Continuation from the previous 13 parts, starting from https://www.nikoport.com/2013/07/05/clustered-columnstore-indexes-part-1-intro/
Lets play with partitioning this time! Get the Contoso BI Database, plug it in and lets start playing! :)
We will be working with the FactOnlineSales table – first we need to drop all the relevant Primary and Foreign Keys:
ALTER TABLE dbo.[FactOnlineSales] DROP CONSTRAINT [PK_FactOnlineSales_SalesKey] ALTER TABLE dbo.[FactOnlineSales] DROP CONSTRAINT [FK_FactOnlineSales_DimCurrency] ALTER TABLE dbo.[FactOnlineSales] DROP CONSTRAINT [FK_FactOnlineSales_DimCustomer] ALTER TABLE dbo.[FactOnlineSales] DROP CONSTRAINT [FK_FactOnlineSales_DimDate] ALTER TABLE dbo.[FactOnlineSales] DROP CONSTRAINT [FK_FactOnlineSales_DimProduct] ALTER TABLE dbo.[FactOnlineSales] DROP CONSTRAINT [FK_FactOnlineSales_DimPromotion] ALTER TABLE dbo.[FactOnlineSales] DROP CONSTRAINT [FK_FactOnlineSales_DimStore]
Now let us setup all the stuff necessary for the partitioning (note, that I expect you to pre-allocate your Primary FileGroup and T-Log sizes and growth, and since they are basic items, which are not the topic of this blogpost, I do not write about them.
I add 4 new Filegroups with each one containing 1 file to our Contoso BI Database – the names of those filegroups reflect their purpose (1st one is for the archival data which happened before the 2007, and then the filegroups for each of the years with 2009 containing the data for the 2009+ years. Then I created a new partitioning function and a new partitioning scheme, which is mapping the partitioning function to the respective filegroups.
-- Add 4 new filegroups to our database
alter database ContosoRetailDW
add filegroup OldColumnstoreData;
GO
alter database ContosoRetailDW
add filegroup Columnstore2007;
GO
alter database ContosoRetailDW
add filegroup Columnstore2008;
GO
alter database ContosoRetailDW
add filegroup Columnstore2009;
GO
-- Add 1 datafile to each of the respective filegroups
alter database ContosoRetailDW
add file
(
NAME = 'old_data',
FILENAME = 'C:\Data\MSSQL\DATA\old_data.ndf',
SIZE = 10MB,
FILEGROWTH = 125MB
) to Filegroup [OldColumnstoreData];
GO
alter database ContosoRetailDW
add file
(
NAME = '2007_data',
FILENAME = 'C:\Data\MSSQL\DATA\2007_data.ndf',
SIZE = 500MB,
FILEGROWTH = 125MB
) TO Filegroup Columnstore2007;
GO
alter database ContosoRetailDW
add file
(
NAME = '2008_data',
FILENAME = 'C:\Data\MSSQL\DATA\2008_data.ndf',
SIZE = 500MB,
FILEGROWTH = 125MB
) to Filegroup Columnstore2008;
GO
alter database ContosoRetailDW
add file
(
NAME = '2009_data',
FILENAME = 'C:\Data\MSSQL\DATA\2009_data.ndf',
SIZE = 500MB,
FILEGROWTH = 125MB
) TO Filegroup Columnstore2009;
GO
-- Create the Partitioning scheme
create partition function pfOnlineSalesDate (datetime)
AS RANGE RIGHT FOR VALUES ('2007-01-01', '2008-01-01', '2009-01-01');
-- Define the partitioning function for it, which will be mapping data to each of the corresponding filegroups
create partition scheme ColumstorePartitioning
AS PARTITION pfOnlineSalesDate
TO ( OldColumnstoreData, Columnstore2007, Columnstore2008, Columnstore2009 );
Now that we have everything set up, lets try to create our Clustered Columnstore Index by using the partitioning scheme that we have just created:
Create Clustered Columnstore Index PK_FactOnlineSales on dbo.FactOnlineSales ON ColumstorePartitioning (DateKey);
Msg 35316, Level 16, State 1, Line 1
CREATE INDEX statement failed because a columnstore index must be partition-aligned with the base table. Create the columnstore index using the same partition function and same (or equivalent) partition scheme as the base table. If the base table is not partitioned, create a nonpartitioned columnstore index.
