This blog post is a continuation in the little series about CosmosDB, that is started with the post CosmosDB: NoSQL, NoDBA & NoProblem? In this blog post I am going to research some common way of viewing about the default performance of the NoSQL database CosmosDB is vastly superior to the relational databases. I hear such phrases every given week around the world and online, and this view challenges me greatly – since it is so vague in the precise description of what is faster and why it is faster, and so I decided to set the record straight and put at least 1 workload to the test.
I have taken a rather simple file with the following structure with the following properties – date, description, lang & granularity (I have listed just 2 entries in the example below):
[
{"date": "-292", "description": "In\u00edcio da constru\u00e7\u00e3o do '''''colosso de Rodes''''' pelo escultor rodiano Car\u00e9s de Lindos.", "lang": "pt", "granularity": "year"},
{"date": "-280", "description": "T\u00e9rmino da constru\u00e7\u00e3o do '''colosso de Rodes''' \u2014 uma das '''''sete maravilhas do mundo antigo''''' \u2014 pelo escultor rodiano Car\u00e9s de Lindos.", "lang": "pt", "granularity": "year"}
]
Using the DocumentDB Data Migration Tool, I will try to upload this document into the collections of the CosmosDB and measure the performance.
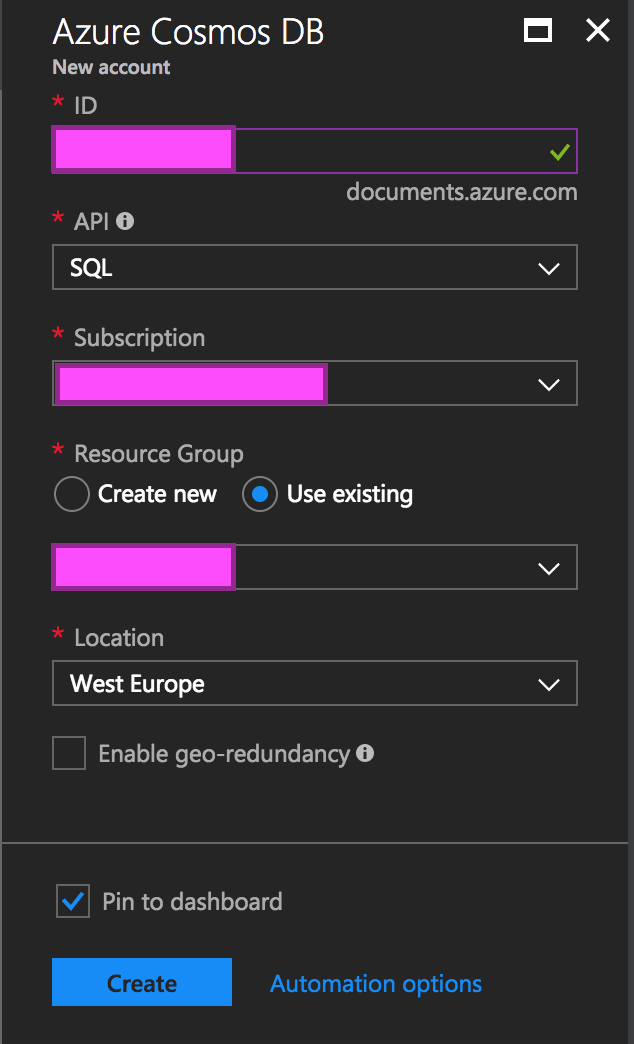
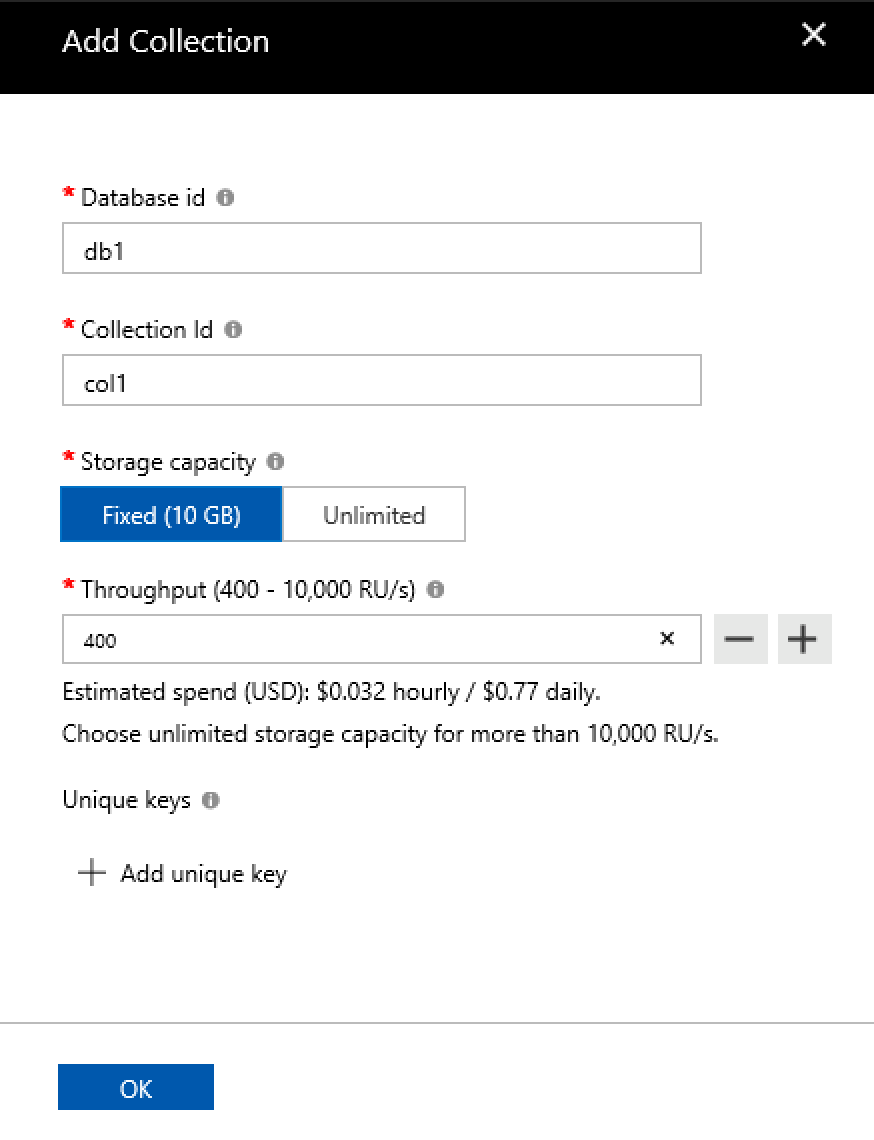
I have created a simple instance of the CosmosDB which will use a SQL API as you can see on the picture on the left side. After that I created a database db1 with a collection col1 with 400 RUs (Request Units) speed as you can see on the picture on the right. I have chosen 400 RUs for the start because this is the lowest and cheapest option available at the moment. This might not be the default option for anyone creating a new collection (the actual default is 1000 RUs), but I wanted to make sure that someone who is caring about the spent amount of money has some kind of a default.
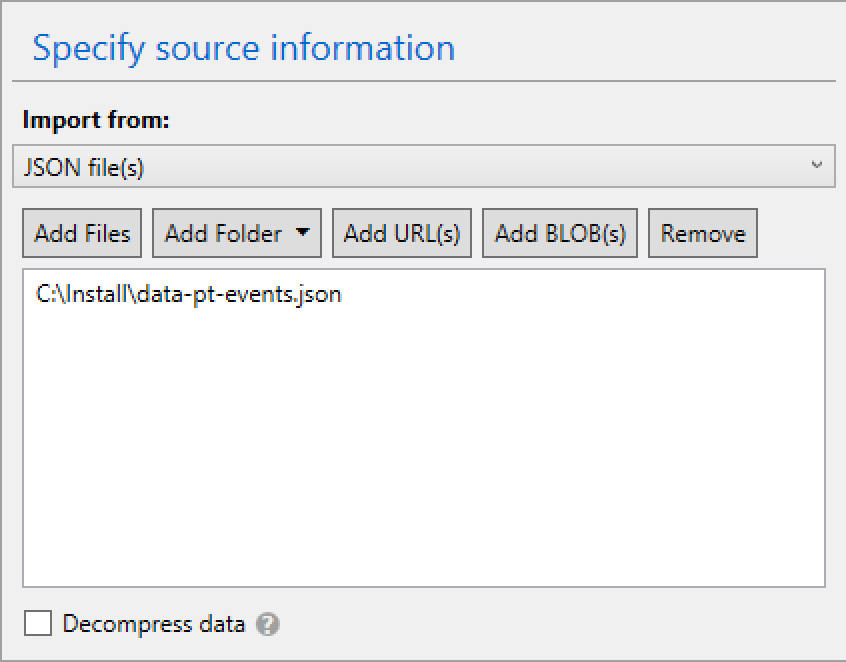 Using the default settings for the file and without changing any changes (I could change the default throughput but it had no real influence in my basic tests) I added the source file with historical events in the Portuguese language, advancing with the connection string and other needed settings I have started the upload and the import of my JSON information into the CosmosDB.
