying to access the modified data, which Undo processing has not finished yet.
The Undo will scan the log backwards and undo each log record individually in reversed sequence. This guarantees that the time for Undo processing will be largely equal to the size of the biggest uncommitted transaction. There are some additional mechanisms involved in this process, such as Compensation Log Records (CLR), that will guarantee the recoverability of the database, even if the server/database will go down again.
Accelerated Database Recovery
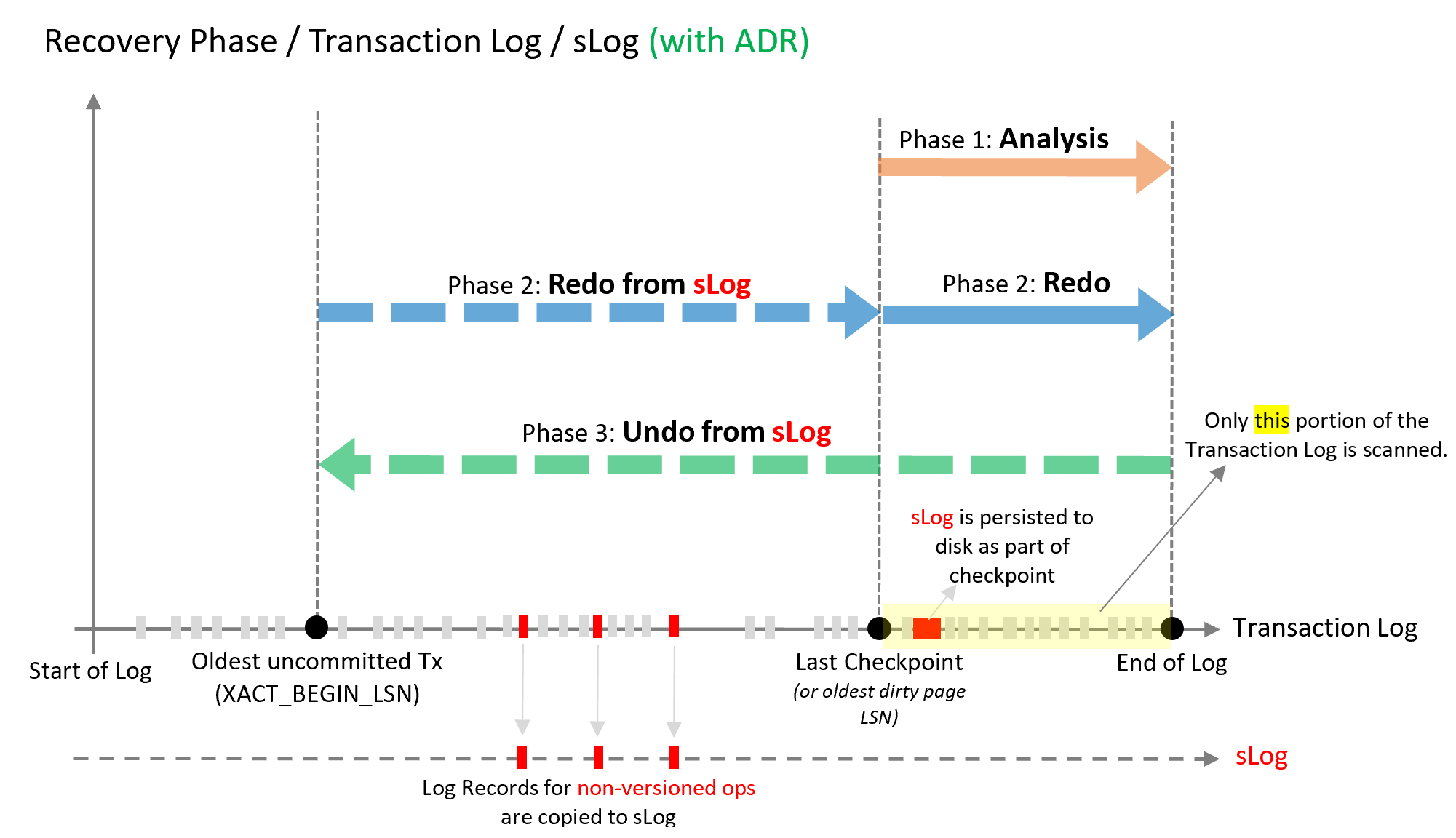 The declared objectives of the ADR implementation were to bring the Constant Recovery Time to the Database Recovery & Transaction Rollback operations, ensuring better predictability for the UNDO & REDO processes, through more efficient Log truncation process. Focusing on the Redo phase that can be optimised through processing not from the beginning of the oldest uncommitted transaction, but rather from the determined in the Analysis phase last modified page LSN, with the addition of the fast processing from the non-versioned pages from the earlier phase of the transaction log.
