Continuation from the previous 54 parts, the whole series can be found at https://www.nikoport.com/columnstore/
The architectural changes in the upcoming SQL Server 2016 are bringing some very important & long-awaited improvements for the complete Columnstore Indexes architecture in Microsoft SQL Server.
These changes can be divided in 3 main parts:
– Clustered Columnstore Indexes supporting Nonclustered Indexes
– Rowstore Table (Heap or Clustered) supporting Updatable Nonclustered Columnstore Indexes
– InMemory Table supporting Updatable Columnstore Indexes
The first element in each of the part’s description is the basis and the driving force for the architectural changes, because from this point on we can talk about further architectural differences between Clustered Columnstore Indexes and Nonclustered Columnstore Indexes.
Clustered Columnstore Indexes supporting Nonclustered Indexes
 If you remember the old Whitepaper from SigMod 2013, you will find the mentions of supporting bookmark lookup, which would serve for the efficient equality and short-range searches.
If you remember the old Whitepaper from SigMod 2013, you will find the mentions of supporting bookmark lookup, which would serve for the efficient equality and short-range searches.
Clustered Columnstore Indexes serve as a great base for the DataWarehouse solutions and are recommended Microsoft to be used by default for the Fact Tables, and they will provide amazing performance for the scan operations. One of the places where their performance will not be as good as for the Rowstore Indexes is exactly the short-range & equality searches.
As already mentioned in the Columnstore Indexes – part 54 (“Thoughts on upcoming improvements in SQL Server 2016″), Clustered Columnstore Indexes are getting support for the multiple Rowstore Nonclustered b-tree Indexes and this improvement is promising to improve the performance for the lookup and short-range scan operations.