Say what ? Does it mean that we have to create a partitioning for the traditional clustered index before we advance for creating partitioning for the clustered Columnstore index ? That might make enough sense for a Nonclustered Columnstore, but this is gibberish when we are talking about the Clustered Columnstore Index. Yes, things are working exactly this way and we shall have to accept it, especially since the partition alignment is a kind of an important topic from a lot of different angles, especially in the future when the nonclustered traditional indexes should become available for the tables with Clustered Columnstore Index.
Before advancing with creation of a traditional clustered index on the FactOnlineSales table, I thought that it would be a good idea to have some measures of comparison with a non-partitioned Clustered Columnstore Index and so I took up some statistics from the principal DMV’s available – sys.column_store_row_groups, since I believe (and I have confirmed) that the algorithm is stable between partitioned and non-partitioned tables, and the only thing which interests me at the moment is the compression results:
Create Clustered Columnstore Index PK_FactOnlineSales on dbo.FactOnlineSales;
So I took off the statistics from the above mentioned DMV and decided to move on with creation of a traditional clustered index on the FactOnlineSales table and then we should be able to finally create our own partitioned clustered columnstore index:
-- Drop our Clustered Non-partitioned Columnstore Index, because we can't recreate directly for this set of options (which is a bug, if you ask me).
drop Index PK_FactOnlineSales on dbo.FactOnlineSales;
-- Creation of a traditional Clustered Index
Create Clustered Index PK_FactOnlineSales
on dbo.FactOnlineSales (DateKey)
ON ColumstorePartitioning (DateKey);
-- Create Partitioned Clustered Columnstore Index
Create Clustered Columnstore Index PK_FactOnlineSales on dbo.FactOnlineSales
with (DROP_EXISTING = ON)
ON ColumstorePartitioning (DateKey);
Here is the graphic which speaks for itself, you can see the difference in number of Segments and accordingly the space occupied between Non-Partitioned and Partitioned Clustered Columnstore Indexes:

Knowing Clustered Columnstore behaviour a little bit, I decided to go and rebuild the Partitioned Clustered Columnstore Index a couple more times, and here are the graphic results of the results that I was able to obtain, while using the command:
alter Index PK_FactOnlineSales on dbo.FactOnlineSales REBUILD;
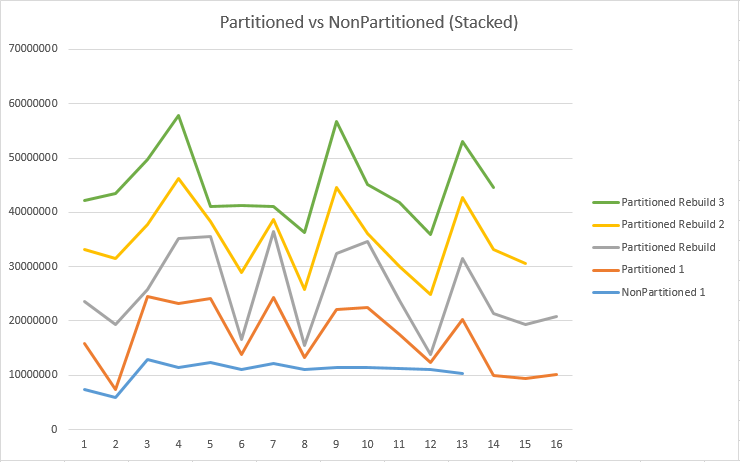
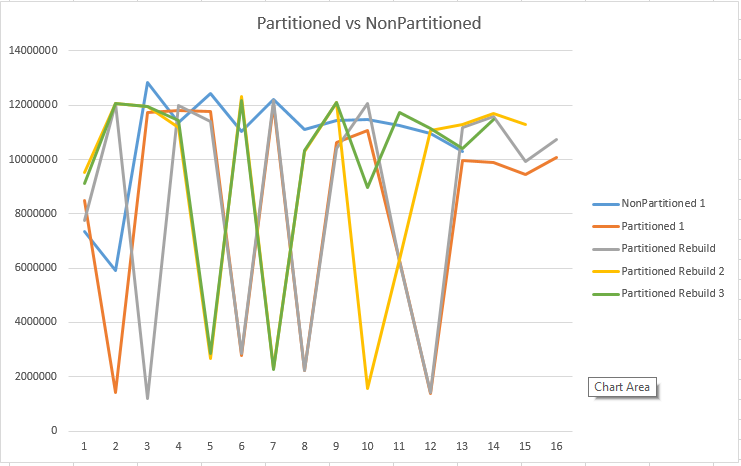
So what actually is happen there – it looks like a non-partitioned index is winning the battle in the terms of the size and in the terms of the space occupied by segments: they look quite smooth in the Non-Partitioned Clustered Columnstore and they look with Ups and great downs in the Partitioned Clustered Columnstore Index case.