Using the default settings for the file and without changing any changes (I could change the default throughput but it had no real influence in my basic tests) I added the source file with historical events in the Portuguese language, advancing with the connection string and other needed settings I have started the upload and the import of my JSON information into the CosmosDB.
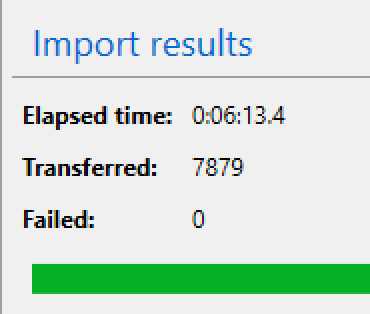 Without waiting too much time, my file was successfully imported into my CosmosDB collection. It took just 6 minutes and 13 seconds and this will serve as a baseline for my research.
Without waiting too much time, my file was successfully imported into my CosmosDB collection. It took just 6 minutes and 13 seconds and this will serve as a baseline for my research.
 Upgrading the throughput to the maximum available value currently, which is 10.000 RUs is easy and absolutely brilliantly in Cosmos DB and it takes place in a matter of seconds – almost like a Resource Governor change. The thing I found pretty disappointing is that it is impossible to change the currently defined API from SQL to MongoDB or GraphDB. I understand that the underlying meta-structures are difficult to change, but given that the flexibility of the JSON I am wondering what could be the problem – after all there should not be any constraints for NoSQL – those are the things of the relational world.
Upgrading the throughput to the maximum available value currently, which is 10.000 RUs is easy and absolutely brilliantly in Cosmos DB and it takes place in a matter of seconds – almost like a Resource Governor change. The thing I found pretty disappointing is that it is impossible to change the currently defined API from SQL to MongoDB or GraphDB. I understand that the underlying meta-structures are difficult to change, but given that the flexibility of the JSON I am wondering what could be the problem – after all there should not be any constraints for NoSQL – those are the things of the relational world.
