Continuation from the previous 12 parts, starting from https://www.nikoport.com/2013/07/05/clustered-columnstore-indexes-part-1-intro/
This time I decided to play a little bit more with Clustered Columnstore dictionaries in order to understand them a little bit better.
Continuing working with Contoso BI Database but this time I am kicking off with in a different way – by executing the following script which will help me to find the tables which might be suitable for the Clustered Columnstore Indexes (with over 1 Million rows) and it provides with some useful information about those parts where Clustered Columnstore are imposing some limits:
Warning: this is a code in development and it is based on the current CTP1 version of SQL Server 2014.
Warning 2: indeed you can convert any table with less than 1 Million rows, and some tables might greatly benefit from it, but this very script and this blog post is focusing just on the big tables.
-- Returns tables suggested for using Clustered Columnstore for the Datawarehouse environments
select object_schema_name( t.object_id ) as 'Schema'
, object_name (t.object_id) as 'Table'
, sum(p.rows) as 'Row Count'
, (select count(*) from sys.columns as col
where t.object_id = col.object_id ) as 'Cols Count'
, (select sum(col.max_length)
from sys.columns as col
join sys.types as tp
on col.system_type_id = tp.system_type_id
where t.object_id = col.object_id
) as 'Cols Max Length'
, (select count(*)
from sys.columns as col
join sys.types as tp
on col.system_type_id = tp.system_type_id
where t.object_id = col.object_id and
(UPPER(tp.name) in ('TEXT','NTEXT','TIMESTAMP','HIERARCHYID','SQL_VARIANT','XML','GEOGRAPHY','GEOMETRY') OR
(UPPER(tp.name) in ('VARCHAR','NVARCHAR') and (col.max_length = 8000 or col.max_length = -1))
)
) as 'Unsupported Columns'
, (select count(*)
from sys.objects
where type = 'PK' AND parent_object_id = t.object_id ) as 'Primary Key'
, (select count(*)
from sys.objects
where type = 'F' AND parent_object_id = t.object_id ) as 'Foreign Keys'
, (select count(*)
from sys.objects
where type in ('UQ','D','C') AND parent_object_id = t.object_id ) as 'Constraints'
, (select count(*)
from sys.objects
where type in ('TA','TR') AND parent_object_id = t.object_id ) as 'Triggers'
, t.is_tracked_by_cdc as 'CDC'
, t.is_memory_optimized as 'Hekaton'
, t.is_replicated as 'Replication'
, coalesce(t.filestream_data_space_id,0,1) as 'FileStream'
, t.is_filetable as 'FileTable'
from sys.tables t
inner join sys.partitions as p
ON t.object_id = p.object_id
where p.data_compression in (0,1,2) -- None, Row, Page
and p.index_id in (0,1)
and (select count(*)
from sys.indexes ind
where t.object_id = ind.object_id
and ind.type in (5,6) ) = 0
group by t.object_id, t.is_tracked_by_cdc, t.is_memory_optimized, t.is_filetable, t.is_replicated, t.filestream_data_space_id
having sum(p.rows) > 1000000
order by sum(p.rows) desc
These are the results that I have received when executing this script on my Contoso BI Database:

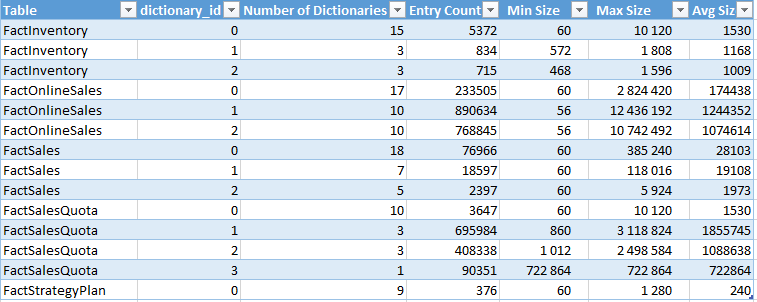
Basically, the results are telling me that I have 5 tables which are candidates to be converted to use the Clustered Columnstore Index: FactOnlineSales, FactInventory, FactSalesQuota, FactSales, FactStrategyPlan. Besides that we can see the number of columns that every table has as well as the number of the respective Primary and Foreign Keys, plus some other columns which are all fine for our exercise.
