Continuation from the previous 47 parts, starting from https://www.nikoport.com/2013/07/05/clustered-columnstore-indexes-part-1-intro/
This post is dedicated to one of the most complex problems in Columnstore Indexes – the Internal Pressure within the Columnstore Dictionaries, that makes Row Groups being cut off with number of rows much smaller than the maximum allowed one (1045678 rows).
This problem itself was very well described by the great Sunil Agarwal.
I will use his problem script as a basis for improving the Dictionary Pressure Problem. Basically I am creating here a table with 5 columns (including 1 character & 1 variable character ones), then loading 1.1 Million Rows into it.
IF OBJECT_ID('dbo.Pressure', 'U') IS NOT NULL
DROP TABLE dbo.Pressure;
CREATE TABLE dbo.Pressure (
c1 int NOT NULL,
c2 INT NOT NULL,
c3 char(40) NOT NULL,
c4 varchar(800) NOT NULL,
c5 int not null
);
set nocount on
declare @outerloop int = 0
declare @i int = 0
while (@outerloop < 1100000)
begin
Select @i = 0
begin tran
while (@i < 2000)
begin
insert dbo.Pressure values (@i + @outerloop, @i + @outerloop, 'a',
concat (CONVERT(varchar, @i + @outerloop), (replicate ('b', 750)))
,ABS(CHECKSUM(NewId())) % 2000000 )
set @i += 1;
end
commit
set @outerloop = @outerloop + @i
set @i = 0
end
go
The catch here is that I am loading a lot of similar textual data into the column c3, reaching almost the maximum length of for the column (which is 800 bytes). Whenever we shall use Columnstore Index, the internal algorithm shall start creating a lot of entries in the Dictionaries, rapidly developing into the direction of the maximum allowed Columnstore Dictionary Size (16 MB), thus creating the Dictionary Pressure.
Create Clustered Columnstore Index CCI_Pressure on dbo.Pressure with (maxdop = 1);
Notice that in this case it does not really matter how many CPU cores I shall use, since the pressure comes not from the memory usage but from the Columnstore Dictionary.
Let's check the Row Groups to see if there is any potential problem:
select partition_number, row_group_id, total_rows, size_in_bytes
from sys.column_store_row_groups
where object_id = object_id('dbo.Pressure')
order by row_group_id
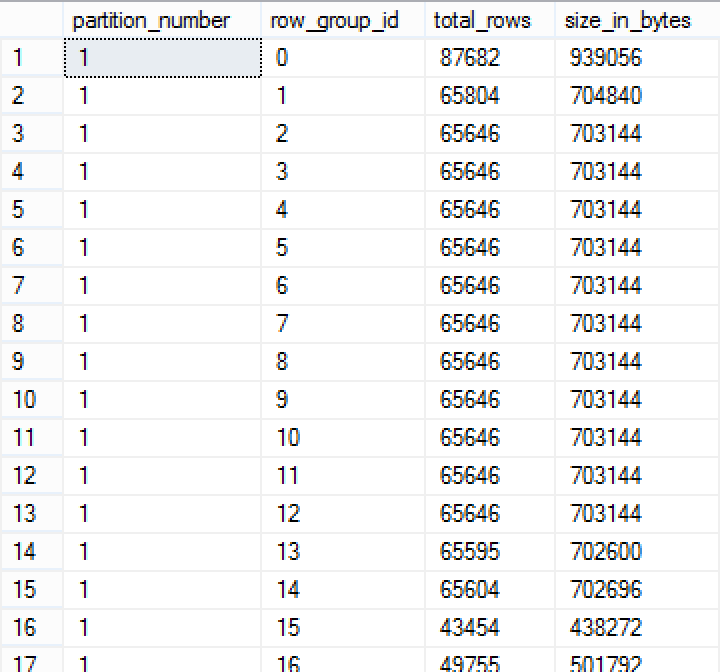 As you can see, the total number of rows per row group is nowhere near the maximum values, with the highest available belonging to the very first one and in my case it is capped at 87.682 rows. The total number of rows is 1.1 Million, which means that instead of the current 16 Row Groups in the ideal case we should have just 2 Row Groups, but we are not in the ideal world and some internal pressure has made the Columnstore Engine to create 16 different Row Groups.
As you can see, the total number of rows per row group is nowhere near the maximum values, with the highest available belonging to the very first one and in my case it is capped at 87.682 rows. The total number of rows is 1.1 Million, which means that instead of the current 16 Row Groups in the ideal case we should have just 2 Row Groups, but we are not in the ideal world and some internal pressure has made the Columnstore Engine to create 16 different Row Groups.