This make a lot of sense and this is a natural process – this is partitioning. Every time we see a major drop with a consequent rise of the size of consequetive Segments, we should be considering this point as end of a partition. Since Clustered Columnstore Index is created inside each of the physically separated partitions (files & filegroups), it is perfectly natural that the at those critical points the number of rows can be cut quite dramatically.
But that is not all that happens there, take a look at the number of Segments – it looks like it is going steady down with each consecutive Rebiuld – should we believe that the Clustered Columnstore Index actually improves rows distribution with each rebuild?
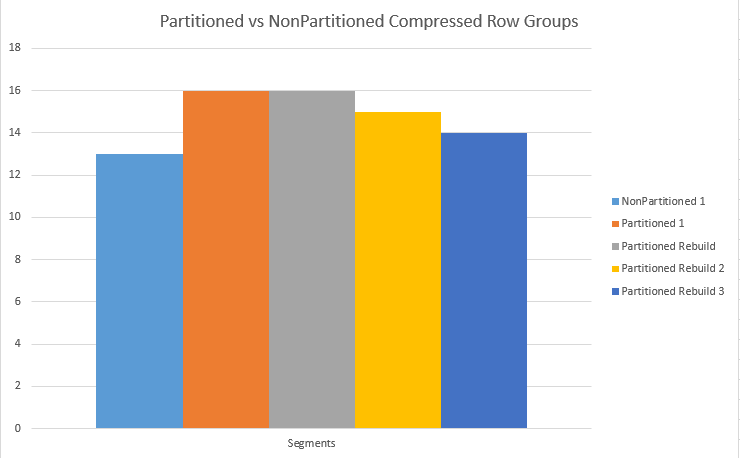
A very interesting detail – I decided to come back and revisit the creation process – so I dropped the partitioned Clustered Columnstore Index and created it again – and this time I have had no error messages or other sad transmissions: everything worked perfectly.
I guess that there is an alignment meta-information stored somewhere inside… :)
drop Index PK_FactOnlineSales on dbo.FactOnlineSales; -- Create Partitioned Clustered Columnstore Index Create Clustered Columnstore Index PK_FactOnlineSales on dbo.FactOnlineSales ON ColumstorePartitioning (DateKey);
At this point I decided to take control of the compression and I thought that since most of the 2007 year data was used very rarely, I should point it to the newest COMUNSTORE_ARCHIVE compression, but before it check out the data from my current sys.column_store_row_groups DMV, by executing the following statement:
select OBJECT_NAME(p.object_id) as TableName, p.partition_id, p.data_compression, p.data_compression_desc, rg.state, rg.state_description,
rg.total_rows as SegmentRows, p.rows as PartitionRows, rg.size_in_bytes as 'Size'
from sys.partitions p
inner join sys.column_store_row_groups rg
on p.object_id = rg.object_id and p.partition_number = rg.partition_number
where p.object_id = object_id('dbo.FactOnlineSales')
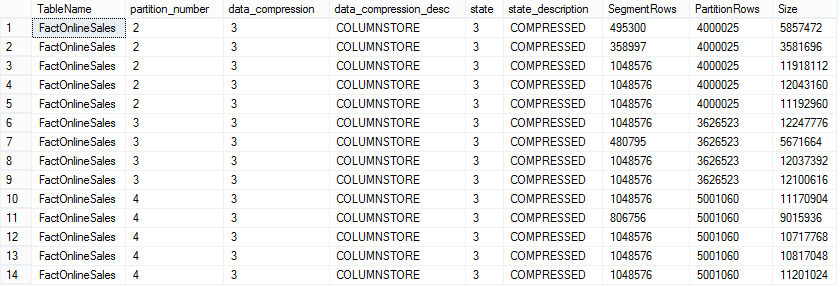
-- Rebuild the oldest partition which has some data with a different compression method: alter Index PK_FactOnlineSales on dbo.FactOnlineSales REBUILD PARTITION = 2 WITH (DATA_COMPRESSION = COLUMNSTORE_ARCHIVE);
Lets check out our results:
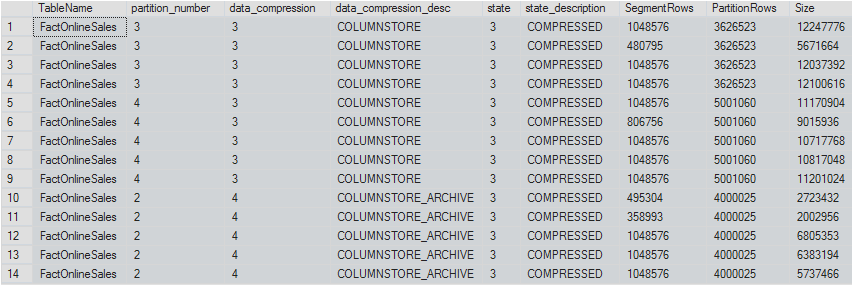
Surely one can see that the 2nd partition indeed has changed its compression algorithm and it is quite visible that the respective sizes of the Segments went also down. This is a nice proof of the partitioning functionality that allows us to use different Columnstore compression algorithms for the same table.