The declared objectives of the ADR implementation were to bring the Constant Recovery Time to the Database Recovery & Transaction Rollback operations, ensuring better predictability for the UNDO & REDO processes, through more efficient Log truncation process. Focusing on the Redo phase that can be optimised through processing not from the beginning of the oldest uncommitted transaction, but rather from the determined in the Analysis phase last modified page LSN, with the addition of the fast processing from the non-versioned pages from the earlier phase of the transaction log.
But before jumping too much ahead, let’s review the 4 of the support components that the log processing has received for the Accelerated Database Recovery process:
– Persistent Version Store (PVS)
– Logical Revert
– sLog
– Background Cleaner
Persistent Version Store (PVS)
The Persistent Version Store is the mechanism that guards the row versions of the data, in the similar way that the TempDB does for the RCSI and Snapshot isolation levels. In this way besides improving the availability, it also improves the readable secondaries in the Availability Groups.
Contrary to the TempDB Row Versions, the information in the PVS is recoverable and consistent and it allows to access the earlier versions of the Data Pages faster and easier.
In Accelerated Database Recovery the Row Versions are needed for the recovery process and thus they will be preserved until all commits to to the data page are finalised. The removal of the obsolete Row Versions in Persistent Version Store are guaranteed and executed by the Background Cleaner process.
The row versions are stored in 2 types of the storage: in-row & off-row.
In the case of the in-row the version is stored up to 200 bytes and for the longer rows a good old 14-byte pointer to the off-row location with the information will be used.
Logical Revert
Logical revert is the process that performs row-level instant operations, allowing the Rollback and Recovery to be executed on the data modification transaction almost instantly by restoring the right version of the data, corresponding to the being of the respective transactions, by taking advantage of the Persistent Version Store.
This asynchronous process is capable of restoring data operations that can be versioned. For those operations that can not be versioned in SQL Server (such as updating system meta-data that are highly compacted such as allocation pages; critical system metadata such as boot page & row and page statistics for Bulk operations) there is a new component in ADR – the sLog.
sLog
sLog is a low volume an in-Memory log stream that guards log records for non-versioned operations. It is persisted on the disk by during the checkpoint phases and regularly truncated on the transaction commit.
The non-versioned operations are copied from the Transaction Log into the sLog.
sLog accelerates Redo & Undo phases by applying only the non-versioned operations only. This means it designed to be compact and fast, a kind of higher level cache, as to say :)
Background Cleaner
This process is responsible for aggressively removing the obsolete Row Versions that will not be used for the recovery process anymore. Such rows that will be removed from PVS by the Background Cleaner are the logically reverting updates, that performed by aborted transactions, aborted transactions that have their updates logically reverted and in-row & off-row versions that won’t be needed for the recovery.
ADR – Accelerated Database Recovery
For the Accelerated Database Recovery there are very similar phases as in the original Recovery phases (of course with some new fancy components and cool names :)):
– ADR Analysis
– ADR sLog Redo
– ADR Physical Redo
– ADR sLog Undo
ADR Analysis
The Analysis phase performs the same operation as before (identification of the the transactions to be rolled back and the LSN of the oldest modified page, etc) with an important addition of copying to sLog the non-versioned operations.
ADR sLog Redo
First in the Redo phase are the recommits for the oldest uncommitted transaction and up to the last checkpoint, that are executed fast from the sLog. Since the sLog should be kept minimal and in-memory, the expectation for the process to finish is very fast.
ADR Physical Redo
This time the transaction log will start from the last checkpoint and not from the oldest uncommitted transaction, having possibility to process just a tiny amount of information potentially, when comparing to the original phase that includes the ADR sLog Redo now.
ADR sLog Undo
The undo operation for the ADR will be executed almost instantly for the non-versioned operations from the sLog. Using Persistent Version store, the Logical Revert will use row versions to perform an undo on the row-level base, being a rather simple find and copy over operation, instead of tireless processing.
The Test Setup
It all sounds wonderful, so let’s take a couple of databases and queries for a ride and see how it behaves in a simple test environment. For this purpose I have a RC1 of the SQL Server 2019 on my Azure VM, with 2 databases – the good old ContosoRetailDW and a HammerDB generated 10GB TPC-H.
Transaction Rollback With Update
For the very first test, let’s do a rather simple and plain statement against the FactOnlineSales table from the forgotten & abandoned ContosoRetailDW database:
SET STATISTICS TIME, IO ON; BEGIN TRAN UPDATE [dbo].FactOnlineSales SET LoadDate = GETDATE(); ROLLBACK
I have executed this workload a good number of times to get a pretty consistent result and on the average I had 358.521 Seconds for the UPDATE process and an additional 141.629 Seconds for the Rollback. That almost 6 minutes for the process itself and 2 minutes and 21 seconds to roll it back. The sum of the executions is 8 minutes and 20 seconds.