There are other improvements in this area as well, but most importantly at this point is to check the overall architecture changes for Clustered Columnstore Indexes.
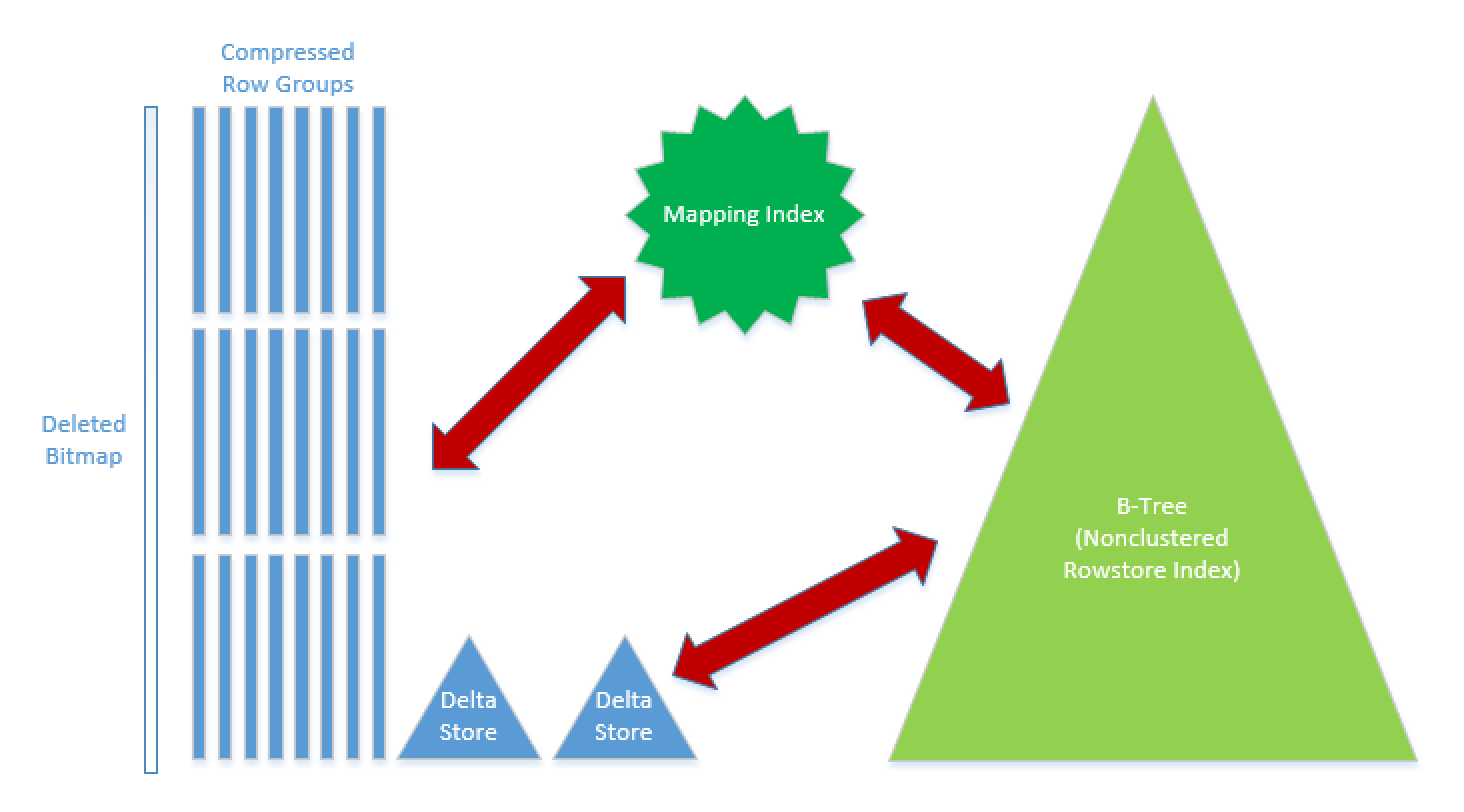
If you look at the picture provided above, you will find a number of already known elements, such as Row Groups, Deleted Bitmap & Delta-Stores – they provide necessary functionality for all basic data manipulation operations. What is new on the picture are the b-tree indexes (just 1 is presented on the right side, marked with Lime Green color), which will be providing support for the lookup operations.
The key element in this new architecture is the internal structure, called Mapping Index – which will perform all synchronisation duties between Clustered Columnstore Indexes and the b-tree Rowstore Indexes.
This Mapping Index is a structure that marked in the Green Color in the center of the image, and is a hidden element of the Clustered Columnstore Indexes architecture. We can observe it in the sys.internal_partitions DMV.
Mapping Index is a mapping table connecting the location of the row in the Row Group with the corresponding data in the B-tree index. It contains the location (Row Group Id:position) of the particular row, connecting it with the row through the RowId which serves as a reference for the B-Tree indexes.
What is the advantage of the maintaining such a structure ? Every time we are moving a row from one Row Group to another (Row Groups Merge operation through Alter Index … Reorganize, for example), we do not have to update every single Index with a new location of the row, but in just 1 place – in the Mapping Index.
The Mapping Index of course will increase the amount of information to be processed that a query connecting B-Tree & Columnstore Index will have to work on, but that’s a minor increase given the advantages of every internal row moving inside the Row Groups operation.