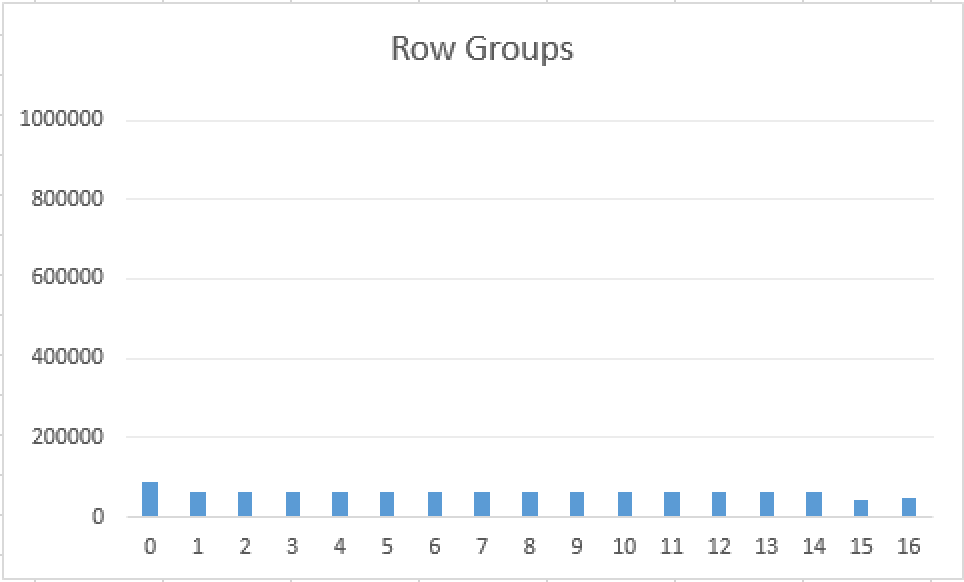
As you can see on the accompanying picture, the distribution of the row groups on the scale with maximum allowed value is quite a scary one - it does not reach even a 10% of what it should be. Having a lot of small Row Groups in most situations shall lead to worse performance, since there will be much more information needing to be analysed and processed before touching on the actual data.
To make sure that the problem was with the Dictionary Pressure, we shall have to consult the sys.column_store_dictionaries DMV to see what sizes the respective dictionaries are:
select column_id, dictionary_id, entry_count, on_disk_size
from sys.column_store_dictionaries dict
inner join sys.partitions p
ON dict.hobt_id = p.hobt_id
where object_id = object_id('dbo.Pressure')
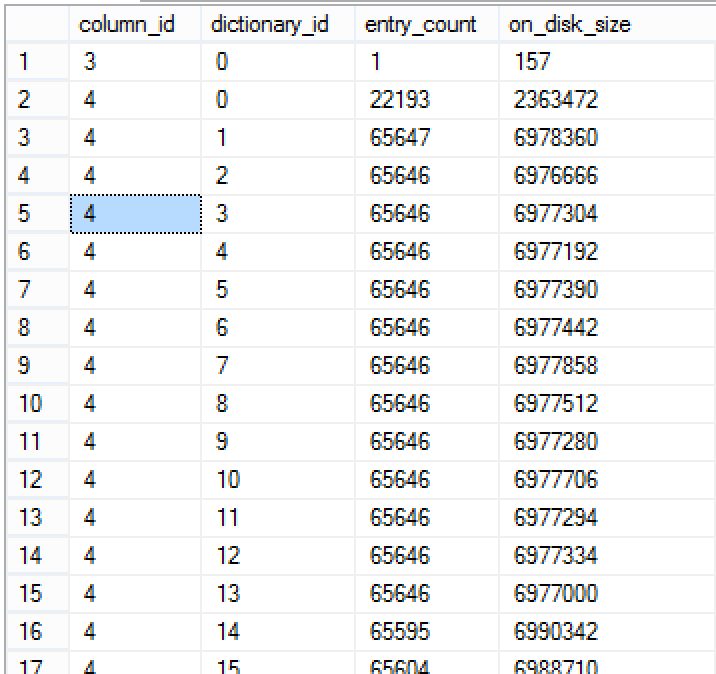 Looking at the sizes of the dictionaries, one might get surprised that the publicly announced limit of 16MB is nowhere near the actual values, which are not even reaching 7MB. I wish that there would be an easier way to determine Dictionary Pressure after the rebuild process (Notice that we can still determine it with the help of Extended Events, as I have shown in Clustered Columnstore Indexes – part 47 (“Practical Monitoring with Extended Events”)),
Looking at the sizes of the dictionaries, one might get surprised that the publicly announced limit of 16MB is nowhere near the actual values, which are not even reaching 7MB. I wish that there would be an easier way to determine Dictionary Pressure after the rebuild process (Notice that we can still determine it with the help of Extended Events, as I have shown in Clustered Columnstore Indexes – part 47 (“Practical Monitoring with Extended Events”)),
but right now there is no way to do it besides analysing all available data.