Converting the database to the Accelerated Database Recovery with the following command requires to be able to get the exclusive lock on the database, so be sure this command to pass through by freeing up the respective DB from locking:
ALTER DATABASE ContosoRetailDW
SET ACCELERATED_DATABASE_RECOVERY = ON;
Running the very same workload against the very same database:
SET STATISTICS TIME, IO ON; BEGIN TRAN UPDATE [dbo].FactOnlineSales SET LoadDate = GETDATE(); ROLLBACK;
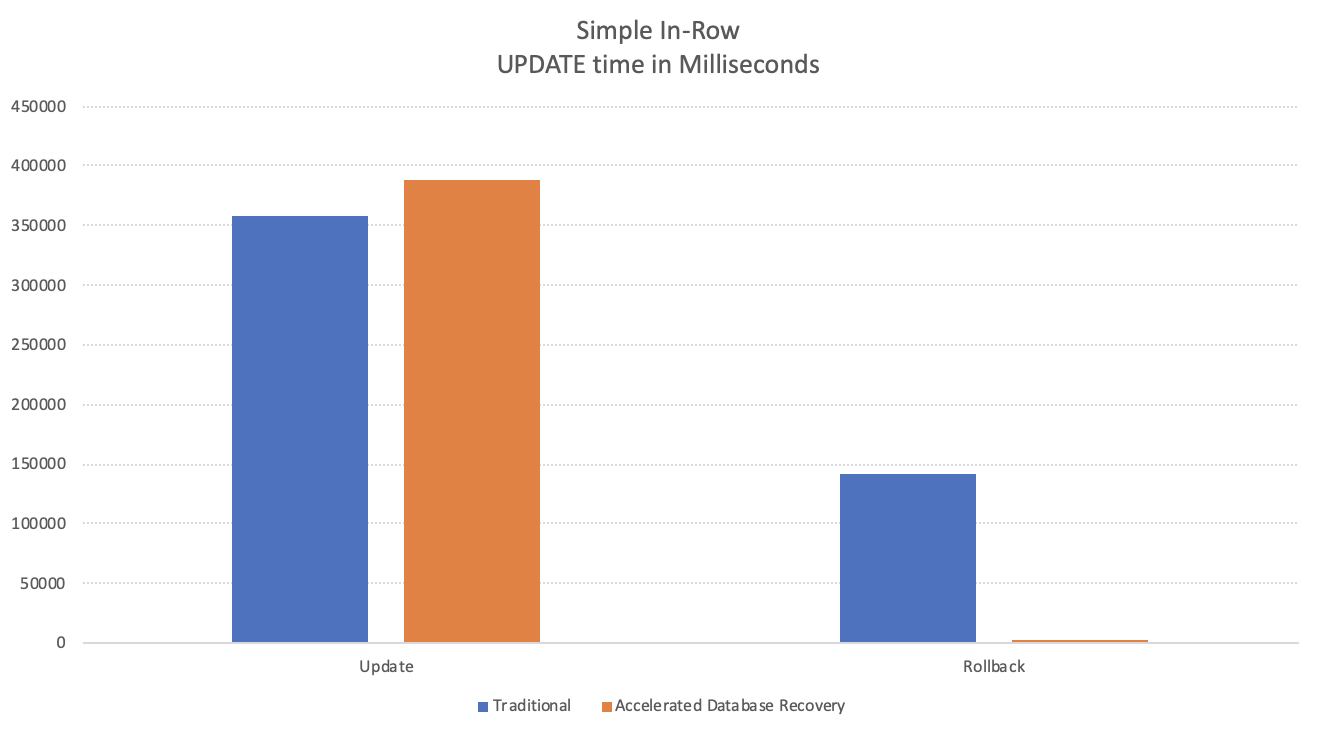 for the Database with enabled Accelerated Database Recovery resulted in a slight increase (around 8%) of the overall time for the UPDATE execution time – 388.588 Seconds, while the rollback … well the rollback receives the ever-generous 1 millisecond. Yes, that is not a mistake – we have spent 1 big second restoring our table (and hence the database) to the previous state. Given that we just have had 1 single version of the table in PVS it does not sound that complicated, isn’t it ? :)
for the Database with enabled Accelerated Database Recovery resulted in a slight increase (around 8%) of the overall time for the UPDATE execution time – 388.588 Seconds, while the rollback … well the rollback receives the ever-generous 1 millisecond. Yes, that is not a mistake – we have spent 1 big second restoring our table (and hence the database) to the previous state. Given that we just have had 1 single version of the table in PVS it does not sound that complicated, isn’t it ? :)
The difference is absolutely abysmal with 1 millisecond against 2 minutes and 20 seconds is an improvement of another dimension. The cost of 8% is something that can be tolerable in the systems with enough IO throughput.
Wide Table
Not saying that one table test is enough, but let’s consider a different scenario – let’s pick up a table that is wider than 200 bytes.
For this purpose I will pick the dbo.Customer table from the TPC-H 10 GB, which I will modify by adding a UpdateDate column that will be DATE and a new_comment CHAR(118) that will replicate the original content of the c_comment column:
ALTER TABLE dbo.customer ADD UpdateDate DATE ALTER TABLE dbo.customer ADD new_comment char(118); UPDATE dbo.customer SET new_comment = c_comment;
To control our current situation we can use the following query, confirming us our current situation for the Clustered Index index level 0:
SELECT min_record_size_in_bytes, max_record_size_in_bytes, avg_record_size_in_bytes FROM sys.dm_db_index_physical_stats(DB_ID(), OBJECT_ID(N'Customer'), NULL, NULL, 'DETAILED') WHERE index_id = 1 and index_level = 0;

On the image you can see that with a minimum of 239 bytes the tuples are reaching even 358 bytes in width, while enjoying the average record width of 298.936 bytes.