Rowstore Table (Heap or Clustered) supporting Updatable Nonclustered Columnstore Indexes
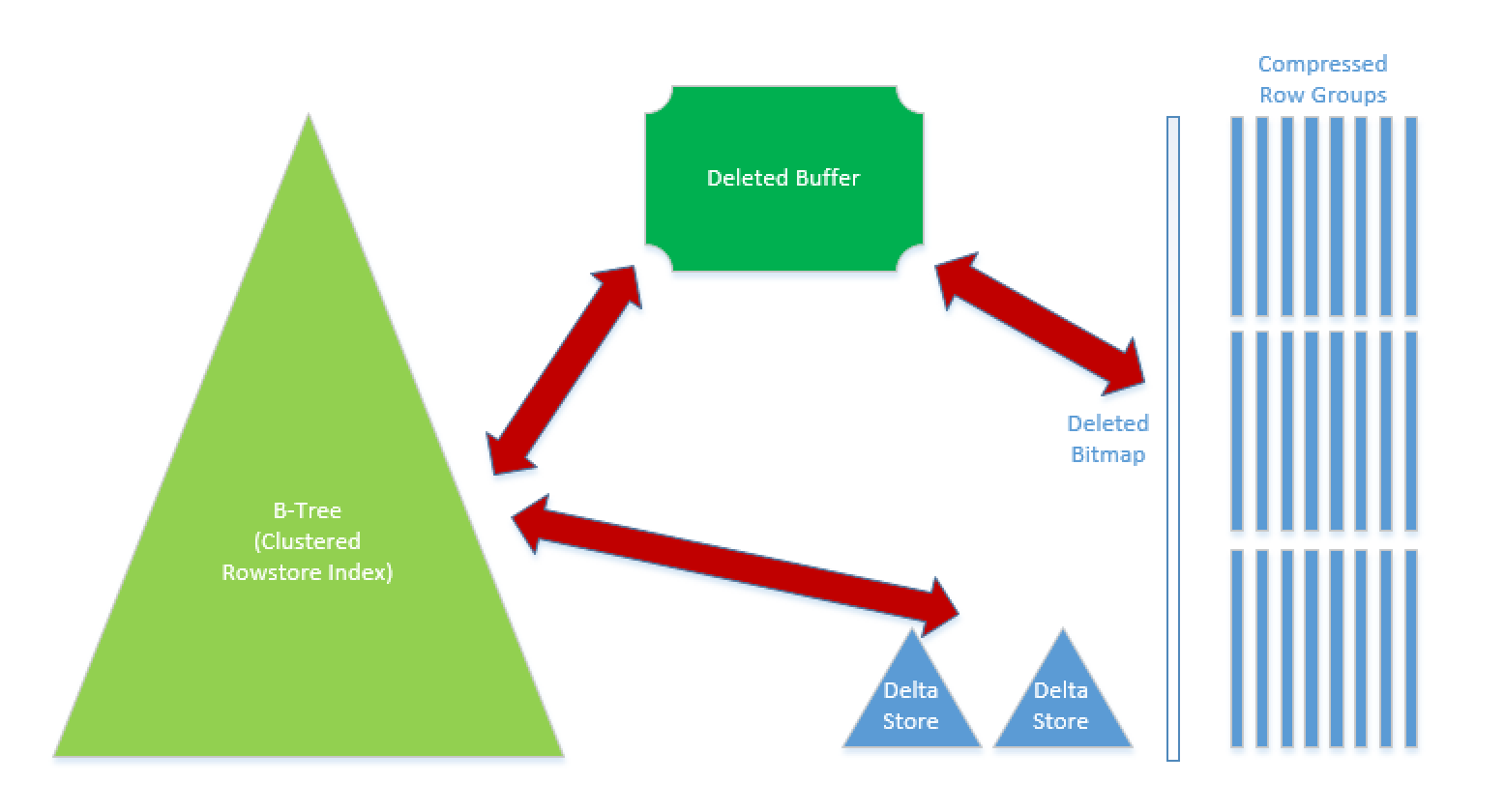 In the case of the base table being defined as a Rowstore HEAP or Rowstore Clustered Table, we can build an updatable Nonclustered Columnstore Index on a selection of the base columns.
In the case of the base table being defined as a Rowstore HEAP or Rowstore Clustered Table, we can build an updatable Nonclustered Columnstore Index on a selection of the base columns.
The new architecture element here is the Deleted Buffer, which serves a support synchronisation element between base Rowstore table and updatable Nonclustered Columnstore Index. This Deleted Buffer will contain index rows that were already deleted/updated from base Rowstore but were not yet copied into Deleted Bitmap of the updatable Nonclustered Columnstore Index.
The synchronisation process is performed by our good old friend Tuple Mover, which is now capable of doing whole necessary management of Deleted Buffers, such as synchronise, merge, truncate and flush information from it.