At the moment of writing of this article, in Azure SQLDatabase contains a couple of new DMV's that might hold interesting information in the future, but at the moment that is all there is.
To see which Segment is using which dictionary we can use the following query:
select column_id, segment_id, primary_dictionary_id, secondary_dictionary_id, row_count, on_disk_size
from sys.column_store_segments seg
inner join sys.partitions p
ON seg.hobt_id = p.hobt_id
where object_id = object_id('dbo.Pressure')
and (primary_dictionary_id <> -1 or
secondary_dictionary_id <> -1 )
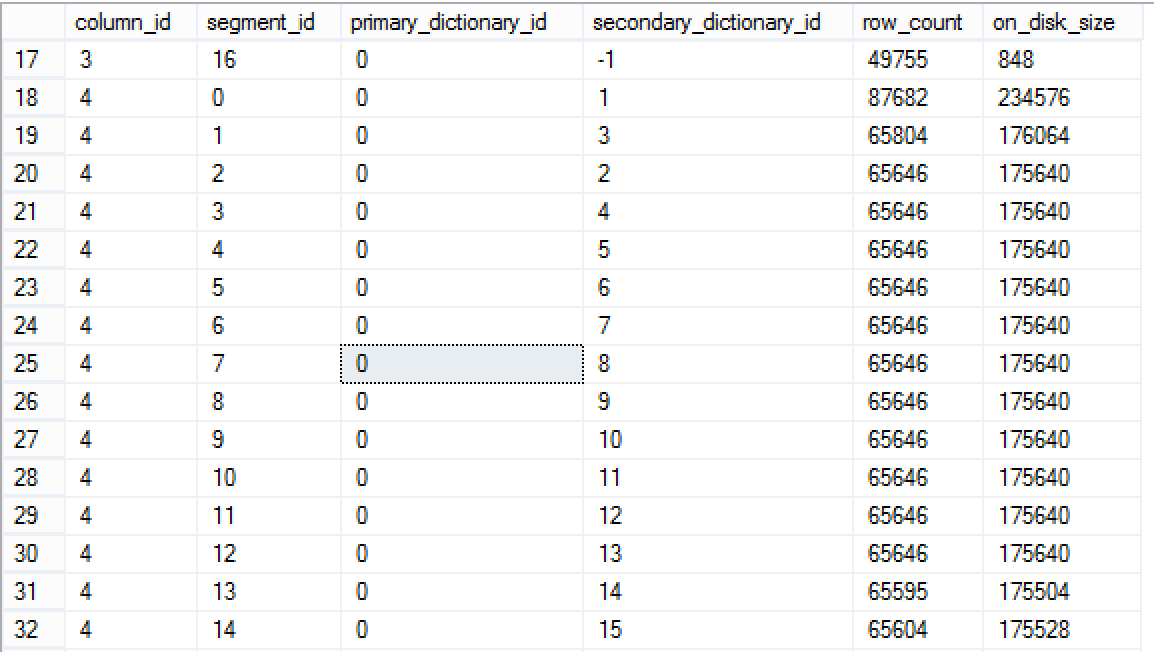 We can find out that every single Segment for the column 4 (Varchar(800)) is using both dictionaries, which means that the Global Dictionary might be actually the source of the Dictionary pressure, even though its size is not even reaching 2.5 MB.
We can find out that every single Segment for the column 4 (Varchar(800)) is using both dictionaries, which means that the Global Dictionary might be actually the source of the Dictionary pressure, even though its size is not even reaching 2.5 MB.
At this point I am guessing more than having any kind of proof, because I have seen enough cases with dictionaries reaching for 16MB and that clearly explains the Dictionary Pressure, but in this case I am guessing that the Dictionary Entry Length has something important to do with it, and until Microsoft reveals more information about the internal limits, the only thing to do here is to test, test & test.
The Improvement idea
The key thought to find an improvement for a lot of problems is understanding the problem. The dictionary pressure arises in our case because of the size problem of the Columnstore Dictionaries, and so to improve it - we need to make sure that we do not reach those limits.
The most obvious solution is the partitioning, because as I have shown a number of times before, every partition is actually an independent Columnstore Structure.
The best idea here would be simply to create a separate partition for each part of the Columnstore Table which is suffering Dictionary Pressure, thus alleviating the whole table and distributing the pressure between different partitions, each one having its own unique Global Dictionary.