Let’s do a very similar workload with simple updates, updating the whole table with 1.500.000 rows:
SET STATISTICS TIME, IO ON; BEGIN TRAN UPDATE [dbo].customer SET UpdateDate = GETDATE(); ROLLBACK;
After running a warm-up and measuring the average of 10 executions my results were the following: 2083 Milliseconds for the Update operation itself and additional 3427 Milliseconds for the rollback process.
To enable the Accelerated Database Recovery on the TPC-H we shall run the following code:
use master; ALTER DATABASE tpch_10 SET SINGLE_USER WITH ROLLBACK IMMEDIATE; ALTER DATABASE tpch_10 SET ACCELERATED_DATABASE_RECOVERY = ON; ALTER DATABASE tpch_10 SET MULTI_USER;
We are ready to re-run the original workload:
SET STATISTICS TIME, IO ON; BEGIN TRAN UPDATE [dbo].customer SET UpdateDate = GETDATE(); ROLLBACK;
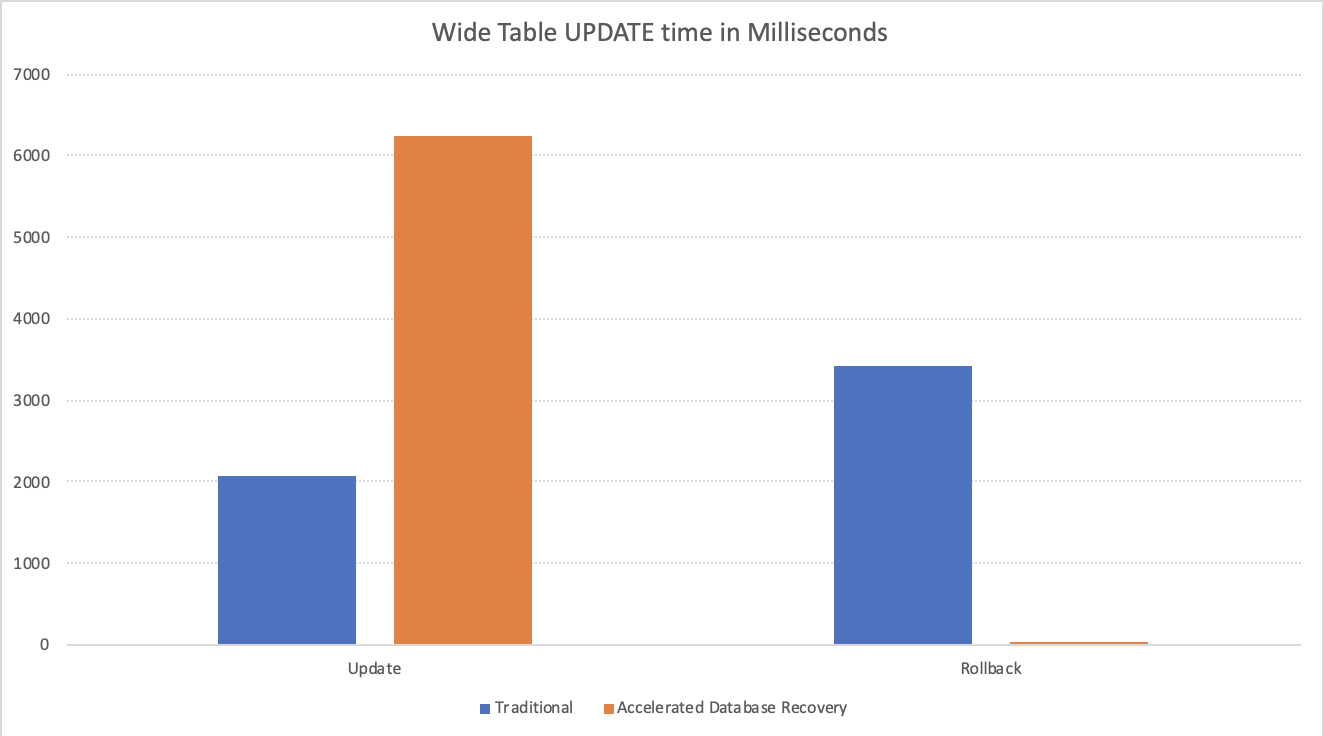 and the result is very interesting and impressive – we spent a huge 6253 milliseconds on the update operation, while enjoying our 1 millisecond for the rollback. In the sum this is an extremely expensive operation, meaning that if we mostly running UPDATE operations and not ROLLBACKs … Gosh what kind of application would expect otherwise? We would be decreasing our performance over 3 times – from 2 seconds down to 6.2 seconds! This is really an undesired scenario, which is the case if the vast majority of your data manipulation tasks are UPDATEs.
and the result is very interesting and impressive – we spent a huge 6253 milliseconds on the update operation, while enjoying our 1 millisecond for the rollback. In the sum this is an extremely expensive operation, meaning that if we mostly running UPDATE operations and not ROLLBACKs … Gosh what kind of application would expect otherwise? We would be decreasing our performance over 3 times – from 2 seconds down to 6.2 seconds! This is really an undesired scenario, which is the case if the vast majority of your data manipulation tasks are UPDATEs.