 I decided to tune a couple of settings to obtain better results (such as Collection Throughput) and after a couple of attempts, I was able to reach a good time of 2 minutes and 5 seconds, which after all represents a 3 times improvement. Not a linear thing, of course, but a very significant improvement, in my opinion. There must be some kind of contention (id generation? persistence level? indexing? I guess I will have to take it to the test in one of the next blog post of the series).
I decided to tune a couple of settings to obtain better results (such as Collection Throughput) and after a couple of attempts, I was able to reach a good time of 2 minutes and 5 seconds, which after all represents a 3 times improvement. Not a linear thing, of course, but a very significant improvement, in my opinion. There must be some kind of contention (id generation? persistence level? indexing? I guess I will have to take it to the test in one of the next blog post of the series).
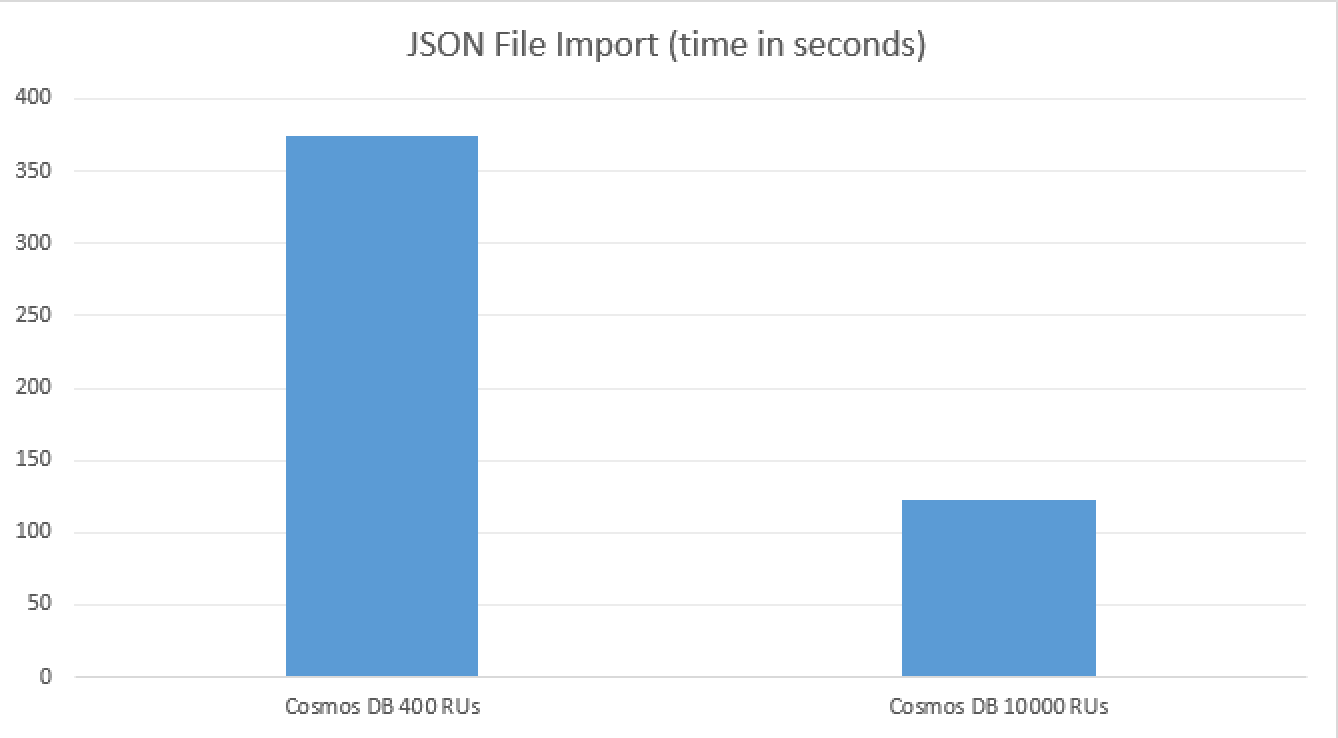
For your visual pleasure, here is a chart visualisation of the respective performance of the collection while importing my test file.
By this moment you are naturally asking how big was my test file. Oh, that’s easy – 1.6 MB. Yes, this is 1.6 MB meaning 1.6 Megabytes as well as ca. 1600 Kilobytes.
And so to optimise the load process, I decided to challenge Azure SQL Database and for this purpose what is better to choose as the most comparable basic tier:
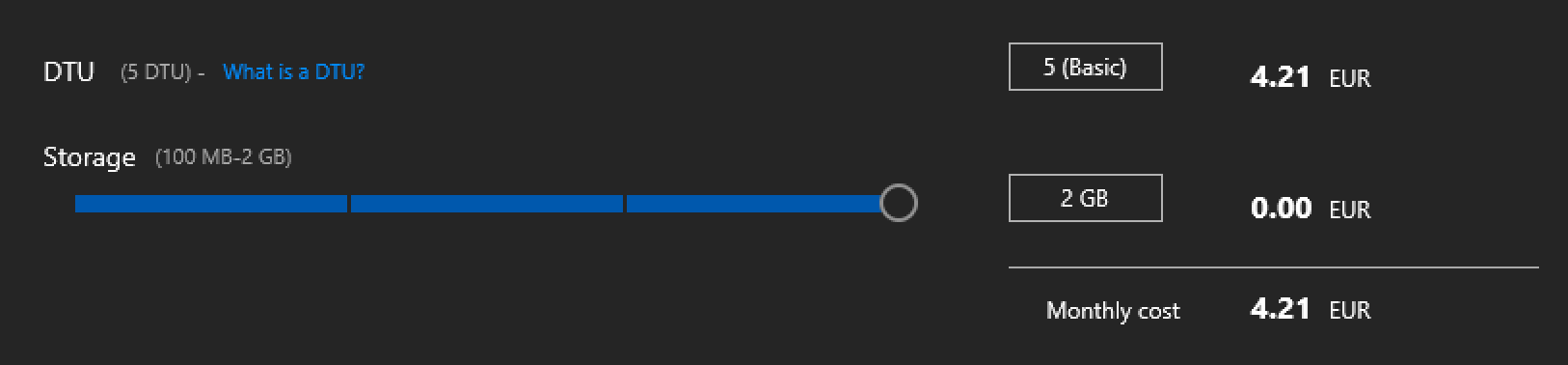
I recon that the comparison is not very fair, because of the Azure SQL Database incredible scalability, API support (well, it actually truly supports 2 additional languages in the on-premises version, but hey – Cosmos DB has no such version, so I am unable to do a true comparison), upgradability (think Azure SQL DW if you go into the Large TB & Petabytes areas), etc – but I thought that monthly price of 4.21 EUR PER MONTH would be a good challenge for the start. Yes, I know Cosmos DB is significantly more expensive with 576 EUR per month in the 10.000 RUs version, but hey – I wanted to start somewhere, and I do understand that this blog post represents a very partial testing – just the data loading of a particular random schema.