For this purpose I have developed a script that in this demo case, simply splits whole table into a number of partitions that will reach the maximum number of rows that Columnstore Engine will allow us. This number is easily visible from the Row Group with the maximum number of rows - in my case it is a Row Group with id = 0, which has 87862 rows.
Since I know that data is evenly distributed, I can calculate the number of different partitions that I need = 1.100.000 rows / 87.862 rows in a row group ~= 12.51 => 13 Partitions.
The following script will print a generated script for adding 13 new FileGroups with 13 new Database Files in total:
declare @tsql as nvarchar(4000); declare @partitions as nvarchar(4000) = ''; declare @filegroups as nvarchar(4000) = ''; declare @i as int = 1; declare @maxFG as int = 13; while @i <= @maxFG begin set @tsql = 'alter database Columnstore_Play add filegroup fg' + cast(@i as varchar(2)) + '; GO'; print @tsql; set @tsql = 'alter database Columnstore_Play add file ( NAME = ''f' + cast(@i as varchar(2)) + ''', FILENAME = ''C:\Data\f' + cast(@i as varchar(2)) + '.ndf'', SIZE = 10MB, FILEGROWTH = 10MB ) to Filegroup [fg' + cast(@i as varchar(2)) + '] GO'; print @tsql; if( @i <> @maxFG ) set @partitions += ',' + cast((1100000/@maxFG * @i ) as nvarchar(20)); --if( @i <> @maxFG ) set @filegroups += ', fg' + cast((@i ) as nvarchar(20)); set @i += 1; end print 'create partition function pfIntPart (int) AS RANGE RIGHT FOR VALUES ( ' + stuff(@partitions,1,1,'') + ' ); GO ' print 'create partition scheme ColumstorePartitioning AS PARTITION pfIntPart TO ( ' + stuff(@filegroups,1,1,'') + ' );'
The advantage from this code is that it gives you a version for review and editing before applying it on the database.
After executing the script creating FileGroups and Files I will drop the existing Clustered Columnstore Index and create a required RowStore Index on the partitions, substituting it in the next step with a Clustered Columnstore Index:
Drop Index CCI_Pressure on dbo.Pressure;
-- Create RowStore Index, aligned to the partitions
Create Clustered Index CCI_Pressure
on dbo.Pressure (c1)
with (DATA_COMPRESSION = PAGE)
ON ColumstorePartitioning (c1);
-- Create Partitioned Clustered Columnstore Index
Create Clustered Columnstore Index CCI_Pressure on dbo.Pressure
with (DROP_EXISTING = ON)
ON ColumstorePartitioning (c1)
Now let us take a look what kind of structure we have created:
select partition_number, row_group_id, total_rows, size_in_bytes
from sys.column_store_row_groups
where object_id = object_id('dbo.Pressure')
order by row_group_id
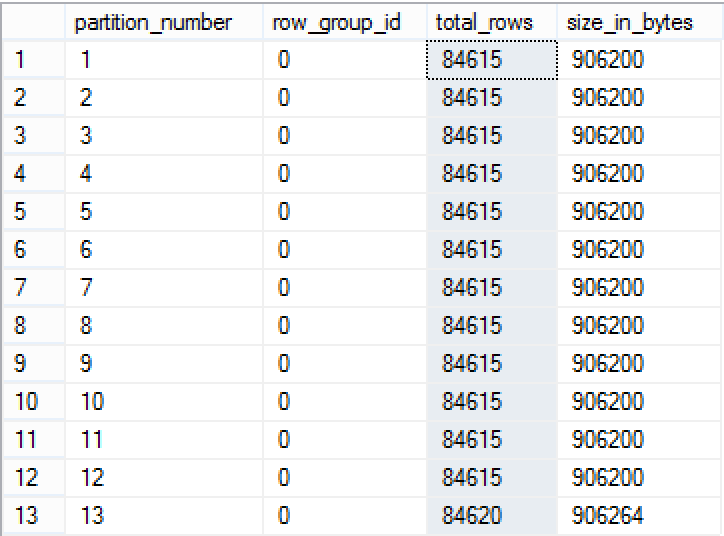 We have decreased the total number of Row Groups from 17 to 13 (the number of partitions), which is great! :) and every single Row Group has around 84.615 rows, with the last Row Group having some additional 5 rows.
We have decreased the total number of Row Groups from 17 to 13 (the number of partitions), which is great! :) and every single Row Group has around 84.615 rows, with the last Row Group having some additional 5 rows.