INSERT & DELETE operations
My expectation is that UPDATE is always the slowest and the most complicated of all the basic primitive atomic operations (and please do not hesitate to mention MERGE to me, I looove it so much! … well not!), that I wanted to take a look at the INSERT & DELETE as well, and so in this exercise let’s take a look at their performance with and without Accelerated Database Recovery.
For this purpose let’s create a copy of our test tables in the respective databases TPCH_10 & ContosoRetailDW – customerNew and FactOnlineSalesNew:
USE tpch_10 GO CREATE TABLE [dbo].[customerNew]( [c_custkey] [bigint] NOT NULL, [c_mktsegment] [char](10) NULL, [c_nationkey] [int] NULL, [c_name] [varchar](25) NULL, [c_address] [varchar](40) NULL, [c_phone] [char](15) NULL, [c_acctbal] [money] NULL, [c_comment] [varchar](118) NULL, CONSTRAINT [customerNew_pk] PRIMARY KEY CLUSTERED ( [c_custkey] ASC )WITH (PAD_INDEX = OFF, STATISTICS_NORECOMPUTE = OFF, IGNORE_DUP_KEY = OFF, ALLOW_ROW_LOCKS = ON, ALLOW_PAGE_LOCKS = ON) ON [PRIMARY] ) ON [PRIMARY] GO ALTER TABLE [dbo].[customer] WITH NOCHECK ADD CONSTRAINT [customerNew_nation_fk] FOREIGN KEY([c_nationkey]) REFERENCES [dbo].[nation] ([n_nationkey]) GO ALTER TABLE [dbo].[customer] CHECK CONSTRAINT [customerNew_nation_fk] GO -- ******************************************************************************************************* USE [ContosoRetailDW] GO CREATE TABLE [dbo].[FactOnlineSalesNew]( [OnlineSalesKey] [int] IDENTITY(1,1) NOT NULL, [DateKey] [datetime] NOT NULL, [StoreKey] [int] NOT NULL, [ProductKey] [int] NOT NULL, [PromotionKey] [int] NOT NULL, [CurrencyKey] [int] NOT NULL, [CustomerKey] [int] NOT NULL, [SalesOrderNumber] [nvarchar](20) NOT NULL, [SalesOrderLineNumber] [int] NULL, [SalesQuantity] [int] NOT NULL, [SalesAmount] [money] NOT NULL, [ReturnQuantity] [int] NOT NULL, [ReturnAmount] [money] NULL, [DiscountQuantity] [int] NULL, [DiscountAmount] [money] NULL, [TotalCost] [money] NOT NULL, [UnitCost] [money] NULL, [UnitPrice] [money] NULL, [ETLLoadID] [int] NULL, [LoadDate] [datetime] NULL, [UpdateDate] [datetime] NULL ) ON [PRIMARY] GO ALTER TABLE [dbo].[FactOnlineSalesNew] WITH CHECK ADD CONSTRAINT [FK_FactOnlineSalesNew_DimCurrency] FOREIGN KEY([CurrencyKey]) REFERENCES [dbo].[DimCurrency] ([CurrencyKey]) GO ALTER TABLE [dbo].[FactOnlineSalesNew] CHECK CONSTRAINT [FK_FactOnlineSalesNew_DimCurrency] GO ALTER TABLE [dbo].[FactOnlineSalesNew] WITH CHECK ADD CONSTRAINT [FK_FactOnlineSalesNew_DimCustomer] FOREIGN KEY([CustomerKey]) REFERENCES [dbo].[DimCustomer] ([CustomerKey]) GO ALTER TABLE [dbo].[FactOnlineSalesNew] CHECK CONSTRAINT [FK_FactOnlineSalesNew_DimCustomer] GO ALTER TABLE [dbo].[FactOnlineSalesNew] WITH CHECK ADD CONSTRAINT [FK_FactOnlineSalesNew_DimDate] FOREIGN KEY([DateKey]) REFERENCES [dbo].[DimDate] ([Datekey]) GO ALTER TABLE [dbo].[FactOnlineSalesNew] CHECK CONSTRAINT [FK_FactOnlineSalesNew_DimDate] GO ALTER TABLE [dbo].[FactOnlineSalesNew] WITH CHECK ADD CONSTRAINT [FK_FactOnlineSalesNew_DimProduct] FOREIGN KEY([ProductKey]) REFERENCES [dbo].[DimProduct] ([ProductKey]) GO ALTER TABLE [dbo].[FactOnlineSalesNew] CHECK CONSTRAINT [FK_FactOnlineSalesNew_DimProduct] GO ALTER TABLE [dbo].[FactOnlineSalesNew] WITH CHECK ADD CONSTRAINT [FK_FactOnlineSalesNew_DimPromotion] FOREIGN KEY([PromotionKey]) REFERENCES [dbo].[DimPromotion] ([PromotionKey]) GO ALTER TABLE [dbo].[FactOnlineSalesNew] CHECK CONSTRAINT [FK_FactOnlineSalesNew_DimPromotion] GO ALTER TABLE [dbo].[FactOnlineSalesNew] WITH CHECK ADD CONSTRAINT [FK_FactOnlineSalesNew_DimStore] FOREIGN KEY([StoreKey]) REFERENCES [dbo].[DimStore] ([StoreKey]) GO ALTER TABLE [dbo].[FactOnlineSalesNew] CHECK CONSTRAINT [FK_FactOnlineSalesNew_DimStore] GO