I keep on asking myself what is wrong that I am doing to obtain such a huge difference in the results …
Here is a limited script that I have used to test the import … The real one with 1.6 MB takes around 6 seconds to load, but this one takes 9 milliseconds on average in my tests.
SET STATISTICS TIME, IO ON
DROP TABLE IF EXISTS dbo.T1;
CREATE TABLE dbo.t1( c1 NVARCHAR(MAX) );
INSERT INTO dbo.t1 (c1)
values ('[ {"date": "-292", "description": "In\u00edcio da constru\u00e7\u00e3o do ''''''''''colosso de Rodes'''''''''' pelo escultor rodiano Car\u00e9s de Lindos.", "lang": "pt", "granularity": "year"}, {"date": "-280", "description": "T\u00e9rmino da constru\u00e7\u00e3o do ''''''colosso de Rodes'''''' \u2014 uma das ''''''''''sete maravilhas do mundo antigo'''''''''' \u2014 pelo escultor rodiano Car\u00e9s de Lindos.", "lang": "pt", "granularity": "year"} ]');
A tough comparison must be made on the data loading side and you can see the visualisation below:
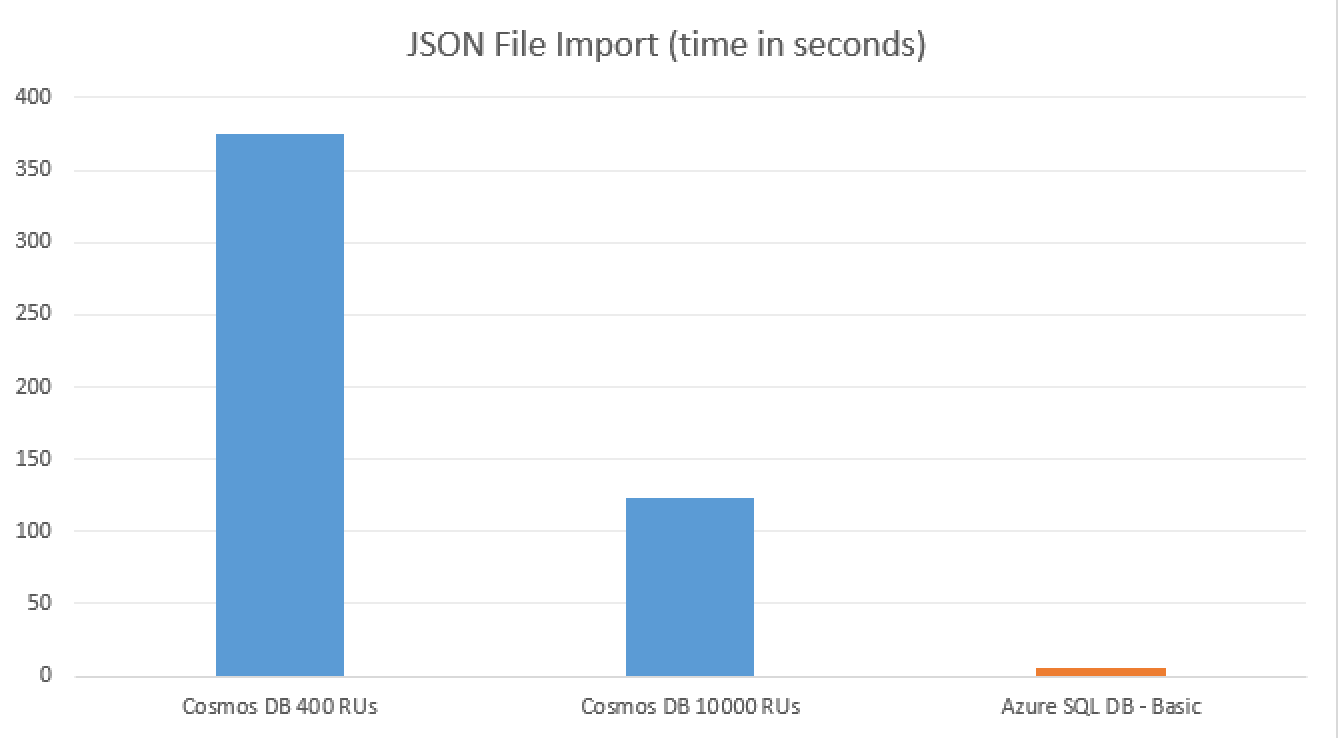
I did not tried to fork or fake anything. I had luck/bad luck of selecting some schema where I obtain these concrete results.