The total size of the Global Dictionaries has multiplied by the number of the partitions that we have created and overall for the structure it might occupy more space, and so this question should be carefully researched before applied in production, but this technic allowed me to optimise 4 Segments out of 17, which represents almost 25% improvement, and the balanced size of each of the segment will allow me to have a better processing by multiple cores, since they are dealing with very comparable sizes of Row Groups.
I have actually measured the final difference in numbers and the occupied space has actually grown by 616KB, which by the total size of ~130MB this does not even reach 0.5%, and so can be tolerated in my current case.
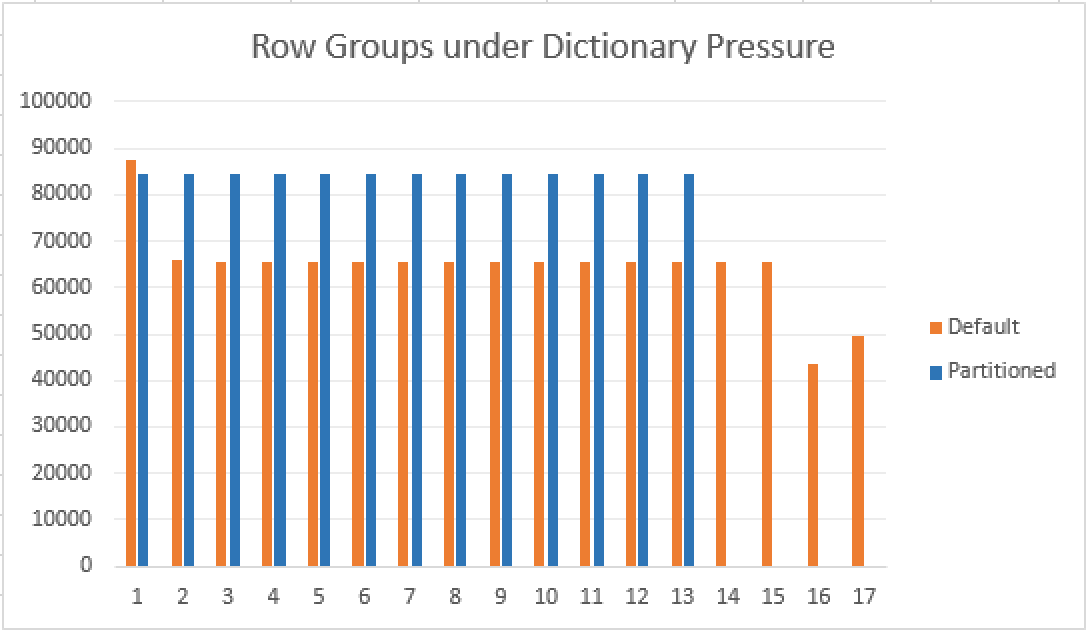 You can see the comparison that I did for this quite trivial situation. In the real world, you will see a number of times when some particular Row Groups will have very low number of rows, following by Row Groups with high number of rows, and getting them into a balance is one of the things that can be done by using smart partitioning.
You can see the comparison that I did for this quite trivial situation. In the real world, you will see a number of times when some particular Row Groups will have very low number of rows, following by Row Groups with high number of rows, and getting them into a balance is one of the things that can be done by using smart partitioning.
The final thoughts
One might object that partitioning can't be used to solve all the problems of the world, and that the number of partitions in SQL Server is not unlimited.
This is very correct, but doing a concrete math: 15.000 partitions * 84.000 rows (for example) = 1.260.000.000 Rows to manage in a single table. Yes, that means over 1 billion rows. :)
Notice that you do not have to partition exactly the Row Groups that are not facing any Dictionary Problems, thus combining different technics whenever it is necessary.
Important addition on the Sorting Matters
I have seen situations where Sorting Table on a different column can remove the Dictionary Pressure, but as the consequence a number of very small Row Groups would appear in the middle of the Columnstore Structure, plus this technic is not viable whenever one is trying to get the best possible Segment Elimination on the column that is really being used in most of the queries on the system.
If I find some good cases to show, I will definitely blog about them in the future.
to be continued with Clustered Columnstore Indexes – part 49 (“Data Types & Predicate Pushdown”)
another excellent deep dive into columnstore
thanx, Niko
Hi Andreas,
thank you for the kind words :)
Best regards,
Niko
Boy do I hate how uncontrollable CS indexes are. Needing to play tricks like these is a testament to design flaws in the product.
Hi Mark,
these are the rougher edges of the limit cases of the product,
generally speaking it is extremely fine without any tricks.
I am also extremely confident in the improvements that the Team is putting into it, just compare SQL 2012 & SQL 2014. :)