Measuring the impact of the inserts on the performance while switching ON / OFF the Accelerated Database Recovery:
SET STATISTICS TIME, IO ON; BEGIN TRAN INSERT INTO dbo.[customerNew] SELECT [c_custkey] ,[c_mktsegment] ,[c_nationkey] ,[c_name] ,[c_address] ,[c_phone] ,[c_acctbal] ,[c_comment] FROM [dbo].[customer]; ROLLBACK;
Here are the results that I have received after warm-ups and taking an average of the 10 consecutive executions:
– 3551 Milliseconds and 1879 Milliseconds for the traditional Recovery Process
– 6370 Milliseconds and 1 Milliseconds for the Accelerated Database Recovery
Again, for the wide tables it is not worth running the ADR, unless the cancelation have the highest priority and have a certain frequency, or one should accept that performance will be significantly lower for this type of operations.
SET STATISTICS TIME, IO ON; SET IDENTITY_INSERT dbo.FactOnlineSalesNew ON; BEGIN TRAN INSERT INTO [dbo].[FactOnlineSalesNew] ([OnlineSalesKey], [DateKey], [StoreKey], [ProductKey], [PromotionKey], [CurrencyKey], [CustomerKey], [SalesOrderNumber], [SalesOrderLineNumber], [SalesQuantity], [SalesAmount], [ReturnQuantity], [ReturnAmount], [DiscountQuantity], [DiscountAmount], [TotalCost], [UnitCost], [UnitPrice], [ETLLoadID], [LoadDate], [UpdateDate]) SELECT [OnlineSalesKey], [DateKey], [StoreKey], [ProductKey], [PromotionKey], [CurrencyKey], [CustomerKey], [SalesOrderNumber], [SalesOrderLineNumber], [SalesQuantity], [SalesAmount], [ReturnQuantity], [ReturnAmount], [DiscountQuantity], [DiscountAmount], [TotalCost], [UnitCost], [UnitPrice], [ETLLoadID], [LoadDate], [UpdateDate] FROM [dbo].[FactOnlineSales]; ROLLBACK; SET IDENTITY_INSERT dbo.FactOnlineSalesNew OFF;
After multiple passes of testing I have received the following results:
– 482.061 Milliseconds and 34.894 Milliseconds for the traditional Recovery Process
– 505.871 Milliseconds and 1 Milliseconds for the Accelerated Database Recovery
These results draw very similar picture to the original one where we had 8% decrease in the overall time spent on the UPDATE transaction, such as in this case for the insertion, where have lost around 5% of the overall time spent – a very acceptable amount of time for the majority of the non-critical workloads.
Forcing Cleanup Manually
One of the more important tasks for solving an ADR problem will definitely be the handling of the PVS behaviour and manually forcing of the cleanup process, described in the theoretical section, is a paramount for success. For this purpose we have a new system stored procedure, called sys.sp_persistent_version_cleanup that will allow us in a magical way (not explained and neither documented) to force the Background Cleaner to do the job of removing the obsolete Row-Version of the modified data.
How much it will change once SQL Server 2019 will go RTM is a very good question, since on-premises and IaaS currently contain heavier workloads then Azure (mostly because of the IO requirements in my experience) and the true impact on some of the bigger DWH will shine in the next months.
Currently for understanding we can call it right away with a default set of parameters, which to my understanding will do a limit scanning of the Persistent Version Store pages within the context of the Database where we have our ADR enabled:
EXECUTE sys.sp_persistent_version_cleanup;
The other option would be to invoke this Stored Procedure directly from the master database with the parameter specifying the name of the database as in
EXECUTE master.sys.sp_persistent_version_cleanup 'ContosoRetailDW';
The more interested option for me was looking at the parameters of this stored procedure:
@dbname sysname = NULL, — name of the database.
@scanallpages BIT = NULL, — whether to scan all pages in the database.
