Continuation from the previous 105 parts, the whole series can be found at https://www.nikoport.com/columnstore/.
One of the most important and recurring topics for any type of indices is their Building/Rebuilding/Reorganzing processes – after all we do load more data into our tables and we want all of the bits to be compressed and optimised to the maximum. Previously I have extensively blogged on these topics in Columnstore Indexes – part 16 (“Index Builds”), Columnstore Indexes – part 33 (“A Tuple Mover that closes open Delta-Stores”) & Columnstore Indexes – part 96 (“Nonclustered Columnstore Index Online Rebuild”) between others, and I have been very vocal over the years saying that “Columnstore Indexes are hungry beasts, they WILL eat every bit of resources they can touch and in order to get them under control one needs to be using Resource Governor“. Naturally since Service Pack 1 for SQL Server 2016, we can use use Columnstore Indexes in any edition of SQL Server, we can’t have Resource Governor for Standard or Express Editions, and actually the limitations of the Columnstore Indexes in lower editions will prevent some serious resource consumption problems.
I always wanted to do a proper comparison between different ways of compressing freshly loaded data into Columnstore Indexes (hey, there are real reasons for that), and after a great discussion at SQLBits with Ola Hallengren & Sunil Agarwal, I was motivated to write a blog post on this matter. Using currently the latest available Cumulative Update (CU 3) for SQL Server 2016 with Service Pack 1, I have decided to restore my standard basic test database ContosoRetailDW and do all the usual stuff for making it perform well on the tests:
USE [master]
alter database ContosoRetailDW
set SINGLE_USER WITH ROLLBACK IMMEDIATE;
RESTORE DATABASE [ContosoRetailDW]
FROM DISK = N'C:\Install\ContosoRetailDW.bak' WITH FILE = 1,
MOVE N'ContosoRetailDW2.0' TO N'C:\Data\ContosoRetailDW.mdf',
MOVE N'ContosoRetailDW2.0_log' TO N'C:\Data\ContosoRetailDW.ldf',
NOUNLOAD, STATS = 5;
alter database ContosoRetailDW
set MULTI_USER;
GO
ALTER DATABASE [ContosoRetailDW] SET COMPATIBILITY_LEVEL = 130
GO
ALTER DATABASE [ContosoRetailDW] MODIFY FILE ( NAME = N'ContosoRetailDW2.0', SIZE = 2000000KB , FILEGROWTH = 128000KB )
GO
ALTER DATABASE [ContosoRetailDW] MODIFY FILE ( NAME = N'ContosoRetailDW2.0_log', SIZE = 400000KB , FILEGROWTH = 256000KB )
GO
use ContosoRetailDW;
-- Drop the Primary Key from the FactOnlineSales table
ALTER TABLE dbo.[FactOnlineSales] DROP CONSTRAINT [PK_FactOnlineSales_SalesKey];
-- Create Clustered Columnstreo Index on the FactOnlineSales table
create clustered columnstore Index PK_FactOnlineSales
on dbo.FactOnlineSales;
I decided to something rather basic and trivial: to create a new table with Clustered Columnstore Index, load 2 million rows into it without using Bulk Load Api (thus making sure we shall have 2 Delta-Stores (1 open and 1 closed) and then compress those Delta-Stores into compressed Row Groups by invoking ALTER INDEX … REORGANIZE and ALTER TABLE … REBUILD commands, while measuring the required resources.