Lets go forward and drop all the respective Primary as well as the Foreign Keys:
-- Drop Primary Keys: ALTER TABLE dbo.[FactOnlineSales] DROP CONSTRAINT [PK_FactOnlineSales_SalesKey] ALTER TABLE dbo.[FactStrategyPlan] DROP CONSTRAINT [PK_FactStrategyPlan_StrategyPlanKey] ALTER TABLE dbo.[FactSales] DROP CONSTRAINT [PK_FactSales_SalesKey] ALTER TABLE dbo.[FactInventory] DROP CONSTRAINT [PK_FactInventory_InventoryKey] ALTER TABLE dbo.[FactSalesQuota] DROP CONSTRAINT [PK_FactSalesQuota_SalesQuotaKey] -- Drop Foreign Keys: ALTER TABLE dbo.[FactOnlineSales] DROP CONSTRAINT [FK_FactOnlineSales_DimCurrency] ALTER TABLE dbo.[FactOnlineSales] DROP CONSTRAINT [FK_FactOnlineSales_DimCustomer] ALTER TABLE dbo.[FactOnlineSales] DROP CONSTRAINT [FK_FactOnlineSales_DimDate] ALTER TABLE dbo.[FactOnlineSales] DROP CONSTRAINT [FK_FactOnlineSales_DimProduct] ALTER TABLE dbo.[FactOnlineSales] DROP CONSTRAINT [FK_FactOnlineSales_DimPromotion] ALTER TABLE dbo.[FactOnlineSales] DROP CONSTRAINT [FK_FactOnlineSales_DimStore] ALTER TABLE dbo.[FactStrategyPlan] DROP CONSTRAINT [FK_FactStrategyPlan_DimAccount] ALTER TABLE dbo.[FactStrategyPlan] DROP CONSTRAINT [FK_FactStrategyPlan_DimCurrency] ALTER TABLE dbo.[FactStrategyPlan] DROP CONSTRAINT [FK_FactStrategyPlan_DimDate] ALTER TABLE dbo.[FactStrategyPlan] DROP CONSTRAINT [FK_FactStrategyPlan_DimEntity] ALTER TABLE dbo.[FactStrategyPlan] DROP CONSTRAINT [FK_FactStrategyPlan_DimProductCategory] ALTER TABLE dbo.[FactStrategyPlan] DROP CONSTRAINT [FK_FactStrategyPlan_DimScenario] ALTER TABLE dbo.[FactSales] DROP CONSTRAINT [FK_FactSales_DimChannel] ALTER TABLE dbo.[FactSales] DROP CONSTRAINT [FK_FactSales_DimCurrency] ALTER TABLE dbo.[FactSales] DROP CONSTRAINT [FK_FactSales_DimDate] ALTER TABLE dbo.[FactSales] DROP CONSTRAINT [FK_FactSales_DimProduct] ALTER TABLE dbo.[FactSales] DROP CONSTRAINT [FK_FactSales_DimPromotion] ALTER TABLE dbo.[FactSales] DROP CONSTRAINT [FK_FactSales_DimStore] ALTER TABLE dbo.[FactInventory] DROP CONSTRAINT [FK_FactInventory_DimCurrency] ALTER TABLE dbo.[FactInventory] DROP CONSTRAINT [FK_FactInventory_DimDate] ALTER TABLE dbo.[FactInventory] DROP CONSTRAINT [FK_FactInventory_DimProduct] ALTER TABLE dbo.[FactInventory] DROP CONSTRAINT [FK_FactInventory_DimStore] ALTER TABLE dbo.[FactSalesQuota] DROP CONSTRAINT [FK_FactSalesQuota_DimChannel] ALTER TABLE dbo.[FactSalesQuota] DROP CONSTRAINT [FK_FactSalesQuota_DimCurrency] ALTER TABLE dbo.[FactSalesQuota] DROP CONSTRAINT [FK_FactSalesQuota_DimDate] ALTER TABLE dbo.[FactSalesQuota] DROP CONSTRAINT [FK_FactSalesQuota_DimProduct] ALTER TABLE dbo.[FactSalesQuota] DROP CONSTRAINT [FK_FactSalesQuota_DimScenario] ALTER TABLE dbo.[FactSalesQuota] DROP CONSTRAINT [FK_FactSalesQuota_DimStore]
Now lets create the respective Clustered Colunstore Indexes for each of those tables:
Create Clustered Columnstore Index PK_FactOnlineSales on dbo.FactOnlineSales WITH (DATA_COMPRESSION = COLUMNSTORE); Create Clustered Columnstore Index PK_FactStrategyPlan on dbo.FactStrategyPlan WITH (DATA_COMPRESSION = COLUMNSTORE); Create Clustered Columnstore Index PK_FactSales on dbo.FactSales WITH (DATA_COMPRESSION = COLUMNSTORE); Create Clustered Columnstore Index PK_FactInventory on dbo.FactInventory WITH (DATA_COMPRESSION = COLUMNSTORE); Create Clustered Columnstore Index PK_FactSalesQuota on dbo.FactSalesQuota WITH (DATA_COMPRESSION = COLUMNSTORE);