@clean_option int = NULL — clean up options
which brought me to understanding that in order to force a deeper scan of the PVS pages we can force the @scanallpages parameter to be equals to 1:
EXECUTE master.sys.sp_persistent_version_cleanup 'ContosoRetailDW', 1;
Executing this statement indeed takes a different amount of time, in my case it took instantly around 14 seconds (instead of just 1 second for the default invocation) just against a rather simple and plain database such as ContosoRetailDW.
The @clean_option parameter is rather an interesting thing and must be something that will allow to focus on the specific areas of the PVS. Wish this will be documented one day, though I do not hold my breath. :)
In any case this tool is just another hammer for your database nails ;)
Other Worthy Notes on ADR
– ADR is not compatible with Database Mirroring. I know, I know — it is deprecated and nobody should use it … Well :)
ADR is not compatible with System Databases. No surprise here I guess.
Explicit transactions with DBCC are not compatible with Accelerated Database Recovery. Well, I have never needed to put the DBCC CHECKDB or any other DBCC command in an explicit transaction, but I guess that this limitation won’t affect the majority of the DBCC users.
Azure SQL
A very interesting situation is to be faced on Microsoft PaaS offerings – Azure SQL Databases (Azure SQL Database, Azure SQL Database Hyperscale & Azure SQL Managed Instance) where for the eldest kids on the block (Azure SQL Database & Azure SQL Managed Instance) we have very well documented IO throughput limits, which will be very negatively impacted by the PVS. Given that I see enough customers successfully and some times not so-successfully running heavy IO-workloads against them, I wonder how much real improvements the ADR will bring. I guess that the write performance in a number of cases will be the burial ground for the attempts of making things work and where the advantages of the Accelerated Database Recovery won’t be THAT important if we are doing more writes then reads.
Given that Microsoft has enabled Accelerated Database Recovery on the Azure SQL Databases by default (and as you can read from the original whitepaper – one of the main goals of the project was improving the Azure availability and guarantee 99% of the disaster recoveries to be executed under 3 minutes – hence the Constant part in the Constant Time Recovery in Azure SQL Database, the original name of the ADR), I guess until all the scenarios are reviewed and bugs are fixed, there will be some cases where things will go wrong.
In the case of the Azure SQL Database Hyperscale the limitations of the write operations are less severe, and this is where on cloud PaaS offerings the true advantages can be taken, especially in the Business Critical tier where we can reach 5000 IOPS per vCore with 200,000 maximum IOPS currently.
I guess that the Accelerated Database Recovery will be a bigger friend of Azure SQL Database Hyperscale than of a Azure SQL Database & Azure SQL Managed Instance, well until Azure SQL Managed Instance will offer Hyperscale architecture at least.
Final Thoughts
It is very interesting to think where this feature can take us to. We have a potential of using the sLog for other purposes. There are so many different candidates that I really do not know where to start from – accelerating the overall write operations, doing pure In-Memory rollbacks on the Instances with huge amounts of memory (and maybe we could even control/tune sLog size one day), we could view previous versions of the data without restoring (just by reading the data from the PVS), we could preserve certain objects history longer then some others (like pin them to the PVS and protect them, because we need them recovering them with some frequency), tuning the Availability Group Secondaries to use as much of In-Memory Log as possible instead of the Transactional Log and so much more! I see this as a certain build-stones and not exactly as the final piece of the puzzle – hoping and expecting that in the next decade Microsoft will build on this feature success (and I have no doubt that this feature will be extremely successful).
I am also a kind of careful to think about unwarranted applications on Azure SQL Database and Azure SQL Managed Instances, where the performance could be tanked greatly, purely on the expectations – but hey, it will give more work to everyone in the end. :)
The same applies to the regular SQL Server installations, being it IaaS, on-premises VMs or non-virtualised installations – if you workload is already suffering from the IO bottlenecks and you do a lot of heavy updates against the wide tables you must be quite mindful about enabling the Accelerated Database Recovery.
I will softly remind you – avoid exaggerating with the wide tables … Would it be great if we could exclude some of the operations from the ADR, wouldn’t it ? :)
I am truly happy that this feature has got implemented, since in comparison to some other relational databases (Oracle, for example) the recovery process of SQL Server has never been something that most users and DBAs could be proud of, but now the game is starting to change and I truly hope that this is just the beginning of using and combining of some of the SQL Server technologies for the overall performance of the systems in any circumstances and heck – I am almost betting that one day we shall be looking on the In-Memory introduction in SQL Server as one of most hyped, disappointed and then again recovered moments of the SQL Server history.
Oh and once again – the real goal and win for the Accelerated Database Recovery lies on the Recovery side, not on the others write side of the transactions …
to be continued, since there are some interesting details I decide to put in a blog apart, avoiding to blow this one totally out of the proportion. :)
Hm, those overheads are tough. After having read the ADR paper I had hoped for a few percentage points of difference.
I guess what ADR buys you is not so much performance for expected and repeated cancellations. It buys you the safety that a certain class of downtime inducing conditions are categorically avoided. Failed database upgrades, mass operations or schema changes are common causes for downtime. These are hard to avoid through testing.