For the setup part, here is the script creating a new table FactOnlineSales_ReIndex with a Clustered Columnstore Index, and loading in a primitive way 20 times the same 100.000 rows, making the total number of rows 2 million within our new table:
USE [ContosoRetailDW] GO DROP TABLE IF EXISTS dbo.FactOnlineSales_Reindex; CREATE TABLE [dbo].[FactOnlineSales_Reindex]( [OnlineSalesKey] [int] NOT NULL, [DateKey] [datetime] NOT NULL, [StoreKey] [int] NOT NULL, [ProductKey] [int] NOT NULL, [PromotionKey] [int] NOT NULL, [CurrencyKey] [int] NOT NULL, [CustomerKey] [int] NOT NULL, [SalesOrderNumber] [nvarchar](20) NOT NULL, [SalesOrderLineNumber] [int] NULL, [SalesQuantity] [int] NOT NULL, [SalesAmount] [money] NOT NULL, [ReturnQuantity] [int] NOT NULL, [ReturnAmount] [money] NULL, [DiscountQuantity] [int] NULL, [DiscountAmount] [money] NULL, [TotalCost] [money] NOT NULL, [UnitCost] [money] NULL, [UnitPrice] [money] NULL, [ETLLoadID] [int] NULL, [LoadDate] [datetime] NULL, [UpdateDate] [datetime] NULL, INDEX CCI_FactOnlineSales_Reindex CLUSTERED COLUMNSTORE ); SET NOCOUNT ON DECLARE @i as INT = 0; DECLARE @offset as INT = 0; WHILE @i < 20 BEGIN set @offset = @i * 100000; INSERT INTO dbo.FactOnlineSales_Reindex WITH (TABLOCK) (OnlineSalesKey, DateKey, StoreKey, ProductKey, PromotionKey, CurrencyKey, CustomerKey, SalesOrderNumber, SalesOrderLineNumber, SalesQuantity, SalesAmount, ReturnQuantity, ReturnAmount, DiscountQuantity, DiscountAmount, TotalCost, UnitCost, UnitPrice, ETLLoadID, LoadDate, UpdateDate) SELECT TOP 100000 OnlineSalesKey, DateKey, StoreKey, ProductKey, PromotionKey, CurrencyKey, CustomerKey, SalesOrderNumber, SalesOrderLineNumber, SalesQuantity, SalesAmount, ReturnQuantity, ReturnAmount, DiscountQuantity, DiscountAmount, TotalCost, UnitCost, UnitPrice, ETLLoadID, LoadDate, UpdateDate FROM dbo.FactOnlineSales SET @i = @i + 1; END
As for Virtual Machine for the tests, naturally I am using Azure and for the initial test I decided to use DS2_V2 Standard Virtual Machine, currently having 2 cores and 7GB of RAM.
First, for the test I have run the following command, forcing closure and compression of all Delta-Stores (open or closed ones):
alter index [CCI_FactOnlineSales_Reindex] on dbo.FactOnlineSales_Reindex reorganize WITH (COMPRESS_ALL_ROW_GROUPS = ON);
For measuring the memory granted I have used a simple query against the sys.dm_exec_query_memory_grants DMV, in the other window of the Management Studio, while the respective REORGANIZE command was running:
SELECT cast(requested_memory_kb / 1024. as Decimal(9,2)) as RequestedMemoryMB ,cast(granted_memory_kb / 1024. as Decimal(9,2)) as GrantedMemoryMB ,cast(required_memory_kb / 1024. as Decimal(9,2)) as RequiredMemoryMB ,cast(used_memory_kb / 1024. as Decimal(9,2)) as UsedMemoryMB ,cast(max_used_memory_kb / 1024. as Decimal(9,2)) as MaxUsedMemoryMB FROM sys.dm_exec_query_memory_grants;

For the 7 GB of RAM that were available for the SQL Server, the operation with ALTER INDEX ... REORGANIZE took acquired around 800 MB, showing a very hungry behaviour, as expected, but my thoughts were - this is nothing special, not even 25% of the available Buffer Pool - as far as I am concerned. What about a complete Rebuild process with ALTER INDEX ... REBUILD command, that one should be definitely more costly!
So once again, I executed the setup script, and this time I ran the following command:
alter index [CCI_FactOnlineSales_Reindex] on dbo.FactOnlineSales_Reindex Rebuild;

Well, this is getting quite interesting, isn't it ? For rebuilding the table with the same amount of information we have acquired just 511MB, while using essentially the same quantity of memory. You can see on the picture below how big the difference between those 2 methods is, and if you have a brand new table where you load the data, you should have no doubts about the suggested methods for the small VMs using a couple of million rows - the REBUILD performs with the same speed while requiring significantly less memory.