To analyze the situation with the dictionaries I have decided to run the following query, which would give me back the information about dictionary sizes for each of the tables:
select object_name(object_id), dictionary_id , count(*) as 'Number of Dictionaries' , sum(entry_count) as 'Entry Count' , min(on_disk_size) as 'Min Size' , max(on_disk_size) as 'Max Size' , avg(on_disk_size) as 'Avg Size' from sys.column_store_dictionaries dict join sys.partitions part on dict.hobt_id = part.hobt_id group by object_id, dictionary_id order by object_name(object_id), dictionary_id
The results are here (already inserted into an Excel file):
According to the diciontary_id, here is an image of the development of the number of dictionaries available:
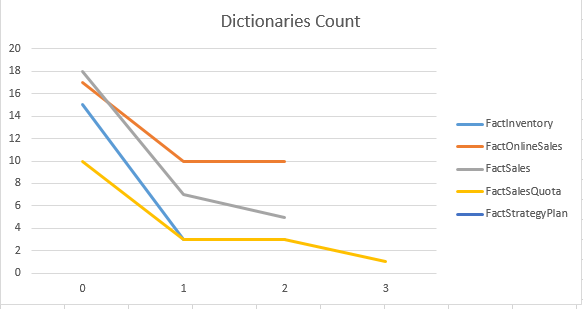
Maybe it is just me, but I see some very clear tendency of the number of dictionaries decreasing according to the dictionary_id progression. Since there is no information at all what should be considered a Primary (Global) dictionary and what is a Secondary one, I would guess that the first available dictionary_id is the Primary dictionary, based on the number of the dictionaries available.
Note: of course this is a speculation and just a one-man in the middle-of-other-things-research :)
Warning: FactInventory & FactSales are represented on the right scale.
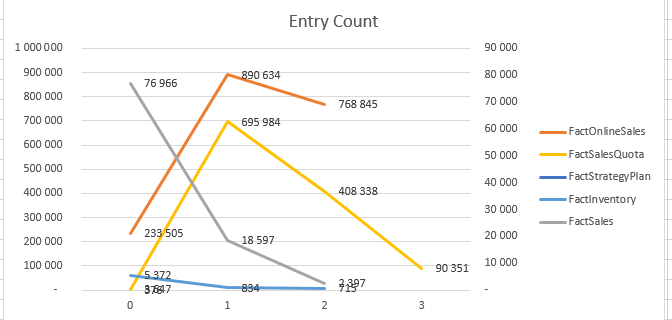
If we look at the Number of Entries inside of a dictionary, aka Entry Count results, we might notice the following tendency – the very first dictionary looks like it is a kind of displaced, but starting with a dictionary_id = 1, the number of entries definitely goes up to dive down, which also points out at the location of the Primary dictionary – the first one which contains the smallest amount of entries -> dictionary_id = 0.
Other thoughts:
From the tables I have analyzed, there were different amount of space that different type of dictionaries have occupied, and from which I believe that the absolute minimum for the very first dictionary_id is 60 bytes, but what makes things even more interesting is that for the second and the third levels of dictionaries_id (which are =1 and =2 respectfully), the minimum number of bytes goes down to 56 bytes, which means that there is a 4 bytes difference between the first level of dictionaries_id and the consequent ones. I wish I had any explanation for all this stuff, but lets hope that someone will discover it quite soon, or that Microsoft shall publish more internal information about the Clustered Columnstore Indexes.
to be continued with Clustered Columnstore Indexes – part 14 (“Partitioning”)
Pingback: Clustered Columnstore Indexes – part 1 (“Intro”) | Nikoport
I believe you should filter sys.partitions like so:
and p.index_id IN (0,1) –Heap, Clustered
Otherwise, the query returns partitions for all indexes, and this inflates the row count (sum(p.rows))
Hi Pittsburgh DBA,
Thank you !
Now the blog post is updated.
Best regards,
Niko