The live database can fairly easily trigger a rollback that a test would not catch. For example, due to a deadlock or due to larger or different data sets.
And in the end, almost all downtime is caused by human mistakes.
Hi tobi,
agreed on the topic of adquiring the guarantee for the unexpected downtimes. For the business critical workloads, it will be so easy to pay this cost, cause there is no alternative.
I guess that since Azure SQL Database has increased the availability SLA from 99.99% to 99.995% it has something to do with work of ADR, especially since ADR is already enabled by default on Azure, and there are some users who were negatively impacted by it.
Best regards,
Niko
Hi Niko,
Great post!
Is it enabled in Azure regardless the compatibility level of the database? And regardless the pricing level? Because, as you say IO is already a performance nightmare for the lower pricing tiers.
Finally, can it be disabled for those cases?
Thanks a lot for your time.
Best Regards
Hi Jaime,
Msg 40517, Level 16, State 1, Line 5
Keyword or statement option ‘accelerated_database_recovery’ is not supported in this version of SQL Server.
That’s what I get when trying to mess with ADR on Azure.
The reason is that improves the platform availability, and before trying it out I was sure that it would be possible to change … Well, apparently not…
I do not expect it to change in the future.
Best regards,
Niko Neugebauer
Yes, my impression was that they require it for the new Azure architecture. I was surprised to learn that they allow disabling ADR. Maybe they will force it on for everyone eventually. They surely don’t want to maintain two parallel internal architectures forever.
Hi tobi,
agreed.
I guess that what will be done is that ADR will simply become incompatible with the old features and nobody will be able to go back in the modern apps. This is a typical way of phasing out the features from Microsoft. Keeping feature for unreasonable amount of time is a speciality of Microsoft and I do not expect it to be different. The problem is fixable with a warning that you won’t get the expected SLA and no corporate manager will approve this step of loosing any percentage of SLA for other then very short amount of time – until the problem is fixed.
Best regards,
Niko
Sorry, crushing morning so I don’t have time to dig into the details you posted. But I have a number of questions/concerns to get out.
1) Everything in this version store would be transaction-log-causing activity, right? Meaning everything affected by that would receive a performance hit:
– log size/backups
– checkdb (gets hit by db size too)
– ALWAYS ON – meaning could get DELAYS FOR SYNCHRONOUS AG?!?
2) Clean-up of VS rows would also be logged? Double the above costs
3) Speaking of AGs, do they work at all, and if so why them and not database mirroring? AGs are glorified mirroring under the covers, right?
4) I have never, in over 50000 hours of working with SQL Server, come across a client (well over 100 total) where they did anywhere near enough transaction rollbacks to make paying the overhead on EVERY DML ACTION worth this benefit. Maybe I missed something in the benefits part where it would be more useful that I am envisioning it.
5) All this extra data writes will be lots of random IOPs, and in the cloud EVERY IOP is measured, counted, and METERED. Once you start requesting more than the 500IOPs/GB limit your volume has (also limited by numerous other factors), your IO starts to SLOW DOWN – eventually very dramatically so.
I will again acknowledge that I know very little about this feature at this point, and won’t for probably many years since my clients do not jump on the latest and greatest SQL Server version for MANY MANY reasons.
Thanks as always for your very well researched and written blog posts Niko. And I hope I get to see you in one or both of the upcoming Portugal SQL Saturday events – or maybe even Madrid this weekend!
Best,
Kevin G. Boles
SQL Server Consultant
SQL Server MVP 2007 – 2012
Indicium Resources, Inc.
@TheSQLGuru
Hi Kevin,
1. Yes.
2. Not sure yet. The second part of this blog post will hopefully address that.
3. AGs get some interesting improvement with ADR, since Row-Versioning is done in ADR and not on TempDB :)
4. Big ETL’s would be able to pay that. If you are rolling back for 10-12 hours, gosh how much some companies would love to pay to stop it.
5. Yeap.
As I wrote, I believe one of the main driver is the availability and predictability of the recovery times in Azure which results in higher SLA overall.
Sounds like a smart move to me. IO times will improve and if you look at other DB-Vendors, almost everyone is already or moving into this space.
Best regards,
Niko Neugebauer
Hi Niko,
thanks for the great article. We are currently upgrading from SQL Server 2016 to 2019 in a high-frequent OLTP AlwaysOn cluster with secondaries used for reporting, another cluster attached with Distributed AGs and RCSI enabled for all databases.
Does the overhead required for ADR “replace” the overhead for RCSI?
We were greatly suffering from version ghost records caused by the readable distributed secondary AG cluster. Hence we set the secondary cluster to not readable.
Our performance with RCSI enabled is very well, but will it suffer (more) with ADR enabled? Or will ADR benefits of the secondaries outweight its cost?
Hi Klaus,
In my expectation and experience, the workload overhead will not replace anything, but will serve as an addition – hence a detailed testing should be done before placing it in Production.
Best regards,
Niko