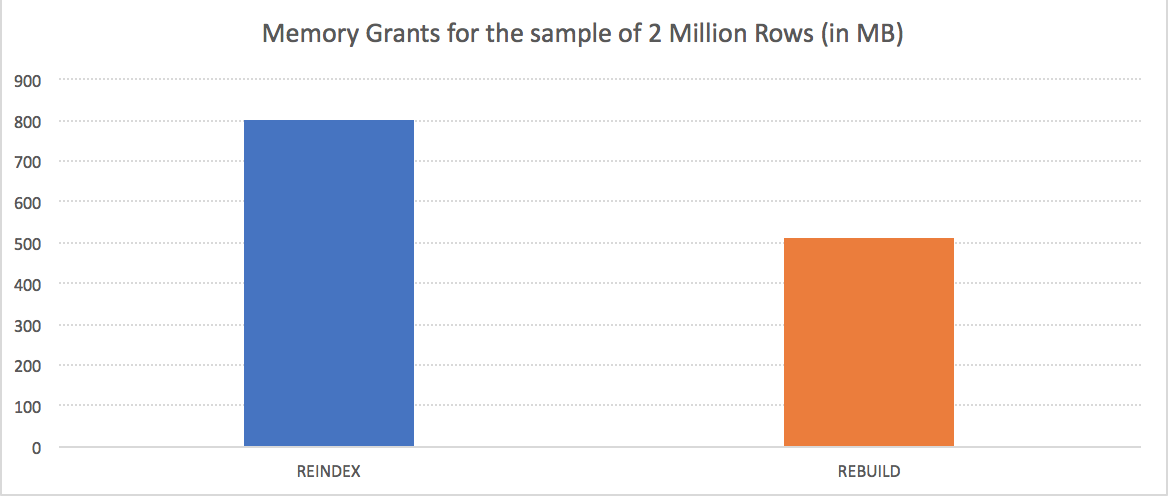
To spare all the Wows & how can's, Microsoft was well aware of this problem and has delivered a solution with Cumulative Update 3 for SQL Server 2016 with Service Pack 1:
FIX: SQL Server 2016 consumes more memory when you reorganize a columnstore index, and here it is - a new trace flag 6404 (documented in the link and thus should be supported), that will allow you to lower the memory requirements for the ALTER INDEX ... REORGANIZE command.
Let's take it for the test, by once again running the setup workload for the FactOnlineSales_Reindex table and then executing the following command, enabling the Trace Flag 6404 and then reorganising our Clustered Columnstore Index:
DBCC TRACEON (6404) alter index [CCI_FactOnlineSales_Reindex] on dbo.FactOnlineSales_Reindex reorganize WITH (COMPRESS_ALL_ROW_GROUPS = ON);
Sampling the information from the sys.dm_exec_query_memory_grants DMV, will give us the following information:
SELECT cast(requested_memory_kb / 1024. as Decimal(9,2)) as RequestedMemoryMB ,cast(granted_memory_kb / 1024. as Decimal(9,2)) as GrantedMemoryMB ,cast(required_memory_kb / 1024. as Decimal(9,2)) as RequiredMemoryMB ,cast(used_memory_kb / 1024. as Decimal(9,2)) as UsedMemoryMB ,cast(max_used_memory_kb / 1024. as Decimal(9,2)) as MaxUsedMemoryMB FROM sys.dm_exec_query_memory_grants;
![]()
This time the ALTER INDEX ... REORGANIZE command went to grab just 733MB of memory, which is around 10% less than the original memory request. This is a quite an important improvement, allowing you to have more workloads running at the same time, but judging by the current results - going REBUILD on similar scenarios should be the weapon of choice!

This is quite an interesting discovery, but the real question that you should be asking is how does this scales on bigger Virtual Machines with more memory - and so let us dive into those scenarios!
For this purpose I decided to scale my virtual machine to the DS12_V2 with 28GB of RAM, DS13_V2 with 56GB of RAM and DS14_V2 with 112GB of RAM:

plus I decided to include to include the VM Standard DS11_V2 with 14GB of RAM to have a more complete picture of the development of the memory grants.