UPDATE on 12th of March 2018
On 8th of March I tested successfully loading of the sample 1.6 MB data file from the Azure Blob Storage to my sample test database with the script presented below (notice that the credentials, storage account are replaced with some random content, you will need to use your own) :
CREATE MASTER KEY ENCRYPTION BY PASSWORD = '123LetThisDatabase2B@'; GO SET STATISTICS TIME, IO ON DROP TABLE IF EXISTS dbo.T1; CREATE TABLE dbo.t1( [date] varchar(10) not null, [description] nvarchar(500) NOT NULL, [lang] char(2) NOT NULL, [granularity] varchar(20) NOT NULL ); DROP EXTERNAL DATA SOURCE MyAzureBlobStorage; DROP DATABASE SCOPED CREDENTIAL MyAzureBlobStorageCredential; CREATE DATABASE SCOPED CREDENTIAL MyAzureBlobStorageCredential WITH IDENTITY = 'SHARED ACCESS SIGNATURE', SECRET = '?sv=2017-07-29&ss=bfqt&srt=sco&sp=rwdlacup&se=2018-05-09T03:53:39Z&st=2018-03-01T19:53:39Z&spr=https&sig=NikosSecret123'; CREATE EXTERNAL DATA SOURCE MyAzureBlobStorage WITH ( TYPE = BLOB_STORAGE, LOCATION = 'https://nikoscosmostests.blob.core.windows.net' ); INSERT INTO dbo.t1 SELECT events.* FROM OPENROWSET (BULK 'json/data-pt-events.json', DATA_SOURCE = 'MyAzureBlobStorage', SINGLE_CLOB) as j CROSS APPLY OPENJSON(BulkColumn) WITH( [date] varchar(10), [description] nvarchar(500), [lang] char(2) , [granularity] varchar(20)) AS events;
The average duration of the BULK Load was around 5 seconds, actually faster then the original script – I believe it has to do with the network latency that my local VM was experiencing in the original tests.
Final Thoughts
I guess you will not believe it, but the dataset that I used for this test was actually the 2nd JSON dataset I played my hands on. I am not qualified to judge how common this scenario is, but it is what it is – you will not be able to influence the format of your data 100% of the time, and going with the flow of the common misconception can be quite an expensive option.
I know that indexing and querying are missing, but I will look at them at the later point.
My glass is not always full.
Well, to be more precise my glass is pretty fool. :)
to be continued …
I know that you are trying to make a fair comparison, but I cannot fully agree with your test approach. I’m not familiar with CosmosDB import tool, but it seems to me that you are comparing an import tool in CosmosDB with the T-SQL script in Azure SQL Db, which might be unfair comparison.
I assume that CosmosDB import tool has some overhead to the prepare data, read data from the file, spends some time on connectivity (like BCP in SQL database), while in T-SQL case you just placed JSON inline in the query, so it might not be the same.
Maybe you can compare CosmosDB import tool with BCP, which have the same overhead, to get some more reliable results. Here is my old post about importing JSON via BULK INSERT and you can reuse some of the code in BCP case (probably you would need the format file): https://blogs.msdn.microsoft.com/sqlserverstorageengine/2016/03/23/loading-line-delimited-json-files-in-sql-server-2016/
Also, you might contact someone in CosmosDb to check is the import tool properly configured, just to be sure that everything is fair. Again, I’m not an expert, but the difference looks strange.
Thanks,
Jovan
Hi Jovan,
actually my initial tests were performing even faster on the BCP import from the Azure Blob Storage:
SQL Server Execution Times:
CPU time = 32 ms, elapsed time = 5005 ms.
I will update the post.
Best regards,
Niko
Maybe the 2min Cosmos DB import run was all network latency. If each of the 7000 rows does a round trip the numbers might work out.
Improbable, I have repeated this test from the Azure VM within the same region.
The original results were obtained already in November of the last year, and so this is definitely not a temporary problem.
The interesting thing is that after 1 Min and 10 Seconds it seems that CosmosDB is digesting the data because Import counter stops at the right number of rows.
Best regards,
Niko
Then I agree with those numbers. Not so hot.