The advantage that Deleted Buffer brings is that it alleviates from the potential synchronisation pressure that the Btree structure of the traditional Rowstore Indexes suffers while updating the Columnstore Indexes with transactional operations such as Insert, Update & Delete. While performing these operations the query engine will not touch on the Columnstore Deleted Bitmap, because seeking the rows inside of the Deleted Bitmap might imply a very big delay in confirming the Online Transaction. Instead we are just storing the reference of the row that was affected inside the compressed Segments, minimising the
And if we are affecting the Deleted Buffer just once (even with a big number of transactions), the engine might just scan the Deleted Bitmap structure once, synchronising this information in just 1 step, which would lower the overall impact on the system.
Information on the current state of the Deleted Buffers can be found in sys.internal_partitions DMV, which will be described in the next blog post of this series.
InMemory Table supporting Updatable Columnstore Indexes

The current implementation of the combination of the InMemoryOLTP table with Columnstore Indexes brings a number of interesting details. First of all, the only Columnstore Index that we can create on InMemory table is the Clustered Columnstore Index. This is very, very, very bad and I hope that this is just a CTP2 limitation, because otherwise we shall be battling with some very regular and unavoidable Dictionary & maybe even Memory problems. For DataWarehousing, for the Fact tables we should be able to avoid them, but I do not see people rewriting their Operational tables in order to get better reporting very easily.
Secondly, there is a direct connection between InMemory table and Columnstore Index, meaning that all new data is coming into the Tail Row Group, where it will be stored, until a special process will compress this hot data into the Columnstore Index. On my tests I have easily loaded 1.5 Million Rows into a Tail Row Group (open Delta-Store), which would never be possible in SQL Server 2014. The frequency of this process compression is something that happens on the data in chunks of 1 million rows that weren’t changed in the passed hour, which will lower impact on so-called Hot Data(operational data that is being constantly updated).
I have found a new stored procedure sys.sp_memory_optimized_cs_migration which should migrate data from the Tail Row Group into the compressed Row Groups, make sure that you are invoking the version from the local database and not from the master DB, since any attempts on referring directly to master provoked an error message in my tests.
The other big change is the presence of the Deleted Row Table(aka DRT), which will function in a similar way like our good old friend Deleted Bitmap. Whenever we modify or delete a row for InMemory OLTP base table, we shall store the Columnstore RowId of the obsolete(modified) row in the Deleted Row Table.
Of course the existence of the Deleted Row Table will imply that whenever we scan our Columnstore Index, before proceeding to the next Execuplan Plan Iterator, we shall need to merge the filtered information with the Deleted Row Table, which will definitely negatively impact the overall performance of the Columnstore Indexes, but I expect to be a minor thing, given that all this information stays in memory all the time and that there must be some kind of the performance optimisations (bitmap filtering for example?), that are implemented in order to lower the negative impact.
I suspect that this is not a 100% complete picture, so this blog post might get updated in the nearest future.
to be continued with Columnstore Indexes – part 56 (“New DMV’s in SQL Server 2016”)
This looks good. The NC CS index is a no-brainer to use. I expect it to become a common perf tip to create such an index in case there are any DW-style queries on that table at all. This will be about the first thing I’ll attempt once I get 2016 in production.
The clustered one probably requires more work at the potential reward of saving a lot of space.
The In-memory stuff was so alpha in 2014 that I doubt it will be complete enough to be anywhere near a “no-brainer” in 2016.
Hi Mark,
>This looks good. The NC CS index is a no-brainer to use. I expect it to become a common perf tip to create such an index in case
>there are any DW-style queries on that table at all. This will be about the first thing I’ll attempt once I get 2016 in production.
:)
>The In-memory stuff was so alpha in 2014 that I doubt it will be complete enough to be anywhere near a “no-brainer” in 2016.
All my experiences so far show it to be extremely rough. I do not expect it to be stable for the general usage, before a couple of Cumulative Updates.
Plus I think that SQL Server 2018 (?) will be bringing the surface close enough that there will be real projects migrating to InMemory without major hustles, so I do not expect 2016 InMemory Operational Analytics to be overly successful. :)