After running multiple workloads on those VM for multiple times, I have seen the following numbers that are represented on the graph below:

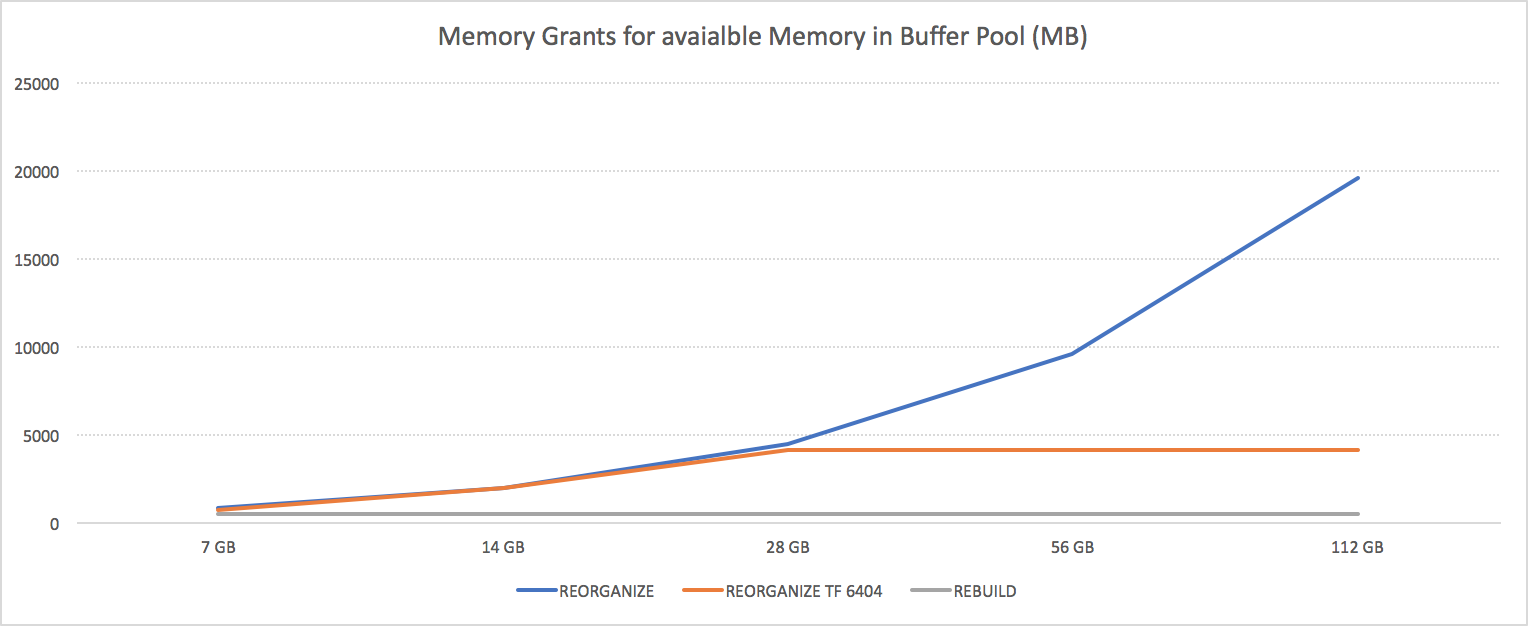
Essentially the Trace Flag introduces a cap on the acquired amount of memory, with smaller machines with around 16GB of memory being capped on 2GB while bigger ones are simply cut on 4GB.
Think about this trace flag as a switch that you can enable, if your system is suffering under huge memory grants in parallel, and please, do not think about this trace flag as a magic voodoo thing that solves all problem of the universe, because it might bring you some problems as well.
Final Thoughts
I agree with the Microsoft decision of not making this change to be the default right now, it will definitely shift a lot of things around - should it be enabled by default. Your system will need to do some serious testing, to understand the impact it will bring.
Think about other aspect of this change, if you have a pretty wide table with hundreds of columns & trying to cap the max amount of memory granted for this process will trim your Row Groups (read Columnstore Indexes – part 31 (“Memory Pressure and Row Group Sizes”) for more information), which might not be the thing you are looking to do.
In any case after reading this article I am sure you will understand why ALTER INDEX ... REORGANIZE does not look attractive by default for all cases,
but keep in my mind that it still holds the candle for the Clustered Columnstore Index because while being ONLINE process, a REBUILD is still an offline one (note that for SQL Server 2017 the Nonclustered Columnstore Index can be rebuilt online).
I will call this as a short term fix, because I believe that we need a more flexible algorithm to adapt to the memory requirements, without capping on some certain number (2GB or 4GB) or stealing 25% of the Buffer Pool.
I am excited to see the improvements but I am definitely hoping to see a more adaptive algorithm in the future.
to be continued with Columnstore Indexes – part 107 (“Dictionaries Deeper Dive”)
Greetings Niko,
Please can you point me on the right direction as to where can I find the implications of turning the traceflag 6404 always ON with our PROD. environment???
Do you have any comments on this permanent traceflag ON???
thanks
Hi João,
I recommend using this trace flag on the individual thread-basis,
while monitoring the size of the row groups, because if your table is very wide (hundreds of columns) you will need bigger memory requirements than TF 6404 gives, thus trimming the Row Groups potentially.
I suggest using Resource Governor and limit the amount of memory available for the maintenance procedures – this is how I avoid the problems.
Best regards,
Niko
Thanks a lot for the clear reply!