And to add a little bit more fun, for the end of this part on the partitioning, let’s try to rebuild our clustered Columnstore Index again, but this time doing it as an online operation, since Microsoft has invested vastly into Online operation in the last 2 versions of the SQL Server (including LOB’s for SQL Server 2012 and including support for online rebuild on a partition level for the upcoming SQL Server 2014l.
alter Index PK_FactOnlineSales on dbo.FactOnlineSales REBUILD WITH (DATA_COMPRESSION = COLUMNSTORE, ONLINE = ON);
This statement produces the following output:
Msg 35328, Level 16, State 1, Line 1
ALTER INDEX REBUILD statement failed because the ONLINE option is not allowed when rebuilding a columnstore index. Rebuild the columnstore index without specifying the ONLINE option.
Which basically says that there is no Online rebuild for the Clustered Columnstore Indexes. I have tried rebuilding just one partition online, but the error message stays the same – no Online operations for the Clustered Columnstore Indexes in this version.
To be continued with Clustered Columnstore Indexes – part 15 (“Partitioning Advanced”)
Hi Niko
Can I please ask your advice ?
I have loaded a fairly large Data Mart table (230 Gig Columnstore compressed). I want to implement partitioning on this table using daily partitions and split the data across multiple database files? Will this be as simple as dropping the existing columnstore on the table ,and creating the Clustered ColumnStore index on the Partition Schema which is points to my new FileGroups\Files.
Ex.
CREATE CLUSTERED COLUMNSTORE INDEX [CCI_TableName] ON [dbo].[Work_Status] WITH (DROP_EXISTING = OFF) On psDaily([Date])
Thanks, Drickus
Hi Drickus,
no, it won’t be that easy.
Since Columnstore Indexes do not sort the data, you will need to implement a full partitioning on Rowstore Index first (making data go into the right partition),
then creating a clustered columnstore index on partitioned clustered rowstore index with (DROP_EXISTING = ON).
Best regards,
Niko
Does ir mean that when a rowstore slustered index table is partitioned and we get the above mentioned error message (Msg 35316) we should:
1. Drop all nonclustered indexes.
2. Create the clustered columnstore partitioned index with (drop_existing=on).
3. Recreate the nonclustered indexes.
Is it correct?
Sorry, only now I realize that my question was wrong..
The problem is the following:
I have Clustered RowStore Index with some NonClustered RowStore indexes, all are partitioned: some by partition function A and some by partition function B.
I understand this Clustered RowStore Index cannot be changed to Clustered ColumnStore Index, unless all the indexes will have the same partition function.
Thanks!
Hi Geri,
yes the rules for the partitioned index alignment are even more severe for the Columnstore Indexes,
than for the traditional Rowstore indexes.
Best regards,
Niko Neugebauer
Hey Niko,
Thanks for the post, I have a fair doubt i can;t see in this post, how do you make sure that the data corresponding to the year 2008 falls into the “2008” filegroup, i don’t see such an explicit pointer when you create the clustered columnstore index.
Thanks
Hi Marce,
the data distribution happens by using the partitioning function (and respective pre-defined partitions) and the Rowstore Indexes creation before creating Columnstore Indexes.
Best regards,
Niko
Thanks Niko,
My apologies for this assumption, I reckon this still looks a tad vague for the way the rows get allocated at each Filegroup/datafile, and it complicates my way to see maintenance activities flowing smoothly – a little bit – and at one specific event: I would like to move the oldest datafile and year to another disk because it could no longer be needed (assuming, for your example, that the FILEGROUP Columnstore2007 relates to only 2007 records) and potentially delete it. I’m not quite confident in saying if it’s safe to assume that the oldest partition plus the next up ( OldColumnstoreData, Columnstore2007) will actually comprise only old rows not newer than 2017-12-31.
Any Ideas?
Thanks!!!